堆的实现
- 堆的概念及结构
- 堆的实现
- 初始化
- 销毁
- 返回堆顶元素
- 判空
- 有效数据个数
- 堆的插入(向上调整算法)
- 删除堆顶元素,仍然保持堆的形态(向下调整算法)
- 堆的创建
- 向上调整法建堆
- 向下调整建堆
- 两种建堆方法时间复杂度
- 向下调整法建堆时间复杂度分析
- 向上调整法建堆时间复杂度分析
- 堆排序
- TOP-k问题
堆的概念及结构
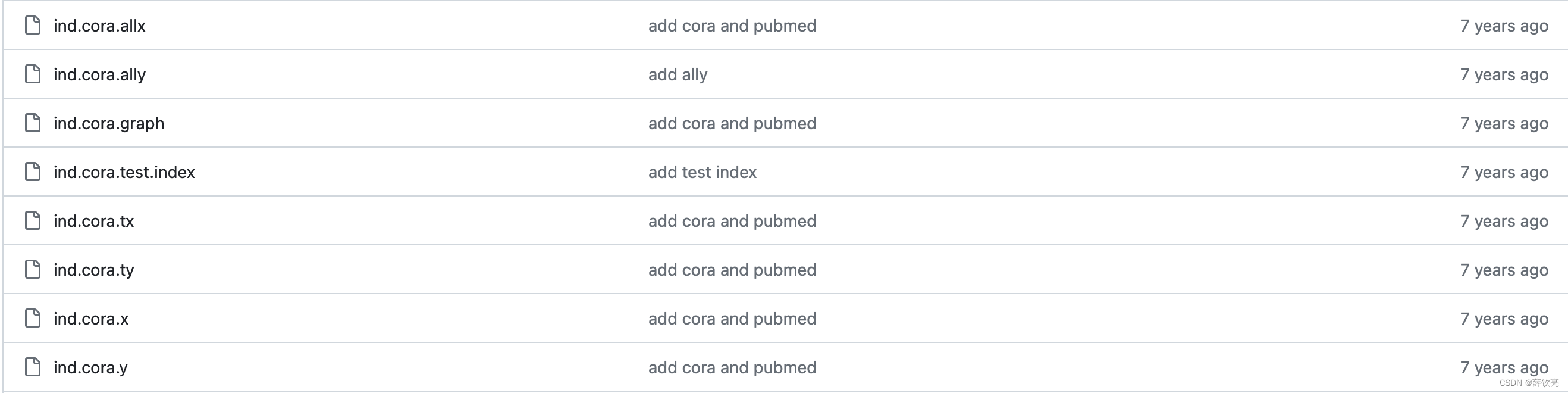
如果有一个关键码的集合K = {k0 ,k1 ,k2 ,…,kn-1 },把它的所有元素按完全二叉树的顺序存储方式存储在一个一维数组中,并满足:ki <=k2*i+1 且 <=k2*i+2 (ki >=k2*i+1 且 >=k2*i+2 ) i = 0,1,2…,则称为小堆(或大堆)。将根节点最大的堆叫做最大堆或大根堆,根节点最小的堆叫做最小堆或小根堆。
堆的性质:
1.堆中某个节点的值总是不大于或不小于其父节点的值;
2.堆总是一棵完全二叉树。
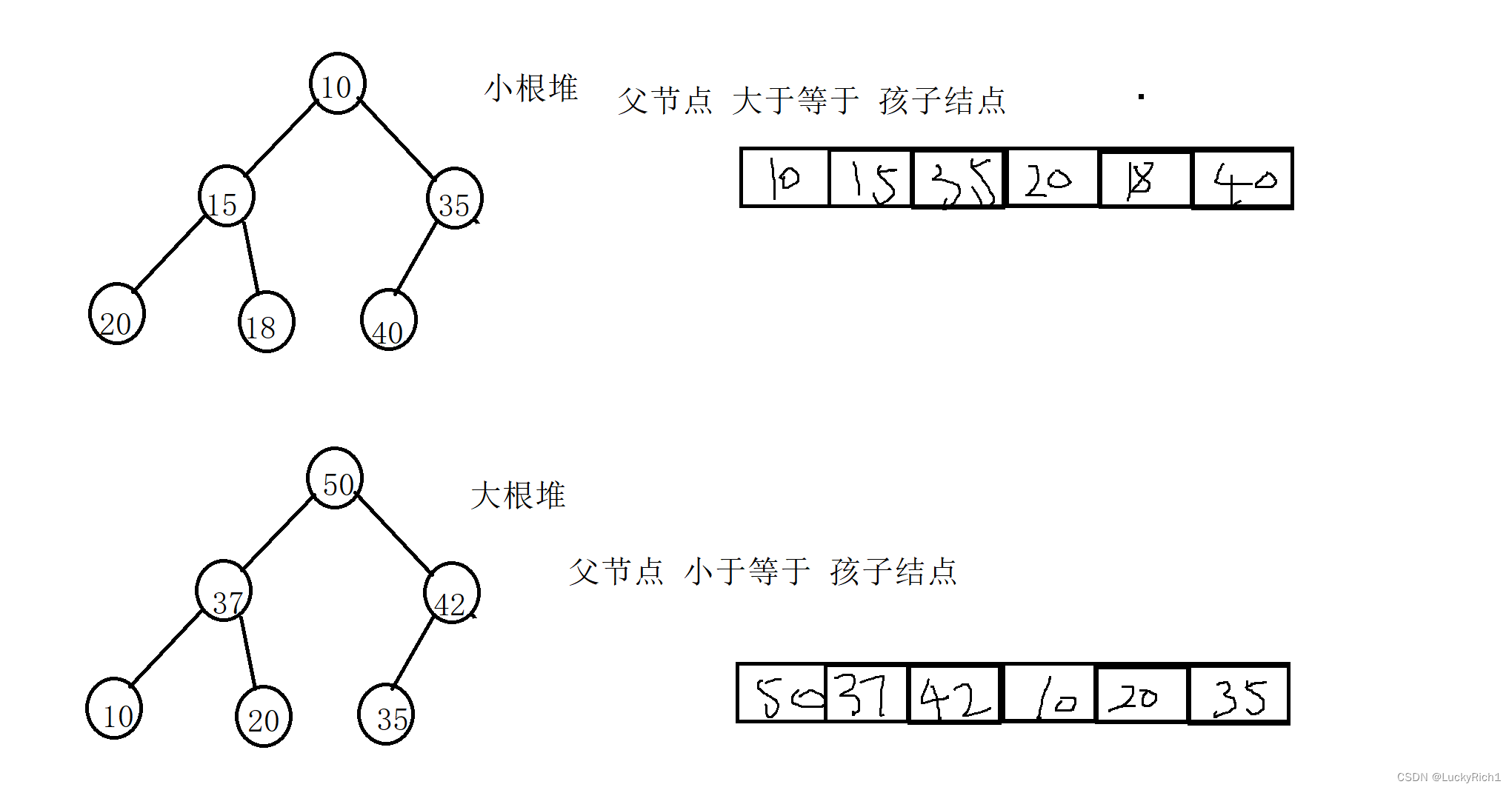
根据数组下标我们可以得到父子结点下标之间的关系

堆的实现
堆其实就是一根完全二叉树,我们可以采用数组的方式实现
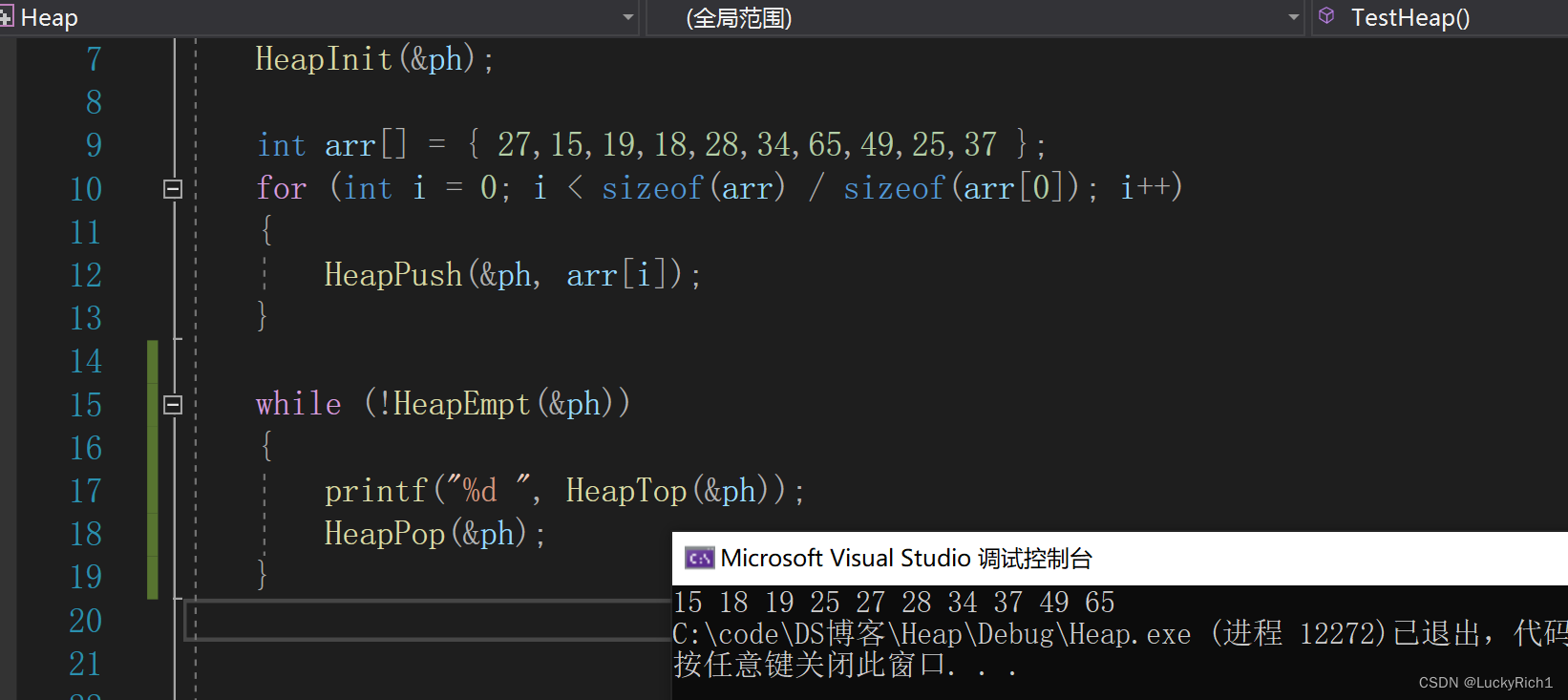
初始化
//初始化
void HeapInit(Heap* php)
{
assert(php);
php->a = NULL;
php->size = php->capacity = 0;
