Mysql相关的各种类型文件
- 文件大汇总
- Mysql数据库自身文件
- 参数文件
- 日志文件
- 错误日志
- 慢查询日志
- 常用参数设置
- 慢查询日志文件
- 慢查询表
- 更换引擎
- 通用日志
- 二进制日志
- 套接字文件
- pid文件
- 表结构定义文件
- Innodb存储引擎的文件
- 表空间文件
- redo日志
文件大汇总
Mysql和Innodb启动和运行过程中涉及到了一堆文件,这些文件主要有:
- 参数文件: 指定相关初始化参数
- 日志文件: 常见的有错误日志文件,二进制日志文件,慢查询日志文件,查询日志文件,重放日志文件等
- socket文件: 当用UNIX域套接字方式进行连接时需要的文件 (我们平时一直在用,或许很多人没意识到)
- pid文件: 存放Mysql实例的进程ID文件
- Mysql表结构定义文件
- 存储引擎相关文件
Mysql数据库自身文件
参数文件
所谓参数文件其实就是常说的mysql配置文件my.cnf,mysql启动的时候会去寻找配置文件my.cnf,如果找不到,相关参数就使用默认值,如果找到了,就使用配置文件中手动设置的相关参数值覆盖默认值。
我们可以通过show variables命令来查看数据库中所有参数,也可以通过like 来过滤参数名。
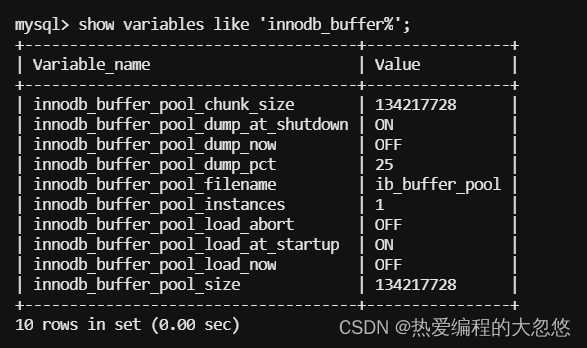
MySQL数据库中的参数可以分为两类:
- 动态(dynamic)参数
- 静态(static)参数
动态参数意味着可以在MySQL实例运行中进行更改,静态参数说明在整个实例生命周期内都不得进行更改,就好像是只读(read only)的。
关于通过SET设置动态参数相关注意事项这里就不展开了,感兴趣的小伙伴可以自行查询相关资料
日志文件
错误日志
错误日志文件对Mysql启动,运行,关闭过程进行了记录。该文件不仅记录了所有的错误信息,也记录一些警告信息或正确信息。
我们可以通过下面的命令来定位错误日志输出位置:

从上面的查询结果可以看出,当前的输出为stderr,表示我的这个MySQL日志会把日志输出到标准错误输出中。因为我的这个MySQL是使用docker容器启动的。所以这个error log默认是这么配置的。这样当我们启动这个容器的时候,如果启动失败,就可以使用docker logs 容器ID来查看具体启动MySQL服务的日志了。
默认情况下错误文件的文件名为服务器的主机名。
我们可以在my.cnf配置文件中修改一下错误日志的输出位置:
[mysqld]
# 错误日志的配置
log_error=/tmp/mysql_error.log
这里一定要注意:在把error log修改为其他目录的时候,一定要保证这个目录的权限,对mysql:mysql这个用户和组来说,是可以读写的。否则配置好之后,可能会因为没有权限导致启动MySQL服务失败。如果因为权限启动失败,可以尝试使用如下命令给MySQL的相关用户授权,授权后,再次尝试重启MySQL服务。
# 把'/'跟目录下面的abc目录已经其下的所有子目录的所属者,改为mysql用户。
chown -R mysql:mysql /abc
如果mysql运行在容器内部,那么切记配置文件中配置的是容器内路径,而不是主机路径
错误日志详细操作可以阅读此文
慢查询日志
常用参数设置
慢查询日志通常是用来记录运行时间超过指定阈值的sql语句,DBA通过慢查询日志找出那些需要进行优化的SQL语句。
该阈值可以通过参数long_query_time来设置,默认值为10秒:
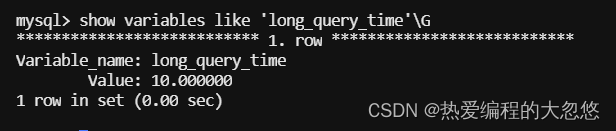
Mysql数据库只会记录运行时间超过该值的所有SQL语句,不记录等于情况。
慢查询日志默认不开启,可以将下面这个参数设置为ON来开启慢查询日志:
