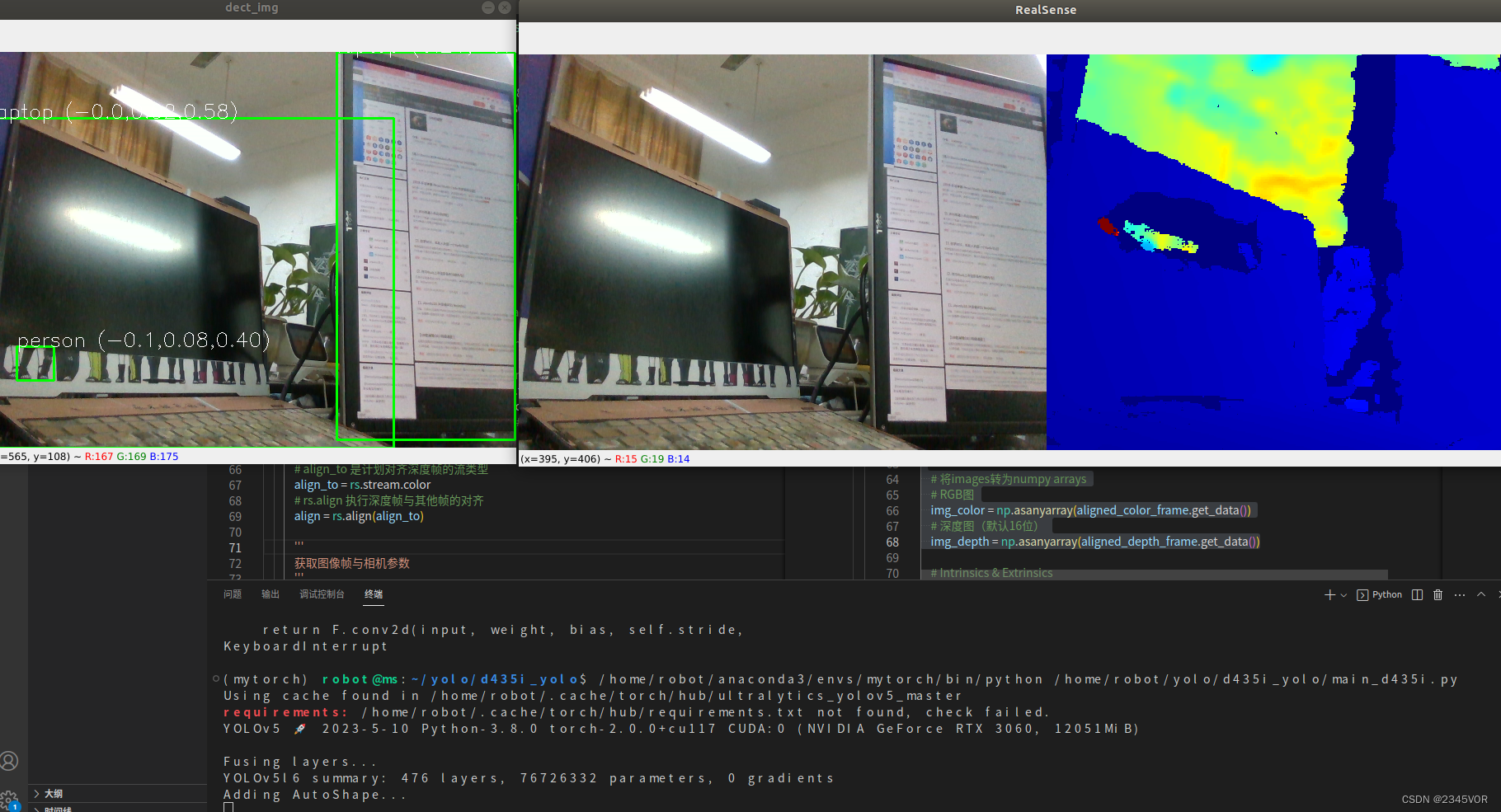
Azure Data Lake Storage Gen2 基于 Azure Blob 存储构建,是一套用于大数据分析的功能。
Azure Data Lake Storage Gen1 和 Azure Blob Storage 的功能在 Data Lake Storage Gen2 中组合在一起。例如,Data Lake Storage Gen2 提供规模、文件级安全性和文件系统语义。你还将获得具有高可用性和灾难恢复功能的低成本分层存储,因为这些功能基于 Blob 存储构建。
专为企业海量数据分析而开发
Azure 存储现在是在 Azure 上创建企业数据湖的起点,这要归功于 Data Lake Storage Gen2。Data Lake Storage Gen2 从头开始创建,支持数 PB 的数据,同时支持数百 GB 的吞吐量,使您能够轻松管理大量数据。
扩展 Blob 存储以包含分层命名空间是数据湖存储第 2 代的关键组件。为了进行有效的数据访问,分层命名空间将对象和文件分组到文件夹层次结构中。斜杠经常用于对象存储名称中,以模拟分层目录结构。Data Lake Storage Gen2的出现使这种安排成为现实。对目录的操作(包括重命名或删除目录)将成为单个原子元数据操作。不需要枚举和处理共享目录名称前缀的每个对象。
Blob 存储是数据湖存储第 2 代的基础,它通过以下方式改进管理、安全性和性能:
性能
由于在分析之前不需要复制或更改数据,因此性能得到了优化。此外,Blob 存储上的分层命名空间执行目录管理活动的效果远远优于平面命名空间,从而提高了作业性能。
管理
由于您可以使用目录和子目录来排列和管理文件,因此管理更加简单。
安全
由于可以对文件夹或特定文件设置 POSIX 权限,因此安全性是可强制执行的。
此外,Data Lake Storage Gen2 相对实惠,因为它基于廉价的 Azure Blob 存储。附加功能降低了使用 Azure 执行大数据分析的总体拥有成本。
数据湖存储第 2 代的重要特征
- Data Lake Storage Gen2使您能够以与Hadoop分布式文件系统(HDFS)相当的方式组织和访问数据。所有Apache Hadoop设置都支持新的ABFS驱动程序,该驱动程序用于访问数据。Azure HDInsight,Azure Databricks和Azure Synapse Analytics是这些环境的一些示例。
- 数据湖第 2 代的安全模型支持 ACL 和 POSIX 权限,以及数据湖存储第 2 代特有的其他粒度。此外,Hive 和 Spark 等框架以及存储资源管理器允许配置设置。
- 经济高效:Data Lake Storage Gen2 提供低成本存储空间和事务。借助 Azure Blob 存储生命周期等功能,随着数据在其生命周期中移动,成本会降低。
- 驱动程序优化:ABFS 驱动程序专为大数据分析量身定制。终结点 dfs.core.windows.net 公开相应的 REST API。
可扩展性
