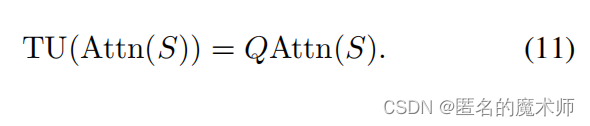BeautifulSoup库介绍
1、BeautifulSoup是Python中的一个第三方库,其最主要的功能是处理HTML文档
⑴查找HTML文档中的指定标签
⑵获取HTML文档中指定标签的标签名、标签值、标签属性等
⑶修改HTML文档中指定标签
2、BeautifulSoup库将HTML文档解析为一个对象,使用该对象方法能很方便的获取HTML文档中的数据
3、BeautifulSoup库也可以用来处理XML文档。这里主要介绍使用BeautifulSoup库来处理HTML文档
4、BeautifulSoup库的官方解释如下:
⑴BeautifulSoup提供一些简单的、Python式的函数用来处理导航、搜索、修改分析树等功能
①它是一个工具箱,通过解析文档为用户提供需要抓取的数据
⑵BeautifulSoup自动将输入文档转换为Unicode编码,输出文档转换为UTF-8编码,不需要考虑编码方式
①除非文档没有指定一个编码方式,这时,BeautifulSoup就不能自动识别编码方式了。此时仅需要说明一下原始编码方式就可以了
⑶BeautifulSoup已成为和lxml、html6lib一样出色的Python库,为用户灵活地提供不同的解析策略或强劲的速度
安装BeautifulSoup库
1、BeautifulSoup3目前已经停止开发,推荐在现在的项目中使用BeautifulSoup4
⑴另外,BeautifulSoup4已经被移植到BS4中了,因此导入库时需要from bs4 import BeautifulSoup
2、BeautifulSoup4通过PyPi发布,可以通过easy_install或pip来安装
⑴包的名字是beautifulsoup4。这个包兼容Python2和Python3
3、 安装命令:pip install BeautifulSoup4==4.0.1
⑴这里指定了安装版本
4、也可以从pypi下载whl文件来手动安装
安装解析器
1、BeautifulSoup库在解析HTML文档的时候实际上是需要依赖于解析器的
2、目前BeautifulSoup库除了支持Python标准库中的HTML解析器(html.parser),还支持一些第三方的解析器(如lxml)
3、Python中自带了HTML解析器(html.parser),另外也可以单独安装第三方解析器
⑴如果不安装第三方解析器,则会使用Python默认的解析器
⑵lxml解析器更加强大,速度更快,推荐安装:pip install lxml
4、下面对BeautifulSoup支持的解析器及它们的一些优缺点做一个简单的对比
BeautifulSoup库的使用
1、BeautifulSoup库将HTML文档解析为一个对象
⑴使用该对象下的方法就能很方便的获取HTML文档中的数据
2、因此在使用BeautifulSoup库处理HTML文档时首先需要将HTML文档转为对象
3、使用BeautifulSoup库来处理HTML文档时,首先需要实例化一个BeautifulSoup对象
⑴使用BeautifulSoup类的构造方法来实例化一个BeautifulSoup实例对象
⑵这里就跟我们自定义的类一样:
①使用类名来实例化一个实例对象
②类存在__init__方法时传入实例属性值
4、BeautifulSoup类的构造方法:
⑴类名:BeautifulSoup
⑵构造方法:def __init__(self, markup="", features=None, builder=None,parse_only=None, from_encoding=None, **kwargs)
5、参数介绍:
⑴markup:待解析的HTML字符串或文件句柄
⑵features:指定解析器
①默认值为None,表示使用Python默认的解析器
②如果手动指定了解析器,那么BeautifulSoup就使用指定的解析器来解析文档
⑶from_encoding:指定待解析的HTML字符串的编码
①默认值为None,表示默认编码为UTF-8
②当传入的HTML字符串为其他类型编码(非UTF-8和ASCII)时,需要指定相应的字符编码,BeautifulSoup才能正确解析
⑷其他参数不怎么用到,就不介绍了
通过字符串来创建对象
1、将一个字符串型的HTML数据传递给BeautifulSoup类名就可以得到一个BeautifulSoup对象
2、整个HTML数据转为BeautifulSoup对象后,该BeautifulSoup对象就拥有了HTML中的所有数据了
例1:
# 导入所需第三方库
from bs4 import BeautifulSoup
# 这里先用一个简单的HTML数据为例
htmlData = """<html>
<head>
<title>The Dormouse's story</title>
</head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>
</body>
</html>"""
# 通过类名来实例化一个BeautifulSoup对象,并指定解析器为lxml
soup = BeautifulSoup(htmlData, "lxml")
print("转换结果为:", soup)
print("转换结果的类型为:", type(soup))
