目录
Review Machine Learning
Introduction of Meta Learning
What is Meta Learning?
Meta Learning的三个步骤
Meta Learning的framework:
ML v.s. Meta
Meta Learning的training
What is learnable in a learning algorithm?
初始化参数θ0
Optimizer
Network Structure
Data Processing
Sample Reweighting
Beyond Gradient Descent
Meta Learning的Applications
More about Meta Learning
Meta Learning v.s. Self-supervised Learning
Meta Learning v.s. Knowledge Distillation
Meta Learning v.s. Domain Adaptation
Meta Learning v.s. Life-long Learning
Meta Learning: Learn to learn
Review Machine Learning
Machine Learning = Looking for a function
Machine Learning有三个step:
Step 1: Function with unknown
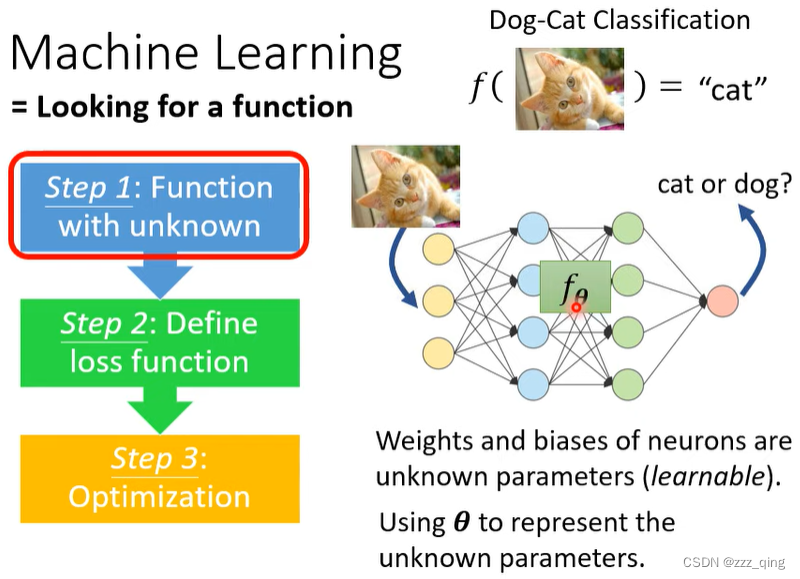
Step 2: Define loss function

Step 3: Optimization

Introduction of Meta Learning
What is Meta Learning?

Meta Learning的三个步骤
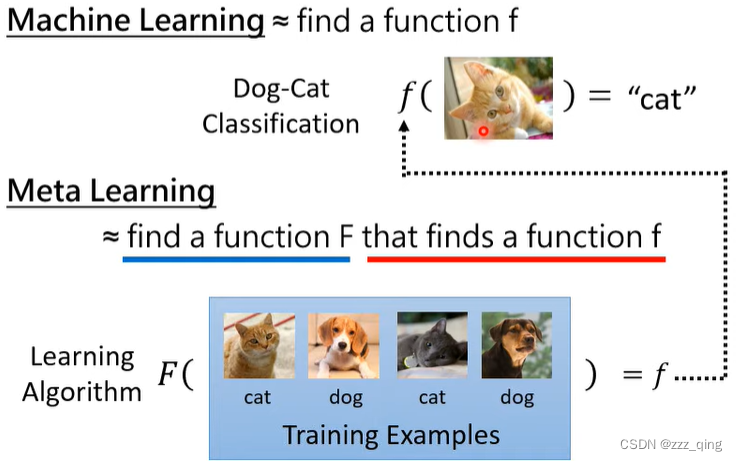
Machine Learning通过三个步骤找function,Meta Learning通过三个步骤找learning algorithm:
step 1: What is learnable in a learning algorithm?
找出learning algorithm中要被machine学出来的东西,例如Net Architecture, Initial Parameters, Learning Rate。这些之前都是人自己决定的,现在我们期待它们是可以被学出来的。我们把这些在learning algorithm里面想要学出来的东西统称为Φ。

step 2: Define loss function(L(Φ)) for learning algorithm FΦ


In typical ML, we compute the loss based on training examples.
In meta, we compute the loss based on testing examples.
step 3: Find Φ that can minimize L(Φ)

Meta Learning的framework:

ML v.s. Meta
Goal:
Training Data:

Framework:

Loss:

