文章目录
- DeSD: Self-Supervised Learning with Deep Self-Distillation for 3D Medical Image Segmentation
- 摘要
- 本文方法
- Deep Self-Distillation
- Downstream Transfer Learning
- 实验结果
DeSD: Self-Supervised Learning with Deep Self-Distillation for 3D Medical Image Segmentation
摘要
背景
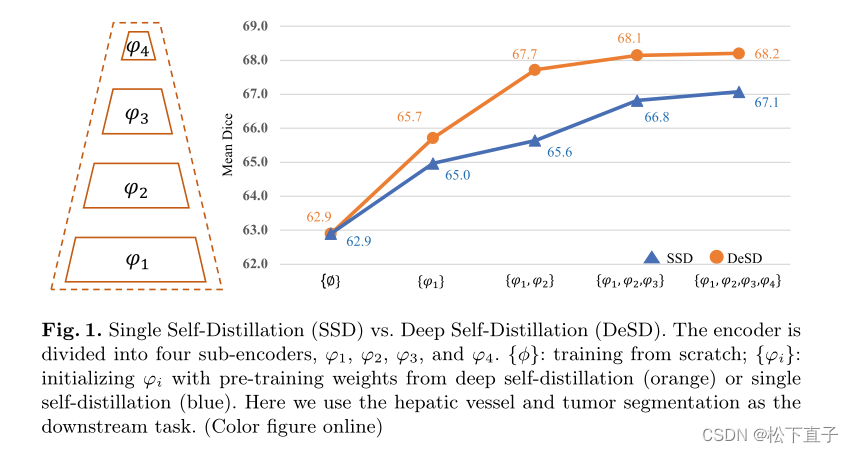
自监督学习(SSL)能够在几乎没有注释的情况下实现高级性能,已被证明在医学图像分割中是成功的。通常,SSL依赖于测量在最深层获得的特征的相似性来吸引正对的特征或排斥负对的特征,然后可能遭受浅层的弱监督。
本文方法
- 以深度自蒸馏(DeSD)的方式重新制定了SSL,以提高浅层和深层的表示质量。
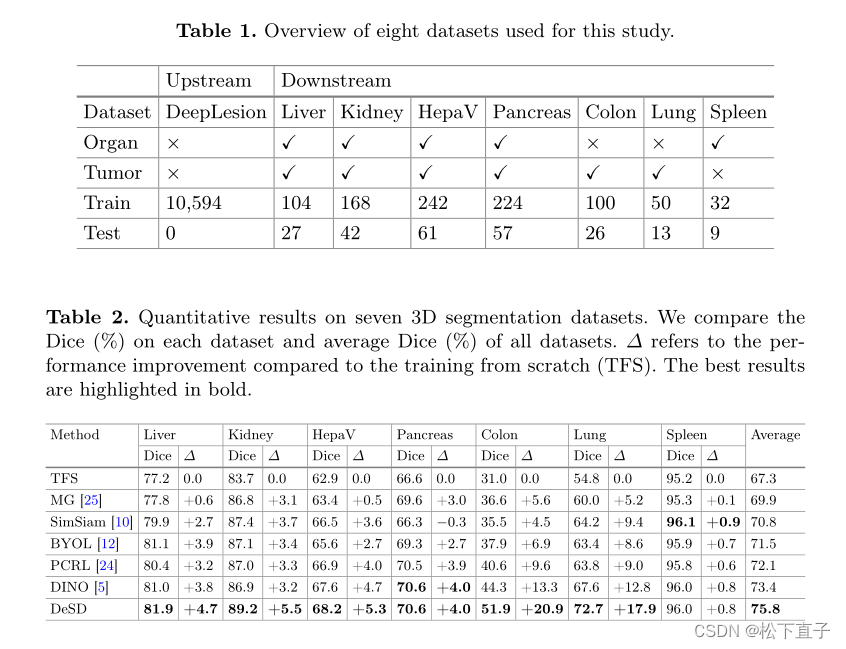
- DeSD模型由在线学生网络和动量教师网络组成,两者都由多个子编码器堆叠。对学生网络中的每个子编码器产生的特征进行训练,以匹配教师网络产生的特征。这样的深度自蒸馏监督能够提高所有子编码器的表示质量,包括浅编码器和深编码器。我们在大规模未标记数据集上预训练DeSD模型,并在七个下游分割任务上对其进行评估。我们的结果表明,与现有的SSL方法相比,所提出的DeSD模型实现了卓越的预训练性能,创下了新的技术水平
代码地址
本文方法
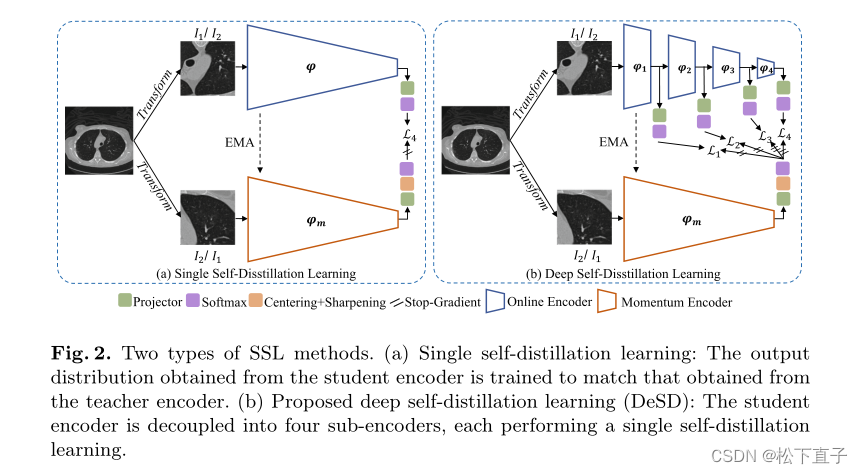
两种类型的SSL方法。(a) 单次自蒸馏学习:从学生编码器获得的输出分布被训练为与从教师编码器获得的相匹配。(b) 建议的深度自蒸馏学习(DeSD):将学生编码器解耦为四个子编码器,每个子编码器执行单个自蒸馏学习
我们的DeSD方法遵循两步SSL范式,即自监督表示学习和完全监督的下游微调。DeSD包含一个在线编码器和一个动量编码器(见图2)。在线编码器进一步分为四个子编码器,这四个子编码器产生多个中间表示。