"""
转换结果为: <html>
<head>
<title>The Dormouse's story</title>
</head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>
</body>
</html>
转换结果的类型为: <class 'bs4.BeautifulSoup'>
"""通过文件来创建对象
1、将一个文件句柄传递给BeautifulSoup类名就可以得到一个BeautifulSoup对象
2、整个HTML数据转为BeautifulSoup对象后,该BeautifulSoup对象就拥有了HTML中的所有数据了
例2:
from bs4 import BeautifulSoup
# 打开一个HTML文件并将文件内容转为BeautifulSoup对象
with open("F:\\testHtml.html", "r", encoding="utf-8") as htmlData:
# 这里只需要打开一个文件就可以了,并不需要使用read()等方法来读取文件内容在传递给BeautifulSoup方法
# BeautifulSoup方法接受一个字符串或文件句柄
soup = BeautifulSoup(htmlData, features="lxml")
print("转换结果为:", soup)
print("转换结果的类型为:", type(soup))
"""
转换结果为: <html>
<head>
<title>The Dormouse's story</title>
</head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>
</body>
</html>
转换结果的类型为: <class 'bs4.BeautifulSoup'>
"""注:
1、一般情况下都是先将整个HTML数据转为BeautifulSoup对象
⑴此时这个BeautifulSoup对象就拥有了HTML中的所有数据了
⑵因此可以使用BeautifulSoup对象下的方法来获取HTML中我们需要的数据
2、在BeautifulSoup()方法中感觉最好指定解析器(使用lxml解析器),不然有时候会报错
将BeautifulSoup对象转为字符串
1、在控制台打印bs4.BeautifulSoup对象时,虽然其看起来像一个字符串。但其实际不是字符串
⑴是不能对bs4.BeautifulSoup对象使用字符串方法的
2、可以使用str()或prettify()方法来将bs4.BeautifulSoup对象转为字符串
⑴str():强制将BeautifulSoup对象转为字符串
⑵prettify():以字符串的形式格式化输出HTML数据
例3:
# 导入所需第三方库
from bs4 import BeautifulSoup
# 这里先用一个简单的HTML数据为例
htmlData = """<html>
<head>
<title>The Dormouse's story</title>
</head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>
</body>
</html>"""
# 通过类名来实例化一个BeautifulSoup对象,并指定解析器为lxml
soup = BeautifulSoup(htmlData, "lxml")
print("转换结果的类型为:", type(soup))
# 格式化输出HTML数据
htmlPrettify = soup.prettify()
print("格式化输出HTML数据:", htmlPrettify)
print("格式化输出HTML数据的类型:", type(htmlPrettify))
"""
转换结果的类型为: <class 'bs4.BeautifulSoup'>
格式化输出HTML数据: <html>
<head>
<title>
The Dormouse's story
</title>
</head>
<body>
<p class="title">
<b>
The Dormouse's story
</b>
</p>
<a class="sister" href="http://example.com/tillie" id="link3">
Tillie
</a>
</body>
</html>
格式化输出HTML数据的类型: <class 'str'>
"""BeautifulSoup库中的四大对象种类
1、网页(HTML)是由许多、各种各样的标签组成
⑴将网页比作是人的话
①标签就是一个人的骨架,定义了一个人的基本结构
②CSS就是一个人的外观,比如头发、脸型、肤色等等。使得人更好看
③JS就是一个人的行为。让人动起来,能跑能跳等等
⑵标签:
①HTML标签是由尖括号包围的关键词,例如<html>
②HTML标签通常是成对出现的,例如<html>和</html>
③标签对中的第一个标签是开始标签,第二个标签是结束标签
⑶标签的常见格式:<标签名 属性1=属性值 属性2=属性值...>内容</标签名>
①标签名:在HTML语法中标签名是固定的,一种标签名代表一种网页元素
㈠比如<img>标签用于定义HTML页面中的图像
㈡标签名用于指明这是一个什么标签(具有什么功能)
