在外界看来,Linux 内核的内部似乎变化很少,尤其是像内存管理子系统(memory-management subsystem)这样的子系统。然而,开发人员时常需要更换内部接口来解决某些长期存在的问题。比如,其中一个问题就是用来保护内存管理里的重要结构的锁的竞争问题,这些重要结构是指页表(page table)和虚拟内存区域(VMA, virtual memory area)等。Liam Howlett 和 Matthew Wilcox 一直在开发一种新的数据结构,称为 "maple tree",希望能取代目前用于 VMA 管理的数据结构。这个改动可能对内核内部结构造成巨大变化,作者已经公布了一个改动很大的 patch set 来召唤 review。
Linux 是一个虚拟内存(virtual-memory)系统。每个进程的地址空间中包含多个虚拟内存区域(VMA),都是由 vm_area_struct 结构表示。每个 vma 都代表一块连续的地址空间,并且这部分区域都是属于相同的内存类型,也就是可以是 anonymous memory(匿名内存,内容并不与某个文件对应)、memory-mapped file(内存映射文件),甚至是 device memory(设备内存)。从进程的角度来看,一个 VMA 区域都是连续的,而实际上底层的物理内存区域可能并不连续。此外,整个地址空间在各个 VMA 之间是有空洞的,当内核需要映射产生一个新的区域时(例如在加载一个库文件或者响应 mmap()调用时),内核就会从这些空洞分配出虚拟空间从而利用起来(当然还是会预留一些未映射的 "guard" page,有利于减少缓冲区溢出的危害)。
我们的系统中几乎所有工作都涉及到内存,所以对这些表示 VMA 的结构的操作必须要快。这些操作包括 lookup(查找,也就是找出哪个 VMA 是对应某个虚拟地址的、确认内存是否被 map 过,或者寻找一个空闲区域用于分配新的 VMA),以及修改(例如,增大堆栈空间)。
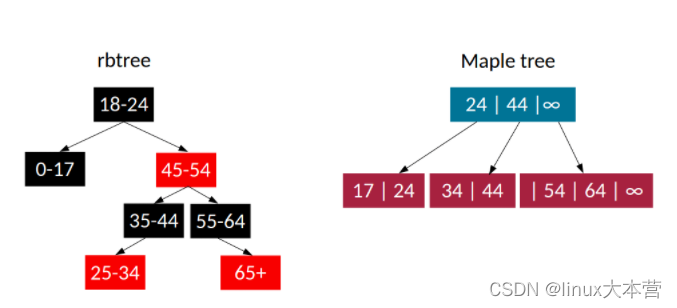
VMA 目前是通过一个红黑树(rbtree,red-black tree)的变种来管理的,针对红黑树来说增加了一个额外的双向链表,用来让内核遍历某个进程地址空间中的所有 VMA。内核开发者对这种数据结构的不满已经有一段时间了,原因有很多:rbtree 不能很好地支持范围(ranges),难以用 lockless(不需要获取锁)的方式来进行操作(rbtree 需要进行 balance 操作,这会同时影响多个 item),而且 rbtree 遍历的效率很低,这也是为什么需要一个额外的双向链表。
对 VMA 的操作会使用一个 lock 来保护(具体来说是一个 reader/writer semaphore),这个 lock 位于 struct mm_struct 中,此前名为 mmap_sem,2020 年 6 月的 5.8 版本将其改名为 mmap_lock。改名是为了能将对这个 lock 的操作都用 API 包装起来,希望将来替换的时候方便。
用户经常会碰到争抢这个 lock 的情况,尤其是那些在大型系统中使用多线程应用的用户。内核开发者已经多次讨论过这个问题,在 2019 年的 Linux Storage, Filesystem, and Memory-Management Summit (LFSMM) 峰会上至少有三次讨论过这个问题。问题的核心是,许多操作都需要获取 lock,这包括几乎全部的涉及 page table 和 VMA 的操作。还有其他一些相关的结构事实上也被 mmap_lock 地保护起来(麻烦的是相关文档也是缺失的)。开发者们在做的事情除了将不相关的结构从 mmap_lock 保护下拆分出来之外,还在考虑使用一个结构能允许 VMA 的访问变成 lockless 模式,或者使用某种类型的 range lock。当时有人提出了 maple tree 结构作为解决方案之一,但当时 maple tree 还处于早期开发状态,代码还没有完成。
相关视频推荐
5种红黑树的用途,从应用到内核场景的优缺点
红黑树、最小堆、时间轮、跳表多种方式实现定时器
7个方面讲解c/c++后端开发技术,让你对技术不再迷茫
免费学习地址:c/c++ linux服务器开发/后台架构师
需要C/C++ Linux服务器架构师学习资料加qun579733396获取(资料包括C/C++,Linux,golang技术,Nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,流媒体,CDN,P2P,K8S,Docker,TCP/IP,协程,DPDK,ffmpeg等),免费分享

Introducing maple trees

maple tree(取这个名字可能是借用了枫叶的形状,意指能走向多个方向)与 rbtrees 有根本性的差异。它们属于 B-tree 类型(
https://en.wikipedia.org/wiki/B-tree),也就是说它们的每个节点可以包含两个以上的元素,leaf node(叶子节点)中最多包含 16 个元素,而 internal node(内部节点)中最多包含 10 个元素。使用 B-trees 也会导致很少需要创建新的 node,因为 node 可能包含一些空余空间,可以随着时间的推移而填充利用起来,这就不需要额外进行分配了。每个 node 最多需要 256 字节,这是常用的 cache line size 的整数倍。node 中增加的元素数量以及 cache-aligned size 就意味着在遍历树时会减少 cache-miss。
maple tree 对搜索过程也有改进,同样是来自于 B-tree 结构特点。在 B-tree 中,每个 node 都有一些 key 键值,名为 "pivot",它会将 node 分隔成 subtree(子树)。在某个 key 之前的 subtree 只会包含小于等于 key 的数据,而这个 key 之后的子树只包含大于 key 的值(并且小于下一个 key 值)。
当然,maple tree 的设计中也是按照 lockless 方式的要求来的,使用 read-copy-update (RCU) 方式。maple tree 是一个通用结构,可以用在内核的不同子系统中。第一个用到 maple tree 的地方就是用来替换 VMA 管理中用到的 rbtree 和双向链表。作者之一 Liam Howlett 在一篇博客中解释了设计由来(