}
销毁
//销毁
void HeapDestroy(Heap* php)
{
assert(php);
free(php->a);
php->a = NULL;
php->size = php->capacity = 0;
}
返回堆顶元素
//返回堆顶元素
HPDatatype HeapTop(Heap* php)
{
assert(php);
assert(!HeapEmpt(php));
return php->a[0];
}
判空
//判空
bool HeapEmpt(Heap* php)
{
assert(php);
return php->size == 0;
}
有效数据个数
//数据个数
int HeapSize(Heap* php)
{
assert(php);
return php->size;
}
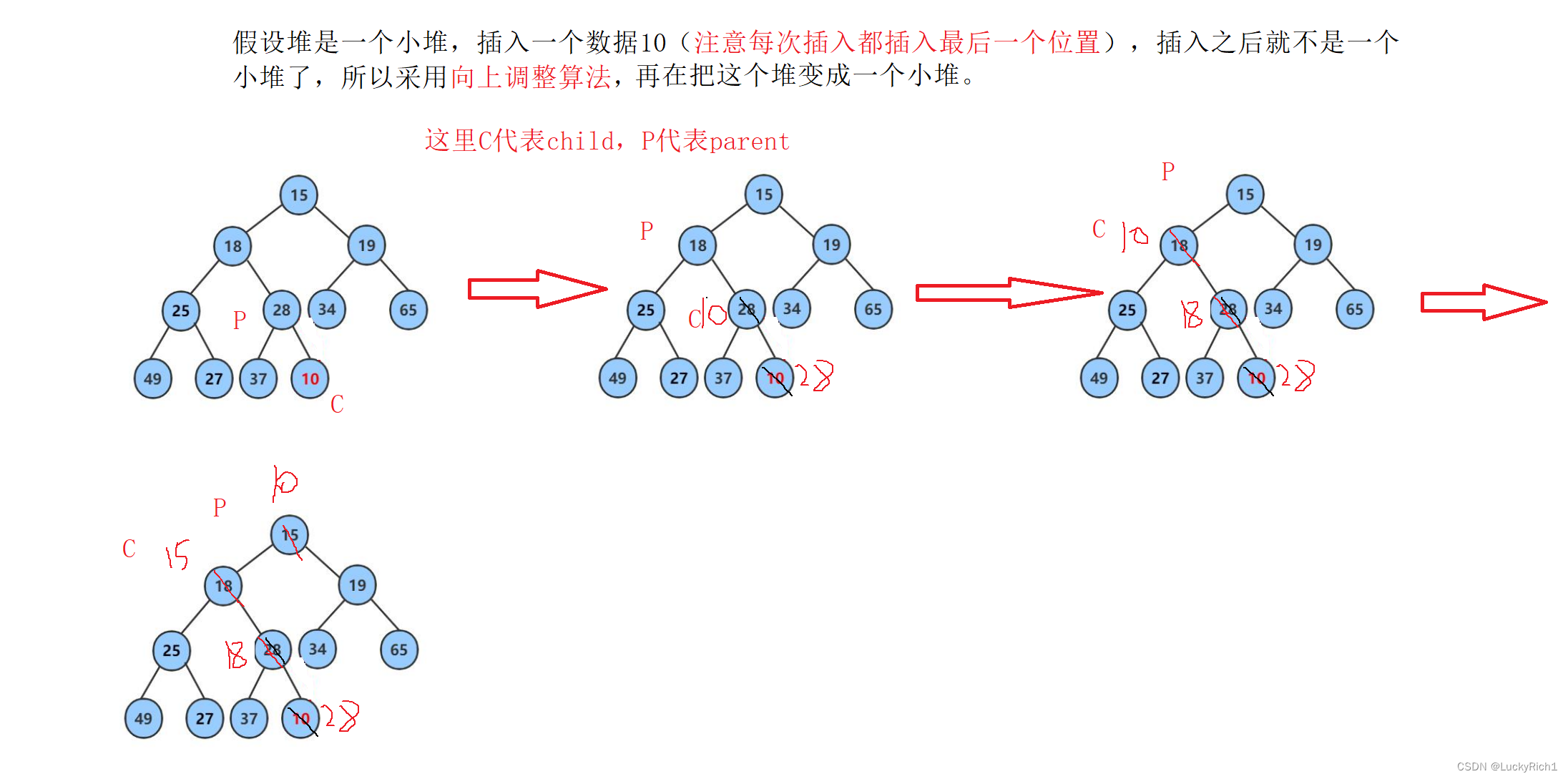
堆的插入(向上调整算法)
插入一个数据,也要保持大堆或(小堆)
void Swap(HPDatatype* x, HPDatatype* y)
{
HPDatatype tmp = *x;
*x = *y;
*y = tmp;
}
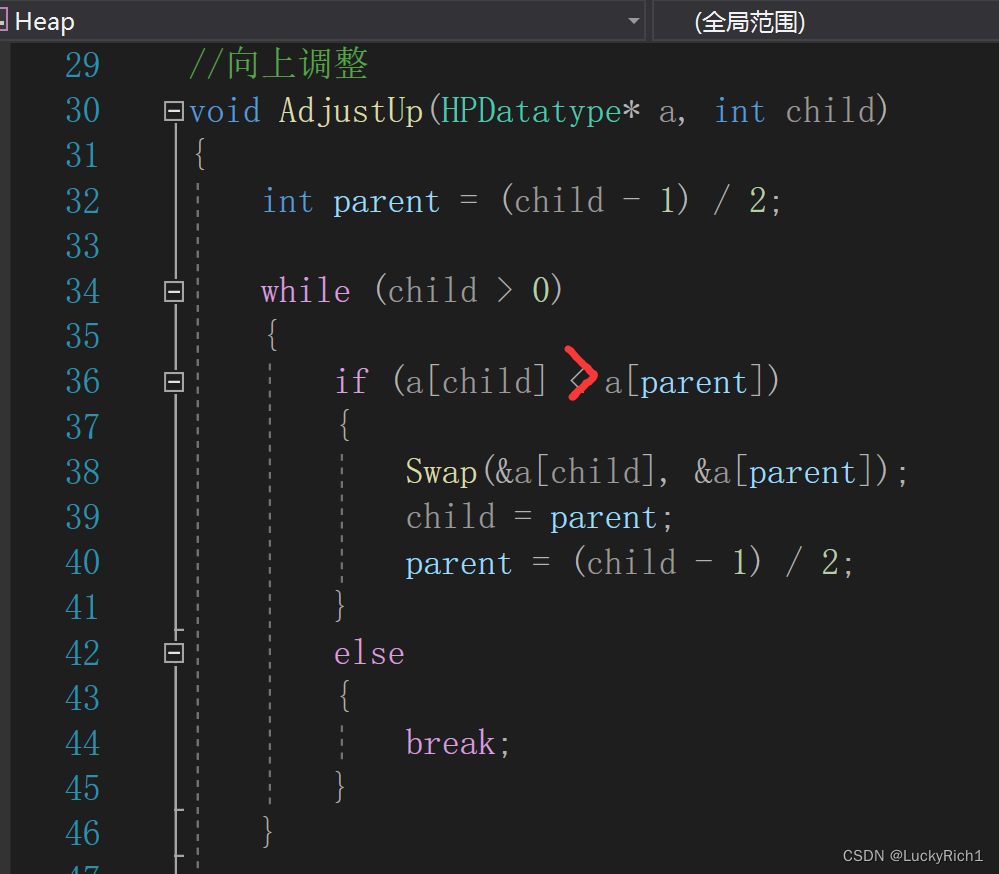
//向上调整
void AdjustUp(HPDatatype* a, int child)
{
int parent = (child - 1) / 2;
//这里用孩子下标作为循环结束条件
while (child > 0)