②属性:标签属性,用于定义标签的各种属性。标签属性总是以键值对的形式出现(属性名=值)
㈠比如<img>标签width属性用于定义图像的宽度
㈡属性用于指明这个标签该怎么显示、显示在哪里
③内容:标签值,用于定义在网页上显示的内容
㈠内容用于指明这个标签显示什么文本(在网页上显示什么内容)
⑷标签之间具有层级关系,且标签之间可以相互嵌套
①标签嵌套会产生"祖先"和"后代", "父子标签"、"兄弟标签"的关系
②外层父元素,内层子元素
③平级元素之间互为兄弟元素
⑸具体的HTML语法这里就不介绍了,有兴趣的可以自己去了解下
2、HTML是一种分层数据格式,最自然的表示方法是使用树(树形结构)
⑴树形结构:从"根部"开始,然后扩展到"枝叶"
⑵HTML元素形成了一棵文档树。这棵树从根部开始,并扩展到树的最底端
3、BeautifulSoup会将HTML文档转换成一个复杂的树形结构
⑴在这个树形结构中,每个节点(标签)都是Python对象
4、在BeautifulSoup树形结构中,所有节点对象可以归纳为4种:
⑴BeautifulSoup对象:文档自身,表示一个HTML文档的全部内容
⑵Tag对象:标签,HTML中的任意一个标签都是一个Tag对象
⑶NavigableString对象:标签值,即标签对之间的值(数据)
⑷Comment对象:注释,HTML文档中的注释
BeautifulSoup对象
1、前面介绍了:可以使用BeautifulSoup类的构造方法来实例化一个BeautifulSoup对象
2、将整个HTML数据转为BeautifulSoup对象后,该BeautifulSoup对象就拥有了HTML中的所有数据了
⑴BeautifulSoup对象表示的是一个HTML文档的全部内容
3、大部分时候可以把BeautifulSoup对象当作特殊的Tag对象,是一个特殊的标签
⑴BeautifulSoup对象支持Tag对象的遍历和搜索中的大部分方法
⑵BeautifulSoup对象并不是真正的HTML或XML的Tag,所以它没有name和attribute属性(后面介绍)
4、Tag对象、Tag对象的遍历和搜索后面介绍。这里先知道就好了
⑴因为经常操作的是Tag对象,因此后续的话主要使用Tag对象来做介绍
Tag对象
1、解析一个HTML文档,最常见的就是为了获取某一个标签的属性或值(标签对之间的数据)
⑴因此在使用BeautifulSoup库时,最常见的就是操作一个Tag(标签)对象
2、Tag对象:即HTML或XML中的标签对
⑴Tag对象与XML或HTML原生文档中的tag相同
⑵可以简单的将Tag对象理解成任意一个标签
⑶一个完整的标签(Tag对象)包含了标签名、标签属性、标签内容
3、例如:<title>The Dormouse's story</title>或<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>
⑴上面的title、a标签加上里面包括的内容称为Tag对象
⑵Tag对象指的是整个标签对:从开始标签到结束标签,包括里面嵌套的标签
4、可以利用beautifulSoup对象下面的属性、方法返回指定的Tag对象(标签)
⑷获取到Tag对象后,可以使用Tag对象下面的属性、方法来获取标签对中的具体数据
获取Tag对象
1、属性:beautifulSoup对象.标签名
2、作用:从一个beautifulSoup对象中获取指定的Tag对象
⑴要获取哪个标签的Tag对象,就传入哪个标签的标签名
⑵不管待获取的标签在HTML文档中的哪个位置,都可以通过该属性来获取
3、返回值:返回beautifulSoup对象(HTML)中第一个符合要求的Tag对象(标签)
⑴当HTML中存在多个相同标签名的标签时也只会返回第一个符合的标签
例4:
from bs4 import BeautifulSoup # 导入bs4库
htmlData = """
<html>
<head>
<title>The Dormouse's story</title>
</head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">
<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>
</p>
<p class="story">they lived at the bottom of a well</p>
<ul class="nav nav-tabs">
<li><a href="/codeformat/xml">XML格式化</a></li>
<li><a href="/codeformat/css">CSS格式化</a></li>
<li><a href="/codeformat/json">JSON格式化</a></li>
<li><a href="/codeformat/js">JavaScript格式化</a></li>
<li><a href="/codeformat/java">Java格式化</a></li>
<li><a href="/codeformat/sql">SQL格式化</a></li>
</ul>
</body>
</html>
"""
# 将HTML文档转为BeautifulSoup对象
soup = BeautifulSoup(htmlData, "lxml")
# 获取header标签
headTag = soup.head
print("获取到的header标签为:", headTag)
# 获取title标签
titleTag = soup.title
print("获取到的title标签为:", titleTag)
# 获取p标签
pTag = soup.p
print("获取到的p标签为:", pTag)
# 获取a标签
aTag = soup.a
print("获取到的a标签为:", aTag)
print("获取到的a标签类型为:", type(aTag))
"""
获取到的header标签为: <head>
<title>The Dormouse's story</title>
</head>
获取到的title标签为: <title>The Dormouse's story</title>
获取到的p标签为: <p class="title"><b>The Dormouse's story</b></p>
获取到的a标签为: <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>
获取到的a标签类型为: <class 'bs4.element.Tag'>
"""注:
1、Tag对象指的是整个标签对:从开始标签到结束标签,包括里面嵌套的标签
2、Tag对象虽然其看起来像一个字符串。但其实际不是字符串
⑴是不能对Tag对象使用字符串方法的
2、可以使用str()或prettify()方法来将Tag对象转为字符串
⑴str():强制将BeautifulSoup对象转为字符串
⑵prettify():以字符串的形式格式化输出HTML数据
例5:
from bs4 import BeautifulSoup # 导入bs4库
htmlData = """
<html>
<head>
<title>The Dormouse's story</title>
</head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
</body>
</html>
"""
# 将HTML文档转为BeautifulSoup对象
soup = BeautifulSoup(htmlData, "lxml")
# 获取header标签
headTag = soup.head
print("将Tag对象转为字符串:", str(headTag))
print("将Tag对象转为字符串:", headTag.prettify())
print("将Tag对象转为字符串的类型:", type(headTag.prettify()))
"""
将Tag对象转为字符串: <head>
<title>The Dormouse's story</title>
</head>
将Tag对象转为字符串: <head>
<title>
The Dormouse's story
</title>
</head>
将Tag对象转为字符串的类型: <class 'str'>
"""
Tag对象的name属性
1、每个Tag都有自己的名字(标签名),可以通过Tag对象的name属性来获取标签的名字
⑴对于BeautifulSoup对象来说:其本身比较特殊,它的name属性为[document]
2、属性:Tag对象.name
3、返回值:以字符串的形式返回标签的名字
例6:
from bs4 import BeautifulSoup # 导入bs4库
htmlData = """
<html>
<head>
<title>The Dormouse's story</title>
</head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>
</body>
</html>
"""
# 将HTML文档转为BeautifulSoup对象
soup = BeautifulSoup(htmlData, "lxml")
# 获取p标签
pTag = soup.p
pName = pTag.name
print("获取到的p标签为:", pTag)
print("获取到的p标签的标签名为:", pName)
# 获取a标签
aTag = soup.a
print("获取到的a标签为:", aTag)
print("获取到的a标签的标签名为:", aTag.name)
print("获取到的a标签的标签名的类型为:", type(aTag.name))
"""
获取到的p标签为: <p class="title"><b>The Dormouse's story</b></p>
获取到的p标签的标签名为: p
获取到的a标签为: <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>
获取到的a标签的标签名为: a
获取到的a标签的标签名的类型为: <class 'str'>
"""Tag对象的attrs属性
1、在HTML或XML中标签是可以拥有属性的:可以没有属性、可以有一个属性、可以多个属性
⑴标签属性位于开始标签中
⑵标签属性一般是由键值对组成:属性名=值
2、<blockquote class="boldest">Extremely bold</blockquote>,其中的'class="boldest"'就是标签的属性
3、属性:Tag对象.attrs
