如果模型知道目标在哪,那么我们只需要教模型读出目标的位置,而不需要显式地进行分类、回归。对于这项工作,研究者们希望可以启发人们探索目标跟踪等视频任务的自回归式序列生成建模。
自回归式的序列生成模型在诸多自然语言处理任务中一直占据着重要地位,特别是最近ChatGPT的出现,让人们更加惊叹于这种模型的强大生成能力和潜力。
最近,微软亚洲研究院与大连理工大学的研究人员提出了一种使用序列生成模型来完成视觉目标跟踪任务的新框架SeqTrack,来将跟踪建模成目标坐标序列的生成任务。
目前的目标跟踪框架,一般把目标跟踪拆分为分类、回归、角点预测等多个子任务,然后使用多个定制化的预测头和损失函数来完成这些任务。而SeqTrack通过将跟踪建模成单纯的序列生成任务,不仅摆脱了冗余的预测头和损失函数,也在多个数据集上取得了优秀的性能。

论文链接:
http://arxiv.org/abs/2304.14394
Github:
https://github.com/microsoft/VideoX

方法亮点
1.新的目标跟踪框架,将跟踪建模为序列生成任务,一个简洁而有效的新基线;
2.摒弃冗余的预测头和损失函数,仅使用朴素的Transformer和交叉熵损失,具有较高的可扩展性。
|
|
|
|
|
|




一 、研究动机
现在比较先进的目标跟踪方法采用了“分而治之”的策略,即将跟踪问题解耦成多个子任务,例如中心点预测、前景/背景二分类、边界框回归、角点预测等。尽管在各个跟踪数据机上取得了优秀的性能,但这种“分而治之”的策略存在以下两个缺点:
1、模型复杂:每个子任务都需要一个定制化的预测头,导致框架变得复杂,不利于扩展
2、损失函数冗余:每个预测头需要一个或多个损失函数,引入额外超参数,使训练困难

