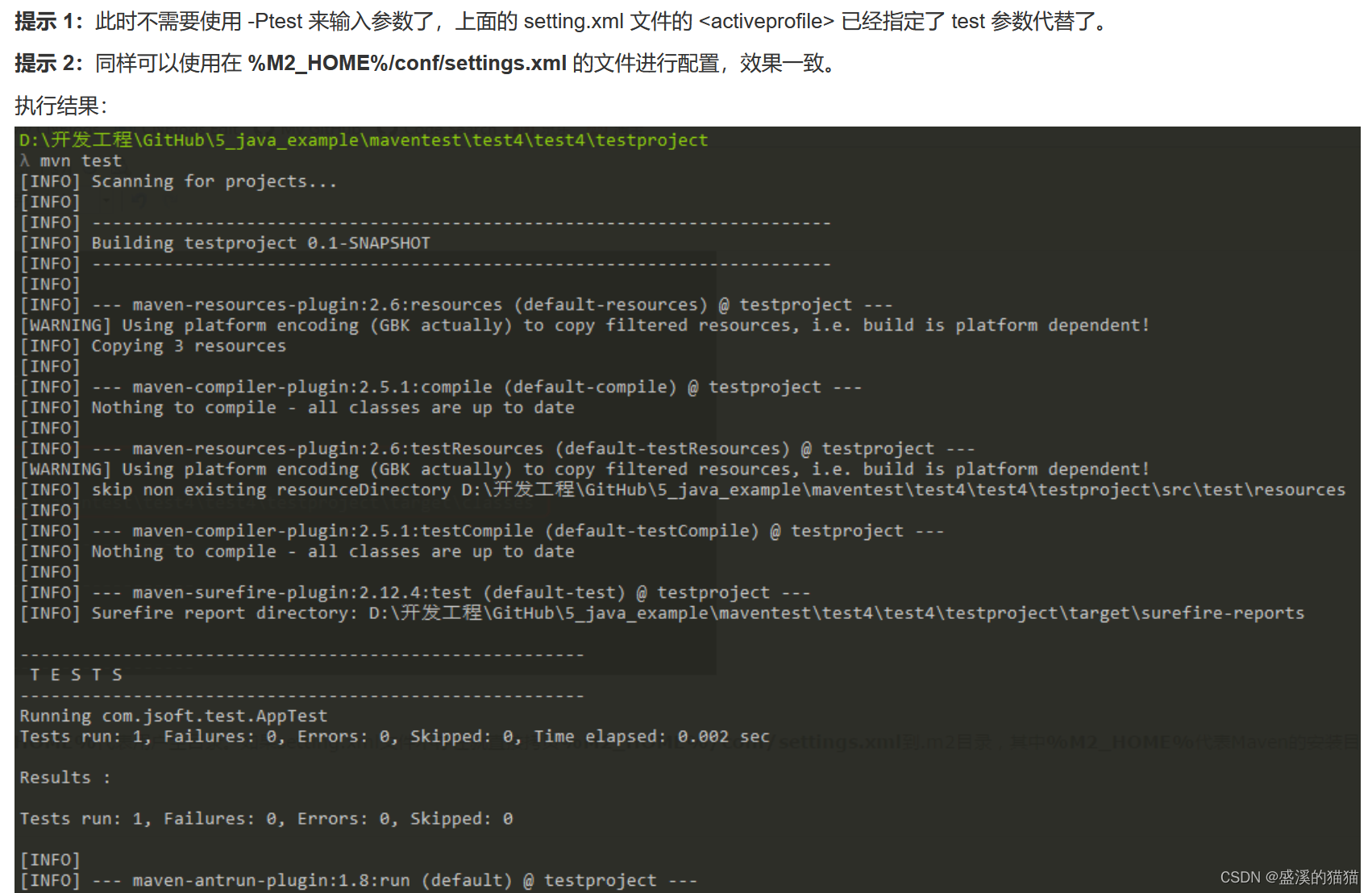
目录
一、数组
1.定义数组
2. 数组中数据类型
2.1数值类型
2.2字符类型
二、数组的用法
1. 输出数组中的值
2. 统计数组参数个数
编辑
3.查看数组下标列表
4.分割字符串
5.替换数组中的字符
6.删除数组
三、数组追加元素
1.方法1示例
2.方法2示例
3.方法3示例
4.方法4示例
四、将数组的值传入函数
1. 如果将数组变量作为函数参数,函数只会取变量的第一个值
2.将输入的数组值转换为原有数组值乘2的新的数组
五、数组排序算法
1.冒泡排序
1.1基本思想
1.2算法思路
2.实验
一、数组
1.定义数组
1) 数组名=(num1 num2 num3 ...)
2) 数组名=([0]=num1 [1]=num2 [3]=num3 ...)
3) 列表名="num1 num2 num3 ..."
数组名=($列表名)
4) 数组名[0]="num1"
数组名[1]="num2"
数组名[2]="num3"
...2. 数组中数据类型
2.1数值类型
#定义一个数组
array=(12 13 14 15)
#输出数组的值
echo ${array[@]} 或 echo ${array[*]}
2.2字符类型
字符要使用" " 或 ' ' 来定义
#定义一个数组
array1=("zhang san" "li si" "wang wu")
echo ${array1[@]}
#查看数组的参数个数
echo ${#array1[@]}
#完整数组下标顺序为0,1,2,3... ;输入下标可查看数组中对应下标的值
echo ${array1[下标]}

