深度学习训练营J2:ResNet50v2算法分析与实战
- 原文链接
- 环境介绍
- 0.引言
- 论文分析与解读
- 1.ResNet50和ResNet50v2之间的结构对比
- 2.不同结构之间的尝试
- 3.关于激活的不同尝试
- 4.文章结果
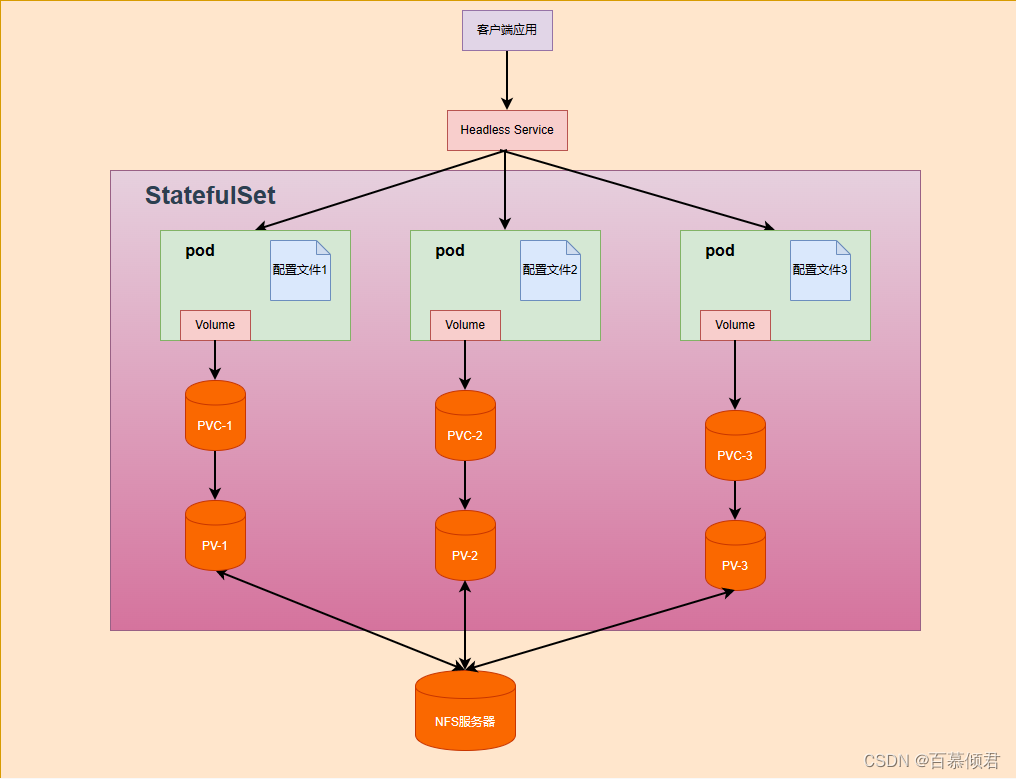
- ResNet50v2架构复现
- 5.残差结构
- 6.模块构建
- 7.架构展示以及网络构建
- 8.网络结构打印
- ResNet50v2完整结构图
- 注释
原文链接
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍦 参考文章:365天深度学习训练营-第J2周:ResNet50v2算法分析与实战
- 🍖 原作者:K同学啊|接辅导、项目定制
环境介绍
- 语言环境:Python3.9.13
- 编译器:jupyter notebook
- 深度学习环境:TensorFlow2
0.引言
本周主要的操作是完整看了ResNet50v2的官方论文,第一次完整的看完一篇英语论文,难度上还是很大的,很多内容还不是很理解,了解了一些深度学习的不熟悉的内容,接下来还可能丰富一下自己的基础知识再来读,可能会有新的体会
论文的源文件链接:Identity Mappings in Deep Residual Networks
论文分析与解读
1.ResNet50和ResNet50v2之间的结构对比
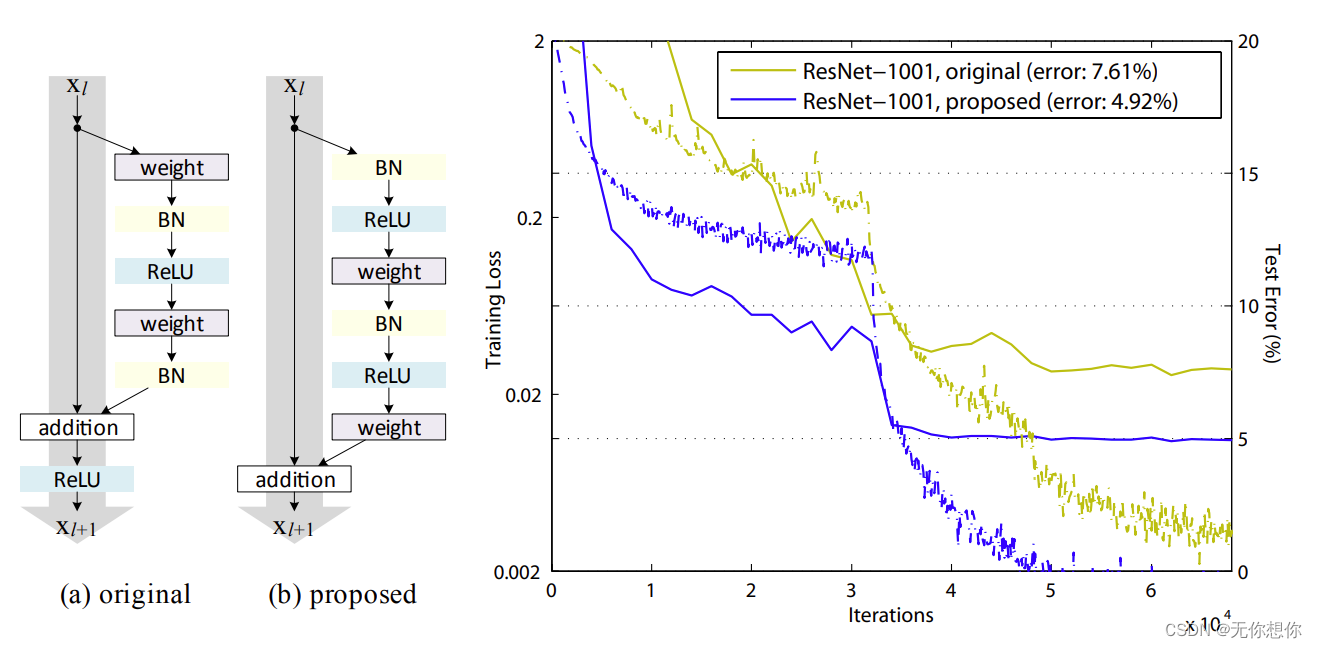
表示:(a)original 表示原始的ResNet结构 (b)proposed 表示新的ResNet残差结构.
改进点:(b)结构当中的ReLU比(a)的使用时候早,使用的BN和ReLU是计算后进行卷积,
改进结果:作者使用这两种不同的结构在CIFAR-10数据集上做测试,模型使用1001层ResNet模型,可以看到,(b)的方案更低一些,达到了4.29%的错误率’
2.不同结构之间的尝试
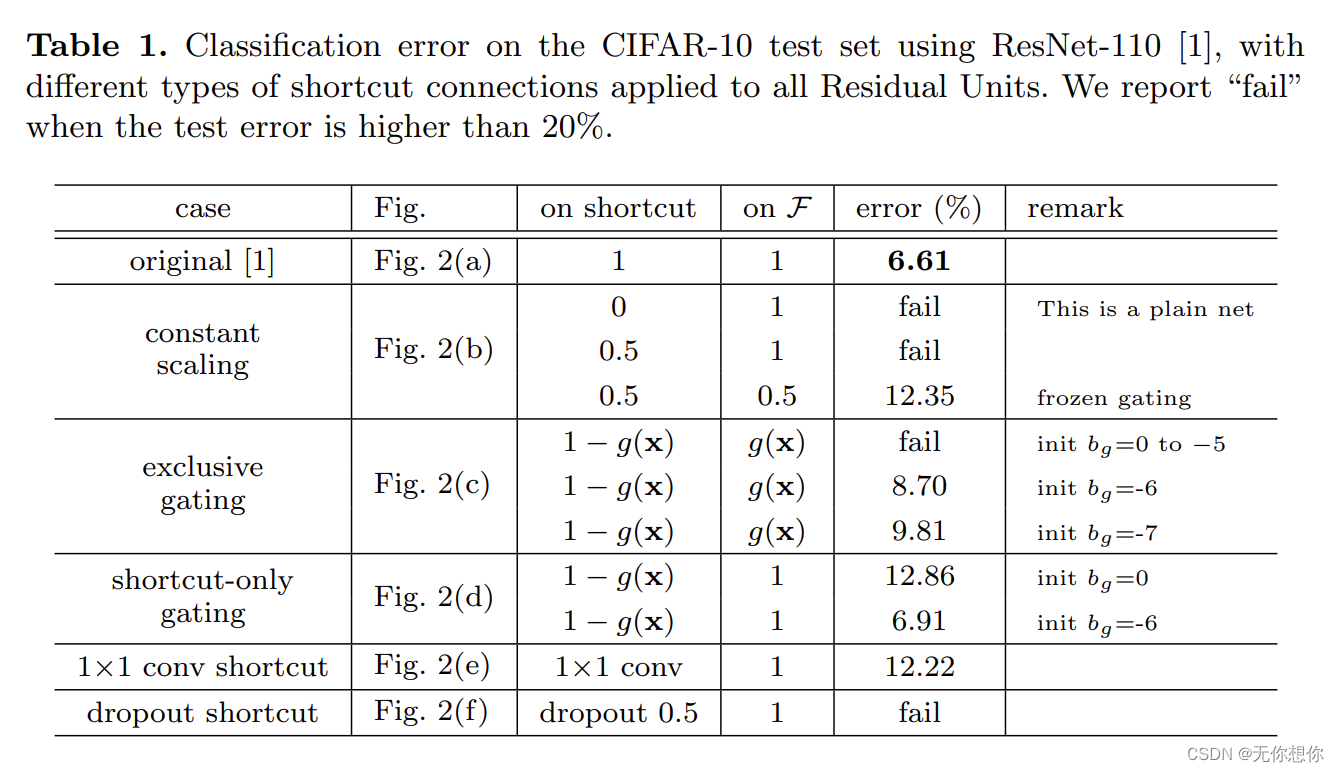
在本论文当中,作者一共提出了6种方法(其中包括原始方法)在CIFAR-10数据集当中进行测试
以下是原始模型和改进后的模型之间的网络架构示意图
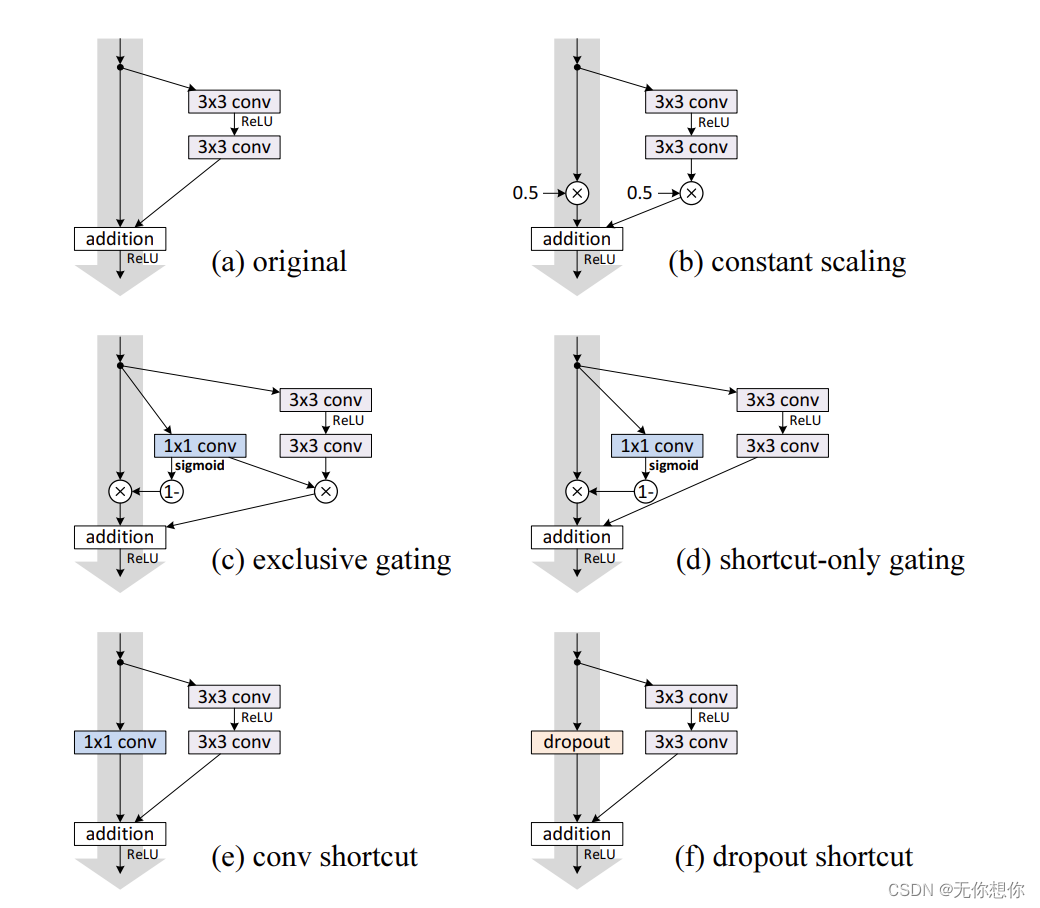
每一种网络在CIFAR-10的数据集上的表现结果如下
训练曲线的结果如下
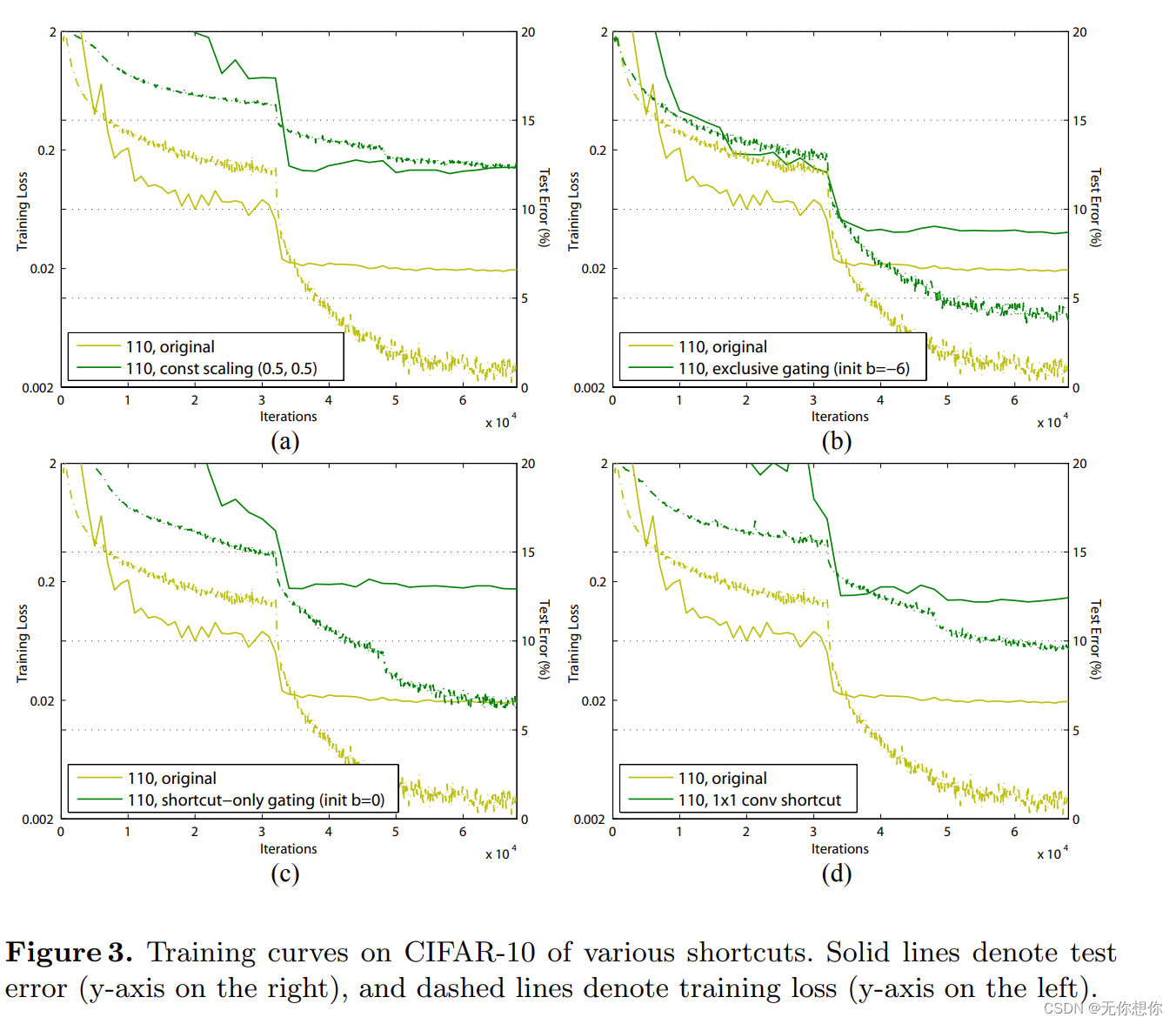
从这里不难看出,以上的所有改变都没有让网络更好的实现错误率降低,反而原始的original的表现是最好的,也就是说identity mapping恒等映射是最好的
3.关于激活的不同尝试
以下是激活函数的调整以及结果展示

可以很清楚的看到(e) full pre-activation的结果是最好的,其次是(a)original.