图1 目前常见的跟踪框架
研究者认为,如果模型知道目标在图像中的位置,那么只需要简单地教模型读出目标边界框即可,不需要用“分而治之”的策略去显式地进行分类和回归等。为此,作者采用了自回归式的序列生成建模来解决目标跟踪任务,教模型把目标的位置作为一句话去“读”出来。
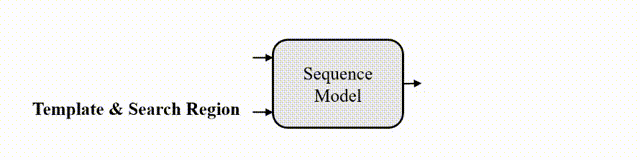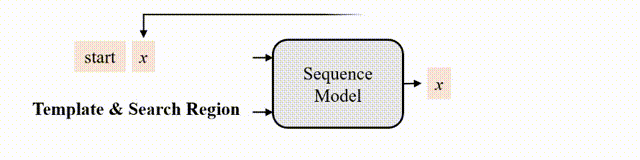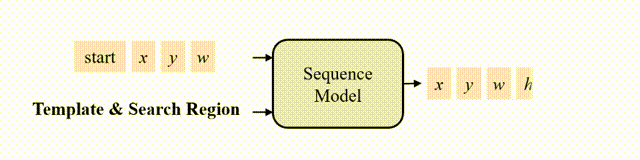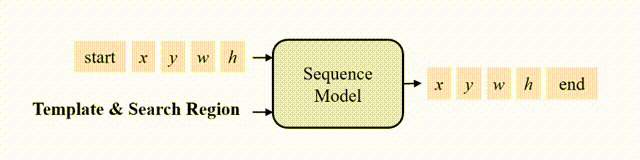
图2 跟踪的序列生成建模
二 、方法概览
研究者将目标边界框的四个坐标转化为由离散值token组成的序列,然后训练SeqTrack模型逐个token地预测出这个序列。在模型结构上,SeqTrack采用了原汁原味的encoder-decoder形式的transformer,方法整体框架图如下图3所示:
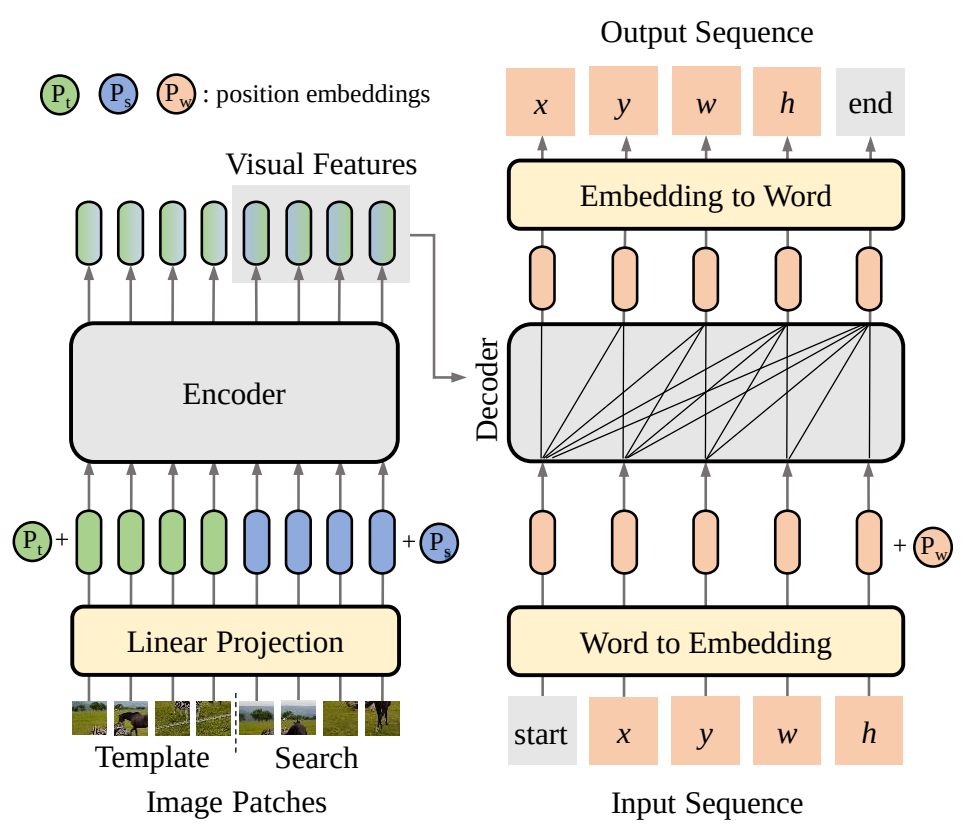
图3 SeqTrack结构图
Encoder提取模板与搜索区域图片的视觉特征,decoder参考这些视觉特征,完成序列的生成。序列包含构成边界框的 x,y,w,h token,以及两个特殊的 start 和 end token,分别表示生成的开始与结束。
在推理时,start token告知模型开始生成序列,然后模型依次生成 x,y,w,h ,每个token的生成都会参考前序已生成好的token,例如,生成 w 时,模型会以 [start, x, y] 作为输入。当 [x,y,w,h] 生成完,模型会输出end token,告知用户预测完成。
