提示:本博客作为学习笔记,有错误的地方希望指正,主要参考乐鑫技术手册说明结合实例代码分析,结合理论知识学习后示例分析以及常见问题说明。
文章目录
- 一、ESP32 Partition概述
- 二、内置分区表
- 三、创建自定义分区表
- 四、生成二进制分区表
- 五、分区大小检查
- 六、MD5 校验和
- 七、烧写分区表
- 八、分区工具 (parttool.py)
一、ESP32 Partition概述
参考资料:ESP IDF编程手册V5.0.1
每片 ESP32 的 flash 可以包含多个应用程序,以及多种不同类型的数据(例如校准数据、文件系统数据、参数存储数据等)。因此,我们在 flash 的 默认偏移地址 0x8000 处烧写一张分区表。
分区表的长度为 0xC00 字节,最多可以保存 95 条分区表条目。MD5 校验和附加在分区表之后,用于在运行时验证分区表的完整性。分区表占据了整个 flash 扇区,大小为 0x1000 (4 KB)。因此,它后面的任何分区至少需要位于 (默认偏移地址) + 0x1000 处。
分区表中的每个条目都包括以下几个部分:Name(标签)、Type(app、data 等)、SubType 以及在 flash 中的偏移量(分区的加载地址)。
在使用分区表时,最简单的方法就是打开项目配置菜单(idf.py menuconfig),并在 CONFIG_PARTITION_TABLE_TYPE 下选择一个预定义的分区表:
- “Single factory app, no OTA”
- “Factory app, two OTA definitions”
在以上两种选项中,出厂应用程序均将被烧录至 flash 的 0x10000 偏移地址处。这时,运行 idf.py partition-table ,即可以打印当前使用分区表的信息摘要。
二、内置分区表
以下是 “Single factory app, no OTA” 选项的分区表信息摘要:
# ESP-IDF Partition Table
# Name, Type, SubType, Offset, Size, Flags
nvs, data, nvs, 0x9000, 0x6000,
phy_init, data, phy, 0xf000, 0x1000,
factory, app, factory, 0x10000, 1M,
- flash 的 0x10000 (64 KB) 偏移地址处存放一个标记为 “factory” 的二进制应用程序,且启动加载器将默认加载这个应用程序。
- 分区表中还定义了两个数据区域,分别用于存储 NVS 库专用分区和 PHY 初始化数据。
以下是 “Factory app, two OTA definitions” 选项的分区表信息摘要:
# ESP-IDF Partition Table
# Name, Type, SubType, Offset, Size, Flags
nvs, data, nvs, 0x9000, 0x4000,
otadata, data, ota, 0xd000, 0x2000,
phy_init, data, phy, 0xf000, 0x1000,
factory, app, factory, 0x10000, 1M,
ota_0, app, ota_0, 0x110000, 1M,
ota_1, app, ota_1, 0x210000, 1M,
分区表中定义了三个应用程序分区,这三个分区的类型都被设置为 “app”,但具体 app 类型不同。其中,位于 0x10000 偏移地址处的为出厂应用程序(factory),其余两个为 OTA 应用程序(ota_0,ota_1)。
新增了一个名为 “otadata” 的数据分区,用于保存 OTA 升级时需要的数据。启动加载器会查询该分区的数据,以判断该从哪个 OTA 应用程序分区加载程序。如果 “otadata” 分区为空,则会执行出厂程序。
我们在编译的时候只要有WI-FI或者蓝牙以及一些其他稍微大点的文件就会出现编译报错,提示内存不足的问题,这个时候我们可以通过配置分区表来解决编译出现内存不足的问题。下面操作是在 Vscode IDF插件中的操作。

三、创建自定义分区表
如果在 menuconfig 中选择了 “Custom partition table CSV”,则还需要输入该分区表的 CSV 文件在项目中的路径。CSV 文件可以根据需要,描述任意数量的分区信息。