后面则重点实验了这种方法之间的一个比较
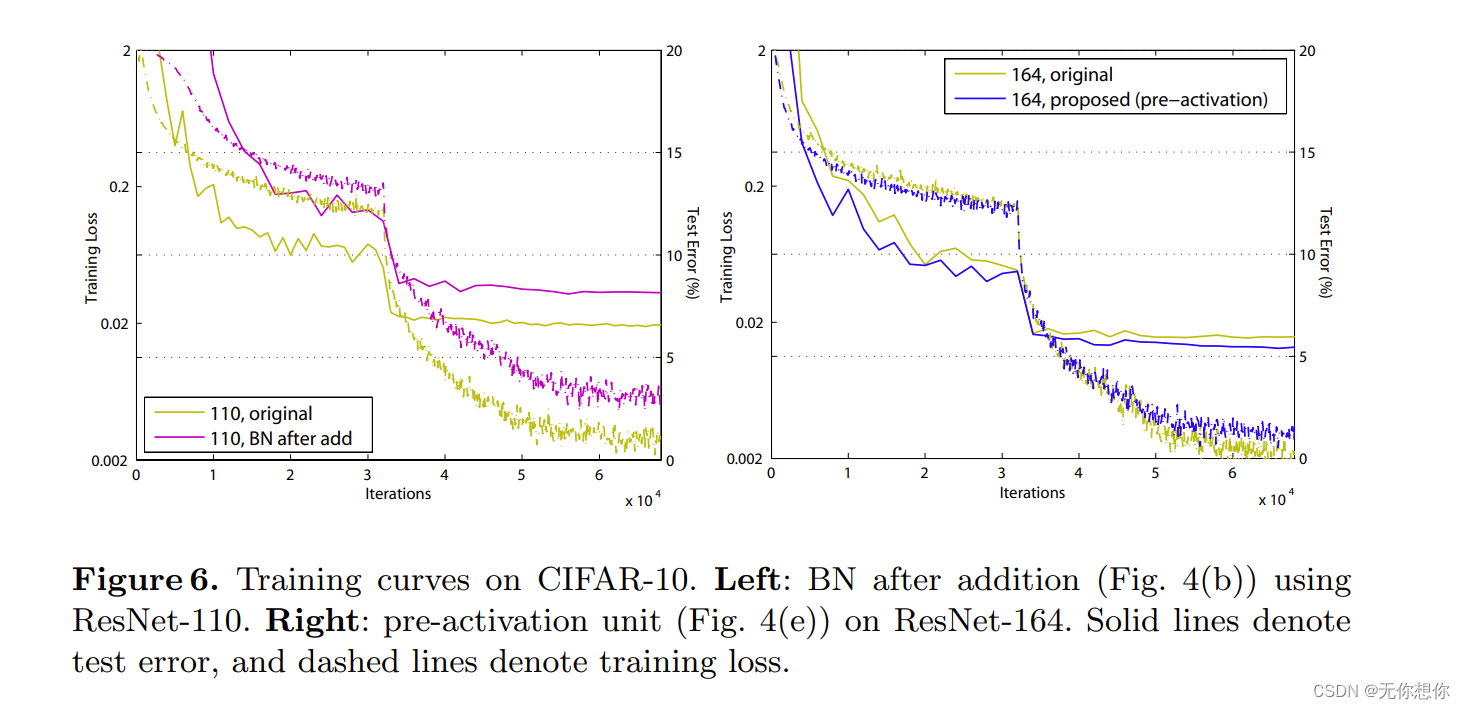 对应的实验结果如下表格
对应的实验结果如下表格
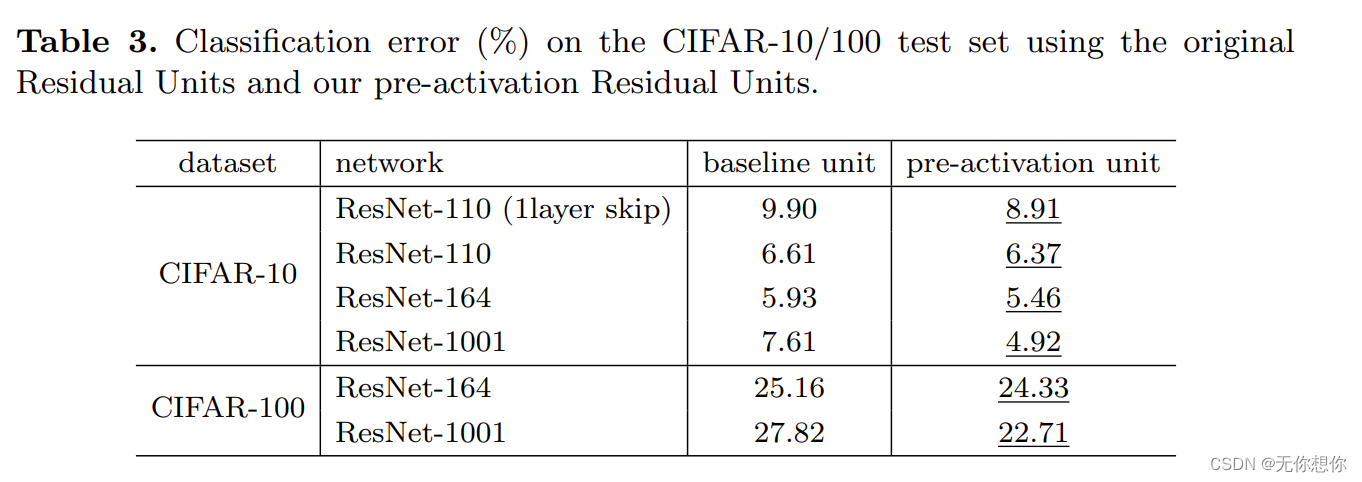
可以看到在同样的神经网络结果下,对于CIFAR-100以及CIFAR-100的训练当中,pre-activation unit 比baseline unit降低了不少
4.文章结果
文章的result则Comparisons on CIFAR-10/100,Comparisons on ImageNet,Computational Cost等方面进行了展开论述pre-activation的优势,其中提到了一句话:
These results demonstrate the potential of pushing the limits of depth
这表明充分并且合理的发挥网络的深度,使其不断到达其极限,会是一个深度学习当中十分重要的思考方向
ResNet50v2架构复现
5.残差结构
''' Residual Block '''
class Block2(nn.Module):
def __init__(self, in_channel, filters, kernel_size=3, stride=1, conv_shortcut=False):
super(Block2, self).__init__()
self.preact = nn.Sequential(
nn.BatchNorm2d(in_channel),
nn.ReLU(True)
)
self.shortcut = conv_shortcut
if self.shortcut:
self.short = nn.Conv2d(in_channel, 4*filters, 1, stride=stride, padding=0, bias=False)
elif stride>1:
self.short = nn.MaxPool2d(kernel_size=1, stride=stride, padding=0)
else:
self.short = nn.Identity()
self.conv1 = nn.Sequential(
nn.Conv2d(in_channel, filters, 1, stride=1, bias=False),
nn.BatchNorm2d(filters),
nn.ReLU(True)
)
self.conv2 = nn.Sequential(
nn.Conv2d(filters, filters, kernel_size, stride=stride, padding=1, bias=False),
nn.BatchNorm2d(filters),
nn.ReLU(True)
)
self.conv3 = nn.Conv2d(filters, 4*filters, 1, stride=1, bias=False)
