原文:
copilot-explorer | Hacky repo to see what the Copilot extension sends to the server
对我来说,Github Copilot 极其有用。它经常能神奇地读懂我的想法并给出有用的建议。最让我惊讶的是,它能够从周围的代码中正确地“猜测”出函数/变量 - 包括从其他文件中。这只可能发生在 copilot 扩展将周围代码的重要信息发送到 Codex 模型的情况下。我对它的工作原理感到好奇,所以我决定查看源代码。
在这篇文章中,我试图回答有关 Copilot 内部机制的特定问题,同时也描述了我在仔细研究代码时发现的一些有趣的观察结果。我将提供几乎所有我谈到的相关代码的指向,以便有兴趣的人可以自己查看代码。
逆向-前瞻
几个月前,我进行了一个非常浅层次的对扩展进行“逆向工程”的尝试,但我一直想进行更深入的探索。最近几周我终于有时间做这件事了。大致上,我拿到了 Copilot 附带的 extension.js 文件,进行了一些微小的手动更改以便于自动提取模块,编写了一堆 AST 变换来“美化”每个模块,对模块进行了命名和分类,并手动注释了几个最有趣的模块。
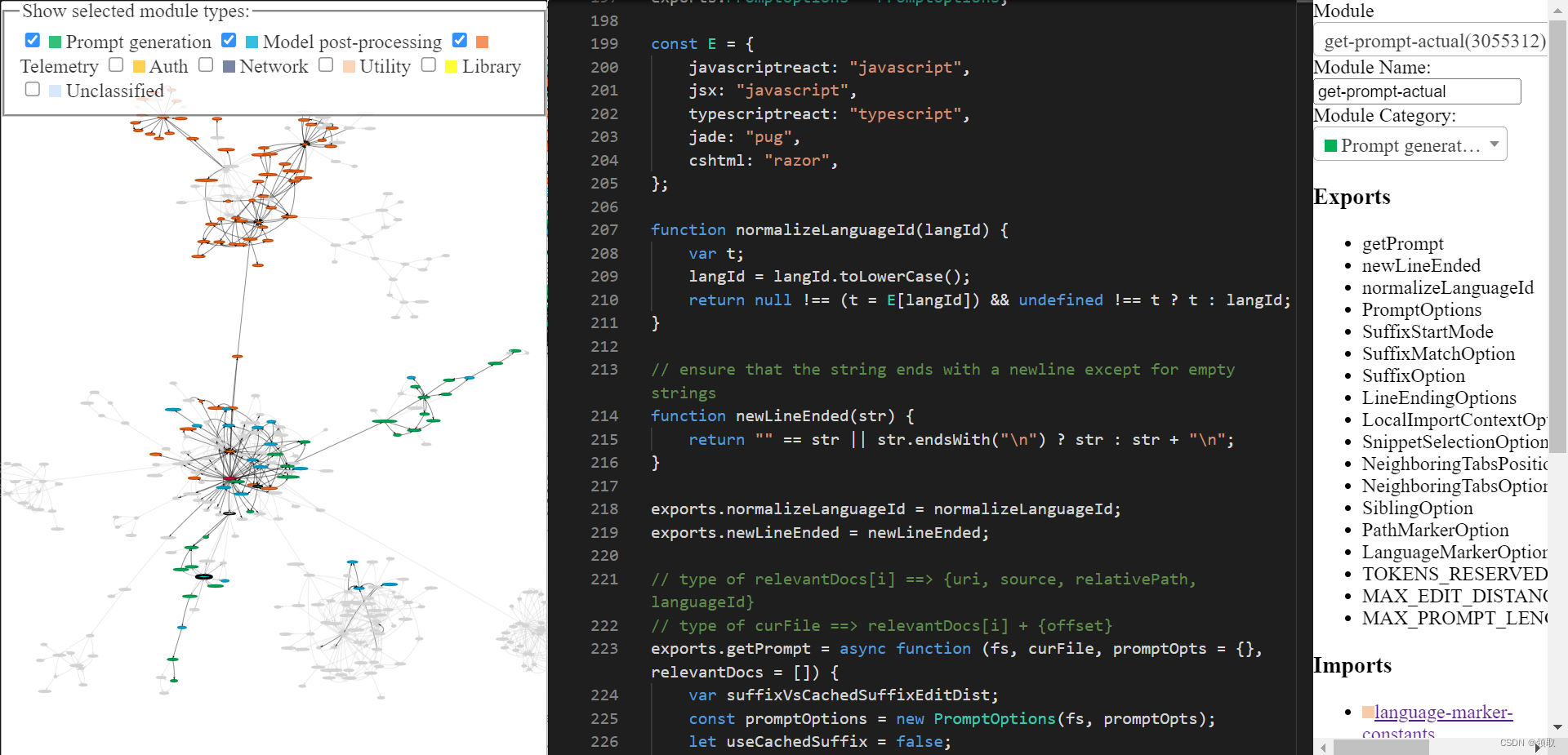
你可以通过我构建的这个工具来探索经过逆向工程的 copilot 代码库(主页,工具本身)。它可能有一些粗糙的地方,但你可以使用它来探索 Copilot 的代码。最后的工具看起来像这样。如果你对如何使用它感到困惑,请查看主页。
Copilot:概览
Github Copilot 主要有两个组成部分:
客户端:VSCode 扩展收集你输入的所有内容(称为提示),并将其发送到类似 Codex 的模型。模型返回的任何内容,它都会在你的编辑器中显示。
模型:类似 Codex 的模型接收提示,并返回完成提示的建议。
Secret Sauce 1: Prompt engineering
现在,Codex 已经在大量的公开 Github 代码上进行了训练,所以它能够给出有用的建议是合理的。但是,Codex 不可能知道你当前项目中存在哪些函数。尽管如此,Copilot 经常能产生涉及你项目中的函数的建议。它是如何做到的呢?