CSV 文件的格式与上面摘要中打印的格式相同,但是在 CSV 文件中并非所有字段都是必需的。例如下面是一个自定义的 OTA 分区表的 CSV 文件:
# Name, Type, SubType, Offset, Size, Flags
nvs, data, nvs, 0x9000, 0x4000
otadata, data, ota, 0xd000, 0x2000
phy_init, data, phy, 0xf000, 0x1000
factory, app, factory, 0x10000, 1M
ota_0, app, ota_0, , 1M
ota_1, app, ota_1, , 1M
nvs_key, data, nvs_keys, , 0x1000
- 字段之间的空格会被忽略,任何以 # 开头的行(注释)也会被忽略。
- CSV 文件中的每个非注释行均为一个分区定义。
- 每个分区的 Offset 字段可以为空,gen_esp32part.py 工具会从分区表位置的后面开始自动计算并填充该分区的偏移地址,同时确保每个分区的偏移地址正确对齐。
Name 字段
Name 字段可以是任何有意义的名称,但不能超过 16 个字符(之后的内容将被截断)。该字段对 ESP32 并不是特别重要。
Type 字段
Type 字段可以指定为 app (0x00) 或者 data (0x01),也可以直接使用数字 0-254(或者十六进制 0x00-0xFE),注意,0x00-0x3F 不得使用(预留给 esp-idf 的核心功能)。
如果您的应用程序需要以 ESP-IDF 尚未支持的格式存储数据,请在 0x40-0xFE 内添加一个自定义分区类型。
参考 esp_partition_type_t 关于 app和 data 分区的枚举定义。
如果用 C++ 编写,那么指定一个应用程序定义的分区类型,需要在 esp_partition_type_t 中使用整数,从而与 分区 API 一起使用。例如:
static const esp_partition_type_t APP_PARTITION_TYPE_A = (esp_partition_type_t)0x40;
注意,启动加载器将忽略 app (0x00) 和 data (0x01) 以外的其他分区类型。
SubType 字段
SubType 字段长度为 8 bit,内容与具体分区 Type 有关。目前,esp-idf 仅仅规定了 “app” 和 “data” 两种分区类型的子类型含义。
参考 esp_partition_subtype_t,以了解 ESP-IDF 定义的全部子类型列表,包括:
- 当 Type 定义为 app 时,SubType 字段可以指定为 factory (0x00)、 ota_0 (0x10) … ota_15 (0x1F) 或者 test (0x20)。
1、factory (0x00) 是默认的 app 分区。启动加载器将默认加载该应用程序。但如果存在类型为 data/ota 分区,则启动加载器将加载 data/ota 分区中的数据,进而判断启动哪个 OTA 镜像文件。
OTA 升级永远都不会更新 factory 分区中的内容。
如果您希望在 OTA 项目中预留更多 flash,可以删除 factory 分区,转而使用 ota_0 分区。
2、ota_0 (0x10) … ota_15 (0x1F) 为 OTA 应用程序分区,启动加载器将根据 OTA 数据分区中的数据来决定加载哪个 OTA 应用程序分区中的程序。在使用 OTA 功能时,应用程序应至少拥有 2 个 OTA 应用程序分区(ota_0 和 ota_1)。更多详细信息,请参考 OTA 文档 。
3、test (0x20) 为预留的子类型,用于工厂测试流程。如果没有其他有效 app 分区,test 将作为备选启动分区使用。也可以配置启动加载器在每次启动时读取 GPIO,如果 GPIO 被拉低则启动该分区。详细信息请查阅 从测试固件启动。 - 当 Type 定义为 data 时,SubType 字段可以指定为 ota (0x00)、phy (0x01)、nvs (0x02)、nvs_keys (0x04) 或者其他组件特定的子类型(请参考 子类型枚举).
