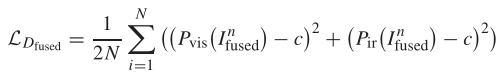行是知之始,知是行之成。——陶行知
目录
练习题 3 :求出各城市的平均温度
练习题4:请用scala得出以下的结果
练习题 3 :求出各城市的平均温度
val d1 = Array(("bj", 28.1), ("sh", 28.7), ("gz", 32.0), ("sz", 33.1))
val d2 = Array(("bj", 27.3), ("sh", 30.1), ("gz", 33.3))
val d3 = Array(("bj", 28.2), ("sh", 29.1), ("gz", 32.0), ("sz", 30.5))OUT===>
(gz,32.43)
(bj,27.87)
(sz,31.80)
(sh,29.30)
/**
* @author:码到成龚
* my motoo:"听闻少年二字,应与平庸相斥。"
* 个人代码规范:
* 1,原始数据的变量命名:①只使用单个单词即数据的类型:无嵌套的数据结构②被嵌套的数据结构类型_嵌套的数据结构类型:嵌套的数据结构
* 2,接收结果的变量命名:①包含的数据类型1_包含的数据类型2_返回的变量类型_表达式中使用到的函数1_表达式中使用到的函数2
* 3,调用函数时的注释:①数据调用第一个函数输出的结果为:函数名-OUT;函数名-OUT....以此类推
*
*/
object Test3 {
def main(args: Array[String]): Unit = {
val d1 = Array(("bj", 28.1), ("sh", 28.7), ("gz", 32.0), ("sz", 33.1))
val d2 = Array(("bj", 27.3), ("sh", 30.1), ("gz", 33.3))
val d3 = Array(("bj", 28.2), ("sh", 29.1), ("gz", 32.0), ("sz", 30.5))
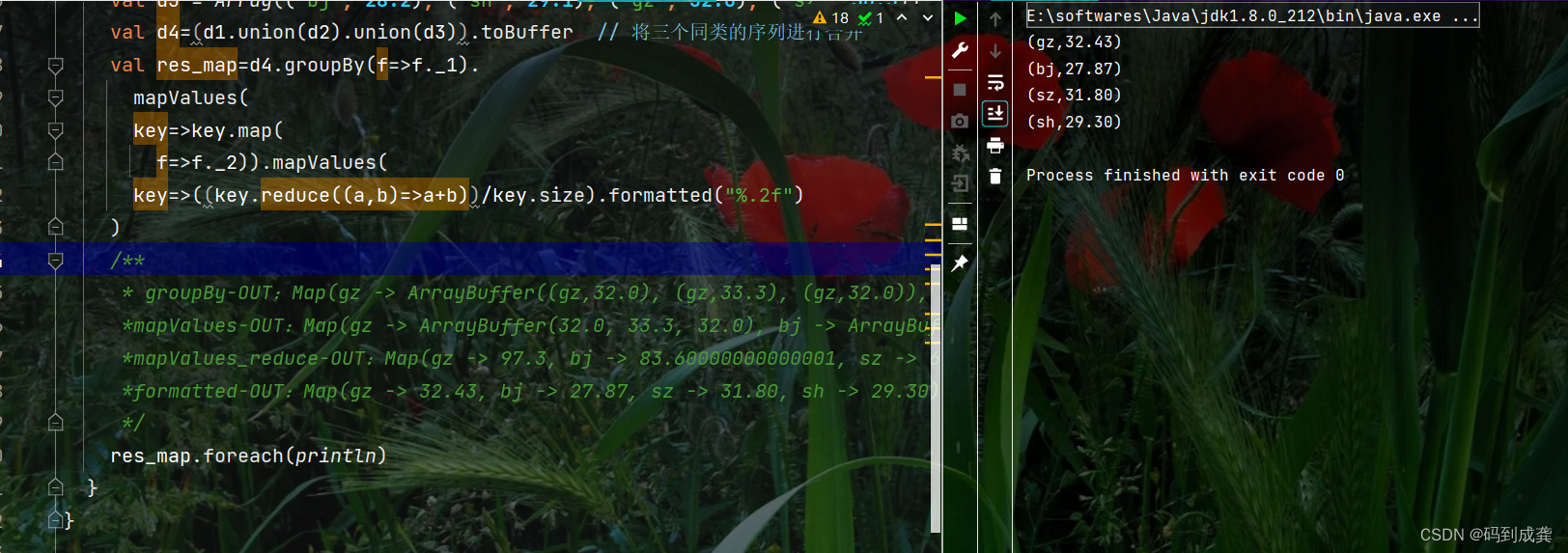
val d4=(d1.union(d2).union(d3)).toBuffer // 将三个同类的序列进行合并
val res_map=d4.groupBy(f=>f._1).