二、数组的用法
1. 输出数组中的值
#定义一个数组
array=(10 20 30 11 22 33)
#输出数组中的值
echo ${array[@] 或 echo ${array[*]}

2. 统计数组参数个数
#统计数组内参数的个数
echo ${#array[@]}

3.查看数组下标列表
#获取数组下标列表
echo ${!array[@]}
#完整数组下标顺序为0,1,2,3... ;输入下标可查看数组中对应下标的值
echo ${array1[下标]}
4.分割字符串
#分割数组中字符串
echo ${array[@]:下标数字:参数个数}
#从下标3开始向后取2个参数
echo ${array[@]:3:2}
5.替换数组中的字符
#临时替换,不对数组进行修改
echo ${array[@]/旧字符/新字符}
#永久替换数组中的字符
array=($(array[@]/旧字符/新字符}
6.删除数组
#删除数组中某一个参数
unset array[下标]
#删除整个数组
unset array
三、数组追加元素
1) array[下标]=元素
2) array[${#array[@]}]=元素
#只可用于完整数组
3) array=("${array[@]}" 元素1 元素2 元素3...)
#双引号不能省略,否则,当数组array中存在包含空格的元素时会按空格将元素拆分多个。
#不能将“@”替换为“*”,如果替换,不加双引号时与 @ 表现一致,
#加双引号时,会将数组所有元素作为一个元素添加到数组中
4) array+=(元素1 元素2 元素3...)
#代添加元素必须用()包围,并且将元素间用空格分隔1.方法1示例

