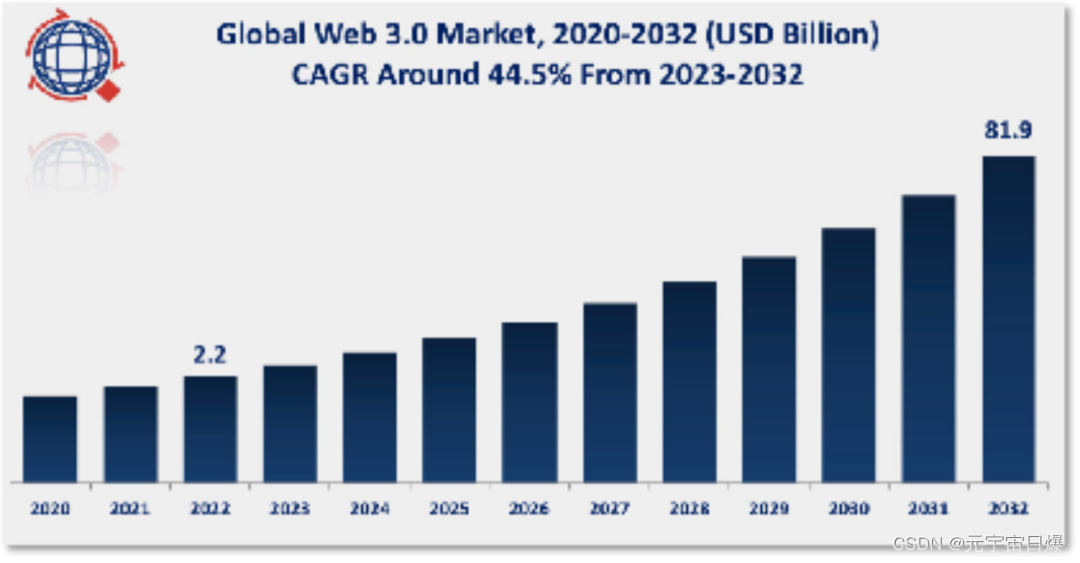
OpenCL上下文
上下文是所有OpenCL应用的核心。上下文为关联的设备、内存对象(例如,缓冲区和图像)以及命令队列(在上下文和各设备之间提供一个接口)提供了一个容器。正是上下文驱动着应用程序与特定设备以及特定设备之间的通信,为此OpenCL定义了内存模型。例如,内存对象分配有一个上下文,不过可以由特定的设备来更新,OpenCL 的内存保证相同上下文中的所有设备可以在明确定义的同步点看到这些更新。
有一点很重要,要认识到尽管通常这些阶段可以构成OpenCL程序的基础,不过完全可以使用多个上下文,分别由不同平台创建,并把工作分布到这些上下文和关联的设备上。区别在于,OpenCL的内存模型不会跨设备,这说明内存对象不能由不同的上下文(可能由相同或不同的平台创建)共享。这也意味着,需要在上下文之间共享的数据必须手动在上下文间移动。这个概念如图3-1所示。
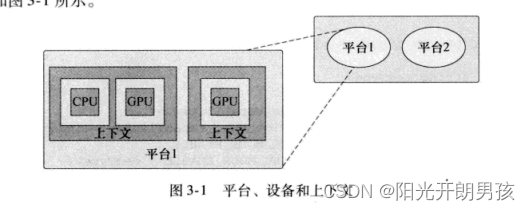
通常平台和设备会在程序或库的开始位置查询,与之不同,你可能希望在程序运行过程中更新上下文,或者分配或删除内存对象等。一般地,应用程序会这样使用OpenCL:
1)查询有哪些平台。
2)查询各个平台支持的设备集:
使用clGetDeviceInfo()为特定功能选择设备。
3)由选择的设备创建上下文(必须由一个平台的设备创建各个上下文),然后利用上下文可以做到:
a.创建一个或多个命令队列。
b.创建程序,使它在一个或多个关联设备上运行。
c.从这些程序创建一个内核。
d.在宿主机或设备上分配内存缓冲区和图像。
e.将数据写至或复制到特定设备,或者由设备写数据。
f.将内核(设置适当的参数)提交到命令队列来执行。
给定一个平台和一组关联设备,可以用命令clCreateContext()创建一个OpenCL 上下文,如果有平台和设备类型,可以使用clcreateContextFromType()创建上下文。这两个函数声明为:
extern CL_API_ENTRY cl_context CL_API_CALL
clCreateContext(const cl_context_properties * properties,
cl_uint num_devices,
const cl_device_id * devices,
void (CL_CALLBACK * pfn_notify)(const char * errinfo,
const void * private_info,
size_t cb,
void * user_data),
void * user_data,
cl_int * errcode_ret) CL_API_SUFFIX__VERSION_1_0;
extern CL_API_ENTRY cl_context CL_API_CALL
clCreateContextFromType(const cl_context_properties * properties,
cl_device_type device_type,
void (CL_CALLBACK * pfn_notify)(const char * errinfo,
const void * private_info,
size_t cb,
void * user_data),
void * user_data,
cl_int * errcode_ret) CL_API_SUFFIX__VERSION_1_0;
这会创建一个OpenCL上下文。参数properties的可取值如下。
CL_CONTEXT_PLATFORM cl_platform_id 指定要使用的平台
这里列出的属性只是与上下文关联的平台。其他上下文属性用特定的OpenCL扩展定义。参数 devices和 device_type分别允许显式地指定设备集或者限制为特定的设备类型。参数 pfn_notify和user_data用来共同定义一个回调,可以调用这个回调报告上下文生命期中所出现错误的有关信息,要把user_data作为最后一个参数传至回调。
给定一个平台,下面的例子展示了如何查询GPU设备集,如果有一个或多个设备,还可以创建一个上下文。
cl_platform pform;
size_t num;
cl_device_id *devices;
cl_context context;
size_t size;
clGetDeviceIDs(platform, CL_DEVICE_TYPE_GPU, 0, NULL, &num);
if (num > 0)
{
devices = (cl_device_id *)alloca(num);
clGetDeviceIDs(platform, CL_DEVICE_TYPE_GPU, num, &devices[0], NULL);
}
cl_context_properties properties[] =
{
CL_CONTEXT_PLATFORM, (cl_context_properties)platform, 0
};
context = clCreateContext(properties, size/sizeof(cl_device_id), devices, NULL, NULL, NULL);
给定一个上下文,可以用以下命令查询各个属性:
extern CL_API_ENTRY cl_int CL_API_CALL
clGetContextInfo(cl_context context,
cl_context_info param_name,
size_t param_value_size,
void * param_value,
size_t * param_value_size_ret) CL_API_SUFFIX__VERSION_1_0;
这个命令返回OpenCL上下文的特定信息。参数param_name定义了合法的查询:
CL_CONTEXT_REFERENCE_COUNT cl_uint 返回上下文引用计数
CL_CONTEXT_NUM_DEVICES cl_uint 返回上下文中的设备数
CL_CONTEXT_DEVICES cl_device_ia[] 返回上下文中的设备列表
CL_CONTEXT_PROPERTIES cl_context_properties[] 返回clCreatecontext或clcreatecontextFromType中指定的properties参数。
