整理一下在机器学习中常见的评价指标,包括:
- 混淆矩阵,TPR,FPR,TNR,FNR;
- Precision,Recall,Accuracy,F-score(F1-meature)
- ROC曲线,AUC;
混淆矩阵
以二分类为例,混淆矩阵如下:
| Reference\Prediction | 1 | 0 |
|---|---|---|
| 1 | TP(真阳) | FN(假阴) |
| 0 | FP(假阳) | TN(真阴) |
TPR(True Positive Rate)可以理解为在所有正类中,被正确检测出来的概率,也就是召回率,也被称作灵敏度(Sensitivity)。
T
P
R
=
T
P
T
P
+
F
N
=
T
R
P
TPR = \frac{TP}{TP+FN} = \frac{TR}{P}
TPR=TP+FNTP=PTR
FPR(False Positive Rate)假阳率,在所有的负类中,有多少被错误的预测为正类。也是 1-Specificity(TNR) ,也是fall-out 误报率。
F
P
R
=
F
P
F
P
+
T
N
=
F
P
N
=
1
−
T
N
R
FPR = \frac{FP}{FP+TN} = \frac{FP}{N} = 1-TNR
FPR=FP+TNFP=NFP=1−TNR
FNR(True Negative Rate)假阴率,在所有的正类中,没有检测出来的比率。也是miss rate 漏报率。
F
N
R
=
F
N
T
P
+
F
N
=
F
N
P
FNR = \frac{FN}{TP+FN} = \frac{FN}{P}
FNR=TP+FNFN=PFN
TNR(True Negative Rate)真阴率,在所有的负类中,负类被正确检测出来的比率。也就是特异性(Specificity)。
T
N
R
=
T
N
T
N
+
F
P
=
T
N
N
TNR = \frac{TN}{TN+FP} = \frac{TN}{N}
TNR=TN+FPTN=NTN
评价指标
Precision(精确度),可以理解为,在预测为正类中的结果中,有多少比率是正确的。在混淆矩阵中是竖着计算的。
P
r
e
c
i
s
i
o
n
=
T
P
T
P
+
F
P
Precision = \frac{TP}{TP+FP}
Precision=TP+FPTP
Recall(召回率),可以理解为,在所有的正类当中,有多少被正确预测出来了。也就是前面提到的TPR。在混淆矩阵中是横着计算的。