{
if (a[child] < a[parent])
{
Swap(&a[child], &a[parent]);
child = parent;
parent = (child - 1) / 2;
}
else
{
break;
}
}
}
//插入,仍保持堆的形态
void HeapPush(Heap* php, HPDatatype x)
{
assert(php);
if (php->size == php->capacity)
{
int newcapacity = php->capacity == 0 ? 4 : php->capacity * 2;
HPDatatype* tmp = (HPDatatype*)realloc(php->a, newcapacity * sizeof(HPDatatype));
if (tmp == NULL)
{
perror("realloc fail");
exit(-1);
}
php->a = tmp;
php->capacity = newcapacity;
}
php->a[php->size] = x;
php->size++;
//向上调整
AdjustUp(php->a, php->size - 1);
}
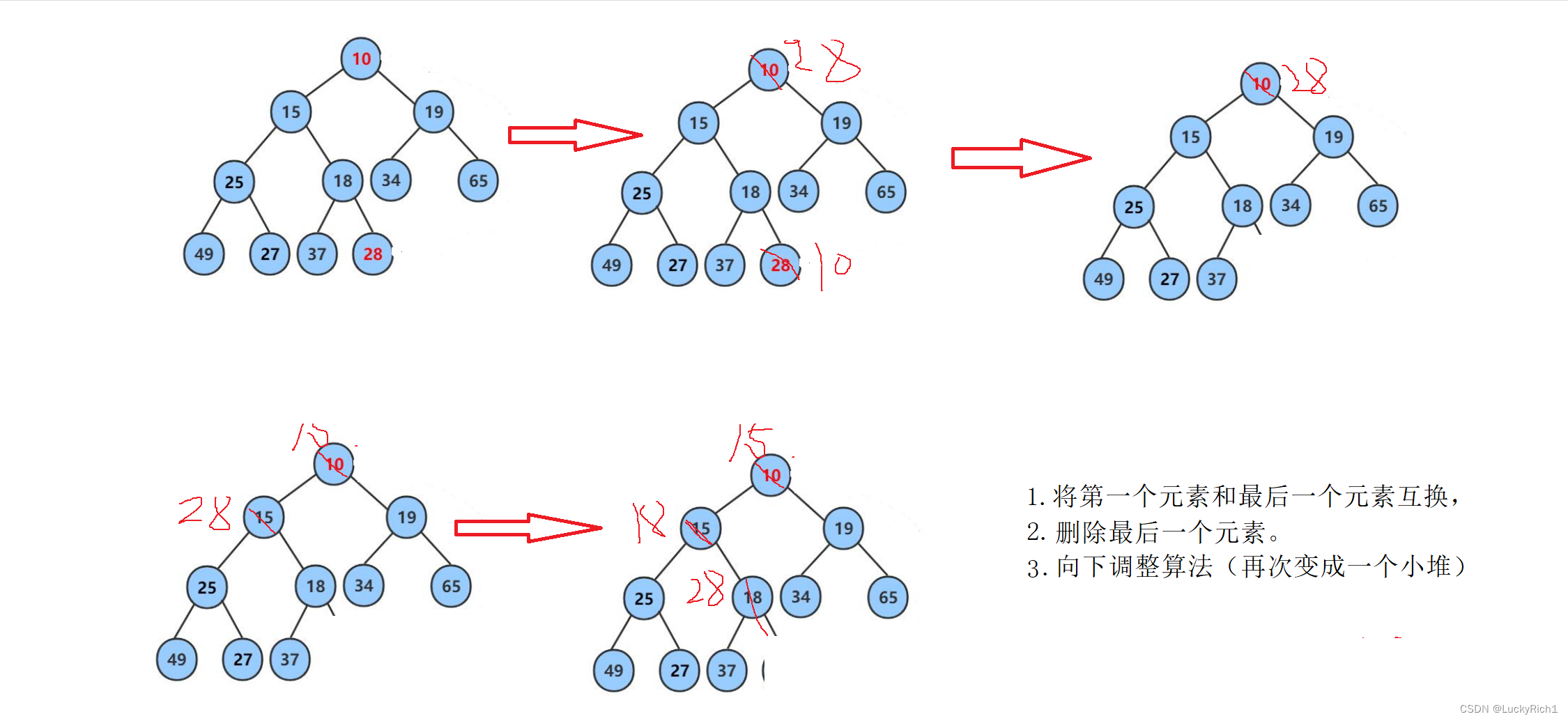
删除堆顶元素,仍然保持堆的形态(向下调整算法)
删除堆顶元素,是为了得到次大次少的元素。
既然用数组实现的堆,那删除元素可以直接像顺序表那样把后边元素向前移,覆盖前面元素吗?