为了保证训练的高效,训练时token的生成是并行的,即 [start, x,y,w,h] 被同时输入给模型,模型同时预测出 [x,y,w,h, end] 。为了保证推理时的自回归性质,在训练时对decoder中的自注意力层中添加了因果性的attention mask,以保证每个token的预测仅取决于它前序的token,attention mask如下图4所示。
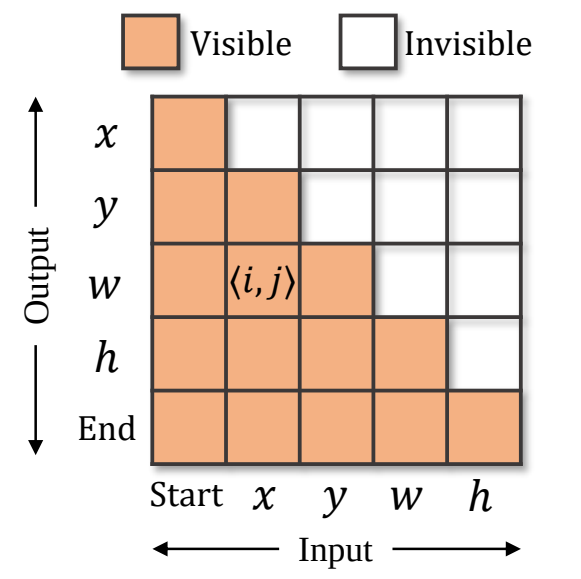
图3 Attention mask,第 i 行第 j 列的橘色格子代表第生成第 i 个输出token时,允许观察到第 j 个输入token,而白色格子代表不可观察。
图像上连续的坐标值被均匀地离散化为了[1, 4000]中的整数。每个整数可以被视为一个单词,构成了单词表 V ,x,y,w,h 四个坐标从单词表 V 中取值。
与常见的序列模型类似,在训练时,SeqTrack使用交叉熵损失来最大化目标值基于前序token的预测值、搜索区域、模板三者的条件概率:
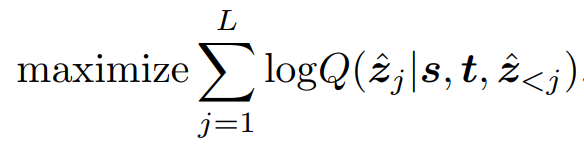
在推理时,使用最大似然从单词表 V 中为每个token取值:
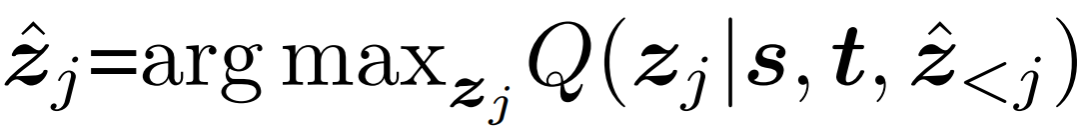
通过这种方式,仅需要交叉熵损失即可完成模型的训练,大大简化了复杂度。
除此之外,研究者们还设计了合适的方式,在不影响模型与损失函数的情况下,引入了在线模板更新、窗口惩罚等技术来集成跟踪的先验知识,这里不再赘述,具体细节请参考论文。
三 、实验结果
研究者开发了四种不同大小的模型,以取得性能与速度之间的平衡,并在8个跟踪数据集上验证了这些模型的性能。
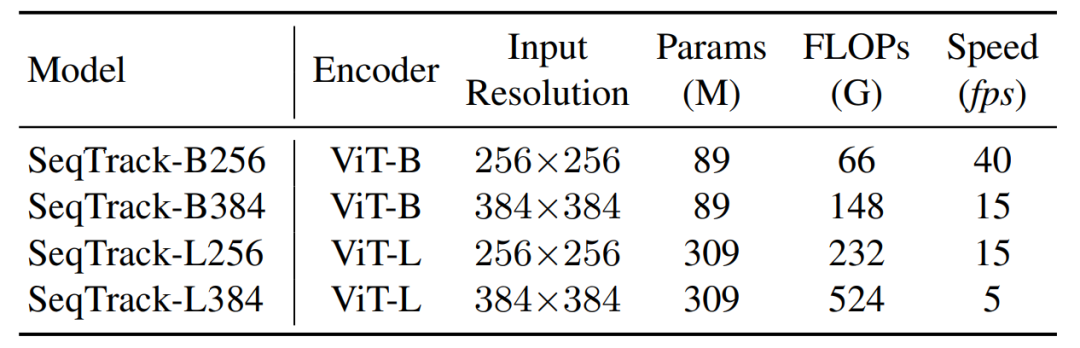
表1 SeqTrack模型参数