def forward(self, x):
x1 = self.preact(x)
if self.shortcut:
x2 = self.short(x1)
else:
x2 = self.short(x)
x1 = self.conv1(x1)
x1 = self.conv2(x1)
x1 = self.conv3(x1)
x = x1 + x2
return x
6.模块构建
class Stack2(nn.Module):
def __init__(self, in_channel, filters, blocks, stride=2):
super(Stack2, self).__init__()
self.conv = nn.Sequential()
self.conv.add_module(str(0), Block2(in_channel, filters, conv_shortcut=True))
for i in range(1, blocks-1):
self.conv.add_module(str(i), Block2(4*filters, filters))
self.conv.add_module(str(blocks-1), Block2(4*filters, filters, stride=stride))
def forward(self, x):
x = self.conv(x)
return x
7.架构展示以及网络构建
图片我根据K同学啊的图片自己使用软件绘制了一遍,有问题的大家可以提出来

''' 构建ResNet50V2 '''
class ResNet50V2(nn.Module):
def __init__(self,
include_top=True, # 是否包含位于网络顶部的全链接层
preact=True, # 是否使用预激活
use_bias=True, # 是否对卷积层使用偏置
input_shape=[224, 224, 3],
classes=1000,
pooling=None): # 用于分类图像的可选类数
super(ResNet50V2, self).__init__()
self.conv1 = nn.Sequential()
self.conv1.add_module('conv', nn.Conv2d(3, 64, 7, stride=2, padding=3, bias=use_bias, padding_mode='zeros'))
if not preact:
self.conv1.add_module('bn', nn.BatchNorm2d(64))
self.conv1.add_module('relu', nn.ReLU())
self.conv1.add_module('max_pool', nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