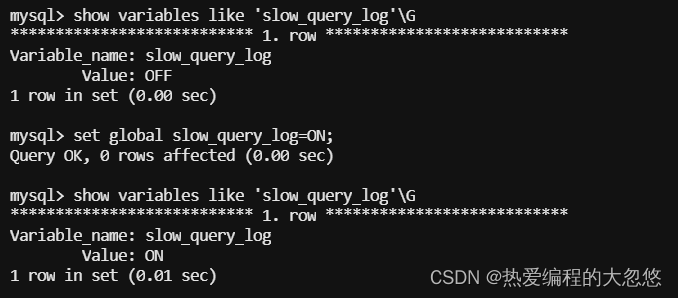
show_query_time这里是动态参数,可以在运行时进行调整。
我们还可以通过设置下面这个参数为true,在慢查询日志中额外记录那些没有使用索引的sql语句:
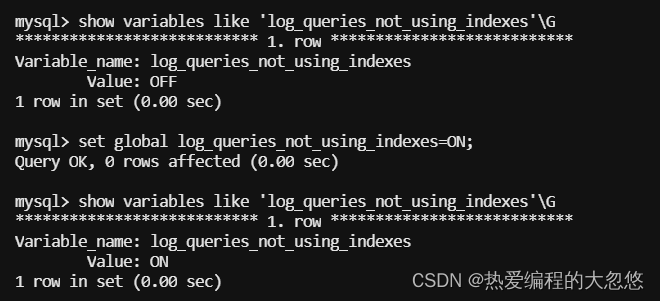
考虑到某些sql语句没有使用索引,但是却被频繁调用,导致slow log文件大小不断增加,mysql 5.6.5版本新增参数log_throttle_queries_not_using_indexes来限制每分钟记录到slow log的且未使用索引的SQL语句次数。

该参数默认值为0,表示无限制
慢查询日志文件
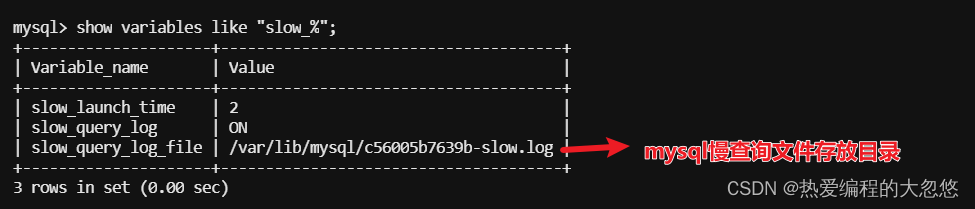
默认的日志文件名称为服务器主机名称-slow.log。默认的日志存储的路径为变量:datadir的值所指向的目录。
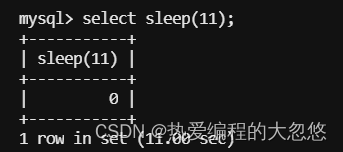
我们模拟执行一条慢查询:
mysql> select sleep(11);
+-----------+
| sleep(11) |
+-----------+
| 0 |
+-----------+
1 row in set (11.01 sec)
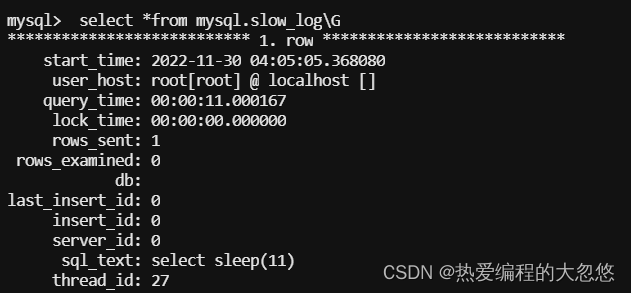
查看对应的慢查询日志:
# Time: 2022-11-30T03:42:53.310422-00:00
# User@Host: root[root] @ localhost [] Id: 6
# Query_time: 11.003019 Lock_time: 0.000000 Rows_sent: 1 Rows_examined: 0
SET timestamp=1669779773;
select sleep(11);
- Time:表示这个慢查询的SQL发生的时间。
- User@Host:表示这个SQL是由哪个用户通过哪个IP地址访问的。
- Query_time:表示这个SQL语句执行所花费的时间,单位是秒。
- Lock_time:表示这个SQL语句在执行的过程中,锁定表或行的时间。
- Rows_sent:表示最后查询的结果发送给客户端的行数。
- Rows_examined:表示这个SQL语句在执行过程中,实际扫描的行数。
- SET timestamp=1609322451:记录日志的时间
- 最后就是SQL语句的具体内容。
在慢查询日志记录很多的情况下,我们可以使用MySQL自带的mysqldumpslow来快速筛选出我们希望看到的那部分慢查询日志:
root@test:/# mysqldumpslow --help
Usage: mysqldumpslow [ OPTS... ] [ LOGS... ]
Parse and summarize the MySQL slow query log. Options are
--verbose verbose
--debug debug
--help write this text to standard output
-v verbose
-d debug
-s ORDER what to sort by (al, at, ar, c, l, r, t), 'at' is default
al: average lock time
ar: average rows sent
at: average query time
c: count # SQL语句出现的次数
l: lock time # SQL语句锁定表或行的时间
r: rows sent # SQL语句返回的结果集行数
t: query time # SQL语句执行锁消耗的时间