1、ota (0) 即 OTA 数据分区 ,用于存储当前所选的 OTA 应用程序的信息。这个分区的大小需要设定为 0x2000。更多详细信息,请参考 OTA 文档 。
2、phy (1) 分区用于存放 PHY 初始化数据,从而保证可以为每个设备单独配置 PHY,而非必须采用固件中的统一 PHY 初始化数据。
默认配置下,phy 分区并不启用,而是直接将 phy 初始化数据编译至应用程序中,从而节省分区表空间(直接将此分区删掉)。
如果需要从此分区加载 phy 初始化数据,请打开项目配置菜单(idf.py menuconfig),并且使能 CONFIG_ESP_PHY_INIT_DATA_IN_PARTITION 选项。此时,您还需要手动将 phy 初始化数据烧至设备 flash(esp-idf 编译系统并不会自动完成该操作)。
3、nvs (2) 是专门给 非易失性存储 (NVS) API 使用的分区。
用于存储每台设备的 PHY 校准数据(注意,并不是 PHY 初始化数据)。
用于存储 Wi-Fi 数据(如果使用了 esp_wifi_set_storage(WIFI_STORAGE_FLASH) 初始化函数)。
NVS API 还可以用于其他应用程序数据。
强烈建议您应为 NVS 分区分配至少 0x3000 字节空间。
如果使用 NVS API 存储大量数据,请增加 NVS 分区的大小(默认是 0x6000 字节)。
4、nvs_keys (4) 是 NVS 秘钥分区。详细信息,请参考 非易失性存储 (NVS) API 文档。
用于存储加密密钥(如果启用了 NVS 加密 功能)。
此分区应至少设定为 4096 字节。
5、ESP-IDF 还支持其它预定义的子类型用于数据存储,包括 FAT 文件系统 (ESP_PARTITION_SUBTYPE_DATA_FAT), SPIFFS (ESP_PARTITION_SUBTYPE_DATA_SPIFFS) 等。
其它数据子类型已预留给 esp-idf 未来使用。 - 如果分区类型是由应用程序定义的任意值(0x40-0xFE),那么 subtype 字段可以是由应用程序选择的任何值(0x00-0xFE)。
请注意如果用 C++ 编写,应用程序定义的子类型值需要转换为 esp_partition_type_t,从而与 分区 API 一起使用。
Offset 和 Size 字段
分区若偏移地址为空,则会紧跟着前一个分区之后开始;若为首个分区,则将紧跟着分区表开始。
app 分区的偏移地址必须要与 0x10000 (64K) 对齐,如果将偏移字段留空,gen_esp32part.py 工具会自动计算得到一个满足对齐要求的偏移地址。如果 app 分区的偏移地址没有与 0x10000 (64K) 对齐,则该工具会报错。
app 分区的大小和偏移地址可以采用十进制数、以 0x 为前缀的十六进制数,且支持 K 或 M 的倍数单位(分别代表 1024 和 1024*1024 字节)。
如果您希望允许分区表中的分区采用任意起始偏移量 (CONFIG_PARTITION_TABLE_OFFSET),请将分区表(CSV 文件)中所有分区的偏移字段都留空。注意,此时,如果您更改了分区表中任意分区的偏移地址,则其他分区的偏移地址也会跟着改变。这种情况下,如果您之前还曾设定某个分区采用固定偏移地址,则可能造成分区表冲突,从而导致报错。
Flags 字段
当前仅支持 encrypted 标记。如果 Flags 字段设置为 encrypted,且已启用 Flash 加密 功能,则该分区将会被加密。
备注:
app 分区始终会被加密,不管 Flags 字段是否设置。
当我们需要制作我们自己自定义分区表的时候,我们可以在menuconfig中partition中设置为用户 Custom partition table.CVS,操作如下
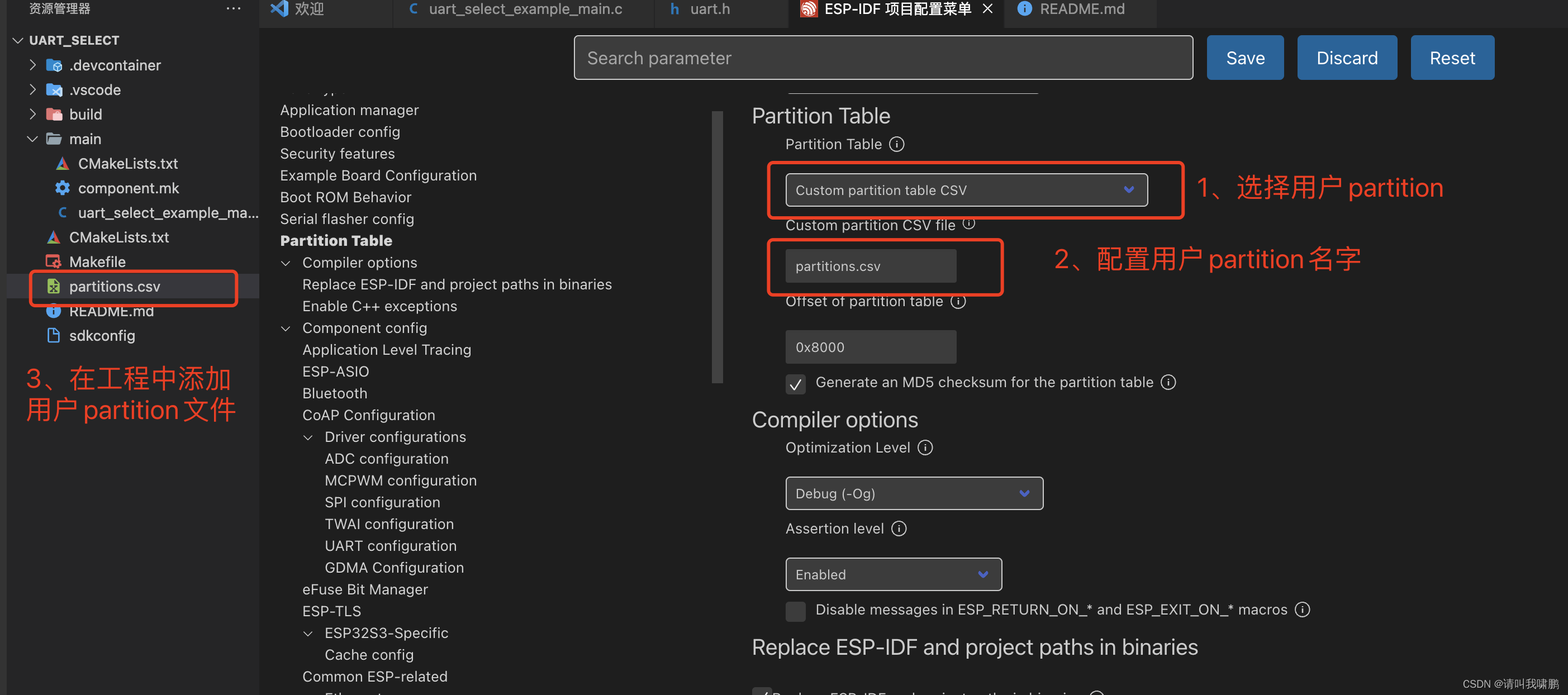
对于partition.cvs文件中的内容可以复制上述中的参考,另外IDF插件也可以辅助帮助我们自定义自己的partition。
四、生成二进制分区表
