人工智能领域视频模型大体也经历了从传统手工特征,到卷积神经网络、3D卷积网络、双流网络、transformer的发展脉络。
视频的技术大多借鉴图像处理技术,只是视频比图片多了一个时间维度。
下面内容先简单汇总下,后续再逐渐补充。
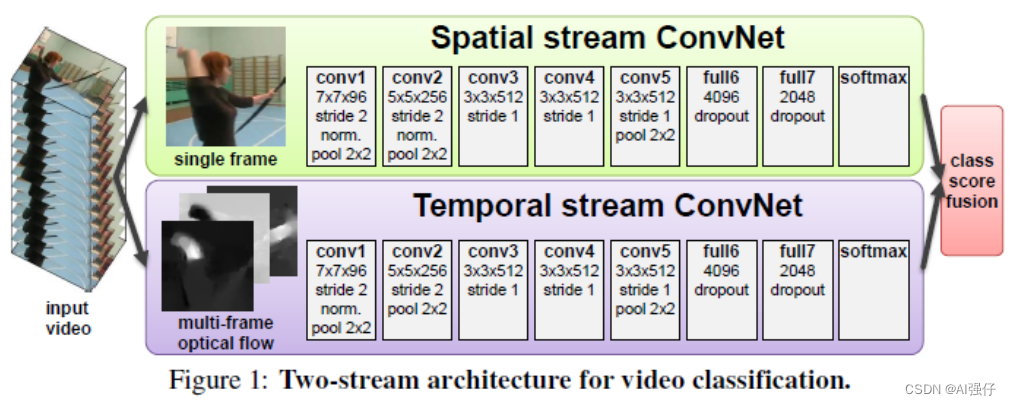
1. 双流网络
双流网络,通过 Spatial stream ConvNet 和 Temporal stream ConvNets 分别抽取视频的空间和时序特征,最后对两个网络进行融合。详见《Two-stream architecture for video recognition》
2. 3D卷积
视频比图片多了个时间维度,故将图片的2D卷积可以扩展到3D,处理视频。

详见论文笔记3D Convolutional Neural Networks for Human Action Recognition_AI强仔的博客-CSDN博客
3. transformer
最近的研究主要集中在3D卷积神经网络和视觉transformer。虽然3D卷积可以在一个小的3D领域内(如3*3*3)可以捕捉详细的局部时空特征,减少了相邻帧之间的时空冗余,即有效处理局部信息来控制局部冗余,但因为受限制的接受域,缺乏捕捉全局依赖的能力。而视觉transformer通过自注意力机制可以捕捉长范围的依赖,但又在每个层中所有token的盲目相似比较导致其不能很好的减少局部冗余。
3.1 UNIFORMER-视频模型(3D CNN和transformer结合)
Unifified transFormer (UniFormer) ,集成了3D卷积和transformer,在计算量和准确度之间取得了较好的平衡。可以同时处理时空冗余和依赖.
详见UNIFORMER-视频模型(3D CNN和transformer结合)_AI强仔的博客-CSDN博客