4、返回值:以字典的形式返回标签中的所有属性
⑴Tag对象无属性时返回的是一个空字典
例7:
from bs4 import BeautifulSoup # 导入bs4库
htmlData = """
<html>
<head>
<title>The Dormouse's story</title>
</head>
<body>
<p class="body strikeout"><b>The Dormouse's story</b></p>
<a class="sister" href="http://example.com/elsie" id="my link1">Elsie</a>
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>
</body>
</html>
"""
# 将HTML文档转为BeautifulSoup对象
soup = BeautifulSoup(htmlData, "lxml")
# 获取p标签
pTag = soup.p
pAttrs = pTag.attrs
print("获取到的p标签为:", pTag)
print("获取到的p标签的属性为:", pAttrs)
# 获取a标签
aTag = soup.a
print("获取到的a标签为:", aTag)
print("获取到的a标签的属性为:", aTag.attrs)
print("获取到的a标签的属性的类型为:", type(aTag.attrs))
"""
获取到的p标签为: <p class="body strikeout"><b>The Dormouse's story</b></p>
获取到的p标签的属性为: {'class': ['body', 'strikeout']}
获取到的a标签为: <a class="sister" href="http://example.com/elsie" id="my link1">Elsie</a>
获取到的a标签的属性为: {'class': ['sister'], 'href': 'http://example.com/elsie', 'id': 'my link1'}
获取到的a标签的属性的类型为: <class 'dict'>
"""注:
1、HTML4定义了一系列可以包含多个值的属性,最常见的多值属性是class
⑴多值属性:属性的值可以存在多个,多个值以空格分割
⑵在获取Tag对象的属性时,当属性名是多值属性时,BeautifulSoup返回的属性值类型是list
⑶属性名为键,多值属性的所有值组合成一个列表
2、如果某个属性看起来好像有多个值,但在任何版本的HTML定义中都没有被定义为多值属性
⑴那么BeautifulSoup会将这个属性作为字符串返回。此时就是普通的单值属性了
3、如果转换的文档是XML格式,那么Tag中不包含多值属性
⑴即属性的多个值会当做一个值以字符串的形式返回(XML中不存在多值属性)
4、如果想要单独获取某个属性具体的值时,可以使用下面三种方法:
⑴Tag对象的attrs属性返回的是一个字典,因此可以使用字典方法
①字典索引:字典对象["键名"]
②字典get():字典对象.get("键名")
⑵使用Tag对象的get()方法:soup对象.标签名.get(属性名)
⑶使用soup对象.标签名[属性名]
例8:
from bs4 import BeautifulSoup
# 单独的一个标签也是可以构造为BeautifulSoup对象的
html = """<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>"""
soup = BeautifulSoup(html, "lxml")
aTagAttrs = soup.a.attrs
print("a标签的tag对象的属性为:", aTagAttrs)
print("a标签的tag对象的属性类型为:", type(aTagAttrs))
# 使用字典方法:字典对象["键名"]
getAttrsFromIndex = aTagAttrs["href"]
print("通过字典索引获取到的tag对象的属性", getAttrsFromIndex)
# 使用字典方法:字典对象.get("键名")
getAttrsFromGet = aTagAttrs.get("href")
print("通过字典索引获取到的tag对象的属性", getAttrsFromGet)
# 使用Tag对象的get()方法:soup对象.标签名.get(属性名)
getAttrsFromTagGet = soup.a.get("href")
print("使用Tag对象的get()方法:", getAttrsFromTagGet)
# 使用soup对象.标签名[属性名]
getAttrsFromTag = soup.a["href"]
print("使用soup对象.标签名[属性名]:", getAttrsFromTag)
"""
a标签的tag对象的属性为: {'href': 'http://example.com/tillie', 'class': ['sister'], 'id': 'link3'}
a标签的tag对象的属性类型为: <class 'dict'>
通过字典索引获取到的tag对象的属性 http://example.com/tillie