mapValues(
key=>key.map(
f=>f._2)).mapValues(
key=>((key.reduce((a,b)=>a+b))/key.size).formatted("%.2f")
)
/**
* groupBy-OUT:Map(gz -> ArrayBuffer((gz,32.0), (gz,33.3), (gz,32.0)), bj -> ArrayBuffer((bj,28.1), (bj,27.3), (bj,28.2)), sz -> ArrayBuffer((sz,33.1), (sz,30.5)), sh -> ArrayBuffer((sh,28.7), (sh,30.1), (sh,29.1)))
*mapValues-OUT:Map(gz -> ArrayBuffer(32.0, 33.3, 32.0), bj -> ArrayBuffer(28.1, 27.3, 28.2), sz -> ArrayBuffer(33.1, 30.5), sh -> ArrayBuffer(28.7, 30.1, 29.1))
*mapValues_reduce-OUT:Map(gz -> 97.3, bj -> 83.60000000000001, sz -> 63.6, sh -> 87.9)
*formatted-OUT:Map(gz -> 32.43, bj -> 27.87, sz -> 31.80, sh -> 29.30)
*/
res_map.foreach(println) // 遍历map集合
/**foreach-OUT:
* (gz,32.43)
* (bj,27.87)
* (sz,31.80)
* (sh,29.30)
*/
}
}练习题4:请用scala得出以下的结果
List("Id1-The Spark", "Id2-The Hadoop Yarn", "Id3-The Spark Yarn")
OUT===>
Spark:Id1 Id3
Hadoop:Id2
The:Id1 Id2 Id3
Yarn:Id2 Id3
import scala.collection.mutable
/**
* @author:码到成龚
* my motoo:"听闻少年二字,应与平庸相斥。"
* 个人代码规范:
* 1,原始数据的变量命名:①只使用单个单词即数据的类型:无嵌套的数据结构②被嵌套的数据结构类型_嵌套的数据结构类型:嵌套的数据结构
* 2,接收结果的变量命名:①包含的数据类型1_包含的数据类型2_返回的变量类型_表达式中使用到的函数1_表达式中使用到的函数2
* 3,调用函数时的注释:①数据调用第一个函数输出的结果为:函数名-OUT;函数名-OUT....以此类推
*
*/
object Test4 {
def main(args: Array[String]): Unit = {
val string_list = List("Id1-The Spark", "Id2-The Hadoop Yarn", "Id3-The Spark Yarn")
val array_list =
string_list.map(