R
e
c
a
l
l
=
T
P
T
P
+
F
N
Recall = \frac{TP}{TP+FN}
Recall=TP+FNTP
F-score(F值),也被称作F1-meature,综合考虑Precision和Recall。是两者的调和平均。
F
=
2
∗
P
r
e
c
i
s
i
o
n
∗
R
e
c
a
l
l
P
r
e
c
i
s
i
o
n
+
R
e
c
a
l
l
=
2
1
P
r
e
c
i
s
i
o
n
+
1
R
e
c
a
l
l
F = 2* \frac{Precision*Recall}{Precision+Recall} = \frac{2}{\frac{1}{Precision}+\frac{1}{Recall}}
F=2∗Precision+RecallPrecision∗Recall=Precision1+Recall12
Accuracy(准确度),所有结果中,分类正确的比例。
A
c
c
u
r
a
c
y
=
T
P
+
T
N
P
+
N
Accuracy = \frac{TP+TN}{P+N}
Accuracy=P+NTP+TN
图示说明
参考 https://en.wikipedia.org/wiki/Confusion_matrix 全面总结
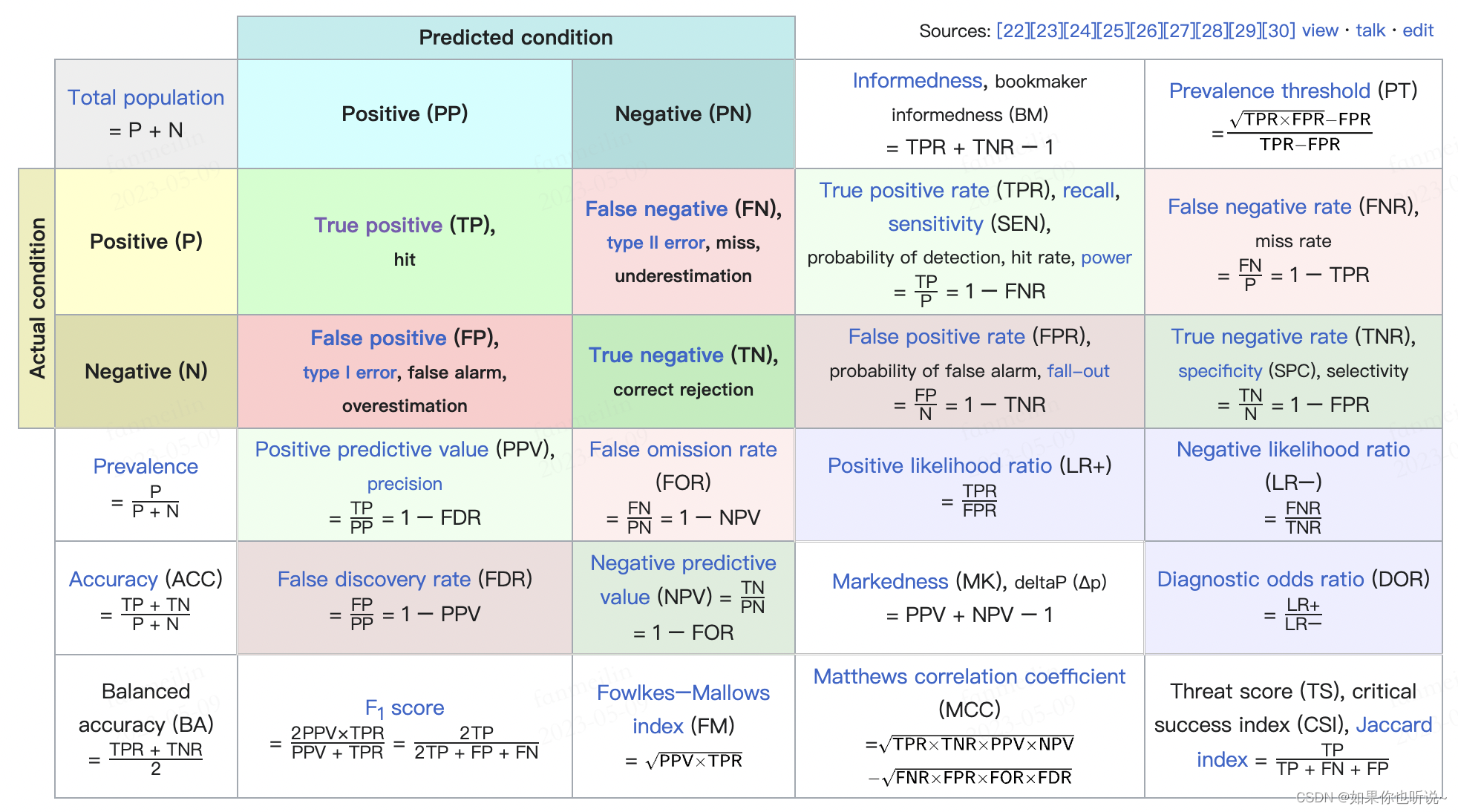
总结得非常全面,可以直接看这张图复习。
ROC曲线
也被称作“受试者工作特性曲线”,越靠近左上角的点,效果越好。
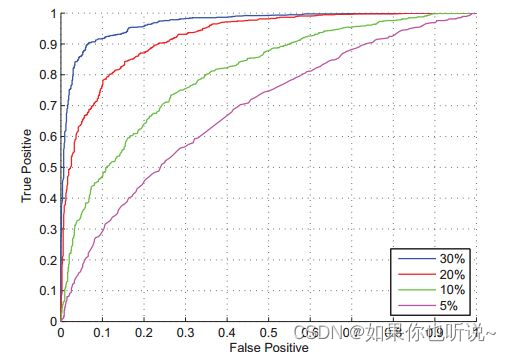
- 横坐标是FPR【1-specificity】,纵坐标是TPR【sensitivity】,两者没有相关性。
- 曲线上点代表着,不同阈值下的分类的结果:
- 当阈值为1时,所有的样本都被分成负类了,那么此时的FPR,TPR均为0;
- 当阈值为0时,所有的样本都被分成正样本,此时FPR,TPR均为1。
- AUC(Area Under Curve)定义为ROC曲线下的面积,最大为1,越大说明分类器效果越好。
![[Vue warn]: You may have an infinite update loop in a component render function](https://img-blog.csdnimg.cn/91384222b9db42bfa926cd45e947ceed.png)