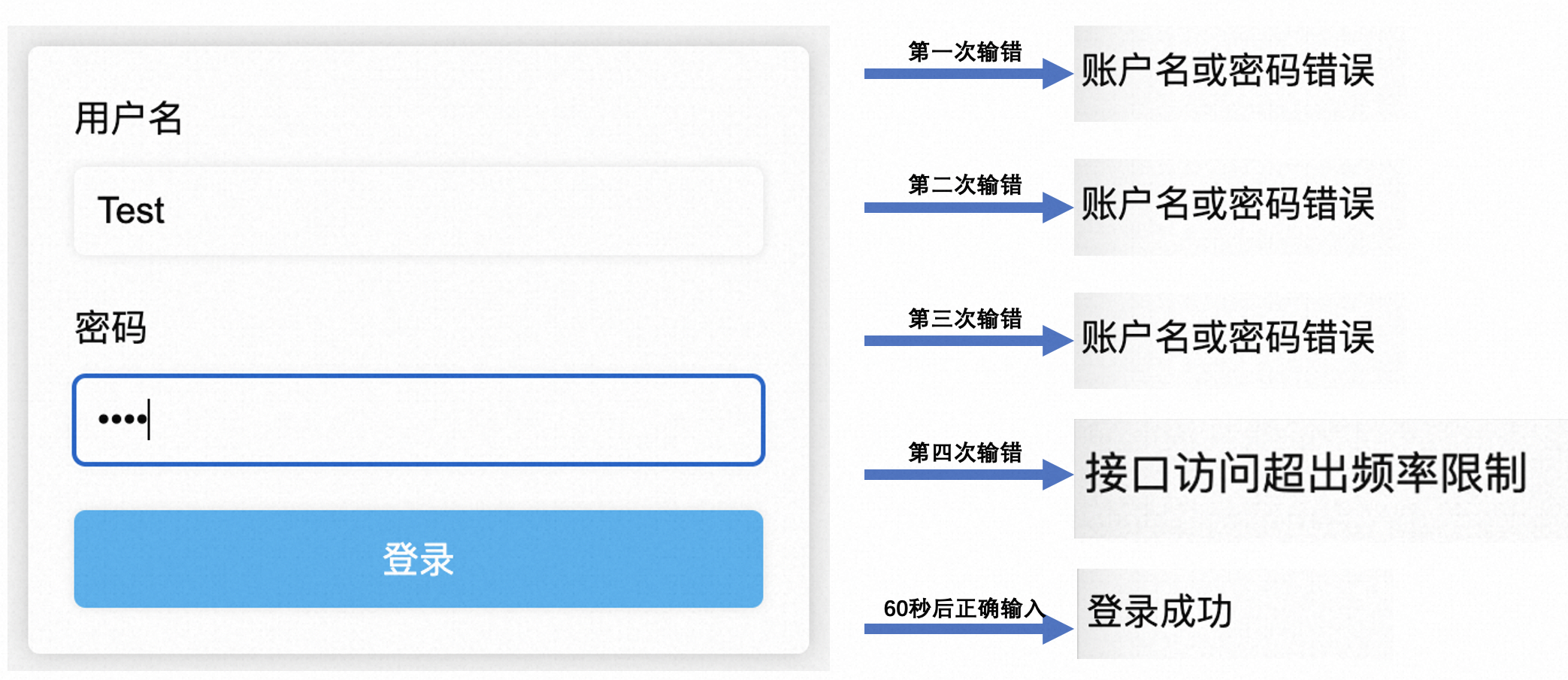
[2203.10321] Sequence-to-Sequence Knowledge Graph Completion and Question Answering (arxiv.org)
目录
1 Abstract
2 Introduction
3 KGT5 Model
3.1 Textual Representations & Verbalization
3.2 Training KGT5 for Link Prediction
3.3 Link Prediction Inference
3.4 KGQA Training and Inference
1 Abstract
KGE为每个实体和关系生成低维嵌入向量,在真实世界有数百万个实体的图上,会导致模型的参数过大。对于下游任务,这些实体表征需要集成到多阶段pipline中,限制了它们的使用。作者发现可以将encoder-decoder的Transformer当作KGE模型。将KG链接预测任务当作sequence-to-sequence任务,并将以前KGE模型使用的triple score方式变为自回归解码方式。
2 Introduction
作者将KG链接预测任务当作一个seq2seq的任务并且在这个任务上训练一个encoder-decoder的Transformer。使用预训练的模型进行链接预测,之后微调它用于QA。在对QA进行微调时,使用链接预测目标进行正则化。通过这种统一的seq2seq结构,实现了(1)可扩展性——通过使用组合实体表示和自回归解码(而不是对所有实体进行评分)进行推理(2)质量——在两个任务上获得了最先进的性能(3)多功能性——相同的模型可以用于多个数据集上的KGC和KGQA,以及(4)简单性——使用现成的模型获得所有结果,没有任务或数据集特定的超参数调整。
贡献:
(1)证明了KG链接预测和QA可以被视为序列到序列的任务,并使用单个编码器-解码器transformer成功解决;(2)使用这种称为KGT5的简单但强大的方法,将KG链路预测的模型大小减少了98%,同时在具有90M实体的数据集上优于传统的KGE;(3)通过KGQA在不完全图上的任务展示了这种方法的多功能性。通过对KG链路预测进行预训练和对QA进行微调,KGT5在多个大规模KGQA基准上的性能与更复杂的方法相似或更好。
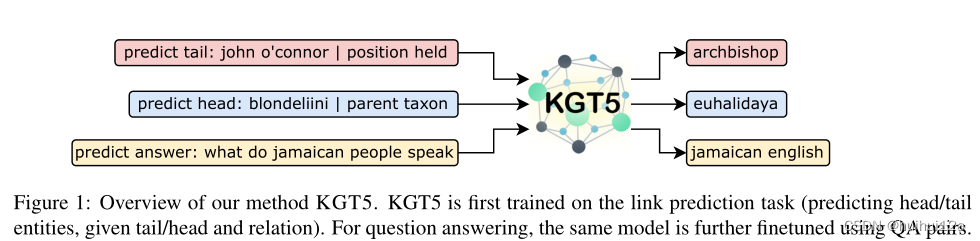
3 KGT5 Model
3.1 Textual Representations & Verbalization
Text mapping
将实体和关系映射到其对应的文本描述。
对于链接预测,需要实体/关系与其文本表示之间的一对一映射。对于基于Wikidata的KGs使用实体和关系的规范提及作为它们的文本表示,然后使用消歧方案,在名称后面添加描述和唯一ID。对于仅用于QA的数据集,不强制执行一对一映射,因为在这种情况下,不必要的歧义消除甚至可能会影响模型的性能。
Verbalization
将链接预测查询转换为文本查询。
通过将查询(s,p,?)描述为文本表示,将查询回答转换为序列到序列的任务。例如,给定一个查询(barackobama,born in,?),首先获得实体和关系的文本提及,然后将其表述为“预测尾部:barackobama| born in”。这个序列被输入到模型中,输出序列被期望是这个查询“united states”的答案,“united states”是实体美国的唯一提及。
3.2 Training KGT5 for Link Prediction
为了训练KGT5,需要一组(输入、输出)序列。对于训练图中的每个三元组(s,p,o),根据3.1描述查询(s,p,?)和(?,p,o)以获得两个输入序列。相应的输出序列分别是o和s的文本提及。