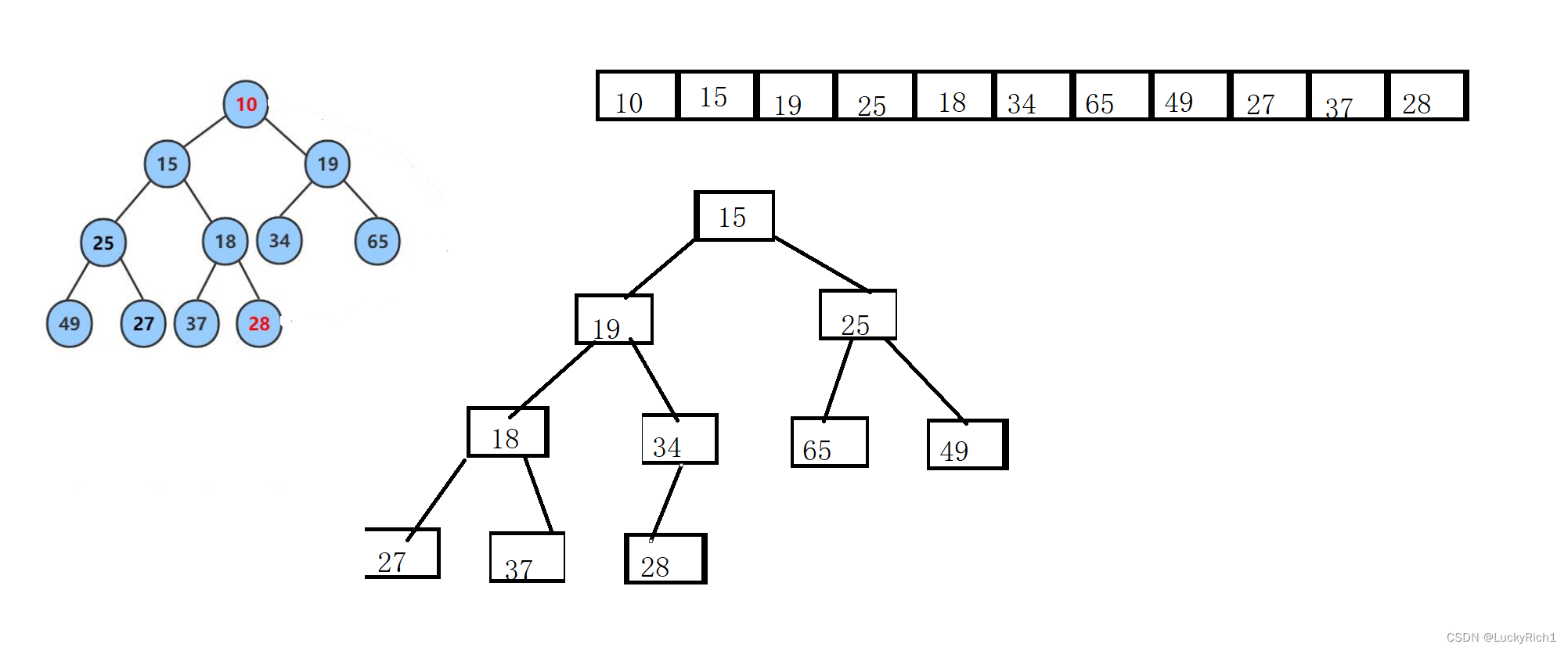
显然是不可以的,这个就称不上堆了。
所以使用下面这种方法。
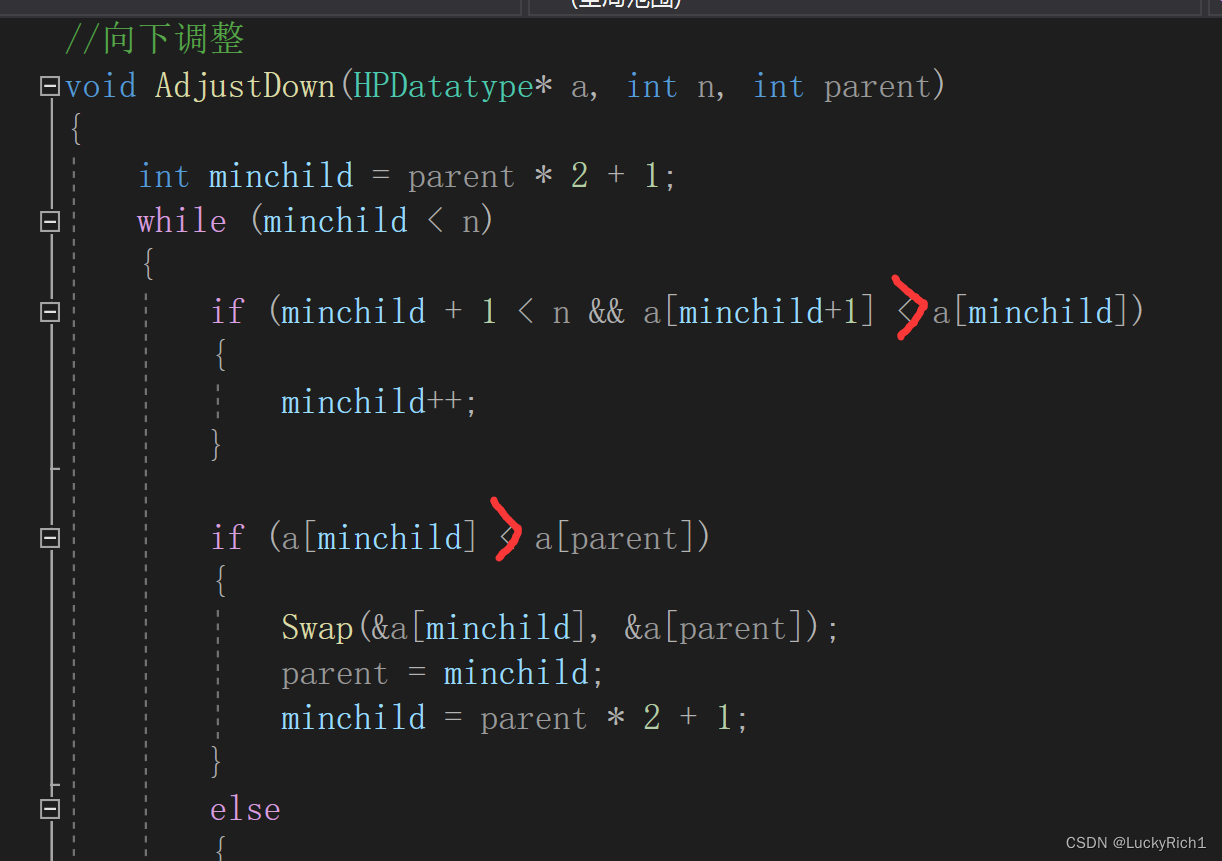
//向下调整
void AdjustDown(HPDatatype* a, int n, int parent)
{
int minchild = parent * 2 + 1;
while (minchild < n)
{
if (minchild + 1 < n && a[minchild+1] < a[minchild])
{
minchild++;
}
if (a[minchild] < a[parent])
{
Swap(&a[minchild], &a[parent]);
parent = minchild;
minchild = parent * 2 + 1;
}
else
{
break;
}
}
}
//删除堆顶元素,仍然保持堆的形态
void HeapPop(Heap* php)
{
assert(php);
assert(!HeapEmpt(php));
Swap(&php->a[0], &php->a[php->size - 1]);
php->size--;
//向下调整
AdjustDown(php->a, php->size, 0);
}
注意向下调整算法如果使用if和else来判断该父节的孩子结点谁大谁小这样会显得代码冗余,所以我们假设最小的是左孩子,然后左孩子和右孩子比较一下。看看那个是最小的,这样我们的代码会简单很多。值得我们借鉴。
其实大家发现没有,我们的建堆和堆排序已经完成了,
但是如果让我们排序一组数据,难道我们要把写一个堆然后在排序吗?