让我们分两部分回答这个问题:首先让我们看一下 copilot 生成的真实提示,然后我们将看到它是如何生成的。
prompt 看起来是什么样的?
扩展在提示中编码了大量关于你项目的信息。Copilot 有一个相当复杂的提示工程管线。这是一个提示的例子:
|
|
如你所见,这个提示包括了前缀和后缀。Copilot 会将此提示(经过一些格式化处理后)发送给模型。在这个例子中,Copilot 是在“插入模式”中调用 Codex,也就是填充中间(FIM)模式,因为后缀是非空的。
如果你查看前缀(在这里可以方便地查看),你会看到它包括了项目中另一个文件的一些代码。看一下 # Compare this snippet from codeviz\predictions.py: 这一行及其后面的行。
如何准备提示?代码解读。
大致上,执行以下一系列步骤来生成提示:
1)入口点:对给定的文档和光标位置进行提示提取。提示生成的主要入口点是 extractPrompt(ctx, doc, insertPos) 从 VSCode 查询文档的相对路径和语言 ID。
2)参见 getPromptForRegularDoc(ctx, doc, insertPos)。
3)相关文档:然后,从 VSCode 查询最近访问的 20 个相同语言的文件。参见 getPromptHelper(ctx, docText, insertOffset, docRelPath, docUri, docLangId)。稍后,这些文件将用于提取要包含在提示中的类似片段。我个人觉得使用相同的语言作为过滤器有点奇怪,因为多语言开发相当常见。但我猜这仍然覆盖了大多数情况。
4)配置:接下来,设置一些选项。具体来说:
a)suffixPercent(提示标记应该有多少用于后缀?默认好像是 15%)
b) fimSuffixLengthThreshold(启用填充中间的最小后缀长度?默认为 -1,所以只要后缀非空,FIM 就总是启用的,但这是由 AB 实验框架控制的)
c)includeSiblingFunctions 似乎已经硬编码为 false,只要 suffixPercent 大于 0(这是默认的情况)。
5)前缀计算:现在,创建一个“提示愿望清单”来计算提示的前缀部分。在这里,添加不同的“元素”及其优先级。例如,一个元素可以是像“Compare this snippet from <path>”,或者本地导入上下文,或者每个文件的语言 ID 和/或路径。这在 getPrompt(fs, curFile, promptOpts = {}, relevantDocs = []) 中发生。
a)有 6 种不同类型的“元素” - BeforeCursor, AfterCursor, SimilarFile, ImportedFile, LanguageMarker, PathMarker。
b)由于提示大小有限,所以按优先级和插入顺序对愿望清单进行排序,然后按大小限制添加元素到提示中。这种“满足”逻辑在 PromptWishlist.fulfill(tokenBudget) 中实现。
c)一些选项如 LanguageMarkerOption, NeighboringTabsPositionOption, SuffixStartMode 等控制这些元素的插入顺序和优先级。有些控制如何提取某些信息,例如,NeighboringTabsOption 控制如何从其他文件中积极地提取片段。有些选项只针对特定的语言定义,例如,LocalImportContextOption 只针对 TypeScript 定义。
d)有趣的是,有相当多的代码处理这些元素的排序问题。我不确定所有的代码是否都在使用,有些东西对我来说看起来像是死代码。例如,neighboringTabsPosition 似乎从未被设置为 DirectlyAboveCursor...但我可能错了。同样,SiblingOption 似乎被硬编码为 NoSiblings,这意味着没有实际的兄弟函数提取发生。再次,也许这是为未来计划的,或者只是死代码。
6) 后缀计算:前一个步骤是为前缀,但是后缀的逻辑相对简单 - 只需用光标可用的后缀填充可用的标记预算。这是默认的,但后缀的起始位置稍微依赖于 SuffixStartMode 选项。这由 AB 实验框架控制。例如,如果 SuffixStartMode 是 SiblingBlock,那么 Copilot 将首先找到最接近的函数,这个函数是正在编辑的函数的兄弟函数,并从那里开始后缀。
后缀缓存:Copilot 做的一个奇怪的事情是,只要新的后缀不是“离缓存的后缀太远”,它就会在调用之间缓存后缀。我不知道为什么这样做。或者我可能误解了混淆的代码(虽然我找不到代码的其他解释)。
细看片段提取