通过字典索引获取到的tag对象的属性 http://example.com/tillie
使用Tag对象的get()方法: http://example.com/tillie
使用soup对象.标签名[属性名]: http://example.com/tillie
"""例9:
from bs4 import BeautifulSoup
# 如果转换的文档是XML格式,那么tag中不包含多值属性
# 如果解析的是XML文档,那么最好指定解析器为xml
xmlSoup = BeautifulSoup('<p class="body strikeout"></p>', 'xml')
print(xmlSoup.p['class'])
# body strikeoutNavigableString对象
1、标签中可以存在属性、标签内容(值)。也可不存在属性、标签内容
⑴当标签不存在内容时,该标签被叫做空标签
⑵空标签可以只有开始标签,无结束标签
2、BeautifulSoup库中的NavigableString对象指的就是标签内容(值)
⑴BeautifulSoup用NavigableString类来包装Tag中的字符串内容
⑵NavigableString对象开始标签与结束标签之间的数据
3、属性:Tag对象.string
4、作用:返回一个Tag对象中的数据(标签对之间的数据)
5、返回值:当标签对之间存在数据时返回对应数据的NavigableString对象
⑴当为空标签(标签对之间无数据)时,返回None
例10:
from bs4 import BeautifulSoup
html = """<html>
<head>
<title>The Dormouse's story</title>
</head>
<body>
<a class="story"/>
<p class="story">they lived at the bottom of a well</p>
</body>
</html>
"""
soup = BeautifulSoup(html, "lxml")
aTag = soup.a
print("a标签的tag对象为:", aTag)
print("a标签的tag对象的类型为:", type(aTag))
print("a标签对之间的数据为:", aTag.string)
# 获取标签对之间的数据:Tag对象.string
pTagContent = soup.p.string
print("p标签对之间的数据为:", pTagContent)
print("p标签对之间的数据的类型为:", type(pTagContent))
"""
a标签的tag对象为: <a class="story"></a>
a标签的tag对象的类型为: <class 'bs4.element.Tag'>
a标签对之间的数据为: None
p标签对之间的数据为: they lived at the bottom of a well
p标签对之间的数据的类型为: <class 'bs4.element.NavigableString'>
"""注:
1、NavigableString对象虽然其看起来像一个字符串。但其实际不是字符串
⑴是不能对NavigableString对象使用字符串方法的
2、可以使用str()方法将NavigableString对象转为字符串
例11:
from bs4 import BeautifulSoup
html = """<p class="story">they lived at the bottom of a well</p> """
soup = BeautifulSoup(html, "lxml")
# 获取标签对之间的数据:Tag对象.string
pTagContent = soup.p.string
print("p标签对之间的数据为:", pTagContent)
print("p标签对之间的数据的类型为:", type(pTagContent))
# 将NavigableString对象转为字符串
stringContent = str(pTagContent)
print("将NavigableString对象转为字符串:", stringContent)
print("将NavigableString对象转为字符串的类型:", type(stringContent))
"""
p标签对之间的数据为: they lived at the bottom of a well
p标签对之间的数据的类型为: <class 'bs4.element.NavigableString'>
将NavigableString对象转为字符串: they lived at the bottom of a well
将NavigableString对象转为字符串的类型: <class 'str'>
"""Comment对象
1、HTML是由许多、可以重复的标签组成
⑴在标签之间可以存在:标签属性、标签内容
⑵除此之外标签对之间还可以存在注释
2、Tag对象、NavigableString对象、BeautifulSoup对象几乎覆盖了HTML和XML中的所有内容
⑴除此之外还有一些特殊对象,比如文档的注释部分:Comment对象
例12:
from bs4 import BeautifulSoup