-r reverse the sort order (largest last instead of first) # 倒序排列输出结果
-t NUM just show the top n queries # 取top n个记录
-a don't abstract all numbers to N and strings to 'S'
-n NUM abstract numbers with at least n digits within names
-g PATTERN grep: only consider stmts that include this string
-h HOSTNAME hostname of db server for *-slow.log filename (can be wildcard),
default is '*', i.e. match all
-i NAME name of server instance (if using mysql.server startup script)
-l don't subtract lock time from total time
root@test:/#
常用的mysqldumpslow命令使用组合有如下几个:
root@test:/var/lib/mysql# #按照query time排序查看日志
root@test:/var/lib/mysql# mysqldumpslow -s t test-slow.log> slow.1.dat
root@test:/var/lib/mysql# #按照平均query time排序查看日志
root@test:/var/lib/mysql# mysqldumpslow -s at test-slow.log > slow.2.dat
root@test:/var/lib/mysql# #按照平均query time排序并且不抽象数字的方式排序
root@test:/var/lib/mysql# mysqldumpslow -a -s at test-slow.log > slow.3.dat
root@test:/var/lib/mysql# #安照执行次数排序
root@test:/var/lib/mysql# mysqldumpslow -a -s c test-slow.log > slow.4.dat
慢查询表
Mysql 5.1开始可以将慢查询的日志记录放入一张表中,慢查询表在mysql架构下,名为slow_log,表结构定义如下:
mysql> show create table mysql.slow_log\G
*************************** 1. row ***************************
Table: slow_log
Create Table: CREATE TABLE `slow_log` (
`start_time` timestamp(6) NOT NULL DEFAULT CURRENT_TIMESTAMP(6) ON UPDATE CURRENT_TIMESTAMP(6),
`user_host` mediumtext NOT NULL,
`query_time` time(6) NOT NULL,
`lock_time` time(6) NOT NULL,
`rows_sent` int(11) NOT NULL,
`rows_examined` int(11) NOT NULL,
`db` varchar(512) NOT NULL,
`last_insert_id` int(11) NOT NULL,
`insert_id` int(11) NOT NULL,
`server_id` int(10) unsigned NOT NULL,