无论是通过数据湖存储第 2 代还是 Blob 存储接口进行访问,Azure 存储都可以在设计上缩放。它可以存储和提供许多艾字节的数据。在高每秒输入/输出操作速率 (IOPS) 下,此存储量的吞吐量以千兆位/秒 (Gbps) 为单位进行测量。处理延迟在服务、帐户和文件级别进行监控,并且每个请求几乎保持不变。无论是通过数据湖存储第 2 代还是 Blob 存储接口进行访问,Azure 存储都可以在设计上缩放。它可以存储和提供许多艾字节的数据。在高每秒输入/输出操作速率 (IOPS) 下,此存储量的吞吐量以千兆位/秒 (Gbps) 为单位进行测量。处理延迟在服务、帐户和文件级别进行监控,并且每个请求几乎保持不变。
成本效益
存储容量和事务成本较低,因为数据湖存储第 2 代构建在 Azure Blob 存储之上。与其他云存储提供商不同,您无需重新定位或更改数据即可对其进行研究。有关定价的更多详细信息,请访问 Azure 存储定价。
分层命名空间等功能也大大提高了许多分析活动的整体性能。由于性能的提高,现在处理相同数量的数据需要更少的计算能力,从而降低了整个分析项目的总拥有成本 (TCO)。
单一服务,多种创意
由于数据湖存储第 2 代基于 Azure Blob 存储,因此可以通过多个概念来描述相同的共享对象。
以下是由各种概念描述的相同对象。除非另有说明,否则以下术语直接同义:
| 概念 | 顶级组织 | 下级组织 | 数据容器 |
| Blob - 通用对象存储 | 容器 | 虚拟目录(仅限 SDK - 不提供原子操作) | 斑点 |
| Azure Data Lake Storage Gen2 - Analytics Storage | 容器 | 目录 | 文件 |
Blob 存储支持功能
帐户有权访问 Blob 存储功能,例如诊断日志记录、访问层和 Blob 存储生命周期管理策略。大多数 Blob 存储功能都完全受支持,但有些功能仅在预览模式下受支持或根本不受支持。
请参阅 Azure 存储帐户中的 Blob 存储功能支持,详细了解数据湖存储第 2 代如何支持每个 Blob 存储功能。
支持的 Azure 服务集成
Data Lake Storage gen2 支持多种 Azure 服务。它们可用于执行分析、生成可视化表示和吸收数据。有关受支持的 Azure 服务的列表,请参阅支持 Azure Data Lake Storage Gen2 的 Azure 服务。
支持的开源平台
数据湖存储 Gen2 由多个开源平台支持。有关完整列表,请参阅支持 Azure 数据湖存储第 2 代的开源平台。
利用 Azure 数据湖存储第 2 代最佳做法
Azure 数据湖存储的第 2 代版本不是特定的服务或帐户类型。它是用于高通量分析任务的工具集合。数据湖存储第 2 代参考中提供了利用这些功能的最佳做法和说明。有关帐户管理的所有其他方面(包括设置网络安全、高可用性设计和灾难恢复)的信息,请参阅 Blob 存储文档内容。
查看功能兼容性和已知问题
设置帐户以利用 Blob 存储服务时,请应用以下方法。