string => string.split("[-| ]").toBuffer)
/**
* split_toBuffer-OUT:List(ArrayBuffer(Id1, The, Spark), ArrayBuffer(Id2, The, Hadoop, Yarn), ArrayBuffer(Id3, The, Spark, Yarn))
*
*/
var tup2_m_arr = mutable.ArrayBuffer[(String, String)]()
for (arr <- array_list) { // 遍历最外层的列表,得到数组
for (elem <- 1 until arr.length) { // 遍历内层的数组,得到索引
tup2_m_arr.append((arr(elem), arr(0))) // 将遍历到的数组添加进入创建的可变数组中
/**
* 观察输出的结果可知,是以Id后面的单词作为键,Id为值,
* 因此,在添加元素的时候,不遍历第一个元素,直接指定即可
*/
}}
/*
println(tup2_m_arr)-OUT:ArrayBuffer((The,Id1), (Spark,Id1), (The,Id2), (Hadoop,Id2),(Yarn,Id2), (The,Id3), (Spark,Id3), (Yarn,Id3))
*/
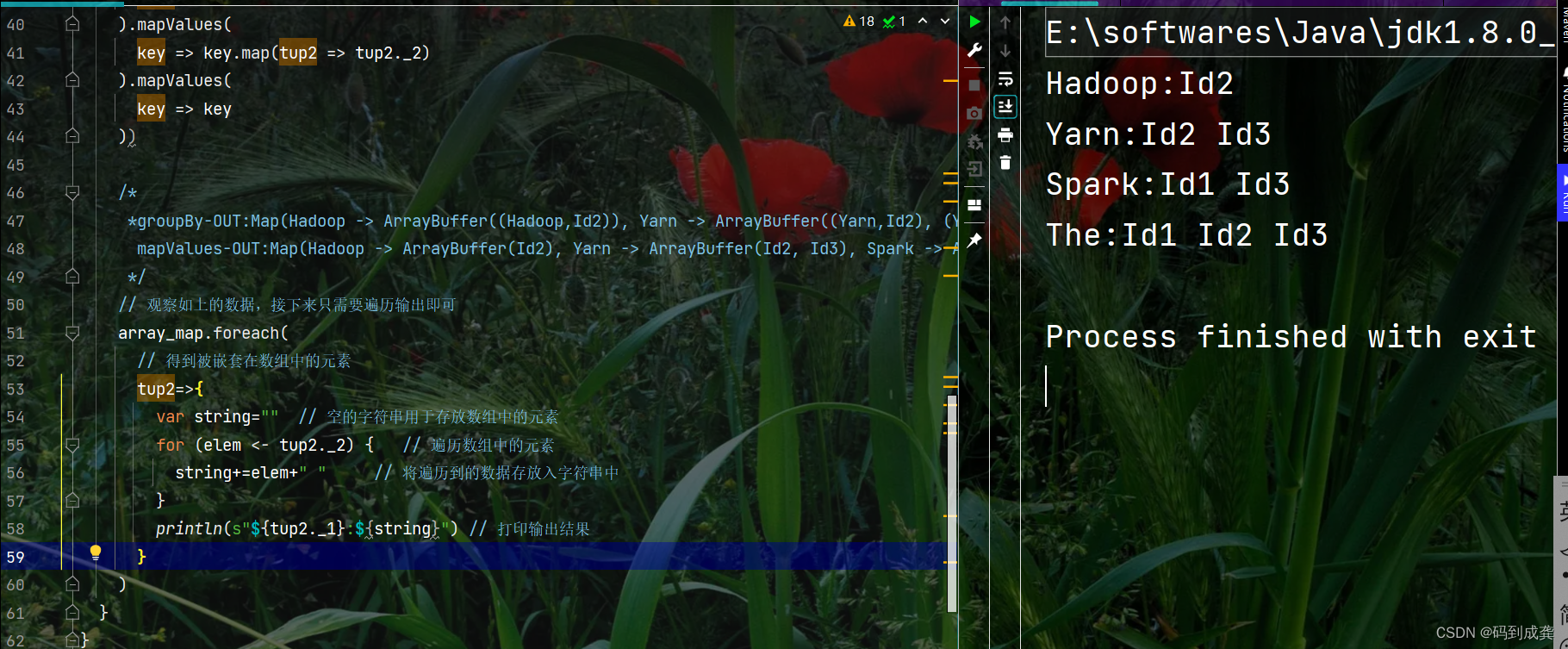
val array_map = (tup2_m_arr.groupBy(
tup2 => tup2._1
).mapValues(
key => key.map(tup2 => tup2._2)
).mapValues(
key => key
))
/*
*groupBy-OUT:Map(Hadoop -> ArrayBuffer((Hadoop,Id2)), Yarn -> ArrayBuffer((Yarn,Id2), (Yarn,Id3)), Spark -> ArrayBuffer((Spark,Id1), (Spark,Id3)), The -> ArrayBuffer((The,Id1), (The,Id2), (The,Id3)))
mapValues-OUT:Map(Hadoop -> ArrayBuffer(Id2), Yarn -> ArrayBuffer(Id2, Id3), Spark -> ArrayBuffer(Id1, Id3), The -> ArrayBuffer(Id1, Id2, Id3))
*/
// 观察如上的数据,接下来只需要遍历输出即可
array_map.foreach(
// 得到被嵌套在数组中的元素
tup2=>{
var string="" // 空的字符串用于存放数组中的元素
for (elem <- tup2._2) { // 遍历数组中的元素
string+=elem+" " // 将遍历到的数据存放入字符串中
}
println(s"${tup2._1}:${string}") // 打印输出结果
}
)
}
}
如果对以上的代码有任何问题的,请在评论区留言。
如果觉得代码有更优的解,也欢迎在评论区展示您的代码。