上面介绍的是它们的差别,下面介绍它们的相同之处:

Meta Learning的training
假设在training的时候使用gradient descent,那就需要求出loss,即求出L(Φ),所以需要把每个ln求出来。要算第n个任务的ln,要进行一次episode(一次within-task training+一次within-task testing),所以要算一个ln,运算量比较大。

What is learnable in a learning algorithm?
下面用一些实例介绍在meta Learning里面,什么是可以被学的。
Review: Gradient Descent
我们一般最常用的learning algorithm就是gradient descent:

初始化参数θ0

在gradient descent的整个过程中,θ0是可以被train出来的。如何找出一个对训练特别有帮助的initial的参数θ0——MAML:

How to train MAML (train MAML也需要调参数,需要random seed):

MAML v.s. pre-training:


在self-supervised learning还不流行的时候,pre-training比较常见的做法是把好几个任务的资料倒在一起当做一个任务进行训练,这种做法叫做multi-task learning。通常把multi-task learning的方法当做meta的baseline。

Why MAML is good? 关于MAML为什么会好有两个不同的假设,rapid learning 和feature reuse,下图中的paper得到的结论是feature reuse是MAML好的理由:

Optimizer
除了学习初始化的参数θ0,还可以学习optimizer:

Network Structure
Network Structure也可以被训练出来。训练network架构这系列的研究,叫做Network Architecture Search (NAS)。


在NAS中,Φ是network架构,不好微分,所以可以用RL硬做:


除了用RL硬做以外,用Evolution Algorithm也是可以的。
把Network Architecture改一下,让它变得可以微分,也是可以做的,有个经典的做法叫DARTS:

Data Processing

Sample Reweighting

Beyond Gradient Descent
上面的方法都是基于gradient descent去做改进,有没有可能完全舍弃gradient descent?


Meta Learning的Applications
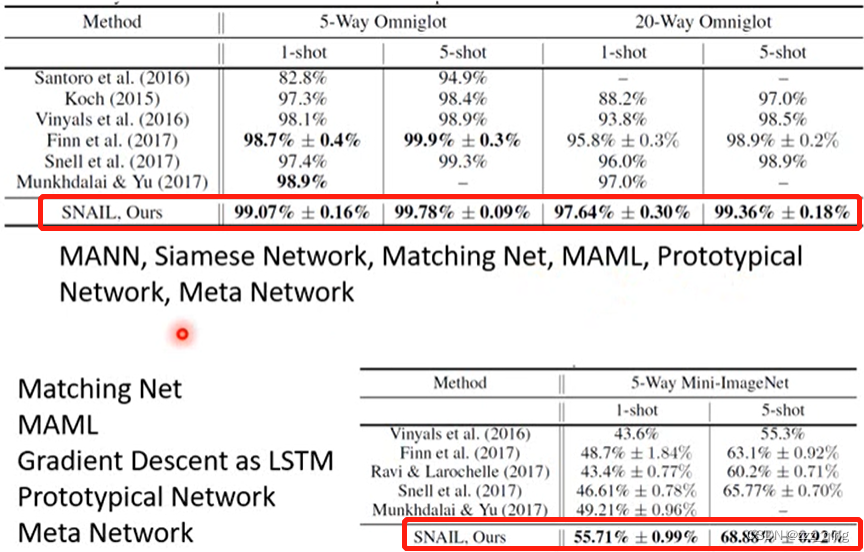
今天做meta learning的时候,最常拿来测试Meta Learning技术的任务是Few-shot lmage Classification。
Few-shot lmage Classification: Each class only has a few images

N-ways K-shot classification: In each task, there are N classes, each has K examples.
In meta learning, you need to repare many N-ways K-shot tasks as training and testing tasks.
如何寻找一堆N-ways K-shot的任务?在文献上,最常见的做法是使用Omniglot这个corpus当做
benchmark corpus:


N-ways K-shot的任务做在Omniglot上没什么实际的作用,但是meta learning不是只能用在Omniglot上面,下表列举了meta learning在语音还有自然语言处理上的应用(纵轴是不同meta learning的方法,横轴是不同的应用):

More about Meta Learning
Meta Learning v.s. Self-supervised Learning
Self-supervised Learning (BERT and pals):

Learn to lnit (MAML family):