- 若要了解帐户是否完全支持某项功能,请阅读有关 Azure 存储帐户的 Blob 存储功能支持的页面。在启用了 Data Lake Storage Gen2 的帐户中,某些功能要么完全不受支持,要么仅部分受支持。随着功能支持的不断增长,请务必经常查看此页面是否有更改。
- 查看 Azure Data Lake 存储第 2 代的已知问题一文,检查要使用的功能是否有任何限制或需要任何特定说明。
- 浏览专题文章,了解专门适用于启用了 Data Lake Storage Gen2 的帐户的任何建议。
识别文档中使用的术语
在内容集之间切换时,您会注意到一些细微的词汇变化。例如,在 Blob 存储说明的特色特色内容中,将使用术语“Blob”而不是“文件”。从技术上讲,上传到存储帐户的数据会在那里变成 Blob。因此,这句话是准确的。但是,如果您习惯使用术语“文件”,则术语“blob”可能会令人困惑。文件系统也称为“容器”。将这些短语视为可互换的。
考虑保费
如果工作负荷需要较低的恒定延迟和/或每秒大量输入-输出操作 (IOP),请考虑采用高级块 blob 存储帐户。此类帐户中使用高性能硬件来使数据可访问。固态驱动器 (SSD) 旨在实现最小延迟,用于存储数据。与传统硬盘驱动器相比,SSD 提供更大的吞吐量。高级性能具有更高的存储成本,但降低了交易成本。因此,如果应用程序执行大量事务,则高级性能块 blob 帐户可能具有成本效益。
如果存储帐户将用于分析,我们强烈建议将 Azure Data Lake 存储第 2 代与高级块 blob 存储帐户一起使用。Azure 数据湖存储的高级层是将高级块 blob 存储帐户与启用了数据湖存储的帐户结合使用。
改进数据摄取
从源系统引入数据时,源硬件、源网络硬件或与存储帐户的网络连接可能是瓶颈。
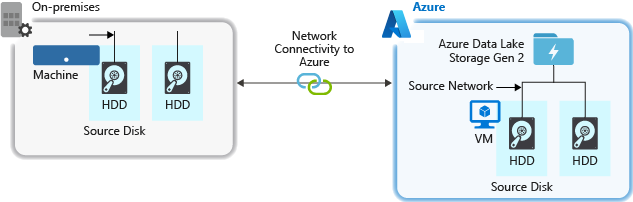
源硬件
请确保仔细选择正确的硬件,无论是在 Azure 上使用虚拟机 (VM) 还是在本地设备上使用。选择具有更快主轴的磁盘硬件,并考虑使用固态驱动器 (SSD)。使用最快的网络接口控制器 (NIC) 进行网络硬件。我们建议使用 Azure D14 VM,因为它们具有足够的网络和磁盘硬件功能。
连接到存储帐户的网络
源数据和存储帐户之间的网络连接有时可能存在瓶颈。当源数据位于本地时,可能需要使用 Azure ExpressRoute 专用链接。当源数据(如果位于 Azure 中)与启用了 Data Lake Storage Gen2 的帐户位于同一 Azure 区域中时,性能最佳。
设置数据引入机制以实现最并行的处理
通过并行运行尽可能多的读取和写入来使用所有可用吞吐量,以获得最佳性能。
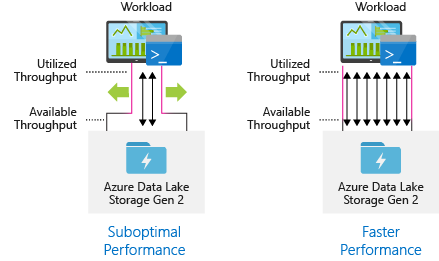
结构化数据集
请考虑事先组织数据的结构。性能和费用可能会受到文件格式、文件大小和目录组织的影响。
文件格式
可以使用不同的格式来吸收数据。数据可以以压缩的二进制格式(如 tar)呈现。go或以人类可读的格式,如JSON,CSV或XML。数据也可以以各种大小到达。大型文件(几 TB)可以构成数据,例如从本地系统导出 SQL 表的信息。例如,来自物联网 (IoT) 解决方案的实时事件数据也可以以大量小文件(大小为几千字节)的形式出现。通过选择合适的文件格式和文件大小,您可以最大限度地提高效率并降低成本。