`sql_text` mediumblob NOT NULL,
`thread_id` bigint(21) unsigned NOT NULL
) ENGINE=CSV DEFAULT CHARSET=utf8 COMMENT='Slow log'
各个字段含义如下:
- start_time:SQL语句执行的时间
- user_host:执行该SQL语句的用户和IP地址
- query_time:该SQL语句执行所消耗的时间,单位是秒。
- lock_time:锁表或行的时间。
- rows_sent:返回的结果集行数。
- rows_examined:实际扫描的记录行数。
- db:该SQL语句的是在哪个schema下面执行的。
- server_id:在MySQL集群中,数据库实例的编号。
- sql_text:SQL语句的具体内容。
- thread_id:线程编号。
Mysql慢查询日志默认只输出到文件中,我们可以通过log_output参数指定慢查询输出流向:
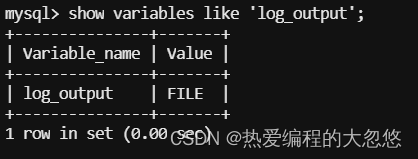
log_output有三个选项:FILE、TABLE、FILE,TABLE。
- 如果为TABLE表示记录在表中,表的名称为:mysql.slow_log。
- 如果为FILE表示只记录在日志文件中,日志路径默认在datadir变量中所配置的路径下,日志文件名称为主机名-slow.log,这个路径和名称都是可以在my.cnf配置文件中根据需求执行配置修改。
- 如果是FILE,TABLE则表示在表和日志中同时记录慢查询日志。
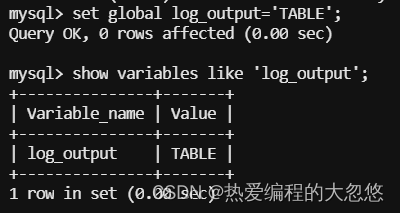
测试:
更换引擎
slow_log表底层使用CSV引擎,该引擎在大数据量查询效率较低,建议改为MyISAM存储引擎,并在start_time列上添加索引进一步提高查询效率。

将slow_log表的存储引擎更改为MyISAM后,会造成额外的开销,这一点需要根据实际情况进行考量。
慢查询日志更多细节可以参阅此篇文章
通用日志
general log通用日志会记录Mysql所有执行过的sql语句,包括所有DML语句,DDL语句和DCL语句。
General log默认不开启,因为日志会非常大,并且对性能有很大影响,一般只会在排查错误的时候,临时打开一下。
mysql> show variables like 'general_log'; -- 查看日志是否开启
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| general_log | OFF |
+---------------+-------+
1 row in set (0.02 sec)
mysql> show variables like 'general_log_file'; -- 看看日志文件保存位置
+------------------+-------------------------+
| Variable_name | Value |
+------------------+-------------------------+
| general_log_file | /var/lib/mysql/test.log |
+------------------+-------------------------+
1 row in set (0.02 sec)
mysql> show variables like 'log_output'; -- 看看日志输出类型 table或file
+---------------+------------+
| Variable_name | Value |
+---------------+------------+