2.方法2示例

3.方法3示例

4.方法4示例

四、将数组的值传入函数
1. 如果将数组变量作为函数参数,函数只会取变量的第一个值


#!/bin/bash
array() {
echo $1
echo $@
echo $#
}
arr=(11 22 33 44)
#将数组变量变成列表
array ${arr[@]} 
2.将输入的数组值转换为原有数组值乘2的新的数组
#!/bin/bash
#定义函数
array() {
#将调用函数后的所有参数定义为newarr
newarr=($@)
#下标i的范围从0开始,小于参数的个数。下标最大为数组参数个数减1
for ((i=0;i<${#newarr[@]};i++))
do
newarr[$i]=$[${newarr[$i]} * 2]
#将原有数组的值乘2
done
#将处理过的值进行输出
echo ${newarr[@]}
}
###main###
read -p "输入一个数组:" num
#将调用函数后输出的值定义为一个新数组arr
arr=($(array $num))
echo "新数组的值为${arr[@]}"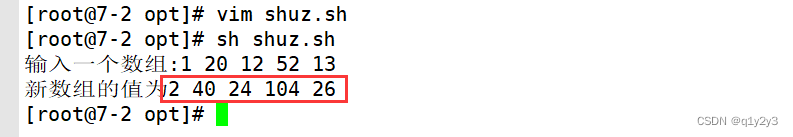
五、数组排序算法
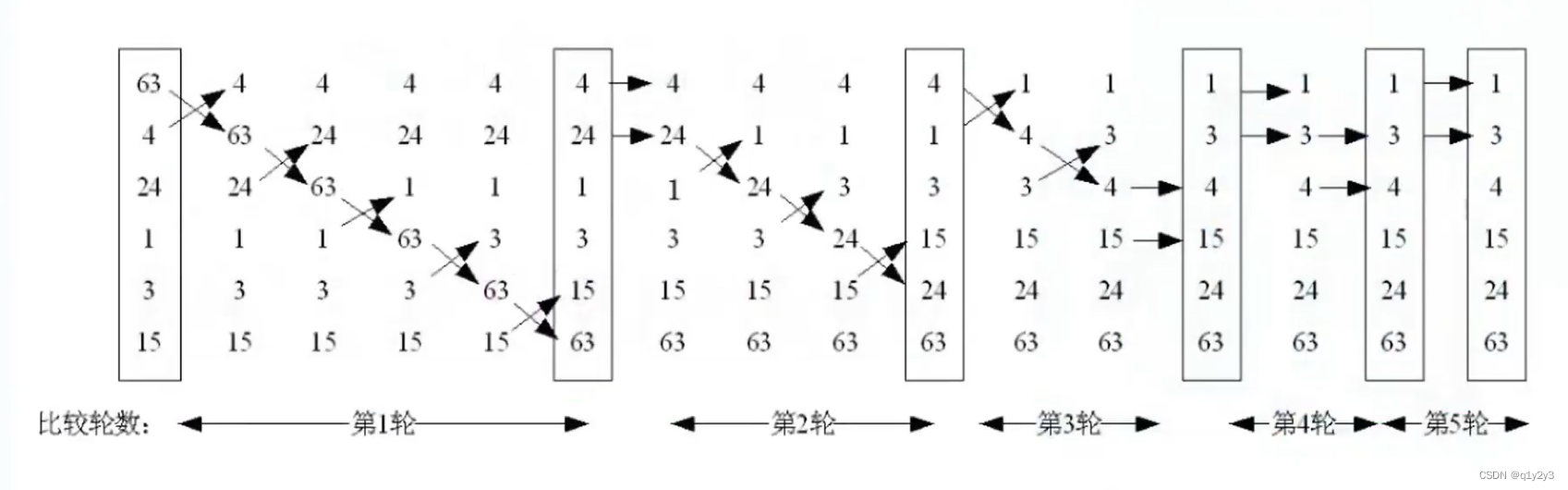
1.冒泡排序
类似于气泡上涌的动作,会将数据在数组中从小到大或者从大到小不断的向前移动。
1.1基本思想
冒泡排序就是对比相邻的两个元素值,如果满足条件就交换元素值,把较小的元素移动到数组前面,把大的元素移动到数组后面(将两个元素的位置交换),这样较小的元素就像气泡一样从底部上升到顶部。
1.2算法思路
冒泡算法由双层循环实现,其中外部循环用于控制排序轮数,轮数为排序的数组长度减1,因为最后一次循环只剩下一个元素,不需要再进行比较。而内部循环主要用于比较数组内每个相邻元素之间的大小,以确定是否交换位置,对比和交换次数随着排序轮数而减少。
2.实验
将冒泡排序封装到函数中,将输入的数组值进行排序,然后输出
#!/bin/bash
MAOPAO() {
newarr=($@)
#将数组的长度定义为length
length=${#newarr[@]}
#外层循环,控制排序轮数,轮数为数组长度-1
for ((i=1;i<length;i++))
do
#内层循环,比较相邻两个元素,首轮比较次数=数组长度-1,
#因为a从0开始,比较次数=数组长度-2;每轮比较后,比较次数比上次少比较一轮。
for ((a=0;a<length-i;a++))
do
#定义相邻两个元素的变量
first=${newarr[a]}
second=${newarr[a+1]}
#比较相邻元素大小
if [ $first -gt $second ]
then
#下标小的元素大的话,就将元素交换位置
newarr[a]=$second
newarr[a+1]=$first
fi
done
done
echo ${newarr[@]}
}
###main###
read -p "输入一个数组:" num
#将调用函数输出的值定义为变量arr
arr=($(MAOPAO $num))
echo "冒泡排序后数组顺序为${arr[@]}"