首先把数组的数据拷贝到堆里,然后进行建堆排序,结果我们只是让堆里面的数据变得有序了,数组里面的数据还是无序的,还得把堆里面数据拷贝回数组里,空间复杂度O(N);这样实在太麻烦了。所以我们考虑一下直接对数组进行建堆排序。
堆的创建
我们这里建的都是小堆。如果建大堆的话,改一下符号就可以了。
向上调整法建堆
void HeapSort(int* a, int n)
{
//向上调整法建堆
for (int i = 1; i < n; i++)
{
AdjustUp(a, i);
}
}
我们假设第一个元素就是一个堆,所以从下标为1的元素开始调整。
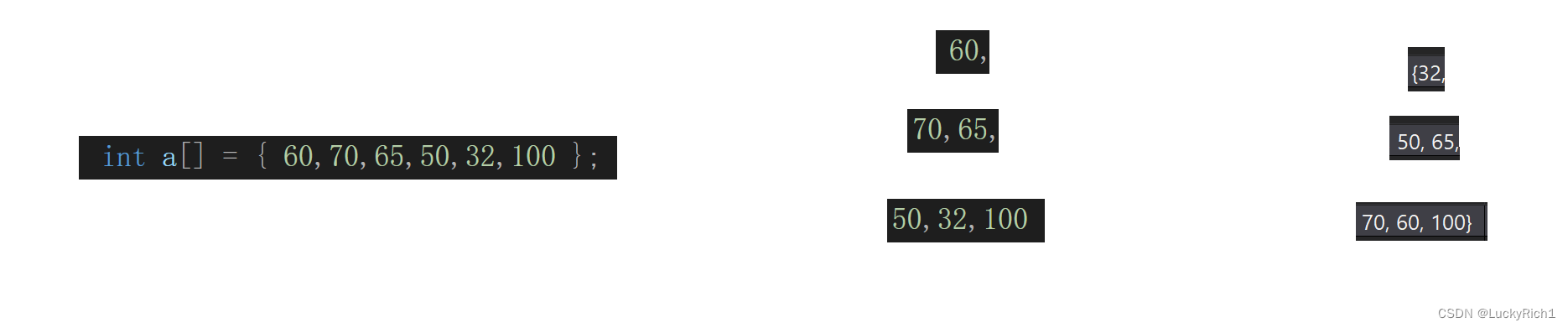
向下调整建堆
void HeapSort(int* a, int n)
{
//向下调整法建堆
for (int i = (n - 1 - 1) / 2; i >= 0; --i)
{
AdjustDown(a, n, i);
}
}
最后一个结点下标n-1,(n-1-1)/ 2是最后一个非叶子结点下标。
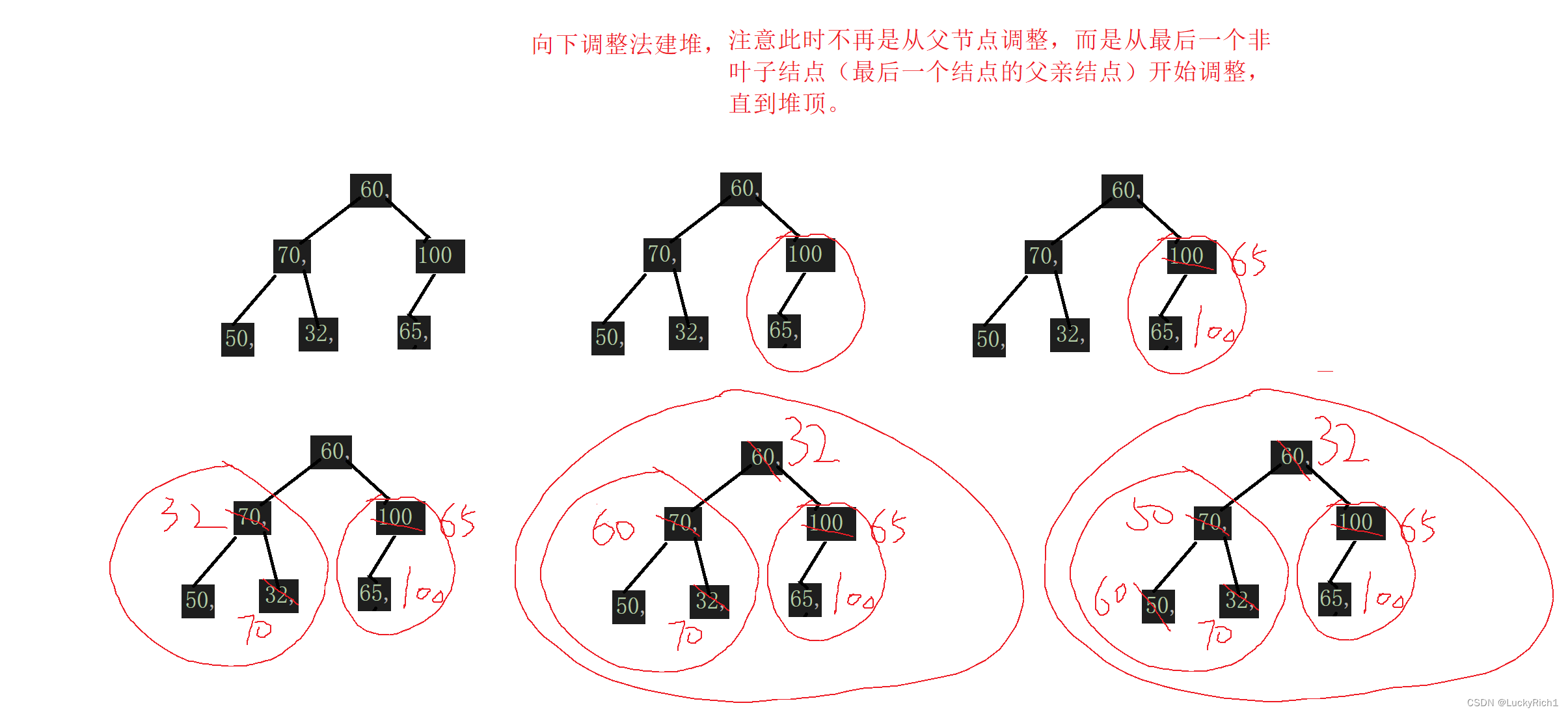
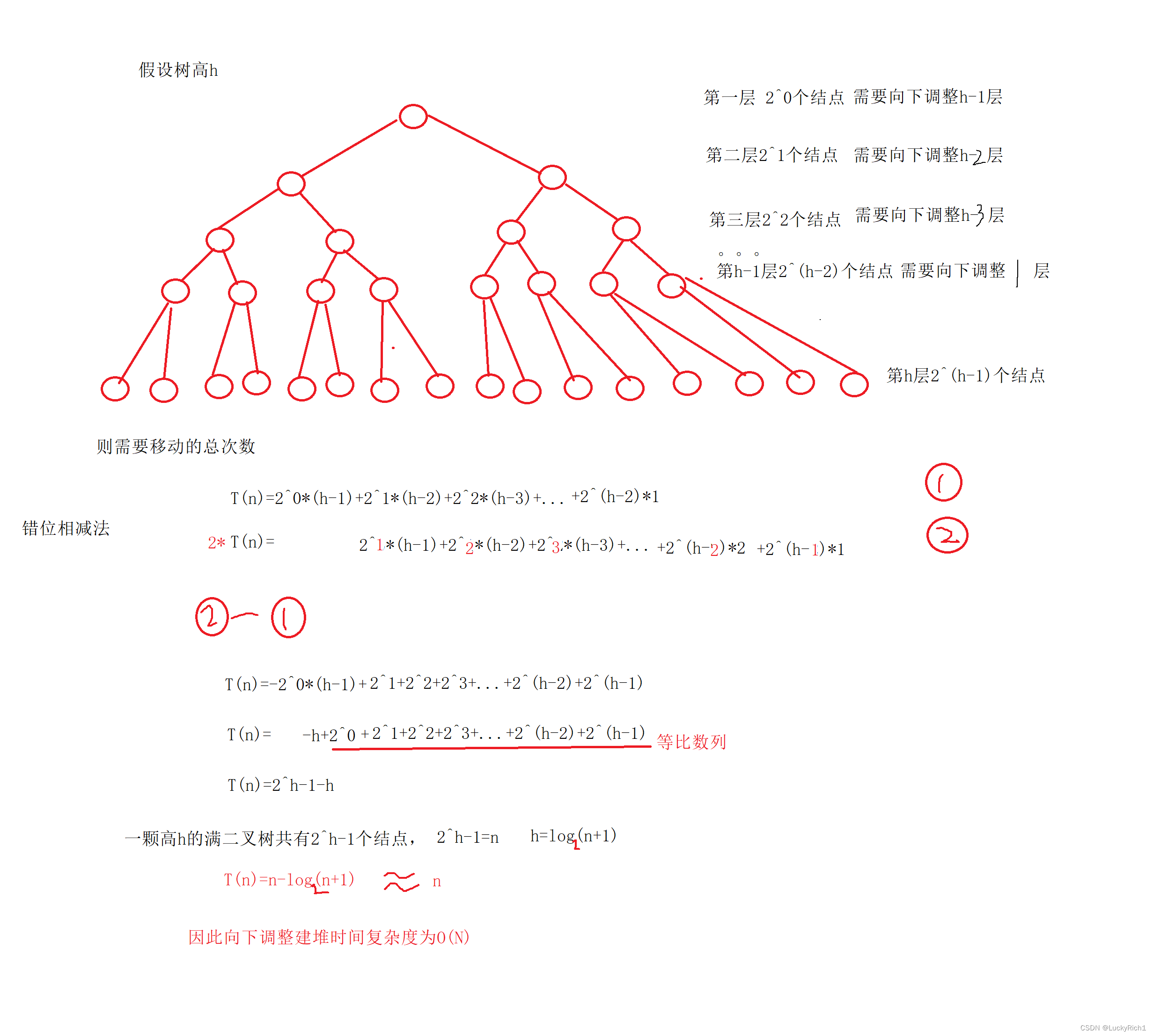
两种建堆方法时间复杂度
因为堆是完全二叉树,而满二叉树也是完全二叉树,此处为了简化使用满二叉树来证明(时间复杂度本来看的
就是近似值,多几个节点不影响最终结果):
向下调整法建堆时间复杂度分析
向上调整法建堆时间复杂度分析
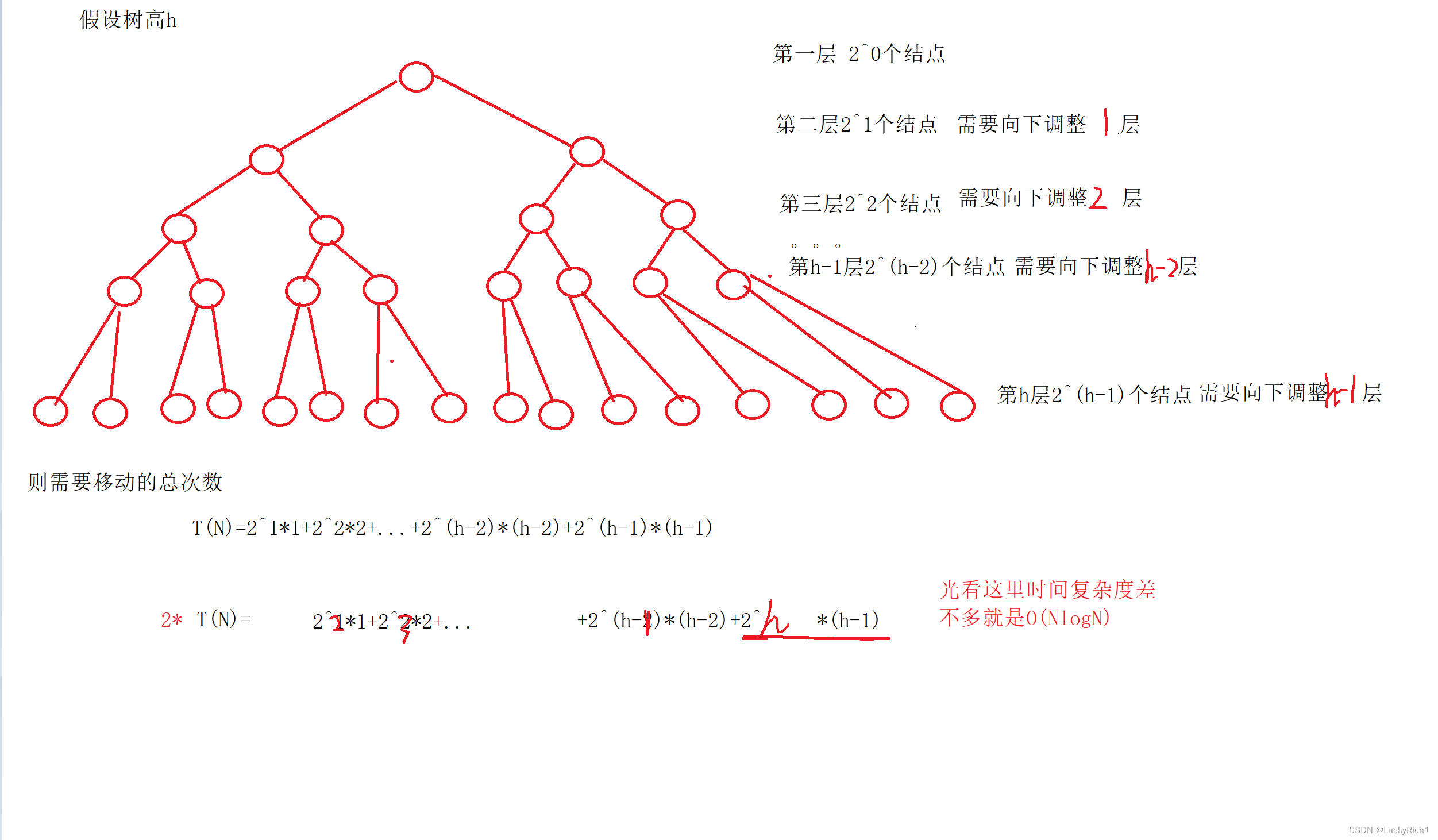
因此建堆,我们应该选择向下调整建堆法
堆排序
堆排序即利用堆的思想来进行排序,总共分为两个步骤:
-
建堆
升序:建大堆
降序:建小堆 -
利用堆删除思想来进行排序
建堆和堆删除中都用到了向下调整,因此掌握了向下调整,就可以完成堆排序。