https://blogs.oracle.com/linux/the-maple-tree)。
Maple tree 提供了两组 API:一个是简单 API ,一个是高级 API。简单 API 使用 mtree_前缀来标记相关功能,主结构 struct maple_tree 定义如下:
struct maple_tree {
spinlock_t ma_lock;
unsigned int ma_flags;
void __rcu *ma_root;
};需要静态初始化(static initialize)的话,可以使用 DEFINE_MTREE(name) 和 MTREE_INIT(name,flags),后者会的 flags 目前只定义了两个 bit 选项,其中 MAPLE_ALLOC_RANGE 表示该树将被用于分配 range,并且需要把多个分配区域之间的空间(gap)管理起来;MAPLE_USE_RCU 会激活 RCU mode,用在多个 reader 的场景下。mtree_init() API 也使用相同的 flags,不过是用在动态初始化(dynamic initialization)场景:
void mtree_init(struct maple_tree *mt, unsigned int ma_flags);开发者可以用这个函数来 free 整个 tree:
void mtree_destroy(struct maple_tree *mt);可以用三个函数来给树增加条目:mtree_insert()、mtree_insert_range()和 mtree_store_range()。前两个函数只有在条目不存在的情况下才会添加,而第三个函数可以对现有的条目进行覆盖。它们的定义如下:
int mtree_insert(struct maple_tree *mt, unsigned long index,
void *entry, gfp_t gfp);
int mtree_insert_range(struct maple_tree *mt, unsigned long first,
unsigned long last, void *entry, gfp_t gfp);
int mtree_store_range(struct maple_tree *mt, unsigned long first,
unsigned long last, void *entry, gfp_t gfp);mtree_insert()的参数 mt 是指向 tree 的指针,index 就是 entry index,entry 是指向一个条目的的指针,有必要的话可以利用 gfp 来指定新增 tree node 的内存分配参数(memory allocation flag)。mtree_insert_range() 会利用给出的 entry 数据来插入从 first 到 last 的一个 range 范围。这些函数成功时返回 0,否则返回负值,如果返回-EEXIST 就表示 key 已经存在。mtree_store_range()与 mtree_insert_range()接受的参数相同,不同的是,它会替换相应 key 的任何现有条目。
有两个函数可以用来从 tree 中获取一个条目或删除一个条目:
void *mtree_load(struct maple_tree *mt, unsigned long index);
void *mtree_erase(struct maple_tree *mt, unsigned long index);要读取一个条目的话,可以使用 mtree_load(),它的参数是一个指向 tree 的指针 mt ,以及所要读取的数据的键值 index。该函数会返回一个指向该条目的指针,如果在 tree 中没有找到键值,则返回 NULL。mtree_erase() 也是同样的语法,用于从 tree 中删除一个 entry。它会从 tree 中删除给定的 key,并返回相关的 entry,如果没有找到,则返回 NULL。
简单的 API 不止上面这些,还有比如 mtree_alloc_range() 可以用来从 key space 中分配一个 range。而高级 API (用 mas_ 前缀标记出来了) 则额外增加了遍历整个 tree 的迭代函数,以及使用 state variable 来访问后一个或者前一个元素。通过这种细粒度的操作,开发者就可以根据需要来恢复中断了的搜索。还有供开发人员找到空闲区域或者对 tree 进行复制操作的 API。
Replacing the VMA rbtree (and more)
patch set 中不仅仅是引入了 maple tree。着重需要指出的是,这组 patch set 中有很大一部分是增加修改测试代码,考虑到这个改动会带来的巨大影响,以及新的数据结构在未来的重要性,这些测试代码是非常值得鼓励的。
这组 patch set 中有 70 个 patch 将 VMA 的所有操作中的 rbtree 操作换成了 maple tree,其中一个 patch 彻底在 VMA 中禁用了 rbtree。patch set 中另一部分代码移除了 VMA 里的双向链表。这个改动需要修改内核中所有直接地使用了 VMA 链表的代码:体系架构相关代码,core dump 代码,program 加载代码,一些设备驱动程序等,当然还有 memory-management 代码。patch set 里还删除了 VMA cache(用来跟踪每个进程最近访问过的 VMA,从而加快 lookup 速度),这是因为使用 maple tree 实现后速度更快,不再需要 VMA cache 了。
Patch set 的第一封邮件中还包括了一些性能数据 ,不过结果有些难以理解。一些 microbenchmark 的结果说明性能提升了,而其他一些(数量较少)则说明性能下降了。编译内核的时间与 5.10 内核本身相类似,只是多执行了几条指令(可能与添加的代码有关)。Howlett 希望大家给些建议如何对这些结果进行更深入的分析。
Current status and next steps
目前 Maple tree 还处于 RFC 阶段,有一些缺点。比如说,目前的实现不支持 32 位系统或 non-MMU 的平台。不过,这些代码已经可以实际用起来了,内核开发者们可以研究一下,从而决定是否符合他们期望的方向(因为这组 patch set 并没有去掉 mmap_lock )。这个 patch set 太大了,可能需要不少时间才能完成 review。