烧写到 ESP32 中的分区表采用二进制格式,而不是 CSV 文件本身。此时,partition_table/gen_esp32part.py 工具可以实现 CSV 和二进制文件之间的转换。
如果您在项目配置菜单(idf.py menuconfig)中设置了分区表 CSV 文件的名称,然后构建项目或执行 idf.py partition-table。这时,转换将在编译过程中自动完成。
手动将 CSV 文件转换为二进制文件:
python gen_esp32part.py input_partitions.csv binary_partitions.bin
手动将二进制文件转换为 CSV 文件:
python gen_esp32part.py binary_partitions.bin input_partitions.csv
在标准输出(stdout)上,打印二进制分区表的内容(运行 idf.py partition-table 时展示的信息摘要也是这样生成的):
python gen_esp32part.py binary_partitions.bin
另外当我们配置好分区表后保存编译,IDF会自动将我们的partition table编译成一个bin文档,我们可以在Build下面可以找到。
五、分区大小检查
ESP-IDF 构建系统将自动检查生成的二进制文件大小与可用的分区大小是否匹配,如果二进制文件太大,则会构建失败并报错。
目前会对以下二进制文件进行检查:
- 引导加载程序的二进制文件的大小要适合分区表前的区域大小(分区表前的区域都分配给了引导加载程序),具体请参考 引导加载程序大小。
- 应用程序二进制文件应至少适合一个 “app” 类型的分区。如果不适合任何应用程序分区,则会构建失败。如果只适合某些应用程序分区,则会打印相关警告。
备注:
即使分区大小检查返回错误并导致构建失败,仍然会生成可以烧录的二进制文件(它们对于可用空间来说过大,因此无法正常工作)。
六、MD5 校验和
二进制格式的分区表中含有一个 MD5 校验和。这个 MD5 校验和是根据分区表内容计算的,可在设备启动阶段,用于验证分区表的完整性。
用户可通过 gen_esp32part.py 的 --disable-md5sum 选项或者 CONFIG_PARTITION_TABLE_MD5 选项关闭 MD5 校验。对于 ESP-IDF v3.1 版本前的引导加载程序,因为它不支持 MD5 校验,所以无法正常启动并报错 invalid magic number 0xebeb,此时用户可以使用此选项关闭 MD5 校验。
七、烧写分区表
- idf.py partition-table-flash :使用 esptool.py 工具烧写分区表。
- idf.py flash :会烧写所有内容,包括分区表。
在执行 idf.py partition-table 命令时,手动烧写分区表的命令也将打印
备注:
分区表的更新并不会擦除根据旧分区表存储的数据。此时,您可以使用 idf.py erase-flash 命令或者 esptool.py erase_flash 命令来擦除 flash 中的所有内容。
八、分区工具 (parttool.py)
partition_table 组件中有分区工具 parttool.py,可以在目标设备上完成分区相关操作。该工具有如下用途:
- 读取分区,将内容存储到文件中 (read_partition)
- 将文件中的内容写至分区 (write_partition)
- 擦除分区 (erase_partition)
- 检索特定分区的名称、偏移、大小和 flag(“加密”) 标志等信息 (get_partition_info)
用户若想通过编程方式完成相关操作,可从另一个 Python 脚本导入并使用分区工具,或者从 Shell 脚本调用分区工具。前者可使用工具的 Python API,后者可使用命令行界面。
Python API
首先请确保已导入 parttool 模块
import sys
import os