排序算法思想:每次交换第一个和最后一个元素,然后把最后一个元素不再看成堆里的元素,再进行向下调整(选择次大次小的元素位于堆顶)。依次下次直到所有元素排序完毕。
void HeapSort(int* a, int n)
{
//向上调整法建堆O(NlogN)
//for (int i = 1; i < n; i++)
//{
// AdjustUp(a, i);
//}
//向下调整法建堆O(N)
for (int i = (n - 1 - 1) / 2; i >= 0; --i)
{
AdjustDown(a, n, i);
}
//堆排序O(NlogN)
int i = 1;
while (i < n)
{
Swap(&a[0], &a[n - i]);
AdjustDown(a, n - i, 0);
++i;
}
}
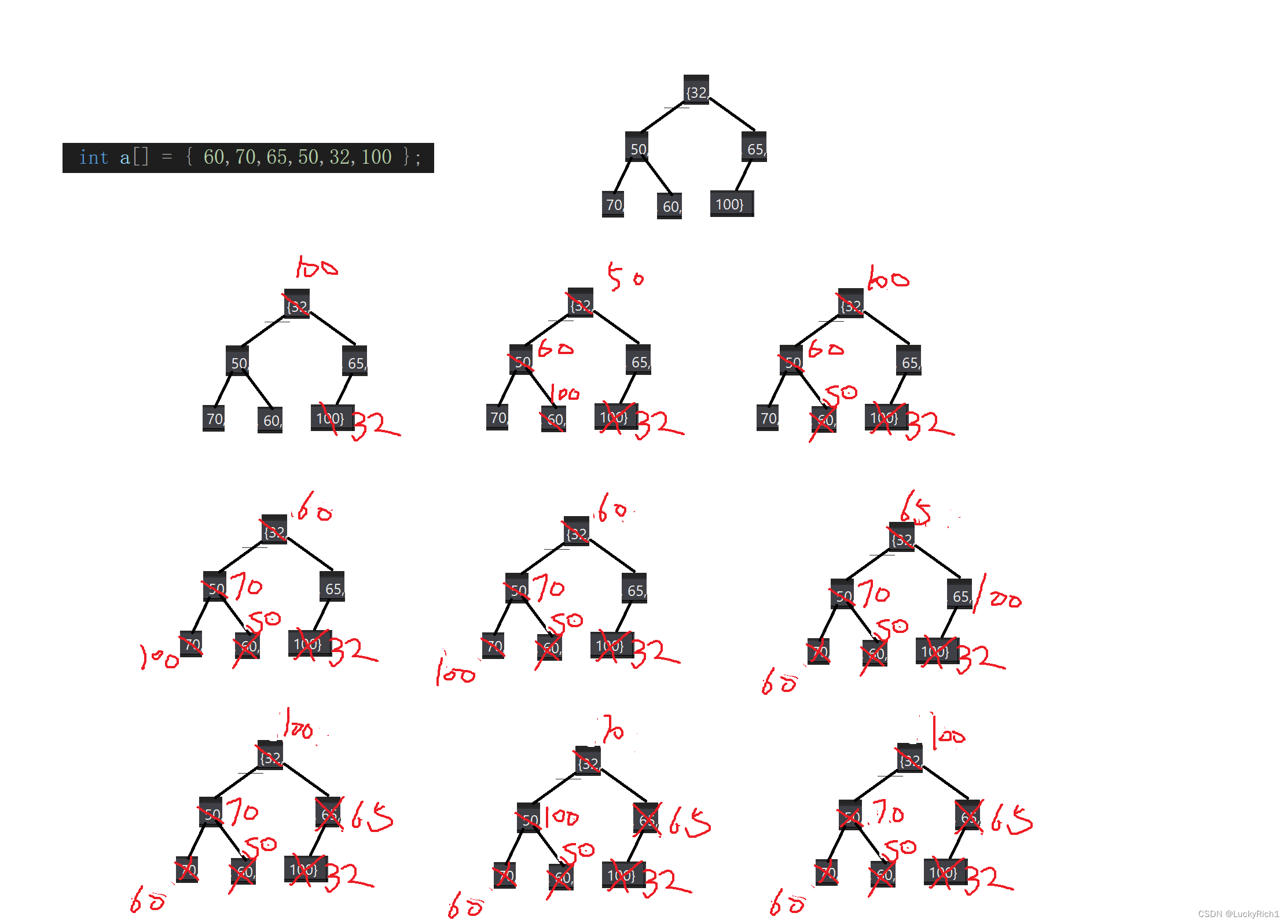
TOP-k问题
TOP-K问题:即求数据结合中前K个最大的元素或者最小的元素,一般情况下数据量都比较大。
比如:专业前10名、世界500强、富豪榜、游戏中前100的活跃玩家等。
假设我们要求给出数据前K个最大的元素。我们用堆有三种思路解决这个问题
1.堆排序
2.建大堆,把N个元素建成大堆,堆顶就是最大的元素,取堆顶元素,然后再Pop堆顶元素,总共Pop k次。
3.建小堆,把前k的元素建小堆,后N-k个元素于堆顶元素比较,比堆顶元素大就让该元素占据堆顶位置,然后再调整堆。
分析一下每种方法时间复杂度把。
堆排序O(Nlog2N);
建大堆,建堆O(N),调整堆O(log2N),总共调整K次,时间复杂度O(N+log2N*K),空间复杂度O(N)
建小堆,建堆O(K),调整堆O(log2K),假设最坏调整N-K次,时间复杂度O(K+log2K*(N-K)),约等于O(N),空间复杂度O(K)
还可以从下面这个角度再分析。
如果数据很大有100w个,而我们只取很小的K呢。代入时间时间复杂度看一看。
所以解决TOP-K问题最佳方式:
- 用数据集合中前K个元素来建堆
前k个最大的元素,则建小堆
前k个最小的元素,则建大堆- 用剩余的N-K个元素依次与堆顶元素来比较,不满足则替换堆顶元素
将剩余N-K个元素依次与堆顶元素比完之后,堆中剩余的K个元素就是所求的前K个最小或者最大的元素。
下面是生成随机数放在文件里,再从文件读取K个数据建成小堆,再把N-K个与堆顶元素进行比较。。。。关于想了解文件的请点击这里文件然后结合看下面代码。
#include<stdio.h>
#include<stdlib.h>
#include<time.h>
void GenerateFile(const char* filename, int N)
{
//把数据写入文件里
FILE* fin = fopen(filename, "w");
if (fin == NULL)
{
perror("fopen fail");
return;
}
srand((unsigned int)time(NULL));
//写
for (int i = 0; i < N; i++)
{
fprintf(fin, "%d ", rand());
}
fclose(fin);
}
void PrintTopk(const char* filename, int k)
{
//把文件中数据读到内存
FILE* fout = fopen(filename, "r");
if (fout == NULL)
{
perror("fopen fail");
return;
}
int* minHeap = (int*)malloc(k * sizeof(int));
if (minHeap == NULL)
{
perror("malloc fail");
return;
}
//读k个数据
for (int i = 0; i < k; i++)
{
fscanf(fout, "%d", &minHeap[i]);
}
//将k个数据建成小堆
for (int i = (k - 2) / 2; i >= 0; i--)