如果用来创建上下文的clCreateContext或clCreateContextFromType中指定的properties参数不为NULL,
则这个实现必须返回properties参数中指定的值;
如果用来创建上下文的clCreateContext或c1CreatecontextFromType中指定的properties参数为NULL,
则实现可能返回param_value_size_ret为0
(也就是说,没有要返回的上下文属性值),
或者在param_value指向的内存中返回上下文属性值0(用来终止上下文属性列表)
下面的例子展示了如何使用clGetContextInfo()查询一个上下文,得到关联设备列表:
cl_uint numPlatforms;
cl_platform_id *platformIDs;
cl_context context = NULL;
size_t size;
clGetPlatformIDs(0, NULL, &numPlatforms);
platformIDs = (cl_platform_id *)alloca(sizeof(cl_platform_id) * numPlatforms);
clGetPlatformIDs(numPlatforms, platformIDs, NULL);
cl_context_properties properties[] =
{
CL_CONTEXT_PLATFORM, (cl_context_properties)platformIDs[0], 0
};
context = clCreateContextFromType(properties, CL_DEVICE_TYPE_ALL, NULL, NULL, NULL);
clGetContextInfo(context, CL_CONTEXT_DEVICES, 0, NULL, &size);
cl_device_id *devices = (cl_device_id*)alloca(sizeof(cl_device_id) * size);
clGetContextInfo(context, CL_CONTEXT_DEVICES, size, devices, NULL);
for (size_t i = 0; i < size / sizeof(cl_device_id); i++)
{
cl_device_type type;
clGetDeviceInfo(devices[i], CL_DEVICE_TYPE, sizeof(cl_device_type), &type, NULL);
switch(type)
{
case CL_DEVICE_TYPE_GPU:
std::cout << "CL_DEVICE_TYPE_GPU" << std::endl;
break;
case CL_DEVICE_TYPE_CPU:
std::cout << "CL_DEVICE_TYPE_CPU" << std::endl;
break;
case CL_DEVICE_TYPE_ACCELERATOR:
std::cout << "CL_DEVICE_TYPE_ACCELERATOR" << std::endl;
break;
}
}
在ATI Stream SDK上,对于有一个Intel i7 CPU设备和ATI Radeon 5780的机器,会显示以下结果:
CL_DEVICE_TYPE_CPU
CL_DEVICE_TYPE_GPU
类似于所有OpenCL对象,上下文是引用技术,可以用以下两个命令递增和递减引用数:
cl_int clRetainContext(cl_context context)
cl_int clReleaseContext(cl_context context)
这两个命令会分别将一个上下文的引用计数递增和递减。
最后我们构建了一个简单的例子,它会完成一个输入信号的卷积。卷积是很多信号处理应用中都会出现的常见操作,最简单的形式是将-个信号(输入信号)与另一个信号(模板)结合生成一个最终输出(输出信号)。卷积对于OpenCL是一个非常好的应用。通过卷积可以展示大量输入的大规模数据并行性,而且有很好的数据环境,允许使用OpenCL的共享构造。
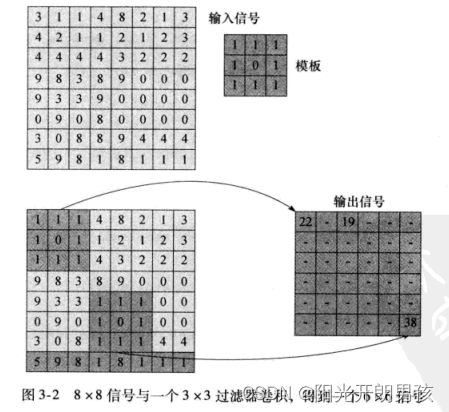
图3-2显示了将一个3×3模板应用到一个8×8输入信号的过程,最后会得到一个6×6的输出信号。这个算法很简单,输出信号的每个样本如下生成:
1)将模板置于输入信号上,以相应的输入位置为中心。
2)将输入值与模板中的相应元素相乘。
3)将第2步的结果累加为一个和,写至相应的输出位置。
对于输出信号中的各个位置,根据下面代码,由内核convolve完成前面的步骤。也就是说,各个输出结果可以并行计算。
Convolution.cl
__kernel void convolve(
const __global uint * const input,
__constant uint * const mask,
__global uint * const output,
const int inputWidth,
const int maskWidth)
{
const int x = get_global_id(0);
const int y = get_global_id(1);
uint sum = 0;
for (int r = 0; r < maskWidth; r++)
{
const int idxIntmp = (y + r) * inputWidth + x;
for (int c = 0; c < maskWidth; c++)
{
sum += mask[(r * maskWidth) + c] * input[idxIntmp + c];
}
}
output[y * get_global_size(0) + x] = sum;
}
下面代码包含这个简单例子的宿主机代码。主函数首先查询可用的平台列表,然后使用clGetDeviceIDs()迭代处理这个平台列表,获取各个平台支持的一组CPU设备类型,如果至少找到一个设备,这个循环就终止。如果没有找到任何CPU设备,程序会直接退出;否则会用找到的设备列表创建一个上下文,然后从磁盘加载内核源代码并编译,创建一个内核对象。再创建输入/输出缓冲区,最后设置内核参数并执行这个内核。程序最后读取输出的信号,并把结果输出到stdout。