# HTML中的注释符号<!--注释的内容-->
html = """<p><!--Hey, buddy. Want to buy a used parser?--></p> """
soup = BeautifulSoup(html, "lxml")
# 获取标签对之间的数据:Tag对象.string
pTagContent = soup.p.string
print("p标签对之间的数据为:", pTagContent)
print("p标签对之间的数据的类型为:", type(pTagContent))
# 将NavigableString对象转为字符串
stringContent = str(pTagContent)
print("将NavigableString对象转为字符串:", stringContent)
print("将NavigableString对象转为字符串的类型:", type(stringContent))
"""
p标签对之间的数据为: Hey, buddy. Want to buy a used parser?
p标签对之间的数据的类型为: <class 'bs4.element.Comment'>
将NavigableString对象转为字符串: Hey, buddy. Want to buy a used parser?
将NavigableString对象转为字符串的类型: <class 'str'>
"""注:
1、Comment对象是一个特殊类型的NavigableString对象
2、当使用"Tag对象.string"属性来输出Comment对象时,其输出的内容是不包括注释符号的
⑴ 就输出而言Comment对象和NavigableString对象时没有区别的
3、前面介绍了BeautifulSoup库中的四大对象:这些对象在源代码中分别对应着4个类
4、因此在使用"Tag对象.string"属性来输出标签内容时,最好判断返回的对象类型
例13:
# 导入所需的类:直接定位到类名
from bs4 import BeautifulSoup
from bs4.element import NavigableString
from bs4.element import Tag
from bs4.element import Comment
# HTML中的注释符号<!--注释的内容-->
html = """<p>Hey, buddy. Want to buy a used parser?</p> """
soup = BeautifulSoup(html, "lxml")
# 获取标签内容
tagContent = soup.p.string
# 判断标签对象的string属性返回的数据类型
if type(tagContent) == NavigableString:
print("为真实的标签内容:", str(tagContent))
else:
print("为注释类标签内容:", str(tagContent))
# 为真实的标签内容: Hey, buddy. Want to buy a used parser?例14:
# 导入所需的类:直接定位到类名
from bs4 import BeautifulSoup
from bs4.element import NavigableString
from bs4.element import Tag
# 这里导入到模块名
from bs4 import element
# HTML中的注释符号<!--注释的内容-->
html = """<p><!--Hey, buddy. Want to buy a used parser?--></p> """
soup = BeautifulSoup(html, "lxml")
# 获取标签内容
tagContent = soup.p.string
#判断标签对象的string属性返回的数据类型
if type(tagContent) == element.Comment:
print("为注释类标签内容:", str(tagContent))
else:
print("为真实的标签内容:", str(tagContent))
# 为注释类标签内容: Hey, buddy. Want to buy a used parser?注:
1、感觉解析过程就是:soup对象->Tag对象->通过tag对象的name、attrs、string属性来获取想要的数据
2、只要是一个Tag对象,就可以使用name、attrs、string属性
拓展
使用BeautifulSoup解析XML
1、使用BeautifulSoup同样能解析XML文档,解析XML文档的方法、步骤与解析HTML文档一样
2、只是说在解析XML文档时最好指定解析器为"xml"
3、这里先提前使用了下BeautifulSoup库中的find_all()和find()方法
⑴这两个方法的具体使用后面介绍
例15:
from bs4 import BeautifulSoup
html = """
<?xml version="1.0" encoding="utf-8"?>
<data>
<time>20200706</time>
<country name="Liechtenstein">
<rank>1</rank>
<year type="year">2008</year>
