文章目录
- Online Easy Example Mining for Weakly-Supervised Gland Segmentation from Histology Images
- 摘要
- 本文方法
- 分割
- 实验结果
Online Easy Example Mining for Weakly-Supervised Gland Segmentation from Histology Images
摘要

背景
开发AI辅助的组织学图像腺体分割方法对癌症的自动诊断和预后至关重要;然而,像素级注释的高成本阻碍了其在更广泛的疾病中的应用。计算机视觉中现有的弱监督语义分割方法在腺体分割中取得了退化的结果,因为腺体数据集的特征和问题不同于一般的对象数据集。我们观察到,与自然图像不同,组织学图像的关键问题是由于不同组织之间的形态学同质性和低颜色对比度而导致的分类混乱。
方法
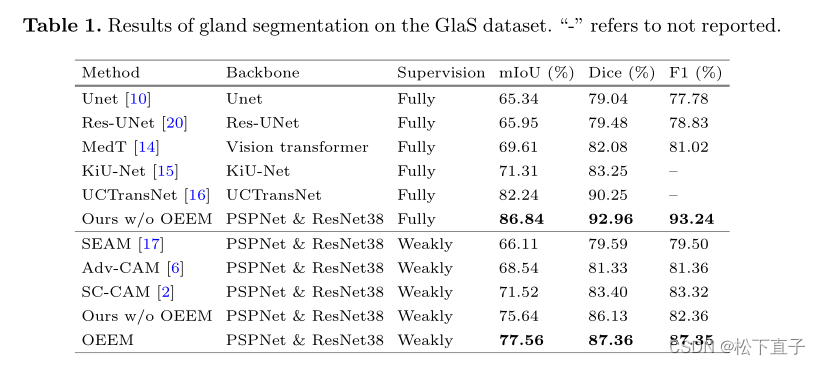
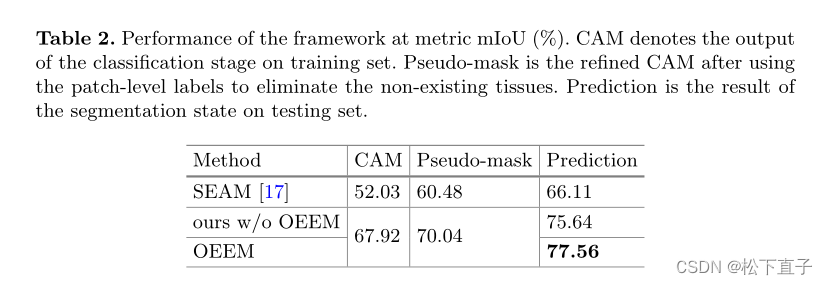
提出了一种新的在线简易示例挖掘(OEEM)方法,该方法鼓励网络关注可信的监督信号,而不是噪声信号,从而减轻伪掩码中不可避免的错误预测的影响。根据腺体数据集的特点,我们设计了一个强大的腺体分割框架。我们的结果超过了许多完全监督方法和弱监督方法,在mIoU下分别超过4.6%和6.04%