Convolution.cpp
//
// Book: OpenCL(R) Programming Guide
// Authors: Aaftab Munshi, Benedict Gaster, Timothy Mattson, James Fung, Dan Ginsburg
// ISBN-10: 0-321-74964-2
// ISBN-13: 978-0-321-74964-2
// Publisher: Addison-Wesley Professional
// URLs: http://safari.informit.com/9780132488006/
// http://www.openclprogrammingguide.com
//
// Convolution.cpp
//
// This is a simple example that demonstrates OpenCL platform, device, and context
// use.
#include <iostream>
#include <fstream>
#include <sstream>
#include <string>
#ifdef __APPLE__
#include <OpenCL/cl.h>
#else
#include <CL/cl.h>
#endif
#if !defined(CL_CALLBACK)
#define CL_CALLBACK
#endif
#pragma warning( disable : 4996 )
// Constants
const unsigned int inputSignalWidth = 8;
const unsigned int inputSignalHeight = 8;
cl_uint inputSignal[inputSignalWidth][inputSignalHeight] =
{
{3, 1, 1, 4, 8, 2, 1, 3},
{4, 2, 1, 1, 2, 1, 2, 3},
{4, 4, 4, 4, 3, 2, 2, 2},
{9, 8, 3, 8, 9, 0, 0, 0},
{9, 3, 3, 9, 0, 0, 0, 0},
{0, 9, 0, 8, 0, 0, 0, 0},
{3, 0, 8, 8, 9, 4, 4, 4},
{5, 9, 8, 1, 8, 1, 1, 1}
};
const unsigned int outputSignalWidth = 6;
const unsigned int outputSignalHeight = 6;
cl_uint outputSignal[outputSignalWidth][outputSignalHeight];
const unsigned int maskWidth = 3;
const unsigned int maskHeight = 3;
cl_uint mask[maskWidth][maskHeight] =
{
{1, 1, 1}, {1, 0, 1}, {1, 1, 1},
};
///
// Function to check and handle OpenCL errors
inline void
checkErr(cl_int err, const char* name)
{
if (err != CL_SUCCESS) {
std::cerr << "ERROR: " << name << " (" << err << ")" << std::endl;
exit(EXIT_FAILURE);
}
}
void CL_CALLBACK contextCallback(
const char* errInfo,
const void* private_info,
size_t cb,
void* user_data)
{
std::cout << "Error occured during context use: " << errInfo << std::endl;
// should really perform any clearup and so on at this point
// but for simplicitly just exit.
exit(1);
}
///
// main() for Convoloution example
//
int main(int argc, char** argv)
{
cl_int errNum;
cl_uint numPlatforms;
cl_uint numDevices;
cl_platform_id* platformIDs;
cl_device_id* deviceIDs;
cl_context context = NULL;
cl_command_queue queue;
cl_program program;
cl_kernel kernel;
cl_mem inputSignalBuffer;
cl_mem outputSignalBuffer;
cl_mem maskBuffer;
// First, select an OpenCL platform to run on.
errNum = clGetPlatformIDs(0, NULL, &numPlatforms);
checkErr(
(errNum != CL_SUCCESS) ? errNum : (numPlatforms <= 0 ? -1 : CL_SUCCESS),
"clGetPlatformIDs");
platformIDs = (cl_platform_id*)alloca(
sizeof(cl_platform_id) * numPlatforms);
errNum = clGetPlatformIDs(numPlatforms, platformIDs, NULL);
checkErr(
(errNum != CL_SUCCESS) ? errNum : (numPlatforms <= 0 ? -1 : CL_SUCCESS),
"clGetPlatformIDs");
// Iterate through the list of platforms until we find one that supports
// a CPU device, otherwise fail with an error.