self.conv2 = Stack2(64, 64, 3)
self.conv3 = Stack2(256, 128, 4)
self.conv4 = Stack2(512, 256, 6)
self.conv5 = Stack2(1024, 512, 3, stride=1)
self.post = nn.Sequential()
if preact:
self.post.add_module('bn', nn.BatchNorm2d(2048))
self.post.add_module('relu', nn.ReLU())
if include_top:
self.post.add_module('avg_pool', nn.AdaptiveAvgPool2d((1, 1)))
self.post.add_module('flatten', nn.Flatten())
self.post.add_module('fc', nn.Linear(2048, classes))
else:
if pooling=='avg':
self.post.add_module('avg_pool', nn.AdaptiveAvgPool2d((1, 1)))
elif pooling=='max':
self.post.add_module('max_pool', nn.AdaptiveMaxPool2d((1, 1)))
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.conv4(x)
x = self.conv5(x)
x = self.post(x)
return x
8.网络结构打印
ResNet50V2(
(conv1): Sequential(
(conv): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3))
(max_pool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
)
(conv2): Stack2(
(conv): Sequential(
(0): Block2(
(preact): Sequential(
(0): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(1): ReLU(inplace=True)
)
(short): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(conv1): Sequential(
(0): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(conv2): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(1): Block2(
(preact): Sequential(