<year type="month" date="week">11</year>
<gdppc>141100</gdppc>
<neighbor name="Austria" direction="E"/>
</country>
</data>
"""
# 使用xml解析器,将一个文件或字符串转为BeautifulSoup对象
soup = BeautifulSoup(html, 'xml')
# print(type(soup)) #返回一个<class 'bs4.BeautifulSoup'>
# print(soup.prettify()) #格式化输出HTML文件
# find_all()方法返回文档中全部的year标签组成的列表
tagYear = soup.find_all("year")
print("year标签对有:", tagYear)
for i in tagYear:
print("返回的标签类型为:", type(i)) # 返回的是一个字符串型的Tag对象,可以直接使用str()方法进行强转换
print(i.name) # 通过Tag对象的name属性来获得标签的名字
print(i.attrs) # 通过Tag对象的attrs属性来获得标签的属性(为属性名与属性值组成的字典)
print(i.string) # 通过Tag对象的string属性来获得标签对中的数据(值)
"""
year标签对有: [<year type="year">2008</year>, <year date="week" type="month">11</year>]
返回的标签类型为: <class 'bs4.element.Tag'>
year
{'type': 'year'}
2008
返回的标签类型为: <class 'bs4.element.Tag'>
year
{'type': 'month', 'date': 'week'}
11
"""例16:
from bs4 import BeautifulSoup
"""
解析目标:将标签名及其数据组成字典
[{标签名:值},{标签名:值}]
"""
msg = """<?xml version="1.0" encoding="utf-8"?>
<breakfast_menu>
<food>
<name>Belgian Waffles</name>
<price>$5.95</price>
<description>two of our famous Belgian Waffles with plenty of real maple syrup</description>
<calories>650</calories>
</food>
<food>
<name>Strawberry Belgian Waffles</name>
<price>$7.95</price>
<description>light Belgian waffles covered with strawberries and whipped cream</description>
<calories/>
</food>
</breakfast_menu>
"""
def parseMsg(msg):
soup = BeautifulSoup(msg, 'xml')
# 通过xml可以看到,我们需要的数据都在"food"标签下面,且"food"标签可以存在一个或多个,
# 因此可以先找到"food"标签,然后依次根据"food"标签来找其下面的子标签
foods = soup.find_all("food")
foodInfoList = []
for food in foods:
# 获取所需标签值
# food标签下name标签不会存在多个,因此使用find()方法比较方便,这里只是演示下find_all()方法
foodName = food.find_all("name")[0].string
foodPrice = food.find("price").string
foodCalories = food.find("calories").string
foodInfo = {"name": foodName, "price": foodPrice, "calories": foodCalories}
foodInfoList.append(foodInfo)
return foodInfoList
foodInfoList = parseMsg(msg)
print(foodInfoList)
"""
[{'name': 'Belgian Waffles', 'price': '$5.95', 'calories': '650'},
{'name': 'Strawberry Belgian Waffles', 'price': '$7.95', 'calories': None}]
这里是找"标签名:值",也可以用同样的方法来找"标签名:属性值"等等
"""注:
1、注:本文是在按照Beautiful Soup 4.2.0 文档学习时记录的
⑴只是为了方便自己以后学习和搜索的,文章中肯定会有错误或者遗漏的
⑵因此如果有幸被您看到,可以直接参考其官方文档:
2、https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html#string