对我来说,提示生成的最完整部分似乎是从其他文件中提取片段。这在这里被调用,并在 neighbor-snippet-selector.getNeighbourSnippets 中定义。根据选项,这要么使用“固定窗口 Jaccard 匹配器”,要么使用“基于缩进的 Jaccard 匹配器”。我不是 100% 确定,但看起来基于缩进的 Jaccard 匹配器实际上没有被使用。
默认情况下,使用固定窗口 Jaccard 匹配器。这个类将给定的文件(要从中提取片段)切成固定大小的滑动窗口。然后,它计算每个窗口和参考文件(你正在输入的文件)之间的 Jaccard 相似性。只有每个“相关文件”的最佳窗口被返回(虽然有返回前 K 个片段的规定,但它从未被使用)。默认情况下,FixedWindowJaccardMatcher
在“Eager mode”(即,窗口大小为60行)中使用。然而,模式是由 AB 实验框架控制的,所以可能使用其他模式。
总的来说,Github Copilot 的提示生成系统包括了一系列复杂的步骤和逻辑,涉及到了文件的语言、文件路径、上下文信息、兄弟函数、以及其他一些相关的选项和参数。它会从项目的各个文件中提取代码片段,并根据特定的规则和优先级对这些片段进行排序和组合,最终生成一个提示,这个提示会被发送到 Codex 模型,Codex 模型会根据这个提示返回代码建议。虽然其中有一些部分可能是未使用的代码或者是为未来的功能预留的,但总体上,这个系统是一个非常精细、复杂的系统,能够提供非常有用的代码建议。
Secret Sauce 2: Model Invocation
Copilot通过两种用户界面提供补全:(a)内联/幽灵文本和(b)Copilot面板。这两种情况下调用模型的方式有一些不同。
内联/幽灵文本
主模块
在这里,扩展程序为了保持快速,只向模型请求非常少的建议(1-3个)。它还会积极地缓存模型的结果。此外,如果用户继续输入,它也会负责调整建议。如果用户快速输入,它也会负责防抖模型请求。
这个用户界面还有一些逻辑来防止在某些情况下发送请求。例如,如果用户在一行的中间,那么只有当光标右边的字符是空白、闭合括号等,才会发送请求。
通过上下文过滤器防止糟糕的请求
更有趣的是,生成提示后,这个模块会检查提示是否“足够好”,值得去调用模型。它通过计算所谓的“上下文过滤器分数”来做到这一点。这个分数似乎是基于一个简单的逻辑回归模型,该模型有11个特征,如语言,前一个建议是否被接受/拒绝,前一个接受/拒绝之间的时间,提示中最后一行的长度,光标前的最后一个字符等。模型权重包含在扩展代码中。
如果分数低于一个阈值(默认为15%),那么就不会发送请求。这个模型值得深入研究一下。我做的一些观察是,有些语言的权重比其他语言高(比如,php > js > python > rust > dart...php,真的吗?)。另一个直观的观察是,如果提示以 ) 或 ] 结尾,那么分数就会比以 ( 或 [ 结尾的分数低 (-0.999, -0.970),比 ( 或 [ 结尾的分数高 (0.932, 0.049)。这是有道理的,因为前者更有可能已经“完成”,而后者显然表示用户会从自动补全中受益。
Copilot面板
主模块,核心逻辑 1,核心逻辑 2。
这个用户界面比内联用户界面从模型中请求更多的样本(默认为10个)。这个用户界面似乎没有上下文过滤器逻辑(如果用户明确调用了这个,你不想不提示模型)。
这里有两个主要的有趣的事情:
1)根据这个被调用的模式(OPEN_COPILOT/TODO_QUICK_FIX/UNKNOWN_FUNCTION_QUICK_FIX),它稍微修改了提示。别问我这些模式是如何激活的。
2)它从模型中请求了对数概率(logprobs),并根据平均对数概率对解决方案列表进行排序。
不显示无效的完成
在显示一个建议(通过任何用户界面)之前,Copilot会进行两次检查:
-
-
如果输出是重复的(例如,foo = foo = foo = foo...),这是语言模型的一个常见故障模式,那么建议就会被丢弃。这也可能在Copilot代理服务器或客户端,或者两者都发生。
-
如果用户已经输入了建议,那么它就会被丢弃。
-
Secret Sauce 3: Telemetry
Github声称程序员写的代码有40%(对于像Python这样的流行语言)是由Copilot写的。我很好奇他们是如何测量这个数字的,所以想深入了解一下遥测代码。
我还想知道收集了哪些遥测数据,特别是是否收集了代码片段。我想知道这个,因为虽然我们可以轻易地把Copilot扩展指向开源的FauxPilot后端,而不是Github的后端,但扩展可能仍然会通过遥测将代码片段发送给Github,阻止对他们的代码隐私感到担忧的人使用Copilot。我想知道是否是这种情况。
问题1:40%的数字是如何测量的?
