卷积神经网络粗学
卷积:用卷积求系统的存量
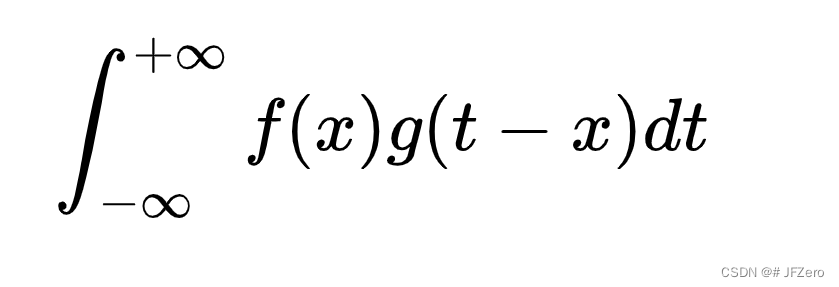
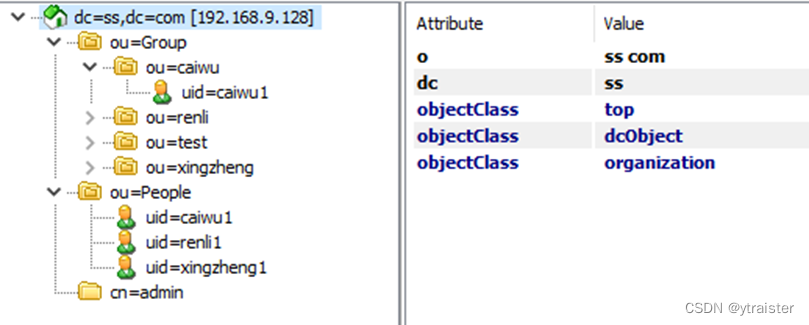
卷积,就是把输出函数反转一下。。。。(离谱)
实际不是从物理意义上理解的函数翻转,而是应该从数学意义上,去理解卷积的意义。
在定义卷积时为什么要对其中一个函数进行翻转? - 中微子的回答 - 知乎
图像的卷积操作:图像与卷积核相乘后相加
f-图像本身,因为图像的像素点是不同的(相当于是系统不稳定的输入)
g-卷积核,因为卷积核是固定的,但g并不是稳定的输出,但g函数是旋转180度之后,才是图像的卷积核
因为f(x,y)*g(m,n) = f(x,y)*g(m-x,n-y),这里的f,和g之间,成相反关系,而卷积核是按顺序对像素点相乘连加

卷积核:设置周围像素点,对当前像素点的影响效果
例如,如果是下列的卷积核,则中间的像素点则等于周围【像素点*】的累加可得,这样的效果,是使得中间像素点与周围像素点更均匀平滑,因此成为平滑卷积操作。
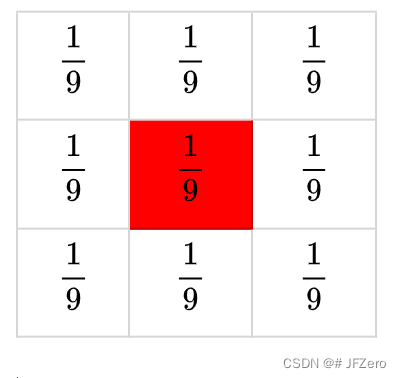
卷积操作,是处理一个像素点与周围像素点的关系
但不同的卷积核,可以有不同的作用,可以把周围有用的特征值保留下来。
因此,在使用神经网络对这些特征进行判断后,可以对图像进行分类等智能操作。
机器学习零碎学
感知机:分类工具,线性分类问题
线性函数+判断函数(激活函数、逻辑回归函数)
t =
机器学习基础流程
建立模型、学习模型、使用模型
预测与分类的关系(个人理解)
分类问题,本质上也是一种预测问题。
预测,可预测实值,也可预测类别。
预测实值可通过线性回归模型,预测出线性的实际数值。
但当预测某个数据的类别(例如男女、老少等非连续线性值)时,则变为了人们常说的分类问题。
因此,如果非要对预测、分类进行一个严格区分:
预测问题是对线性连续值的预测,分类问题是对非线性值的预测。
建立模型:针对数据集及任务要求,建立模型函数
预测问题:一般采用线性回归模型。
求解线性回归模型参数,即是学习模型的过程
常见的线性回归函数:一元线性回归【y = wx + b】、多元线性回归【y=】
分类问题:通常是引入非线性函数(激活函数),对线性回归结果进行非线性加工计算。
常见的激活函数有逻辑回归
具体的激活函数σ有多种,常见的有sigmoid函数(也叫逻辑回归函数)、Relu函数、softmax函数等。

(sigmoid与softmax实际相通,解释不同)
线性回归预测的结果值,经过逻辑回归,可实现分类效果。
总结来看:
如果要求实现预测,需建立线性回归模型。
如果要求实现分类,需建立逻辑回归模型。
学习模型:求解最优模型
选择损失函数
模型效果如何,是通过判断当前模型计算结果与实际结果拟合程度,拟合效果可通过损失函数来计算。
损失函数:用于判断模型效果。
损失函数有多种,常见的有三种:最小二乘法、极大似然估计法、交叉熵法。
即对应:平方损失函数(最小二乘法)、交叉熵损失函数(极大似然估计法、交叉熵法)
认识常用损失函数:
① 最小二乘法(模型计算结果与实际结果差值的平方和)
Loss = (模型计算结果-实际结果)的平方和
平方损失函数值越小,模型越优
② 极大似然估计法——(即交叉熵法,解释角度不同,但公式相同)
似然值:每个模型下发生的概率,叫做似然值。当似然值越大,表示该概率模型与实际结果概率的分布更接近。
极大似然估计法,就是在挑出似然值越大的那个概率模型。
Loss =
似然值(交叉熵)越大,模型越优。