(0): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(1): ReLU(inplace=True)
)
(short): Identity()
(conv1): Sequential(
(0): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(conv2): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(2): Block2(
(preact): Sequential(
(0): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(1): ReLU(inplace=True)
)
(short): MaxPool2d(kernel_size=1, stride=2, padding=0, dilation=1, ceil_mode=False)
(conv1): Sequential(
(0): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(conv2): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
)
)
(conv3): Stack2(
(conv): Sequential(
(0): Block2(
(preact): Sequential(
(0): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(1): ReLU(inplace=True)
)
(short): Conv2d(256, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(conv1): Sequential(
(0): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(conv2): Sequential(
(0): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(1): Block2(
(preact): Sequential(
(0): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(1): ReLU(inplace=True)
)
(short): Identity()
(conv1): Sequential(
(0): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(conv2): Sequential(
(0): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(2): Block2(
(preact): Sequential(
(0): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(1): ReLU(inplace=True)
)
(short): Identity()
(conv1): Sequential(
(0): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(conv2): Sequential(
(0): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(3): Block2(
(preact): Sequential(
(0): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(1): ReLU(inplace=True)
)
(short): MaxPool2d(kernel_size=1, stride=2, padding=0, dilation=1, ceil_mode=False)
(conv1): Sequential(
(0): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(conv2): Sequential(
(0): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
)
)
(conv4): Stack2(
(conv): Sequential(
(0): Block2(
(preact): Sequential(
(0): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(1): ReLU(inplace=True)
)
(short): Conv2d(512, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(conv1): Sequential(
(0): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(conv2): Sequential(
(0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(1): Block2(
(preact): Sequential(
(0): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(1): ReLU(inplace=True)
)
(short): Identity()
(conv1): Sequential(
(0): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(conv2): Sequential(