代码链接
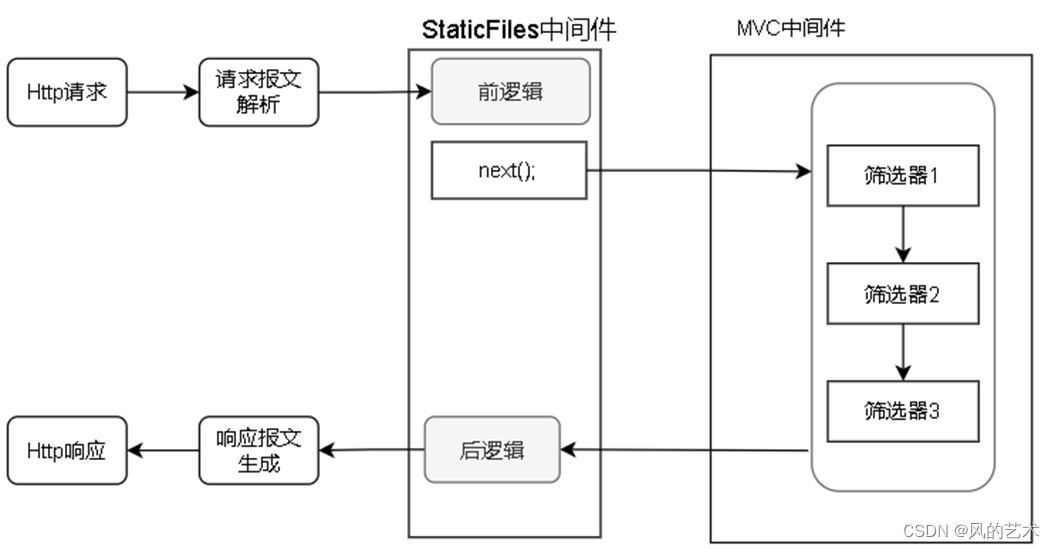
本文方法
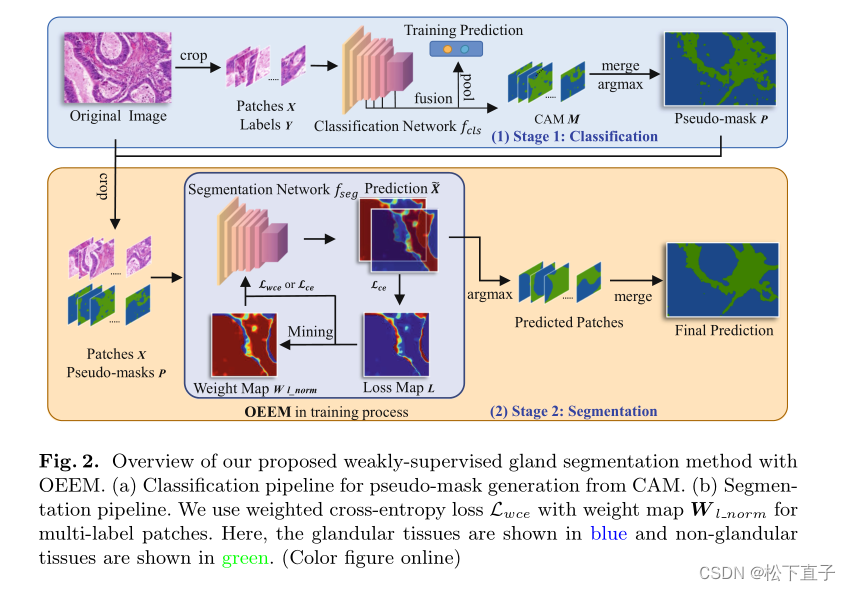
(a) 用于从CAM生成伪掩码的分类流水线
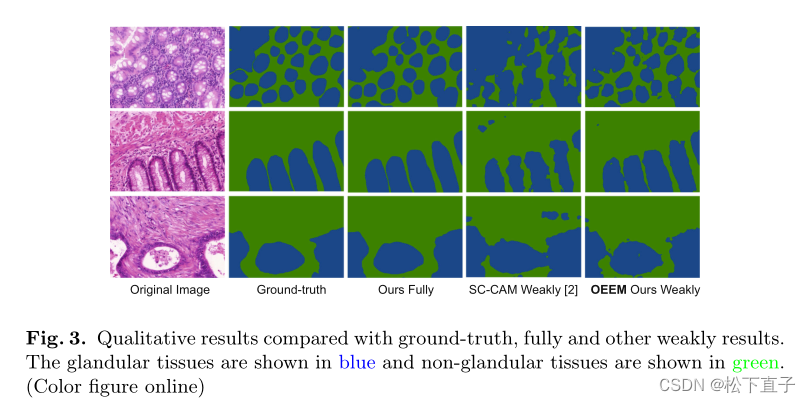
(b) 分割管道:对于多标签补丁,我们使用加权交叉熵损失Lwce和加权映射W l范数。图中,腺组织以蓝色显示,非腺组织以绿色显示
最后三个阶段的特征图在分类器之前与插值进行融合,以获得更好的表示。然后,我们通过将分类器φcls的权重乘以没有平均池化的特征图,得到CAM M∈Rn×H×W,如下所示:
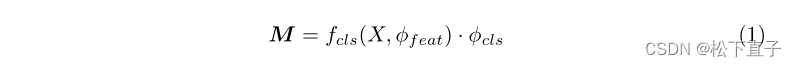
分割
- 提出了OEEM来重新调整损失图,以更好地使用可信和干净的监督
- 提出了在线简易示例挖掘,以动态地从可信的监督信号中学习。具体来说,我们的OEEM通过将损失权重乘以指示难度的度量来修改标准交叉熵损失Lce。
- 表示我们的分割预测图~X和标签Y。我们通过加权交叉熵损失来实现重新加权方案,如下所示:
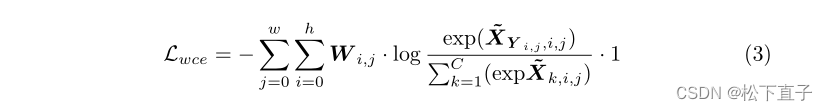
为了得到这个损失权重,我们选择分散在损失图L∈RH×W上的损失和预测得分图上的置信度作为指示学习难度的度量。基于这些指标,我们提出了四种类型的损失权重图来挖掘简单的例子 - 前两种权重类型基于置信度度量。方程4的动机是,简单的例子通常具有很高的可信度。我们首先在类别维度上应用softmax运算sm来将分数归一化为,并选择最大值作为度量来形成权重映射W c max。
- 第二种类型的方程5使用置信度差作为度量,因为可比较的置信度表示更难的例子。
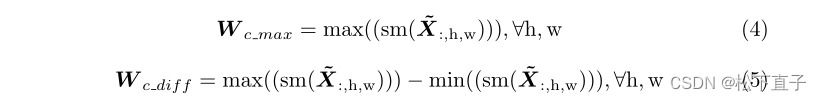
其他两种类型基于损失值。与置信度不同,损失是从置信度和具有更多信息的伪标签中获得的。在伪类别上具有高置信度的噪声具有高损失值,而由干净标签监督的那些像素具有较低的损失值。为了获得更高的损失权重,我们对损失映射L应用减号,并在hw维度上部署softmax函数sm,并对其平均值进行除法。我们将这个过程命名为归一化损耗,如方程6所示。最后,我们将最大置信度和归一化损失结合起来,如等式7所示。
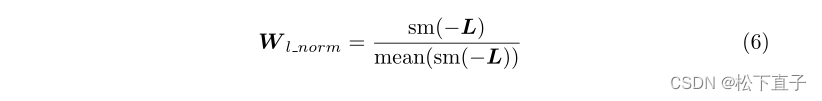
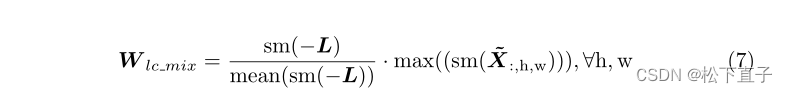
经验经验表明,方程6中的W l范数表现最好。所以我们选择它作为重新加权的度量。请注意,有些图像只包含一种类型的伪影,不应该产生任何噪声。因此,对于类数n=1的图像,我们使用没有OEEM的原始交叉熵损失Lce。然后将分割的最终损失表示为
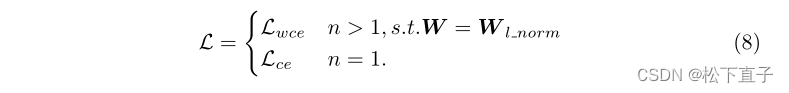
实验结果