idf_path = os.environ["IDF_PATH"] # 从环境中获取 IDF_PATH 的值
parttool_dir = os.path.join(idf_path, "components", "partition_table") # parttool.py 位于 $IDF_PATH/components/partition_table 下
sys.path.append(parttool_dir) # 使能 Python 寻找 parttool 模块
from parttool import * # 导入 parttool 模块内的所有名称
要使用分区工具的 Python API,第一步是创建 ParttoolTarget:
# 创建 partool.py 的目标设备,并将目标设备连接到串行端口 /dev/ttyUSB1
target = ParttoolTarget("/dev/ttyUSB1")
现在,可使用创建的 ParttoolTarget 在目标设备上完成操作:
# 擦除名为 'storage' 的分区
target.erase_partition(PartitionName("storage"))
# 读取类型为 'data'、子类型为 'spiffs' 的分区,保存至文件 'spiffs.bin'
target.read_partition(PartitionType("data", "spiffs"), "spiffs.bin")
# 将 'factory.bin' 文件的内容写至 'factory' 分区
target.write_partition(PartitionName("factory"), "factory.bin")
# 打印默认启动分区的大小
storage = target.get_partition_info(PARTITION_BOOT_DEFAULT)
print(storage.size)
使用 PartitionName、PartitionType 或 PARTITION_BOOT_DEFAULT 指定要操作的分区。顾名思义,这三个参数可以指向拥有特定名称的分区、特定类型和子类型的分区或默认启动分区。
更多关于 Python API 的信息,请查看分区工具的代码注释。
命令行界面
parttool.py 的命令行界面具有如下结构:
parttool.py [command-args] [subcommand] [subcommand-args]
- command-args - 执行主命令 (parttool.py) 所需的实际参数,多与目标设备有关
- subcommand - 要执行的操作
- subcommand-args - 所选操作的实际参数
# 擦除名为 'storage' 的分区
parttool.py --port "/dev/ttyUSB1" erase_partition --partition-name=storage
# 读取类型为 'data'、子类型为 'spiffs' 的分区,保存到 'spiffs.bin' 文件
parttool.py --port "/dev/ttyUSB1" read_partition --partition-type=data --partition-subtype=spiffs --output "spiffs.bin"
# 将 'factory.bin' 文件中的内容写入到 'factory' 分区
parttool.py --port "/dev/ttyUSB1" write_partition --partition-name=factory --input "factory.bin"
# 打印默认启动分区的大小
parttool.py --port "/dev/ttyUSB1" get_partition_info --partition-boot-default --info size
更多信息可用 –help 指令查看:
# 显示可用的子命令和主命令描述
parttool.py --help
# 显示子命令的描述
parttool.py [subcommand] --help