deviceIDs = NULL;
cl_uint i;
for (i = 0; i < numPlatforms; i++)
{
errNum = clGetDeviceIDs(
platformIDs[i],
CL_DEVICE_TYPE_CPU,
0,
NULL,
&numDevices);
if (errNum != CL_SUCCESS && errNum != CL_DEVICE_NOT_FOUND)
{
checkErr(errNum, "clGetDeviceIDs");
}
else if (numDevices > 0)
{
deviceIDs = (cl_device_id*)alloca(sizeof(cl_device_id) * numDevices);
errNum = clGetDeviceIDs(
platformIDs[i],
CL_DEVICE_TYPE_CPU,
numDevices,
&deviceIDs[0],
NULL);
checkErr(errNum, "clGetDeviceIDs");
break;
}
}
// Check to see if we found at least one CPU device, otherwise return
if (deviceIDs == NULL) {
std::cout << "No CPU device found" << std::endl;
exit(-1);
}
// Next, create an OpenCL context on the selected platform.
cl_context_properties contextProperties[] =
{
CL_CONTEXT_PLATFORM,
(cl_context_properties)platformIDs[i],
0
};
context = clCreateContext(
contextProperties,
numDevices,
deviceIDs,
&contextCallback,
NULL,
&errNum);
checkErr(errNum, "clCreateContext");
std::ifstream srcFile("Convolution.cl");
checkErr(srcFile.is_open() ? CL_SUCCESS : -1, "reading Convolution.cl");
std::string srcProg(
std::istreambuf_iterator<char>(srcFile),
(std::istreambuf_iterator<char>()));
const char* src = srcProg.c_str();
size_t length = srcProg.length();
// Create program from source
program = clCreateProgramWithSource(
context,
1,
&src,
&length,
&errNum);
checkErr(errNum, "clCreateProgramWithSource");
// Build program
errNum = clBuildProgram(
program,
numDevices,
deviceIDs,
NULL,
NULL,
NULL);
if (errNum != CL_SUCCESS)
{
// Determine the reason for the error
char buildLog[16384];
clGetProgramBuildInfo(
program,
deviceIDs[0],
CL_PROGRAM_BUILD_LOG,
sizeof(buildLog),
buildLog,
NULL);
std::cerr << "Error in kernel: " << std::endl;
std::cerr << buildLog;
checkErr(errNum, "clBuildProgram");
}
// Create kernel object
kernel = clCreateKernel(
program,
"convolve",
&errNum);
checkErr(errNum, "clCreateKernel");
// Now allocate buffers
inputSignalBuffer = clCreateBuffer(
context,
CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR,
sizeof(cl_uint) * inputSignalHeight * inputSignalWidth,
static_cast<void*>(inputSignal),
&errNum);
checkErr(errNum, "clCreateBuffer(inputSignal)");
maskBuffer = clCreateBuffer(
context,
CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR,
sizeof(cl_uint) * maskHeight * maskWidth,
static_cast<void*>(mask),
&errNum);
checkErr(errNum, "clCreateBuffer(mask)");
outputSignalBuffer = clCreateBuffer(
context,
CL_MEM_WRITE_ONLY,
sizeof(cl_uint) * outputSignalHeight * outputSignalWidth,
NULL,
&errNum);
checkErr(errNum, "clCreateBuffer(outputSignal)");
// Pick the first device and create command queue.
queue = clCreateCommandQueue(
context,
deviceIDs[0],
0,
&errNum);
checkErr(errNum, "clCreateCommandQueue");
errNum = clSetKernelArg(kernel, 0, sizeof(cl_mem), &inputSignalBuffer);
errNum |= clSetKernelArg(kernel, 1, sizeof(cl_mem), &maskBuffer);
errNum |= clSetKernelArg(kernel, 2, sizeof(cl_mem), &outputSignalBuffer);
errNum |= clSetKernelArg(kernel, 3, sizeof(cl_uint), &inputSignalWidth);
errNum |= clSetKernelArg(kernel, 4, sizeof(cl_uint), &maskWidth);
checkErr(errNum, "clSetKernelArg");
const size_t globalWorkSize[1] = { outputSignalWidth * outputSignalHeight };
const size_t localWorkSize[1] = { 1 };
// Queue the kernel up for execution across the array
errNum = clEnqueueNDRangeKernel(
queue,
kernel,
1,
NULL,
globalWorkSize,
localWorkSize,
0,
NULL,
NULL);
checkErr(errNum, "clEnqueueNDRangeKernel");
errNum = clEnqueueReadBuffer(
queue,
outputSignalBuffer,
CL_TRUE,
0,
sizeof(cl_uint) * outputSignalHeight * outputSignalHeight,
outputSignal,
0,
NULL,
NULL);
checkErr(errNum, "clEnqueueReadBuffer");
// Output the result buffer
for (int y = 0; y < outputSignalHeight; y++)
{
for (int x = 0; x < outputSignalWidth; x++)
{
std::cout << outputSignal[x][y] << " ";
}
std::cout << std::endl;
}
std::cout << std::endl << "Executed program succesfully." << std::endl;
return 0;
}
卷积
卷积运算是指从图像的左上角开始,开一个与模板同样大小的活动窗口,窗口图像与模板像元对应起来相乘再相加,并用计算结果代替窗口中心的像元亮度值。然后,活动窗口向右移动一列,并作同样的运算。以此类推,从左到右、从上到下,即可得到一幅新图像。

如上图,卷积操作其实就是每次取一个特定大小的矩阵F(蓝色矩阵中的阴影部分),然后将其对输入X(图中蓝色矩阵)依次扫描并进行内积的运算过程。可以看到,阴影部分每移动一个位置就会计算得到一个卷积值(绿色矩阵中的阴影部分),当F扫描完成后就得到了整个卷积后的结果Y(绿色矩阵)。
同时,我们将这个特定大小的矩阵F称为卷积核,即convolutional kernel或kernel或filter或detector,它可以是一个也可以是多个;将卷积后的结果Y称为特征图,即feature map,并且每一个卷积核卷积后都会得到一个对应的特征图;最后,对于输入X)的形状,都会用三个维度来进行表示,即宽(width),高(high)和通道(channel)。例如图中输入X的形状为[7,7,1]。
多卷积核
卷积核的个数还可以是多个,那我们为什么需要多个卷积核进行卷积呢?
