大家好呀,我是一个SLAM方向的在读博士,深知SLAM学习过程一路走来的坎坷,也十分感谢各位大佬的优质文章和源码。随着知识的越来越多,越来越细,我准备整理一个自己的激光SLAM学习笔记专栏,从0带大家快速上手激光SLAM,也方便想入门SLAM的同学和小白学习参考,相信看完会有一定的收获。如有不对的地方欢迎指出,欢迎各位大佬交流讨论,一起进步。
目录
1. 点云数据介绍
2. 点云主成分分析
2.1 维度缩减 将点云投影到二维,从而使得点云被更好的分类。
2.2 表面法向量估计
3. 点云滤波
3.1 噪点去除
Radius Outlier Removal
Statistical Outlier Removal
3.2 下采样
Voxel Grid Downsampling
Farthest Point Sampling
Normal Space Sampling
Learning to Sampling
3.3 上采样
4. 点云最邻近问题
4.1 点云搜索
4.2 点云存储
Binary Search Tree 二叉树
kd-tree
Oc-tree
5. 点云聚类
5.1 K-Means算法
5.2 K-Medoids
编辑5.3 高斯GMM模型
5.4 Spectral Clustering 谱聚类
5.5 Mean Shift聚类
编辑5.6 DBSCAN
6. 点云拟合
6.1 最小二乘法
6.2 RANSAC随机抽样一致算法
7. 点云特征点提取与描述
7.1 特征点提取
3DHarris
NARF
SIFT3D
7.2 特征点描述
PFH
SPFH
基于坐标系Signature based
8. 点云匹配
8.1 ICP基于距离
8.2 NDT基于概率
在学习SLAM算法之前需要知道点云数据的类型和基本特性,这样我们才明白每一步是做什么的,下来我们来一起学习一下。
1.点云数据介绍
点云是一个数据集,数据集中的每个点代表一组X、Y、Z几何坐标和一个强度值,这个强度值根据物体表面反射率记录返回信号的强度。当这些点组合在一起时,就会形成一个点云,即空间中代表3D形状或对象的数据点集合。主要特征如下:
Ø 密度不均匀(稀疏性)
Ø 不规则
Ø 没有纹理信息(三人成车)
Ø 对深度学习的特点:无序性,旋转不变性

2. 点云主成分分析
Principle Component Analysis主成分分析,PCA是寻找点云的主要方向,可以利用主成分分析,对点云进行如下操作:
2.1 维度缩减 将点云投影到二维,从而使得点云被更好的分类。
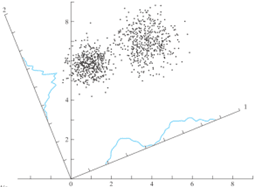
2.2 表面法向量估计
点云拟合曲面的切面的法向量,只有定义邻域才有法向量,邻域大相对平滑受个别点的影响小,邻域大比较灵敏但容易受影响。法向量是最没用的向量,所有点投影到这个向量上的值加起来最小,反应最少的特征。法向量估计可以应用到点云分割、聚类、平面点检测、作为点云的一个特征。


3. 点云滤波
对点云的密度进行处理
3.1 噪点去除
去除点云中的离散点
-
Radius Outlier Removal

-
Statistical Outlier Removal

3.2 下采样
对点云的密度进行降低,保证点云的整体特征不变
-
Voxel Grid Downsampling
核心思想,将点用体素内少量的中心点代替表示。
两种选点方式:1. 一个格子中计算平均点 2. 一个格子中随机选一个点