Hadoop 支持的一系列文件格式专为存储和分析结构化数据而设计。Avro、Parquet 和优化行列式 (ORC) 格式是一些流行的格式。这些都是可以被机器读取的二进制文件格式。它们被压缩以帮助您控制文件大小。它们是自我描述的,因为每个文件都包含一个嵌入式架构。用于存储数据的方法因格式而异。Parquet 和 ORC 格式以列式方式存储数据,而 Avro 以基于行的格式存储数据。
如果您的 I/O 模式写入量更大,或者您的查询模式倾向于完整提取大量信息行,则可能需要使用 Avro 文件格式。例如,Avro 格式适用于写入事件或消息序列的消息总线,如事件中心或 Kafka。
当 I/O 模式的读取密集度更高或查询模式集中在记录中的特定列子集上时,请考虑 Parquet 和 ORC 文件格式。读取事务可能会简化为仅获取某些列,而不是读取完整记录。
开源 Apache Parquet 是一种文件格式,专为读取密集型分析管道而设计。由于 Parquet 的列式存储格式,您可以跳过不相关的数据。由于查询可能专门针对要从存储发送到分析引擎的数据,因此它们的效率要高得多。此外,Parquet 提供了有效的数据编码和压缩技术,可以降低数据存储的成本,因为相似的数据类型(对于列)存储在一起。Azure Synapse Analytics、Azure Databricks 和 Azure Data Factory 等服务中支持本机 Parquet 文件格式。
文件大小
较大的文件可提高性能并降低费用。
HDInsight 等分析引擎通常包括每个文件的开销,其中包括列出、确定访问权限和执行不同元数据操作等活动。几个小文件形式的数据存储可能会对性能产生负面影响。为了提高性能,请将数据整理成更大的文件(大小为 256 MB 到 100 GB)。某些引擎和程序可能无法有效处理大小超过 100 GB 的文件。
降低事务成本是放大文件的另一个好处。您将以 4 MB 为增量为读取和写入活动付费,无论文件包含 4 MB 还是仅包含几 KB。有关定价的详细信息,请参阅 Azure 数据湖存储定价。
原始数据由大量小文件组成,有时可能受到数据管道的有限控制。我们建议您的系统有一个程序,将小文件合并成较大的文件,以供下游应用程序使用。如果要实时处理数据,则可以将实时流式处理引擎(如 Spark 流式处理或 Azure 流分析)与消息代理(如事件中心或 Apache Kafka)结合使用,将数据另存为较大的文件。将小文件合并为大文件时,请考虑将它们保存为读取优化格式(如 Apache Parquet),以供以后处理。
目录结构
这些是使用物联网 (IoT)、批处理方案或优化时序数据时要考虑的一些典型布局。每个工作负载对数据的使用方式都有各种要求。
批量工作的安排
在物联网工作负载中,来自许多商品、设备、企业和客户的大量数据可能会被吸收。目录布局需要及时规划,以便为下游用户提供组织、安全和有效的数据处理。以下设计可以作为需要考虑的广泛模板:
{Region}/{SubjectMatter(s)}/{yyyy}/{mm}/{dd}/{hh}/
为了说明,英国飞机发动机的着陆遥测结构可能如下所示:
UK/Planes/BA1293/Engine1/2017/08/11/12/
在此示例中,通过将日期添加到目录结构的末尾,您可以更轻松地将区域和主题限制为用户和组。如果日期结构排在第一位,那么确保这些领域和主题将更具挑战性。例如,如果您想限制对英国数据的访问或仅限制对特定飞机的访问,则需要为每个小时目录下的多个目录请求单独的授权。此外,随着时间的推移,这种安排将迅速增加目录的数量。
批任务的结构
将数据添加到“in”目录是一种频繁的批处理技术。处理完数据后,将新数据放在“out”目录中,以便其他进程可以使用它。此目录结构偶尔用于只需要检查单个文件的任务,并且不一定需要跨大数据集大规模并行执行。一个有用的目录结构具有父级目录,用于区域和主题等内容,如上面显示的物联网结构(例如,组织、产品或生产者)。为了在处理中实现更好的组织、筛选搜索、安全性和自动化,请在设计结构时考虑日期和时间。上传或下载数据的频率决定了数据结构的粒度级别。
由于数据损坏或意外格式,文件处理偶尔会失败。在这些情况下,目录结构可能会受益于具有 /bad 文件夹,以便可以将文件移动到那里进行其他分析。批处理任务还可以监督报告或提醒用户注意这些问题文件,以便他们可以执行手动操作。请考虑以下模板排列:
{Region}/{SubjectMatter(s)}/In/{yyyy}/{mm}/{dd}/{hh}/{Region}/{SubjectMatter(s)}/Out/{yyyy}/{mm}/{dd}/{hh}/{Region}/{SubjectMatter(s)}/Bad/{yyyy}/{mm}/{dd}/{hh}/
例如,一家营销公司每天从北美客户那里接收客户更新的数据提取。在处理之前和之后,它可能类似于以下代码片段:
NA/Extracts/ACMEPaperCo/In/2017/08/14/updates_08142017.csvNA/Extracts/ACMEPaperCo/Out/2017/08/14/processed_updates_08142017.csv
在批处理数据处理直接到数据库(如 Hive 或传统 SQL 数据库)的典型方案中,输出已进入 Hive 表或外部数据库的单独文件夹;因此,不需要 /in 或 /out 目录。例如,每个目录将接收来自使用者的每日数据提取。之后,每日 Hive 或 Spark 作业将由 Azure Data Factory、Apache Oozie 或 Apache Airflow 等服务启动,以处理数据并将其写入 Hive 表。
时序的数据结构
对 Hive 工作负荷的时序数据进行分区修剪可能会使某些查询仅读取部分数据,从而提高性能。
用于吸收时序数据的管道通常将其文件组织到命名文件夹中。下面是通常按日期排列的数据示例:
/DataSet/YYYY/MM/DD/datafile_YYYY_MM_DD.tsv
请记住,日期和时间详细信息可以在文件名和文件夹中找到。
以下是日期和时间的典型格式:
/DataSet/YYYY/MM/DD/HH/mm/datafile_YYYY_MM_DD_HH_mm.tsv
再一次,您所做的关于如何组织文件夹和文件的决定应该针对更大的文件大小和每个文件夹中可管理的文件数量进行优化。
设置安全性
首先查看 Blob 存储的安全注意事项一文中的建议。你将收到有关如何保护防火墙后面的数据、防止恶意或意外删除以及使用 Azure Active Directory (Azure AD) 作为标识管理基础的最佳做法建议。
然后,有关启用了数据湖存储第 2 代的帐户特有的建议,请参阅 Azure 数据湖存储第 2 代页的访问控制模型部分。本文介绍如何使用 Azure 基于角色的访问控制 (Azure RBAC) 角色和访问控制列表 (ACL) 将安全权限应用于分层文件系统中的目录和文件。
引入、执行和评估
数据可以从各种来源和各种方法摄取到支持 Data Lake Storage Gen2 的帐户中。
若要对应用程序进行原型设计,可以从 HDInsight 和 Hadoop 群集以及较小的即席数据集引入大量数据。您可以接收由各种来源(包括软件、硬件和传感器)生成的流数据。您可以利用工具逐个事件实时记录和处理此类数据,然后将事件批量写入您的帐户。还可以引入 Web 服务器日志,其中包括页面请求历史记录等详细信息。如果您希望能够灵活地将数据上传组件集成到更大的大数据应用程序中,请考虑使用定制的脚本或程序来提交日志数据。
数据在帐户中可用后,可以对该数据运行分析、创建可视化效果,甚至将数据下载到本地计算机或其他存储库,例如 Azure SQL 数据库或 SQL Server 实例。
监视遥测
操作服务需要仔细注意使用情况和性能监视。示例包括频繁发生、具有大量延迟或限制服务的过程。
通过 Azure Monitor 中的 Azure 存储日志,可以访问存储帐户的所有遥测数据。此功能允许将日志存档到另一个存储帐户,并将存储帐户与 Log Analytics 和事件中心链接。访问 Azure 存储监视数据参考,查看指标、资源日志及其相应结构的整个集合。
根据您打算访问它们的方式,您可以将日志存储在您喜欢的任何位置。例如,如果希望几乎实时访问日志,并能够将日志中的事件与 Azure Monitor 中的其他指标连接,则可以将日志存储在 Log Analytics 工作区中。然后,使用 KQL 和创作查询来查询日志,其中列出了工作区中的 StorageBlobLogs 表。
如果希望存储日志以进行近实时查询和长期保留,则可以将诊断设置设置为将日志发送到 Log Analytics 工作区和存储帐户。
如果要通过其他查询引擎(如 Splunk)检索日志,可以将诊断设置设置为将日志发送到事件中心,并将日志从事件中心引入到首选目标。
结论
Azure Data Lake Storage Gen1 和 Azure Blob Storage 的功能在 Data Lake Storage Gen2 中组合在一起。例如,Data Lake Storage Gen2 提供规模、文件级安全性和文件系统语义。你还将获得具有高可用性/灾难恢复功能的低成本分层存储,因为这些功能基于 Blob 存储构建。