(0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(2): Block2(
(preact): Sequential(
(0): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(1): ReLU(inplace=True)
)
(short): Identity()
(conv1): Sequential(
(0): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(conv2): Sequential(
(0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(3): Block2(
(preact): Sequential(
(0): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(1): ReLU(inplace=True)
)
(short): Identity()
(conv1): Sequential(
(0): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(conv2): Sequential(
(0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(4): Block2(
(preact): Sequential(
(0): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(1): ReLU(inplace=True)
)
(short): Identity()
(conv1): Sequential(
(0): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(conv2): Sequential(
(0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(5): Block2(
(preact): Sequential(
(0): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(1): ReLU(inplace=True)
)
(short): MaxPool2d(kernel_size=1, stride=2, padding=0, dilation=1, ceil_mode=False)
(conv1): Sequential(
(0): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(conv2): Sequential(
(0): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
)
)
(conv5): Stack2(
(conv): Sequential(
(0): Block2(
(preact): Sequential(
(0): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(1): ReLU(inplace=True)
)
(short): Conv2d(1024, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(conv1): Sequential(
(0): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(conv2): Sequential(
(0): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(1): Block2(
(preact): Sequential(
(0): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(1): ReLU(inplace=True)
)
(short): Identity()
(conv1): Sequential(
(0): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(conv2): Sequential(
(0): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(2): Block2(
(preact): Sequential(
(0): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(1): ReLU(inplace=True)
)
(short): Identity()
(conv1): Sequential(
(0): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(conv2): Sequential(
(0): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
)
)
(post): Sequential(
(bn): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
(avg_pool): AdaptiveAvgPool2d(output_size=(1, 1))
(flatten): Flatten(start_dim=1, end_dim=-1)
(fc): Linear(in_features=2048, out_features=4, bias=True)
)
)
ResNet50v2完整结构图
可以看得出来这个网络非常深

注释
还有补充的内容
我后面部分的代码是来着这篇博客的
第J2周:ResNet50V2算法实战与解析