BERT和MAML它们有共同的目标——找初始化的参数。
BERT和MAML不是互斥的,它们可以相辅相成。MAML通过gradient descent的方法去learn一组初始化的参数,但MAML本身也需要initialize的参数Φ0,BERT可以用来寻找Φ0:


BERT和MAML各有长短,把它们结合在一起的实验结果如下:

有关meta learning用在自然语言处理上的一些work,如下图,在做MAML的时候,多数文章都使用了BERT或Word Embedding做initialization:

Meta Learning v.s. Knowledge Distillation
Knowledge Distillation:

在Knowledge Distillation中,大的model、即teacher model到底擅不擅长教学?因为在训练过程中,teacher model只是被当做一个普通的的model去训练,并没有教teacher model如何teaching。
有文献指出,在分类任务上做的特别好的teacher,不一定擅长教学:

Can the teacher-network “learn to teach”? —— meta learning
要让teacher net learn to teach,teacher net update参数的目标不是自己能够做多好,而是student可以做多好:

Meta Learning v.s. Domain Adaptation
Domain Adaptation:

Meta Learning for Domain Generalization:

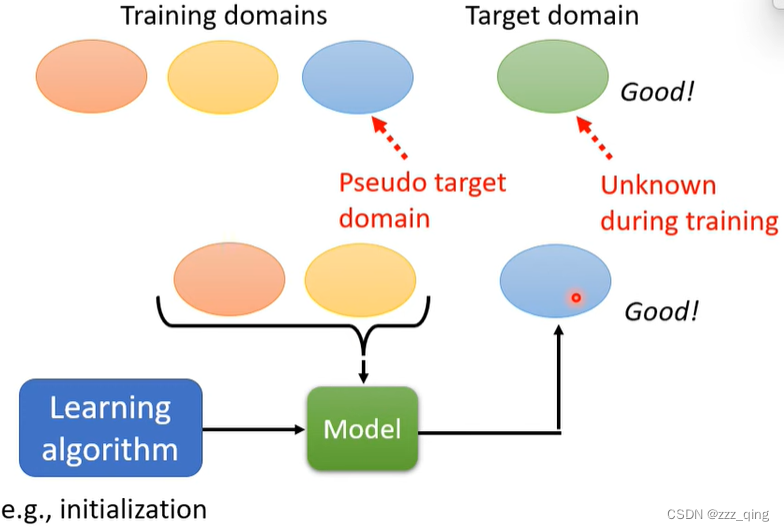

Example -Text Classification:

Meta Learning可以帮助做domain adaptation,但是Meta Learning本身也可能会遇到需要做domain adaptation的状况:

Meta Learning v.s. Life-long Learning
Lifelong Learning Scenario:
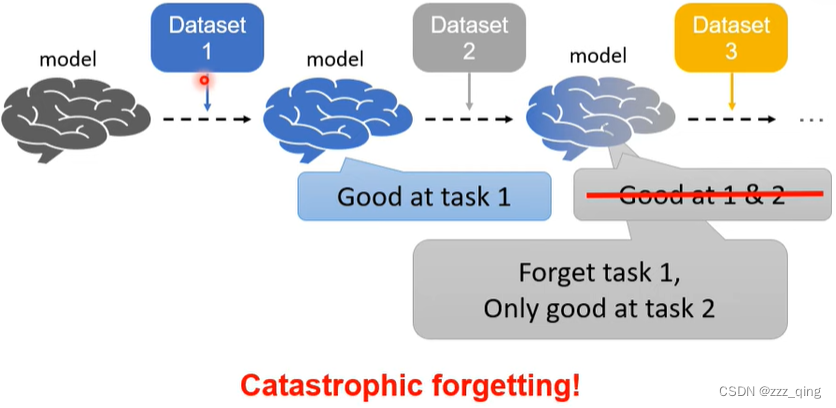
在过去的笔记中,有写过一些处理Catastrophic forgetting的方法,meta learning可以强化这些方法,下面以Regularization-based的方法为例:


在之前的笔记中提过一系列Regularization-based的方法,例如EWC、SI等,这些方法是人设计的。除了让人设计Regularization以外,可以通过meta learning找一个比较好的algorithm,这个比较好的algorithm可以避免Catastrophic forgetting:

Meta Learning可以帮助learn一个比较好的algorithm,这个algorithm可以避免Catastrophic forgetting,但是Meta Learning本身也可能遇到Catastrophic forgetting的状况,如何解决参见下图中的论文: