上篇文章是中规中矩的标准计算函数,就算不用pgrx,也是可以正常理解的,所以基本上没有什么对于pgrx框架有关系的东西(唯一有关系的东西,应该就是Rust的时间类型与pgrx的时间类型的计算了)。
这篇文章会讲一个pgrx对于postgresql或者说对于任何数据库扩展来说都比较有用的开发内容:返回序列以及表的函数的编写。
针对上篇文章,用了一个概念,就是:单值输入与单值输出,那么相对来说,这篇文章描写的就是单值输入与多值输出。
所谓的多值输出,就是可以输出超过一行的函数。
如下所示,这个Python函数,就是单值输入,多值输出的例子:我们输入1个整数,然后函数根据我们输入的整数,去生成一个list。
例如我们输入的是5,得到的结果就是[0,1,2,3,4]。
def generate_list(x:int):
return [i for i in range(0,x)]在本系列的第一篇文章里面,大家可能还记得我给出来的这样一个效果:

那么在pgrx里面,如何来实现呢?
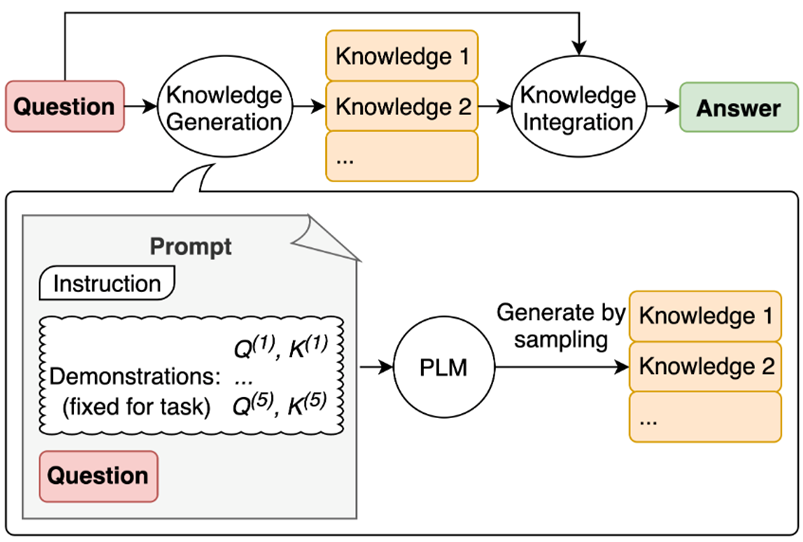
pgrx对于这种集合类型的支持,有很多种,例如Vec、range这些个类型都是支持的,但是对于数据库来说,这种返回超过一行序列的方法被称之为srf,即:Set Returning Functions。
在Postgresql里面,本身就内置了很多srf,例如generate_series()这个就是最著名的内置srf。

而在pgrx里面,如果要实现srf,需要包装的类型分别是:
- SetOfIterator
- TableIterator
注意:这两个类型是pgrx 0.7.0之后版本才推出的,如果你看的旧版本的介绍,发现是没有这两个类型的。
首先我们来看如何使用SetOfIterator来实现一个生成自定义序列的srf:
表示rust风格的代码,是这样写的:
#[pg_extern]
fn my_generate_series(start:i64,
end:i64,
step:i64)->SetOfIterator<
'static, i64
>{
SetOfIterator::new((start..=end).step_by(step as usize).into_iter())
}
不过这种写法编程,对于没有接触过函数式编程的同学感觉非常痛苦,所以我们写成传统的过程化编程风格:
#[pg_extern] fn my_generate_series2(start:i64,end:i64,step:i64) ->SetOfIterator<'static, i64>{ //初始化一个集合 let mut series:Vec<i64> = vec![]; //迭代从start - end的所有数值 for x in start..=end{ //如果有setp,则满足条件在放入集合中 if x % step ==0{ series.push(x); } } //把生成的集合,放入SetOfIterator 包装类型中,返回出来 SetOfIterator::new(series) }
我们可以来看看两种不同的写法,实际上结果是一样的:

生成50000个数值,效率也是差不多的:

不过对于写过函数式编程的同学来说,第一种写法更加简洁明了……起码对于我来说,我还是喜欢第一种写法的:

下面我们来看一个小案例:
第一个是定制一个我们自己的UUID函数:
做数据库设计的时候,最头疼的问题之一是如何设计一个有意义、高性能其能保证在一定程度上不会冲突的ID。 其中一种方案就是用UUID:UUID 是 通用唯一识别码(Universally Unique Identifier)的缩写,他可以保证生成在时间和空间上的唯一编码。
虽然从PG13的版本开始,就已经提供了uuid的生成函数,但是它只能生成UUID V4版本的序列:
常用的自增 ID 缺乏随机性,且会暴露数据细节(黑客可以通过 id 的规律爬到大量数据);UUID v4 是基于随机数的,具备足够随机性,但其最大的问题就是无法排序。

而最新的UUID 7版本,已经支持了排序和大小比较,所以我们想在postgresql里面使用UUID V7版本,怎么做呢?
首先在cargo里面把需要的包导入进来:
uuid7 = "0.6.2"
然后编写一个方法:
#[pg_extern]
fn my_uuid7() -> String {
uuid7::uuid7().to_string()
}然后可以阔以了:

下面我们来看看效果:
生成出来的表是这样的:

做一个查询:

简单得让人难以置信……真是太残暴了……

下面来做一个数据分析中常用的操作:抽样。
例如上面那个表,我做了20万条数据数据进去,现在需要对它进行随机抽样,而且要求抽样满足各种分布,例如正态分布、均匀分布或者泊松分布以及伯努利分布……

如果仅仅是做随机抽样,那么SQL原生提供的RAND()函数就可以搞定了:
注意前面那么一堆代码,是我给这个表加了个行号,用来标识信息,否则uuid更本看不出效果来,ORDER BY random()的意思就是随机排序。

如果要做正态分布(高斯)的话,postgresql也提供了一个扩展模块:tabfunc中的normal_rand 函数:

安装好这个扩展之后,可以看见有如下函数:

例如我们可以用这个函数生成10个均值为10万,标准差为1万的数值:

然后可以用于抽样:

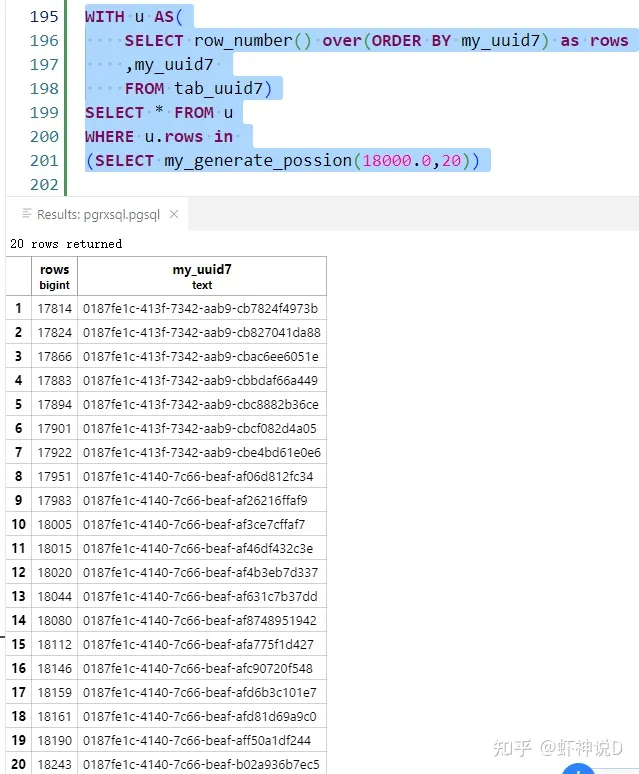
但是其他的分布,SQL就比较麻烦了,所以我们针对此需求,来编写一个伯努利抽样的扩展,代码如下:
- 直接导入Rust的随机数工具包rand(Rust的随机数包)和rand_distr(这个包用来生成泊松分布抽样),写在工程的cargo.toml配置文件里面:

- 编写扩展函数,代码如下:
use rand_distr::{Poisson};
#[pg_extern]
fn my_generate_possion(lambda:f64,cnt:i64) -> SetOfIterator<'static,i64>{
let poi = Poisson::new(lambda).unwrap();
let v = poi.sample(&mut rand::thread_rng());
SetOfIterator::new((0..cnt).into_iter()
.map(move |x| poi.sample(&mut rand::thread_rng()) as i64))
}编译运行,

测试结果如下:

现在我们配合这个函数做一个泊松抽样:
打完收工





![[Android]AsyncChannel介绍](https://img-blog.csdnimg.cn/b2590e8021534925b82c06959ef9fc31.png)