对于一个卷积核,可以认为其具有识别某一类元素(特征)的能力;而对于一些复杂的数据来说,仅仅只是通过一类特征来进行辨识往往是不够的。因此,通常来说我们都会通过多个不同的卷积核来对输入进行特征提取得到多个特征图,然再输入到后续的网络中。
多卷积核视频
如上图所示,对于同一个输入,通过两个不同的卷积核对其进行卷积特征提取,最后便能得到两个不同的特征图。从图2右边的特征图可以发现,上面的特征图在锐利度方面明显会强于下面的特征图。当然,这也是使用多卷积核进行卷积的意义,探测到多种特征属性以有利于后续的下游任务。
偏置项
偏置项(bias)是一个常数,它与卷积核一起作用于输入数据,用于调整输出结果的偏移。具体来说,偏置项可以看作是一个与卷积核大小相同、但只有一个深度的数组,其中的每个元素都加到卷积的输出中。
卷积层的中偏置项可以帮助模型学习数据的偏移量和偏差,从而提高模型的准确性和稳定性。偏置项的调整可以通过反向传播算法自动完成,使得模型能够快速适应不同的数据。
在实际应用中,偏置项的值通常设置为0或一个小的常数,以免梯度爆炸或梯度消失等问题。同时,由于偏置项与卷积核的大小相同,因此在训练过程中需要对其进行更新和调整。
单通道单卷积核
如下图所示,现在有一张形状为[5,5,1]的灰度图,我们需要用图3右边的卷积核对其进行卷积处理,同时再考虑到偏置的作用。那么其计算过程是怎么样的呢?
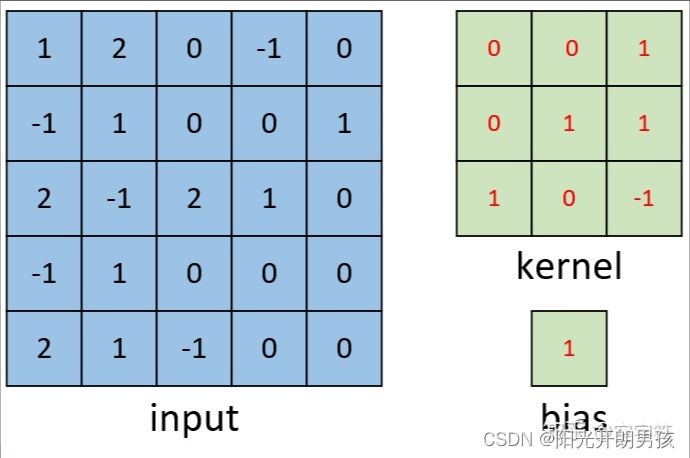
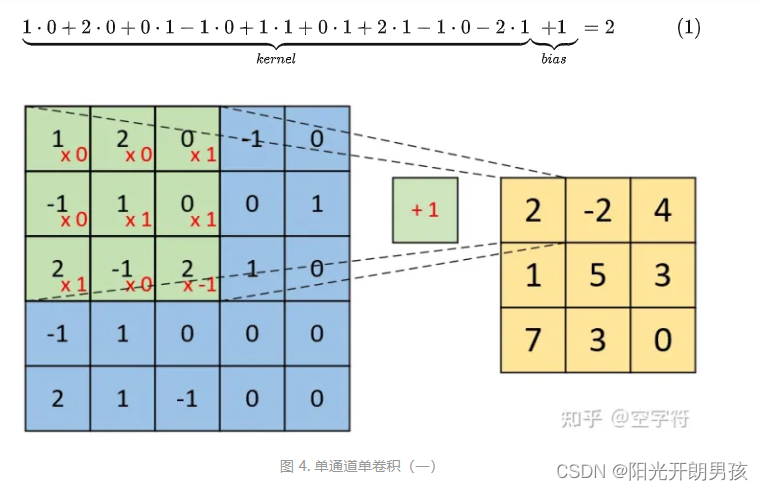
如下图所示,右边为卷积后的特征图(feature map),左边为卷积核对输入图片左上放进行卷积时的示意图。因此,对于这个部分的计算过程有:
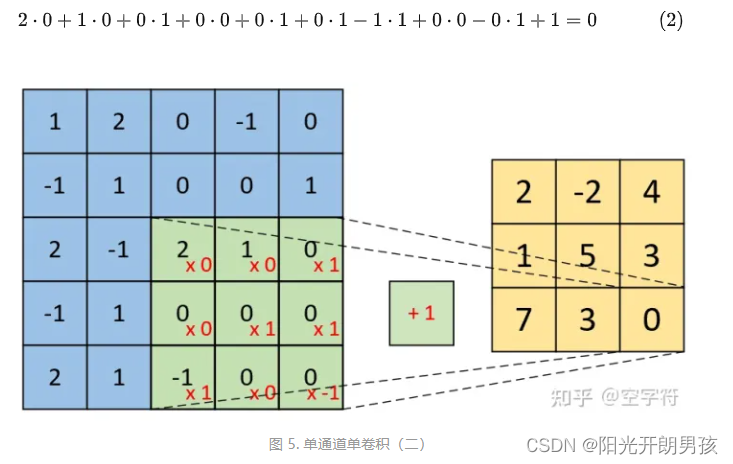
同理,对于最右下角部分卷积计算过程有:
因此,对于最后卷积的结果,我们得到的将是一个如图5右边所示形状为[3,3,1]的特征图。到此我们就把单通道单卷积的计算过程介绍完了。下面我们再来看单通道多卷积核的例子。
单通道多卷积核
如下图所示,左边依旧为输入矩阵,我们现在要用右边所示的两个卷积核对其进行卷积处理。
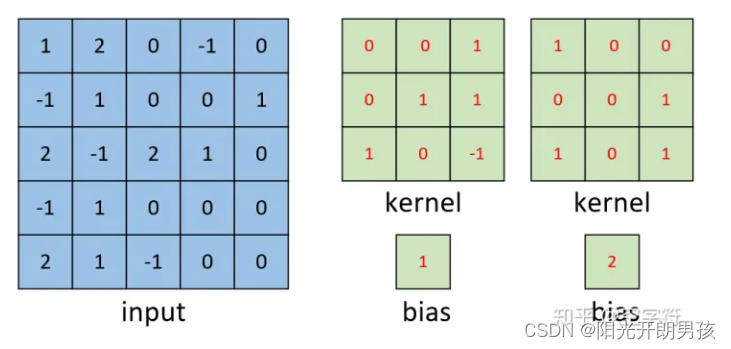
分别对两个卷积核进行计算,如下
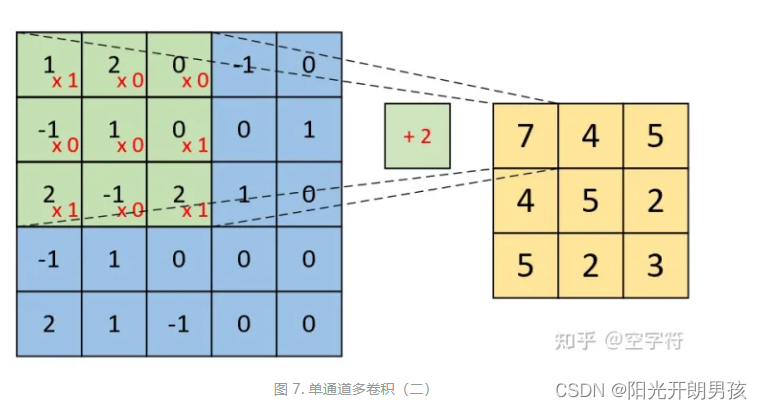
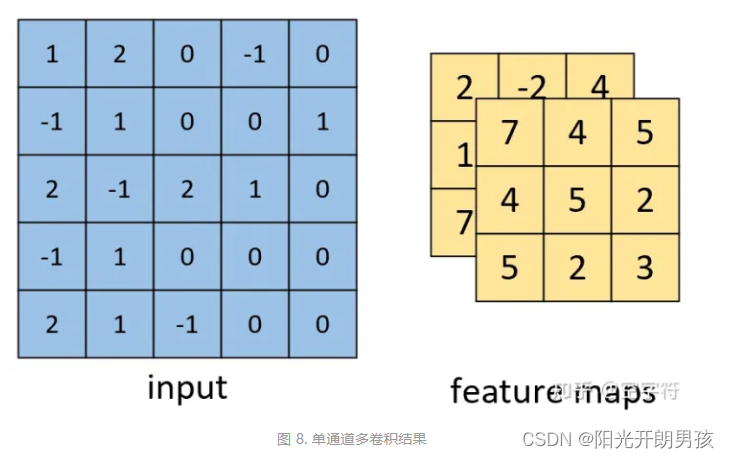
最后我们便能得到如图8右边所示的,形状为[3,3,2]的卷积特征图,其中2表示两个特征通道。
多通道单卷积核
对于多通道的卷积过程,总体上还是还是同之前的一样,都是每次选取特定位置上的神经元进行卷积,然后依次移动直到卷积结束。下面我们先来看看多通道单卷积核的计算过程。
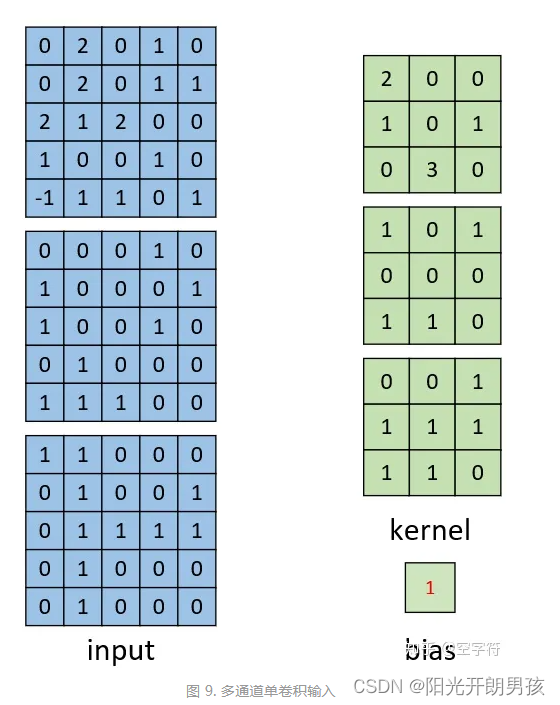
如上图所示,左边为包含有三个通道的输入,右边为一个卷积核和一个偏置。注意,强调一下右边的仅仅只是一个卷积核,不是三个。笔者看到不少人在这个地方都会搞错。因为输入是三个通道,所以在进行卷积的时候,对应的每一个卷积核都必须要有三个通道才能进行卷积。下面我们就来看看具体的计算过程。
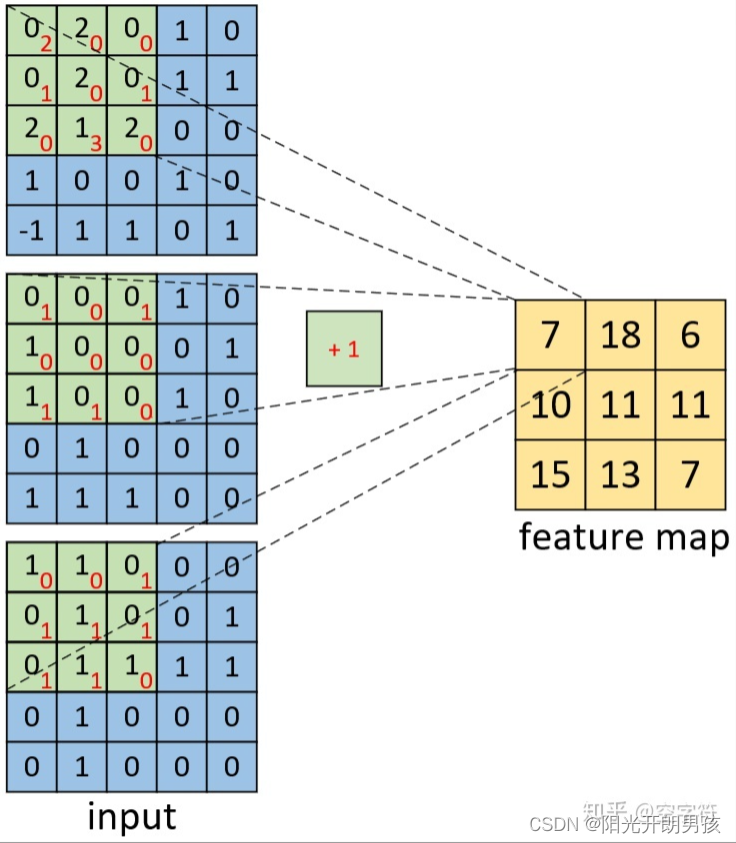
如上图所示,右边为卷积后的特征图(feature map),左边为一个三通道的卷积核对输入图片左上放进行卷积时的示意图。因此,对于这个部分的计算过程有:
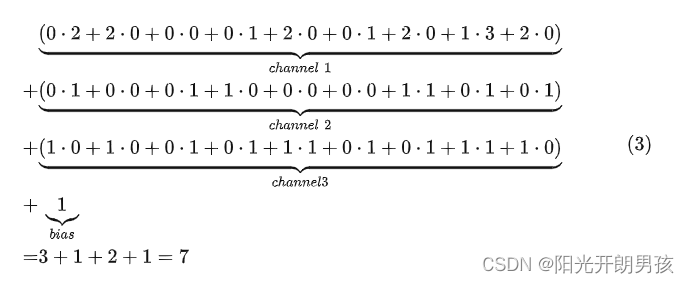
同理,对于其它部分的卷积计算过程也类似于上述计算步骤。由此我们便能得到如上图右边所示卷积后的形状为[3,3,1]的特征图。
多通道多卷积核
我们再来看看多通道多卷积核的计算过程。
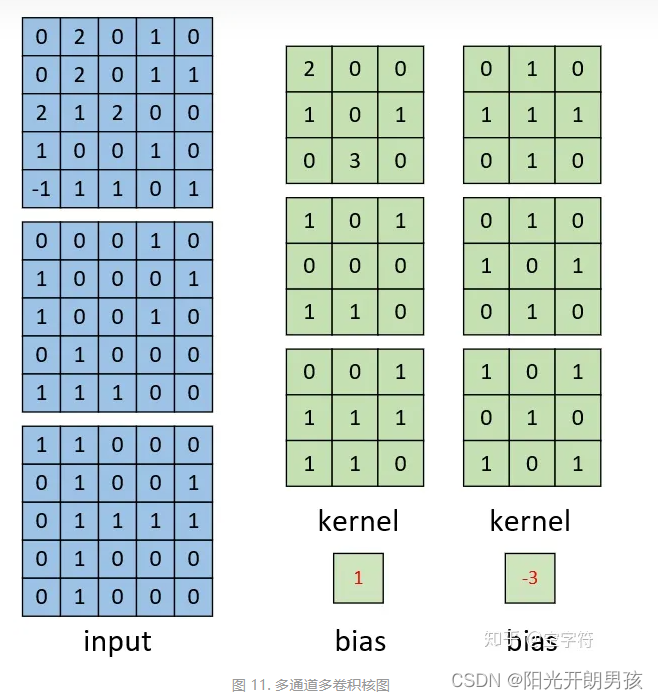
如上图所示,左边依旧为输入矩阵,我们现在要用右边所示的两个卷积核对其进行卷积处理。同时可以看到,第一个卷积核就是图9中所示的卷积核,其结果如图10所示。对于第二个卷积核,其计算过程也和式子(3)类似,都是将每个通道上的卷积结果进行相加,最后再加上偏置。因此,最后我们便能得到如下图右边所示的,形状为[3,3,2]的卷积特征图,其中2表示两个特征通道。
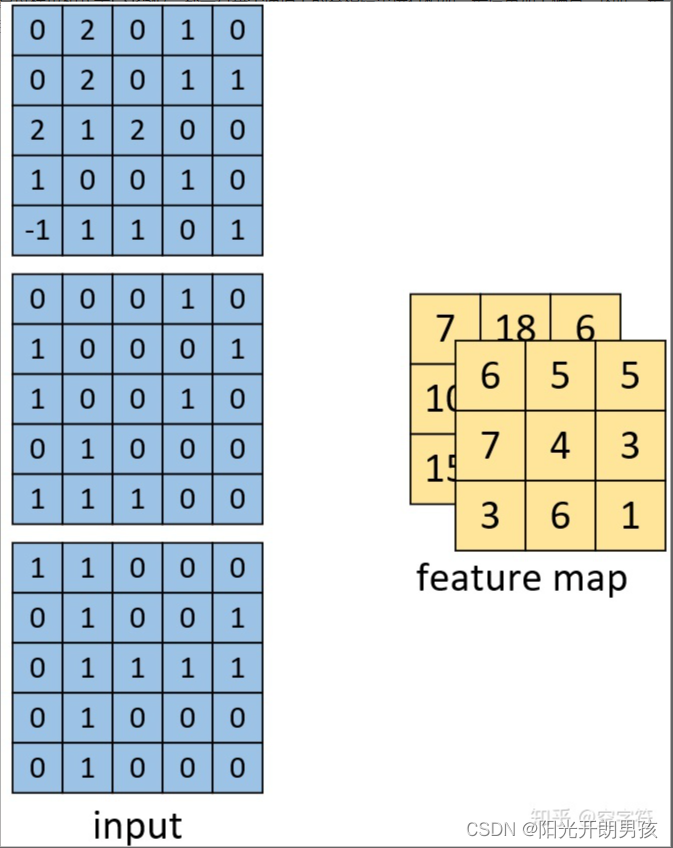
同时,从上面单通道卷积核多通道卷积的计算过程可以发现:
(1)原始输入有多少个通道,其对应的一个卷积核就必须要有多少个通道,这样才能与输入进行匹配,也才能完成卷积操作。换句话说,如果输入数据的形状为[n,n,c],那么对应每个卷积核的通道数也必须为c。
(2)用k个卷积核对输入进行卷积处理,那么最后得到的特征图一定就会包含有k个通道。例如,输入为[n,n,c],且用k个卷积核对其进行卷积,则卷积核的形状必定为[w1,w2,c,k],最终得到的特征图形状必定为[h1,h2,k];其中w1,w2为卷积核的宽度,h1,h2为卷积后特征图的宽度。
深度卷积
深度卷积就是卷积之后再卷积,然后再卷积。卷积的次数可以是几次,也可以是几十次、甚至可以是几百次。在全连接网络中我们可以通过更深的隐藏层来获取到更高级和更抽象的特征,以此来提高下游任务的精度。因此,采用深度卷积也是处于同样的目的。
卷积操作可以看作是对上一次输入的特征提取,即用来抓取输入中是否包含有某一类的特征。但是,通常情况下,输入的图像数据都是由一系列特征横向和纵向组合叠加起来的。因此,对于同一层次(横向)的特征我们需要通过多个卷积核对输入进行特征提取;而对于不同层次(纵向)的特征我们需要通过卷积的叠加来进行特征提取。
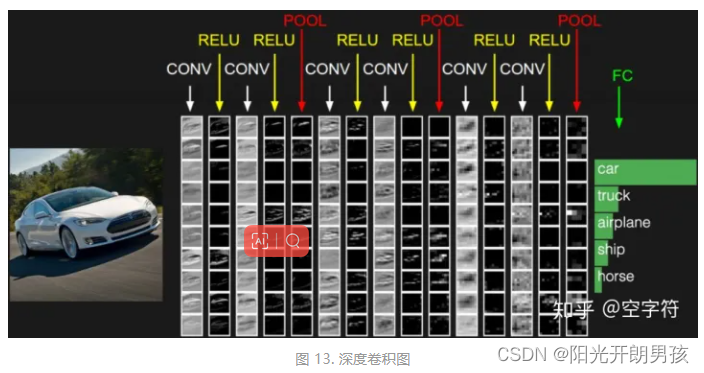
如上图,对于输入的一张图片,我们可以通过取多次叠加卷积后的结果来进行物体的分类任务。从图中可以发现,对于一开始的几次卷积,我们还能看到一些汽车的轮廓;但是在后续的多次叠加卷积处理后,我们人眼也就再也看不所谓汽车的影子了。但是,这些更高级的、抽象的特征却真实的能够提高模型最终的任务精度。因此,在一定的条件下,你甚至可以认为卷积的次数越多越好。
在相邻空间位置上具有依赖关系的数据均可以通过卷积操作来进行特征提取。