Deep Self-Distillation
DeSD是基于自蒸馏SSL范式实现的,包括在线学生编码器和动量教师编码器。学生编码器被解耦为四个子部分,分别表示为:两个编码器共享相同的网络架构,而教师网络的参数被公式化为学生网络的动量版本。本研究采用了强大的数据转换,包括翻转、缩放、高斯噪声、高斯模糊、图像亮度和图像对比度,以生成两个视图I1和I2作为Siamese网络的输入
在每次迭代期间,I1和I2依次通过四个子编码器,然后通过全局平均池化将这些子编码器的每个输出特征转换为特征向量。随后,每个子编码器之后是多层感知器(MLP)投影仪(具有四层)和softmax函数,以将特征向量投影到高维潜在空间。前两个MLP层中的每个层都有2048个神经元,随后是批量归一化(BN)和高斯误差线性单元(GELU)激活。瓶颈层有256个没有BN和GELU的神经元。最后一层MLP将神经元数量增加到K,并采用权重归一化来加速训练。与此同时,I2和I1通过动量教师编码器,获得的特征向量被馈送到MLP投影仪,随后是居中和锐化操作以及softmax函数。该输出被视为由在线编码器中的四个子编码器产生的那些目标向量的监督信号。损失函数基于对称交叉熵损失,如下所示
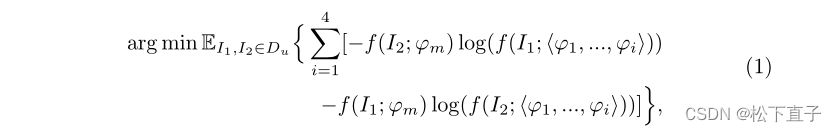
其中Du是一个大规模的未标记数据集,f表示生成输出向量的前馈过程,而<.>是此过程中使用的一组参数。注意,为了简单起见,MLP参数在该方程中被忽略。
上述损失函数仅用于更新在线编码器。采用以下指数移动平均(EMA)策略在每次迭代中更新动量编码器
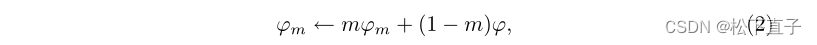
其中,m是动量系数,该动量系数被初始化为0.996,并根据余弦表逐渐增加到1
Downstream Transfer Learning
为了使DeSD预训练的动量编码器适应下游分割任务,我们在其末尾堆叠了一个基于CNN的解码器。解码器参数是随机初始化的。该分割网络以有监督的方式进行训练,以最小化Dice损失和二进制交叉熵损失之和
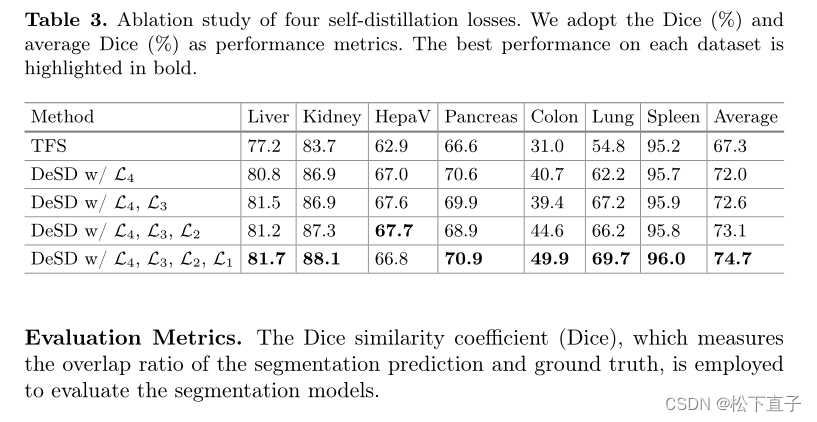
实验结果