测量Copilot的成功率并不仅仅是简单地计算接受的数量/拒绝的数量。这是因为人们通常会接受然后做一些修改。因此,Github的工作人员会检查是否还存在被接受的建议。这在插入后的不同时间长度内完成。具体来说,插入后的15秒、30秒、2分钟、5分钟和10分钟的超时后,扩展会测量接受的建议是否“仍在代码中”。
现在,进行精确搜索以查找接受的建议的存在是过于严格,所以他们使用编辑距离(字符级和词级)来测量建议的文本和插入点周围的窗口之间的距离。然后,如果插入的和窗口之间的'单词'级编辑距离小于50%(相对于建议的大小进行归一化),那么这个建议就被认为是“仍在代码中”。
当然,这只发生在接受的代码上。
问题2:遥测数据是否包含代码片段?
是的。
在接受/拒绝建议后的30秒,copilot会“捕获”插入点周围的一个快照。特别是,扩展调用提示提取机制来收集可能已经用于在那一点上提出建议的“假设提示”。它还通过捕获插入点和一个“猜测的”终点之间的代码,来捕获一个“假设的完成”,即,从那一点开始,与完成无关的代码开始。我还没有真正理解它是如何猜测这个终点的。如前所述,这在接受或拒绝后都会发生。
我怀疑这些快照基本上起到了作为进一步改进模型的训练数据的作用。然而,30秒似乎对于假设代码已经“稳定”来说,时间太短了。但是,我猜想,即使30秒的超时产生了噪音数据点,考虑到遥测数据包含了用户项目对应的github仓库,Copilot的工作人员也许可以清理这相对嘈杂的数据。所有这些都只是我的猜测。
重要更新
⚠️ 注意,Github确实允许你选择退出你的代码片段被用于“产品改进”。如果你这样做,包含这些片段的遥测点就不会被发送到服务器。也就是说,如果你选择退出,片段信息根本不会离开你的机器(至少在我查看的v1.57版本中,但也验证了v1.65版本)。我通过查看代码,以及在网络发送前记录遥测数据点来检查这一点。
其他随机细节
我稍微修改了扩展代码,以启用详细日志记录(找不到一个可配置的参数来实现这一点)。我发现模型被称为“cushman-ml”,这强烈暗示Copilot使用的是一个120亿参数模型,而不是一个1750亿参数模型。这对开源工作非常鼓舞人心,意味着一个中等大小的模型可以提供这样好的建议。当然,他们仍然没有Github拥有的数据飞轮。
我在这次探索中没有涉及的一件事是随扩展一起提供的worker.js文件。乍一看,它似乎只是提供了并行化的提示提取逻辑,但可能还有更多内容。
启用详细日志记录
如果你希望启用详细日志记录,可以按照以下步骤修改扩展代码:
搜索扩展文件。通常在~/.vscode/extensions/github.copilot-<version>/dist/extension.js下。 搜索字符串shouldLog(e,t,n){(如果找不到,试试shouldLog()。在几个搜索匹配中,其中一个将是一个非空的函数定义。 在函数体的开始,添加return true。 如果你想要一个现成的补丁,只需复制扩展代码。注意这是为1.57.7193版本。
未来
这是一个有趣的小项目,但它需要一些手动注释/逆向工程。我希望自动化大部分这样我也可以探索不同版本的Copilot,或者探索Copilot实验室...或者通常只是执行混淆的JS代码的自动反编译。我使用ChatGPT/Codex进行的初步实验是令人鼓舞的,但问题是它们不可靠。我有一个想法,可以自动检查反编译是否正确,基本上是通过进行一种形式的抽象解释。但那是另一天的事了。
总结,这个项目提供了深入理解Copilot运行原理和其数据收集方式的机会。通过深入研究,我们理解了Github如何衡量和追踪Copilot的成功率,以及他们如何收集和使用遥测数据,包括代码片段,以改进他们的产品。虽然仍有许多未知之处,但这个项目至少为那些对自己代码隐私感到担忧,或者对自动化编程感兴趣的人提供了一些洞见。希望这个研究可以激发更多的探索和进一步的研究,以便我们可以更好地理解和利用这些强大的工具。