和标准的KGE模型相比,作者在没有明确负采样的情况下进行训练。在解码的每一步上,模型都会在可能的下一个token上产生概率分布。在训练时,该分布和真实token之间使用交叉熵损失。作者不是针对所有其他实体对真实实体进行评分,而是在每个步骤针对所有其他token对真实token进行评分,并且该过程重复的次数与标记的真实实体的长度一样多(一个实体由多个token组成)。这避免了对许多负样本的需要,并且与实体的数量无关。

这里面的vocabulary[v1,v2,…,vM]是所有可能token的集合,目标实体由多个token组成[w1,w2,…,wT]。
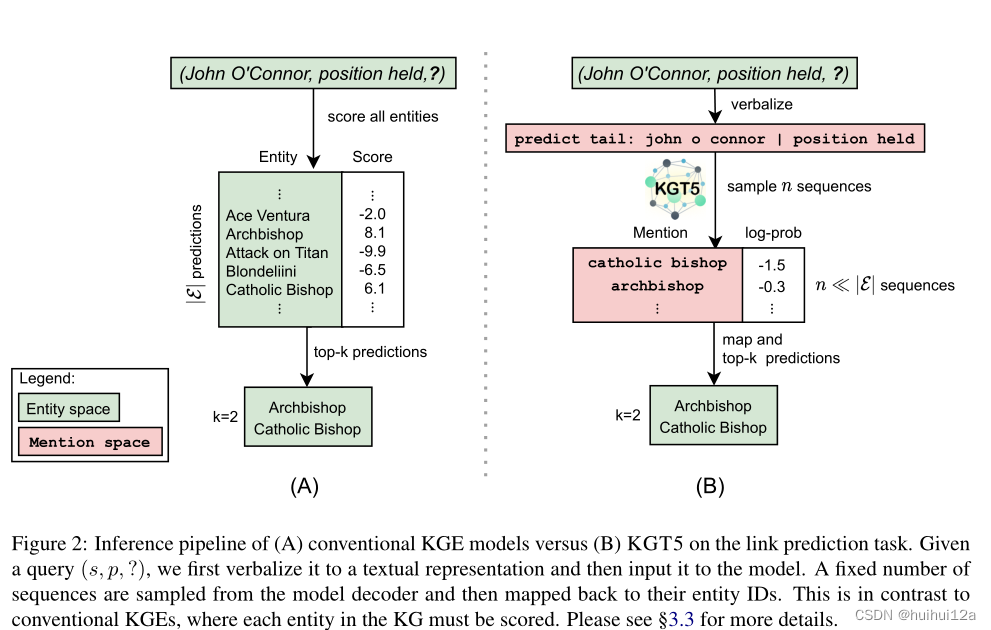
3.3 Link Prediction Inference
在传统的KGE模型中,通过找到分数f(s,p,o)∀o∈E来回答查询(s,p,?),其中f是特定于模型的评分函数。然后根据得分对实体o进行排名。
在本文方法中,给定查询(s,p,?),首先将其转换为语言表达,再将其提供给KGT5。然后,从解码器中采样固定数量的序列,然后映射到它们的实体ID。通过使用这样的生成模型,能够近似(高置信度)top-m模型预测,而不必像传统的KGE模型那样对KG中的所有实体进行评分。对于每个解码的实体们分配一个等于解码其序列的(log)概率的分数,即产生(实体,分数)对。为了计算与传统KGE模型相当的最终排名指标,为采样过程中未遇到的所有实体分配了-∞的分数。
3.4 KGQA Training and Inference
对于KGQA,使用链接预测任务在KG上进行链接预测来预训练模型,然后对相同的模型进行微调以进行问答。作者将新的任务前缀(predict answer:)和input question拼接起来,将回答的实体的mention string作为输出。这种统一的方法允许将KGT5应用于任何KGQA数据集,而不用考虑问题的复杂性,并且不需要子模块。
为了对抗QA微调过程中的过拟合(尤其是具有小KG的任务中),设计了一种正则化方案,将从KG中随机采样的链路预测序列添加到每个批次,使得一个批次由相等数量的QA和链路预测序列组成。为了进行推断,使用波束搜索,然后基于邻域的重新排序,从而获得单一答案的模型预测。