目录索引
- ==Selenium是什么:==
- ==下载和配置环境变量:==
- ==1. 基本使用:==
导入五个常用包:基本代码:
- ==实例引入:==
- ==声明不同浏览器对象:==
- ==访问页面:==
Selenium是什么:
- Selenium是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。
- 可以在一定程度上避免JS逆向的干扰
你问我selenium是什么?那我只能告诉你这是个高科技超级武器,爬虫界的神,可以让你节省极大的时间和简化代码的复杂程度。
下载和配置环境变量:
'''
1,安装selenium
-- 命令:pip install selenium
-- 网络不稳的请换源安装:pip install selenium -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
2,打开百度,输入chrome webdriver,下载谷歌浏览器webdriver驱动
-- http://npm.taobao.org/mirrors/chromedriver/
-- 根据自己谷歌版本选择驱动器
-- 选择对应版本,如果没有对应版本选择跟谷歌版本相近但不超过谷歌版本的
-- 下载后解压
3,拷贝到python安装路径
-- 找到Lib目录
-- 进入site-packages目录,将下载好的chromedriver.exe程序驱动放进该目录文件里
--如何找到Python安装路径 可以打开cmd,输入where Python
4,配置环境变量
-- 将webdriver驱动所在文件路径复制
-- 添加到系统环境变量里的Path路径里
5,验证是否配置完成
-- from selenium import webdriver
a = webdriver.Chrome()
a.get('https://www.baidu.com/')
6,如果上述操作报错,执行以下方法:
-- 将下载的驱动放入python环境的Scripts的文件夹里
-- 再将路径添加到环境变量(如果安装python时勾选了自动添加环境变量这步可省略)
7,上述两种方法还报错,执行以下方法:
-- 将下载的驱动放进项目根目录
'''
from selenium import webdriver
a = webdriver.Chrome()
a.get('https://www.baidu.com/')
如果在运行后发现网页会自动打开,就代表下载成功了!
1. 基本使用:
从上到下的代码都是连续的,但是为了方便学习,这里将它分别拆开来看。
导入五个常用包:
from selenium import webdriver #驱动浏览器
from selenium.webdriver.common.by import By #选择器,用于选择
from selenium.webdriver.common.keys import Keys #按键,起到鼠标点击的作用
from selenium.webdriver.support import expected_conditions as EC #等待所有标签加载完毕
from selenium.webdriver.support.wait import WebDriverWait #等待页面加载完毕,寻找某些元素
注释:
- 驱动浏览器
- 选择器,用于选择
- 按键,起到鼠标点击的作用
- 等待所有标签加载完毕
- 等待页面加载完毕,寻找某些元素
基本代码:
browser = webdriver.Chrome() #browser驱动对象,实例化一个对象
browser.get("网址地址") #调用浏览器驱动对象访问站点
注释:
- browser驱动对象,实例化一个对象
- 调用浏览器驱动对象访问站点
- browser的中文释义是浏览器
实例引入:
1.打开百度
2.在搜索框输入爬虫
3.点击搜索按钮
- 利用异常捕捉是因为设定了等待时间
try:
#1.打开百度
browser.get("https://www.baidu.com/") #调动浏览器驱动对象访问站点
#2.输入python文本
# text_input = browser.find_element(By.ID,"kw") #kw是搜索框的id名
text_input = browser.find_element(By.XPATH,'//*[@id="kw"]')
#向输入框中输入内容
text_input.send_keys("美女")
#按回车按钮
text_input.send_keys(Keys.ENTER)
#等待事件——会受网络的影响
wait = WebDriverWait(browser,10)#参数一:浏览器对象 参数二:最大等待的秒数
#等待的元素,如果该元素加载完毕则等待事件停止。如果超出时间还没加载出等待的元素,那么程序就会报错
wait.until(EC.presence_of_element_located((By.XPATH,'//*[@id="s_tab"]/div/b')))#选什么元素自己决定
print(browser.current_url)#看url
print(browser.get_cookies())#看cookie
print(browser.page_source)#看源代码
input()#让页面卡住,不至于自动关闭
finally:#无论是否发生异常都会执行的代码块
browser.close()#关闭浏览器
呈现效果:
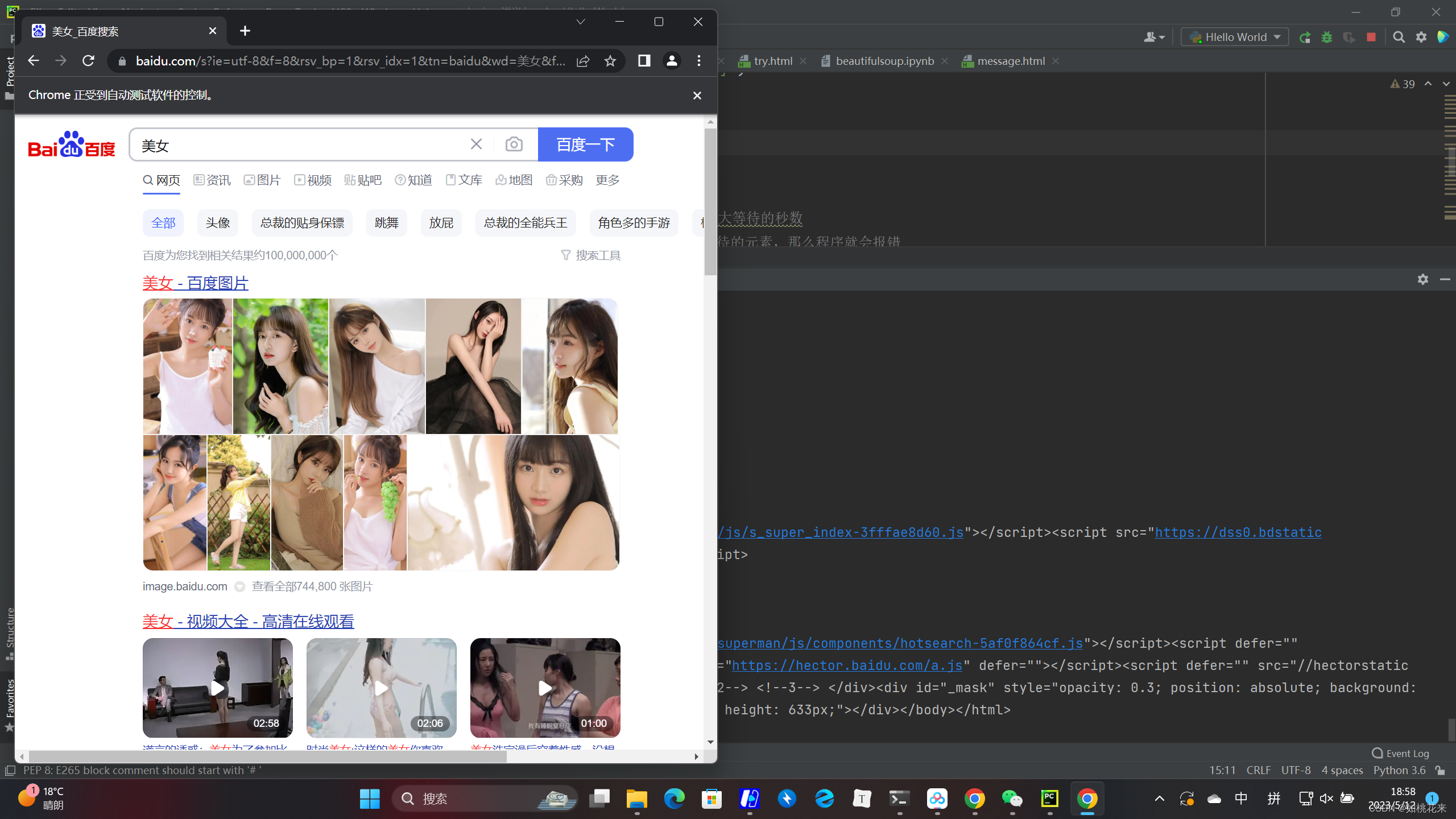
总结:
1. text_input.send_keys()可以用来输入内容和按下按钮
2. wait是和wait.until搭配使用的。一个设置等待,一个设置等待元素
3. wait = WebDriverWait(浏览器驱动对象,最长等待时间)
4. presence_of_element_located()方法中传入的参数格式一定是一个元组,别忘了!
5.
- browser.current_url 打印url
- browser.get_cookies() 打印cookie信息
- browser.page_source 查看源代码
声明不同浏览器对象:
selenium可以支持多种浏览器
from selenium import webdriver
browser = webdriver.Chrome()
browser = webdriver.Firefox()
browser = webdriver.Edge()
browser = webdriver.PhantomJS()
browser = webdriver.Safari()
访问页面:
一些最简洁的访问页面的代码
from selenium import webdriver
#声明Chrome浏览器对象
browser = webdriver.Chrome()
#请求页面,返回的数据封装在了browser对象里面,不需要用额外的变量接收
browser.get('https://www.taobao.com')
#获取网页源代码
print(browser.page_source)
#关闭当前网页
browser.close()








![[OGeek2019]babyrop](https://img-blog.csdnimg.cn/2f4703e4dfca47138774006e110dd46d.png)