总结来看:
最小二乘法(平方损失函数值越小,模型越优)
极大似然估计法(似然值越大,模型越优)
计算损失函数的值,并更新模型参数
模型与实际模型的拟合程度通过损失函数计算可得,而损失函数的计算通常有以下两种方法:
求出解析解,得到精确模型——数学计算求极值
求出近似解,逼近较优模型——梯度下降法、牛顿法…
① 求出解析解,更新模型参数
解析法求线性回归(可换为逻辑回归)的平方损失函数极小值
但使用解析法求出线性回归的平方损失函数极小值的前提是,是满秩矩阵
(数据集内容不同,结果可能满秩,也可能不满秩,因此最小二乘法在数据量过大数据内容不确定情况,有可能无法使用最小二乘法,可采用L2正则化进行优化【此知识点难度较大,待更新】,或是数量级差距过大,最小二乘法得出的结果偏差过大)
解析法求交叉熵损失函数的极大值(求解似然最大值)
对交叉熵损失函数求导,使导数为0,计算极值(具体不作详解)
计算平方损失函数、或是交叉熵损失函数的极值后,得到模型参数,即可更新为最终模型。
解析法难以应对大批量的数据集计算,因此实际常用求近似解,逼近较优模型的方式。
② 求出近似解,更新模型参数
求出近似解-梯度下降法:
使用梯度下降法,求解损失函数的值,多次迭代计算出损失函数的值。
停止迭代的方式有两种:
①设置损失函数的阈值,当损失函数小于某阈值,即停止迭代
②设置迭代的次数,当迭代次数超过时,即停止迭代(迭代会收敛,迭代次数越多,则越逼近极值)
多次迭代过程中,不断更新模型参数,使模型在迭代过程中逐渐变优。
牛顿法:
(正在学习中,涉及较多,待更新)
多层神经网络的浅显认识
上述是对单层神经网络的模型进行迭代,更新模型参数。
但当涉及多层神经网络时,中间含有较多隐含层,要如何更新各层模型的参数呢?
若是要训练多层神经网络,可考虑误差反向传播法:
计算当前模型的预测值与实际值的误差,根据误差值反向计算各层的参数
模型优劣指标:R方
R² = ,R²值越大,表示模型越好
当SST = SSR + SSE时,有R² =
SSR:回归值与实际均值的方差,表示线性模型的波动,即回归模型的x变量对实际y变量的相关性程度
SST:实际值与实际均值的方差,表示实际模型的波动,即实际模型的x变量对实际y变量的相关性程度
SSE:实际值与回归值的方差,表示线性模型的回归值对实际模型的值的拟合程度。
这里的SST = SSR + SSE等式之所以成立,是因为有个重要的前提就是拟合值最小,所以我们才可以用两式联立进行求解。如果没有这个条件,即拟合过程中没有取得最值,这个结论是不能保证成立的。
原文链接:https://blog.csdn.net/weixin_43145361/article/details/103546382
为什么不用SSE而用R²来作为模型评价指标?
R² =
因为,SSE一般用于表示回归值与实际值的误差,当SSE越小,可以说明,回归模型可以更好地拟合当前实际数据,但不代表回归模型就是好的。
还需要引进变量x与实际值y之间的相关关系判断。
当实际值与实际均值的差距不大(即SST很小时),我们认为变量x与实际值并没有太大相关性,才导致实际值与均值差距不大。
变量与值相关性不强的模型,即使拟合程度很好,也无法更好地根据变量x进行预测。
因此判断一个模型是否为好的模型,并不应该只是判断它的回归值与实际值的拟合程度,还应该根据实际数据(变量与值)之间的相关性进行综合判断。
相关性不强的数据,进行回归分析
R² = SSR/SST,但SST≠SSR+SSE
R²很小
相关性较强的数据,进行回归分析
R²较大,说明模型较好
【以上均个人理解】