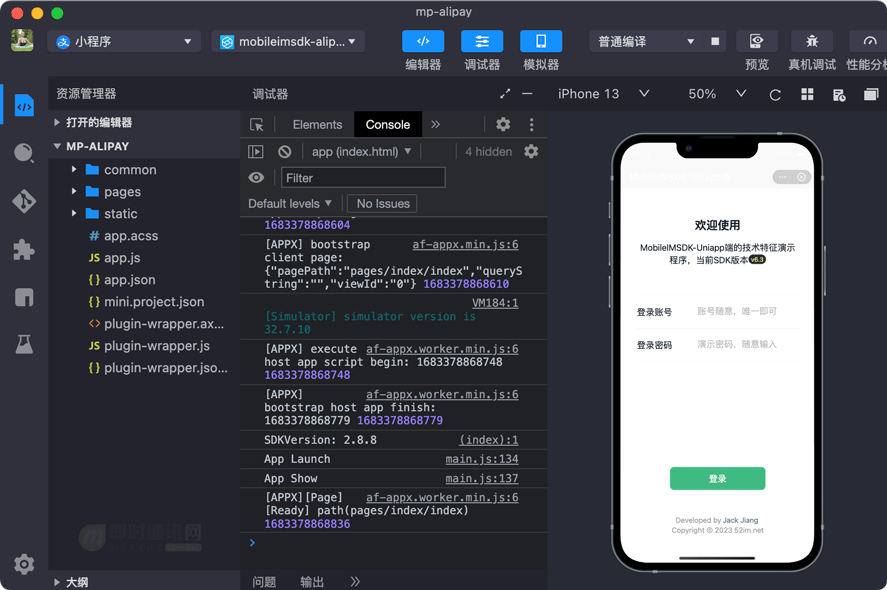
"reason": "Failed to parse mapping: analyzer [ik_max_word] has not been configured in mappings"
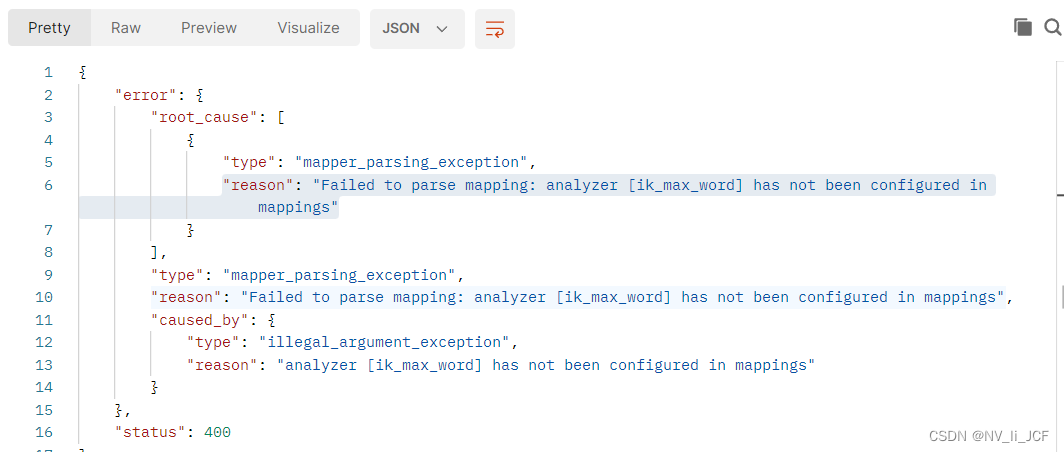
这是因为没有安装ES的IK分词器
下载地址 Release v8.7.0 · medcl/elasticsearch-analysis-ik · GitHub
ElasticSearch 内置了分词器,如标准分词器、简单分词器、空白词器等。但这些分词器对我们最常使用的中文并不友好,不能按我们的语言习惯进行分词。
ik分词器就是一个标准的中文分词器。它可以根据定义的字典对域进行分词,并且支持用户配置自己的字典,所以它除了可以按通用的习惯分词外,我们还可以定制化分词。
ik分词器是一个插件包,我们可以用插件的方式将它接入到ES。
一、安装
1.1 下载
medcl/elasticsearch-analysis-ikgithub.com/medcl/elasticsearch-analysis-ik
注意:下载的包一定要和 ElasticSearch 的版本一致。点击右侧的 Releases ,选择版本

不要下载源码包

1.2 安装
将下载的zip包解压到ES的 plugins 目录即可,别忘了重启ES
以windows为例
在ES目录的plugins目录下创建ik子目录,然后将解压的内容移到里面
注意:删除拷贝过来的 elasticsearch-analysis-ik-7.12.1.zip 包

最后重启ES,界面可以看到加载的ik插件

也可以用命令查看当前加载的ik插件

重启过程可能会出现闪退情况,不要慌。按前面提到的注意事项检查
1、版本号是否匹配
2、包是否下载错
3、多余包是否删除
二 、ik分词器2种模式
ik_smart 最粗粒度的拆分
ik_max_word 最细粒度的拆分
它们其实就是2中分词算法,其区别直接通过测试观察
三、测试
ik_smart

ik_max_word

可以看出 ik_max_word 比 ik_smart 划分的词条更多,这就是它们为什么叫做最细粒度和最粗粒度。
四、自定义字典
问题:如何把 金毛狮王 拆分成“金毛”“狮王”“金毛狮王”三个词条?
默认2种模式都会拆分成 “金”“毛”“狮王”三个词条。不符合我们的要求

根据默认拆分的结果,发现我们需要增加“金毛”和“金毛狮王”2个词条并删除“金”和“毛”2个词条。这里就可以用自定义字典来实现
打开 ..\elasticsearch-7.12.1\plugins\ik\config\IKAnalyzer.cfg
可以看到有2个配置 ext_dict 和 ext_stopwords。分别是扩展和停用字典

参照默认的dic文件,在config目录新建 my_ext.dic 和 my_stop.dic


然后配置到 IKAnalyzer.cfg

重启ES。启动日志可以看到加载了我们的字典

测试
ik_max_word 正是我们想要的效果

ik_smart 只有金毛狮王一个词条

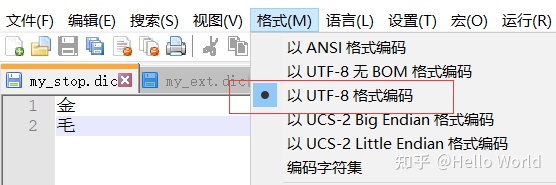
注意:配置好重启后可能发现并没有效果,不慌,检查下文件的编码格式是否UTF-8
Plugin [analysis-ik] was built for Elasticsearch version 8.7.0 but version 8.7.1 is running
ik分词器和es版本号不一致导致的