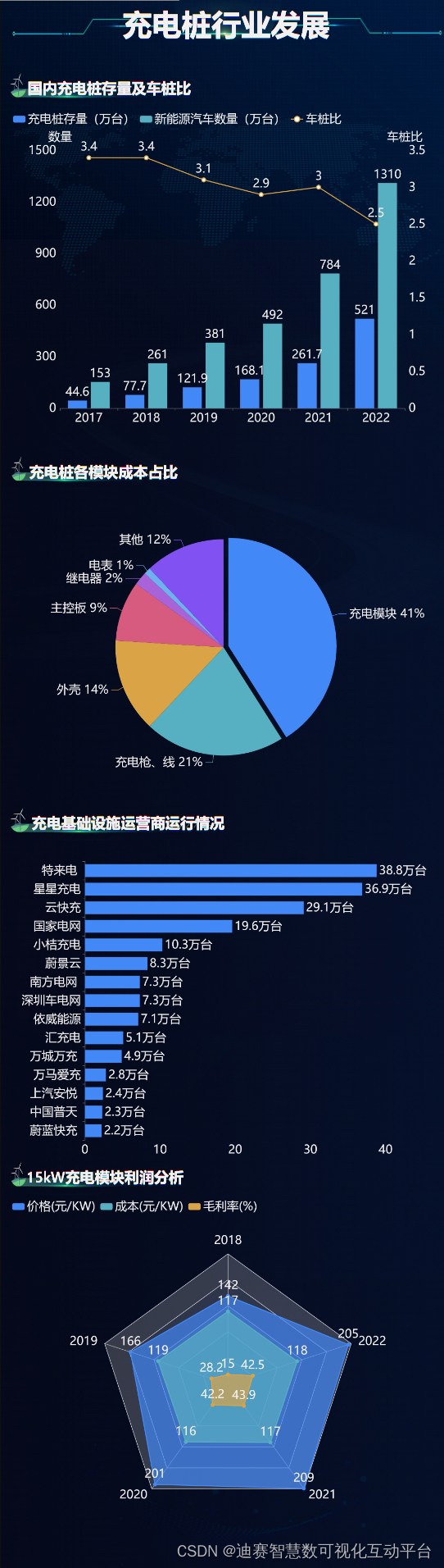
Robots.txt 文件是用于指导搜索引擎爬虫在网站上爬行的标准。正确地设计 Robots.txt 文件可以帮助 Google 爬虫更好地理解您的网站结构,从而提高您的网站在 Google 搜索引擎上的收录率。

以下是一些设计 Robots.txt 文件的技巧,可以帮助 Google 爬虫更好地爬行您的网站:
1. 不要阻止 Google 爬虫访问重要的页面和文件。确保您的 Robots.txt 文件不会禁止 Google 爬虫访问您的首页、产品页面、服务页面、关于我们页面和其他重要页面。这些页面对于您的网站的搜索引擎优化非常重要,确保它们可以被爬行。
2. 禁止 Google 爬虫访问无用的页面和文件。您可以在 Robots.txt 文件中禁止 Google 爬虫访问一些无用的页面和文件,如登录页面、注销页面、购物车页面、下载页面等等。这可以帮助 Google 爬虫更快地爬行您的网站,并提高搜索引擎的收录率。
3. 确保 Robots.txt 文件没有语法错误。确保您的 Robots.txt 文件没有语法错误,因为这可能会导致 Google 爬虫无法正确地读取您的文件。可以使用 Robots.txt 测试工具进行测试,以确保您的 Robots.txt 文件没有错误。
4. 使用 Robots.txt 文件来指导 Google 爬虫的爬行方式。您可以使用 Robots.txt 文件来指导 Google 爬虫如何爬行您的网站。例如,您可以指导 Google 爬虫不要爬行您的某些目录,或指导 Google 爬虫只爬行您的某些页面。这可以帮助您更好地控制搜索引擎优化,以获得更好的搜索引擎排名。
以下是一个简单的 Robots.txt 文件的示例:
User-agent: *
Disallow: /admin/
Disallow: /cart/
Disallow: /login/
Disallow: /logout/
Disallow: /search/
Sitemap: https://www.example.com/sitemap.xml
这个 Robots.txt 文件的含义是:
- User-agent: *:这个指令告诉所有搜索引擎爬虫,下面的规则都适用于他们。
- Disallow: /admin/:这个指令告诉搜索引擎爬虫不要访问 /admin/ 目录下的任何内容。
- Disallow: /cart/:这个指令告诉搜索引擎爬虫不要访问 /cart/ 目录下的任何内容。
- Disallow: /login/:这个指令告诉搜索引擎爬虫不要访问 /login/ 目录下的任何内容。
- Disallow: /logout/:这个指令告诉搜索引擎爬虫不要访问 /logout/ 目录下的任何内容。
- Disallow: /search/:这个指令告诉搜索引擎爬虫不要访问 /search/ 目录下的任何内容。
- Sitemap: https://www.example.com/sitemap.xml:这个指令告诉搜索引擎爬虫网站的 sitemap 地址,以帮助它更好地发现和索引网站的内容。
这个 Robots.txt 文件的目的是告诉搜索引擎爬虫哪些页面是不需要被索引和显示在搜索结果中的,以及网站的 sitemap 地址,以帮助搜索引擎更好地发现和索引网站的内容。