-
Farthest Point Sampling
核心思想:挑一个点距离最远的点
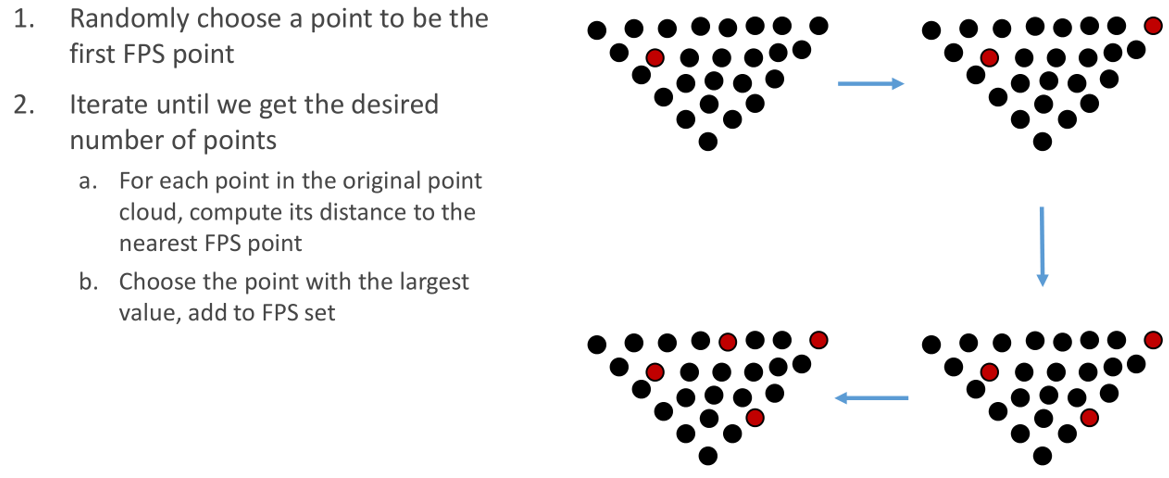
-
Normal Space Sampling
核心思想:保留特征突变的点,不会漏掉特征。适用于点云对齐
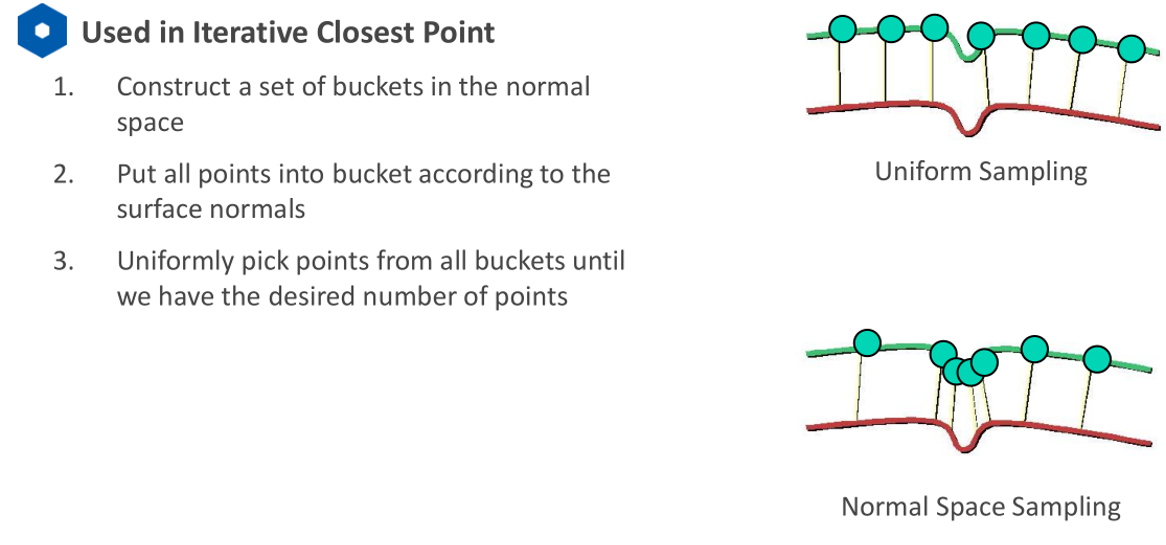
-
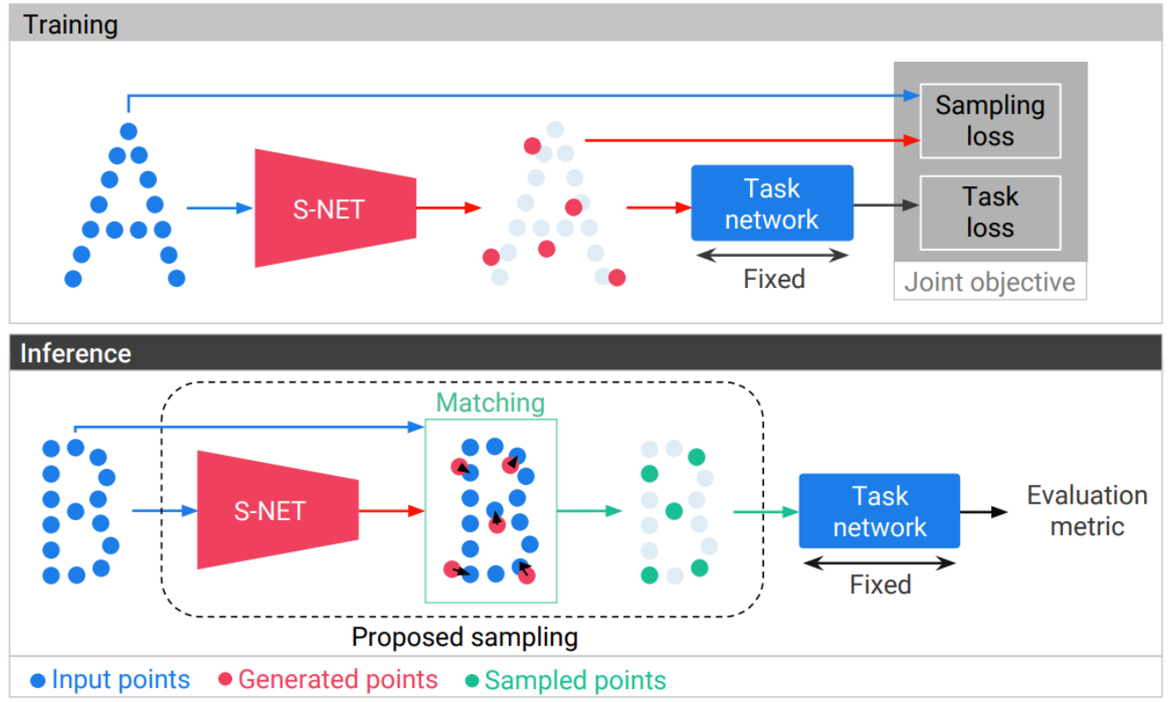
Learning to Sampling
核心思想:传统方法通过几何关系找到降采样点,S-NET是根据语义关系,即经过降采样之后的点云输入网络还是能够得到同样的标签。设定几何约束,来使降采样的点与原来的点云距离相似。
3.3 上采样
点云上采样是将低密度的点云转换为高密度的点云的一种操作。与点云下采样相对应,点云上采样的目的是在保留原始点云几何形状的同时,增加点云的分辨率和细节信息。