如下表2所示,在大尺度数据集LaSOT, LaSOText,TrackingNet, GOT-10k上,SeqTrack取得了优秀的性能。例如,与同样使用ViT-B和256输入图片分辨率的OSTrack-256相比,SeqTrack-B256在四个数据集上都取得了更好的结果。
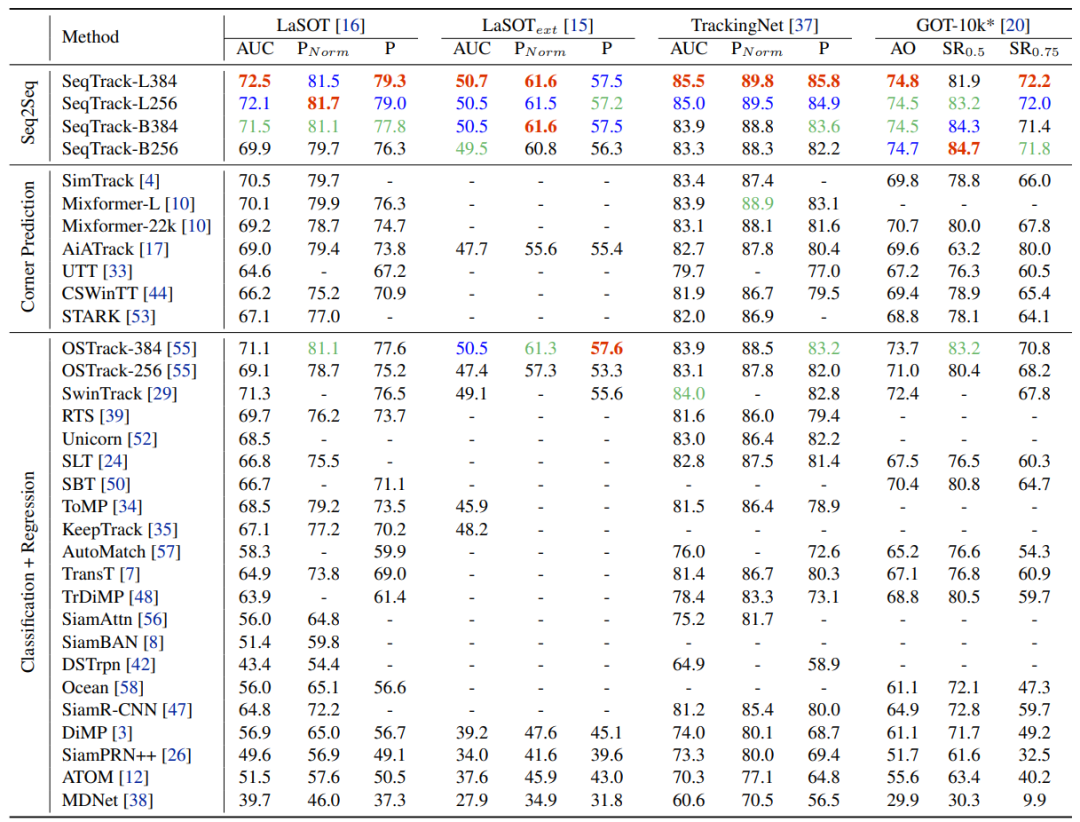
表2大规模数据集性能
如表3所示,SeqTrack在包含多种不常见目标类别的TNL2K数据集上取得了领先的性能,验证了SeqTrack的泛化性。在小规模数据集NFS和UAV123上也都取得了具有竞争力的性能。
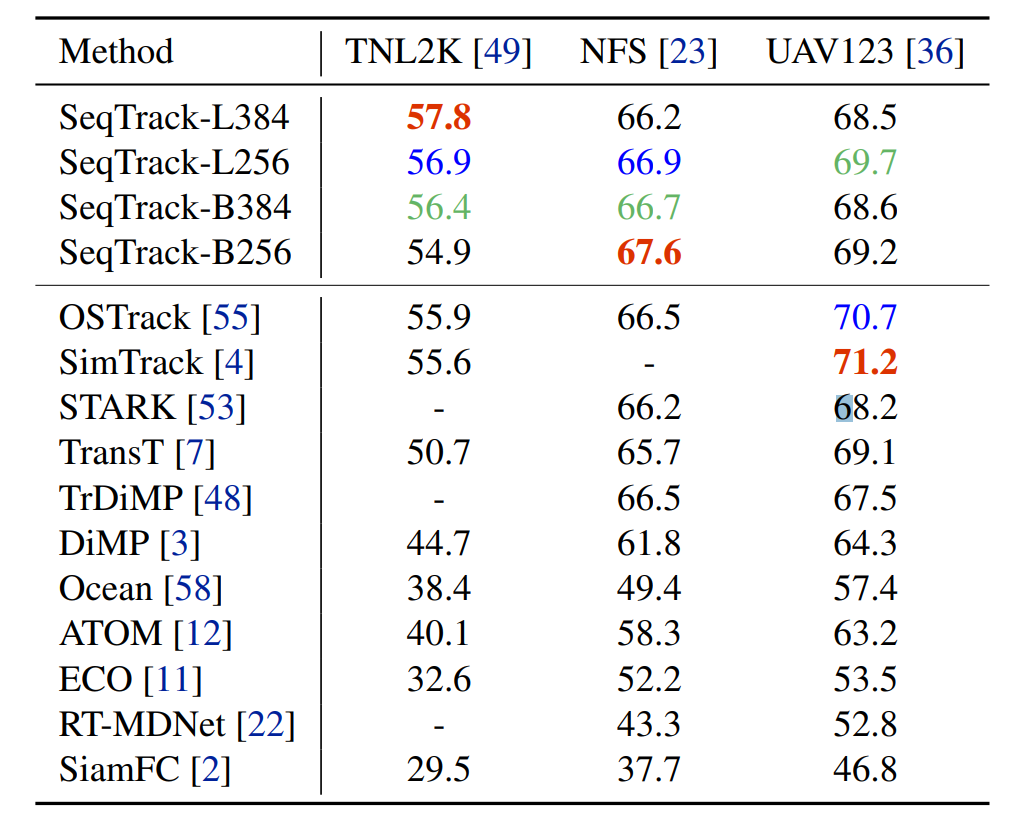
表3额外数据集性能
图4所示,在VOT竞赛数据集上,分别使用边界框测试和分割掩膜测试,SeqTrack都取得了优秀的性能。

图4 VOT2020性能
这样简单的框架具有良好的可扩展性,只需要将信息引入到序列构建中,而无需更改网络结构。例如,研究者们进行了额外的实验来尝试在序列中引入时序信息。具体来说,将输入序列扩展到多帧,包含了目标边界框的历史值。表4显示这样的简单扩展提升了基线模型的性能。

图5 时序序列示意图

表4 时序序列结果
四、结语
本文提出了目标跟踪的新的建模方式:序列生成式建模。它将目标跟踪建模为了序列生成任务,仅使用简单的Transformer结构和交叉熵损失,简化了跟踪框架。大量实验表明了序列生成建模的优秀性能和潜力。在文章的最后,研究者希望通过本文给视觉目标跟踪和其他视频任务的序列建模提供灵感。在未来工作,研究者将尝试进一步融合时序信息,以及扩展到多模态任务。
Illustration by IconScout Store from IconScout
-The End-
点击阅读原文