| log_output | FILE,TABLE |
+---------------+------------+
1 row in set (0.01 sec)
通用日志的具体操作和慢查询日志一致,关于通用日志详细使用,可以阅读此文
二进制日志
二进制日志涉及内容颇多,我参考各方资料整理了一篇较为齐全的binlog介绍,文章链接如下:
binlog日志
套接字文件
前面提到过,在UNIX系统下本地连接MySQL可以采用UNIX域套接字方式,这种方式需要一个套接字(socket)文件。套接字文件可由参数socket控制。一般在/tmp目录下,名为mysql.sock:

pid文件
Mysql实例启动的时候,会将自己的进程ID写入一个文件中,该文件即为pid文件,该文件可由参数pid_file控制,默认位于数据库目录下,文件名为主机名.pid;

表结构定义文件
因为MySQL插件式存储引擎的体系结构的关系,MySQL数据的存储是根据表进行的,每个表都会有与之对应的文件。但不论表采用何种存储引擎,MySQL都有一个以frm为后缀名的文件,这个文件记录了该表的表结构定义。
frm还用来存放视图的定义,如用户创建了一个v_a视图,那么对应地会产生一个v_a.frm文件,用来记录视图的定义。
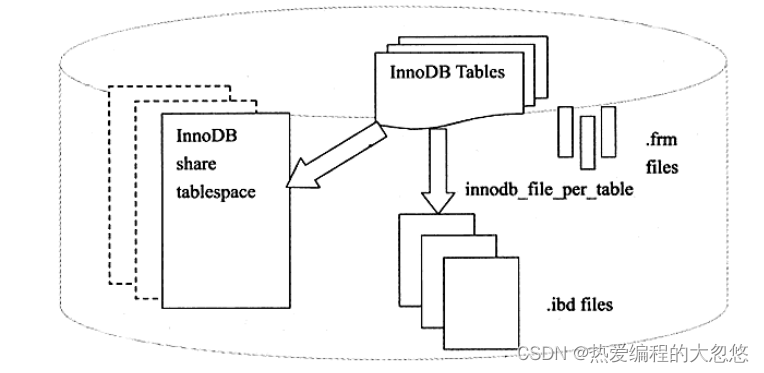
Innodb存储引擎的文件
之前介绍的文件都是MySQL数据库本身的文件,和存储引擎无关。除了这些文件外,每个表存储引擎还有其自己独有的文件。下面将具体介绍与InnoDB存储引擎密切相关的文件,这些文件包括重做日志文件、表空间文件。
表空间文件
InnoDB采用将存储的数据按表空间(tablespace)进行存放的设计。在默认配置下会有一个初始大小为10MB,名为ibdatal的文件。该文件就是默认的表空间文件(tablespace file),用户可以通过参数 innodb_data_file_path对其进行设置,格式如下:
innodb_data_file_path=datafile_spec1[;datafile_spec2]...
用户可以通过多个文件组成一个表空间,同时制定文件的属性,如:
[mysqld]
innodb_data_file_path = /db/ibdatal1:2000M;/dr2/db/ibdata2:2000M:autoextend
这里将/db/ibdatal和/dr2/db/ibdata2两个文件用来组成表空间。若这两个文件位于不同的磁盘上,磁盘的负载可能被平均,因此可以提高数据库的整体性能。同时,两个文件的文件名后都跟了属性,表示文件idbdatal的大小为2000MB,文件ibdata2的大小为2000MB,如果用完了这2000MB,该文件可以自动增长(autoextend)。
设置innodb_data_file_path参数后,所有基于InnoDB存储引擎的表的数据都会记录到该共享表空间中。
若设置了参数innodb_file_per_table,则用户可以将每个基于InnoDB存储引擎的表产生一个独立表空间。独立表空间的命名规则为:表名.ibd。通过这样的方式,用户不用将所有数据都存放于默认的表空间中。下面这台MySQL数据库服务器设置了innodb_file_per_table,故可以观察到:

单独的表空间文件仅存储该表的数据、索引和插入缓冲BITMAP等信息,其余信息还是存放在默认的表空间中,如下图所示:
redo日志
redo日志讲清楚需要的篇幅不小,因此另开一文单独进行讲解,文章的链接如下:
redo日志
![[附源码]计算机毕业设计springboot市场摊位管理系统](https://img-blog.csdnimg.cn/81b4873ce240449ea65dfac88b5f7a0f.png)