{
AdjustDown(minHeap, k, i);
}
int val = 0;
//继续读取N-K个元素
while (fscanf(fout, "%d", &val) != EOF)
{
if (val > minHeap[0])
{
minHeap[0] = val;
//调整堆
AdjustDown(minHeap, k, 0);
}
}
//打印
for (int i = 0; i < k; i++)
{
printf("%d ", minHeap[i]);
}
fclose(fout);
}
int main()
{
const char* filename = "Data.txt";
int k = 10;
int N = 10000;
GenerateFile(filename, N);
PrintTopk(filename, k);
return 0;
}
为了验证这个代码是否正确,我们可以把这段代码
//写
for (int i = 0; i < N; i++)
{
fprintf(fin, "%d ", rand());
}
改成
//写
for (int i = 0; i < N; i++)
{
fprintf(fin, "%d ", rand()%10000);
}
这样就得到随机数为10000里的数字,再在文件里添加10001-10010,千万注意不要再生成文件了,不然你的数据就会被覆盖。然后打印,是我们想要的结果。
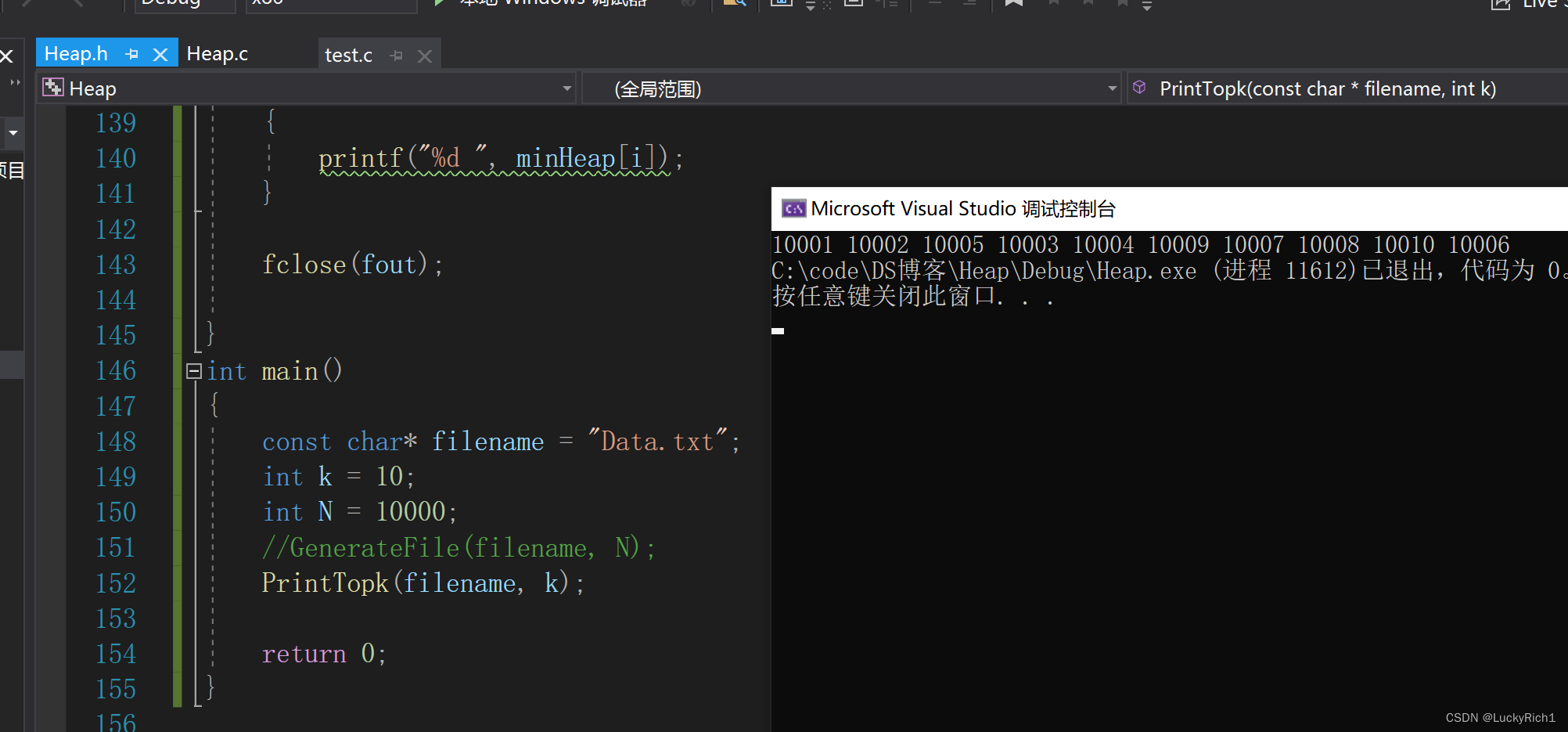
自此关于堆的实现,建堆,堆排序以及TOP-K问题再一篇文章里都解决了,欢迎有问题的小伙伴们再评论区提问,点赞,收藏。一键三连哦!万分感谢!




![BUUFCTF—[极客大挑战 2019]Upload 1](https://img-blog.csdnimg.cn/img_convert/d740fc51b1a04da2ccf144588ede0a90.png)