点云上采样通常有两种方法:
-
基于重构的方法:这种方法通过对点云进行重构(如曲面重构、体素网格化等),生成更密集的点云。
-
基于插值的方法:这种方法通过对原始点云中的点进行插值(如最近邻插值、高斯过程插值等),生成新的点,从而增加点云的密度。
点云上采样的应用场景包括但不限于:医学图像处理、机器人视觉、三维重建等领域。
4. 点云最邻近问题
在SLAM中常会遇见点云的特征点匹配这类问题,如何寻找最邻近点成为了主要问题。
点云最邻近问题难点:1. 不规则 2. 三维 3. 数据量大
最邻近问题算法一般流程: 1. 分隔空间 2. 搜索空间 3. 停止搜索
算法主要分为点云储存和搜寻两个主要算法
4.1 点云搜索
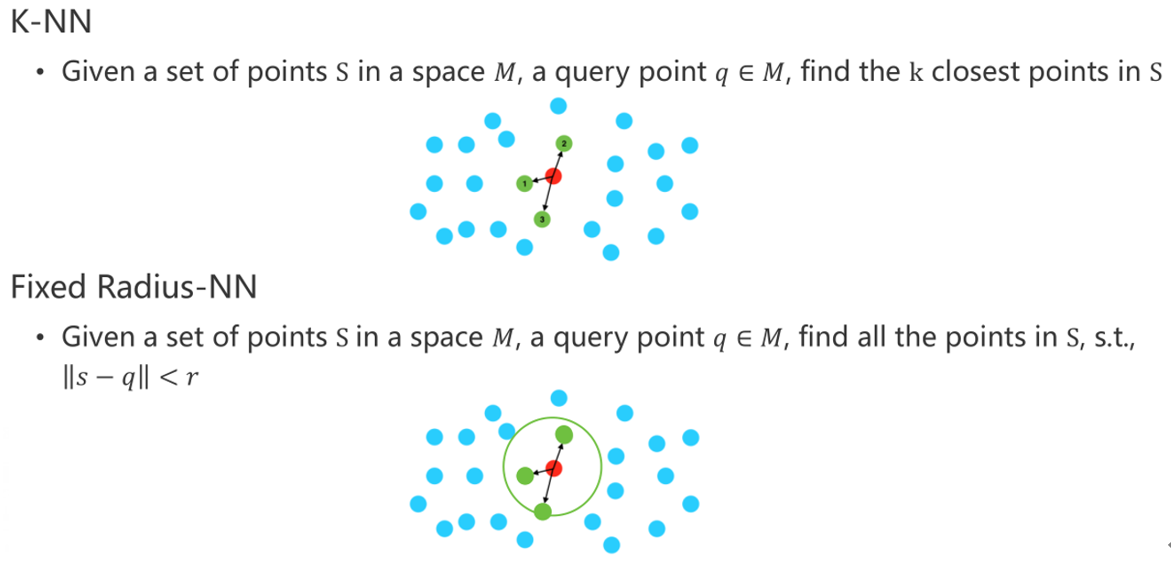
4.2 点云存储
-
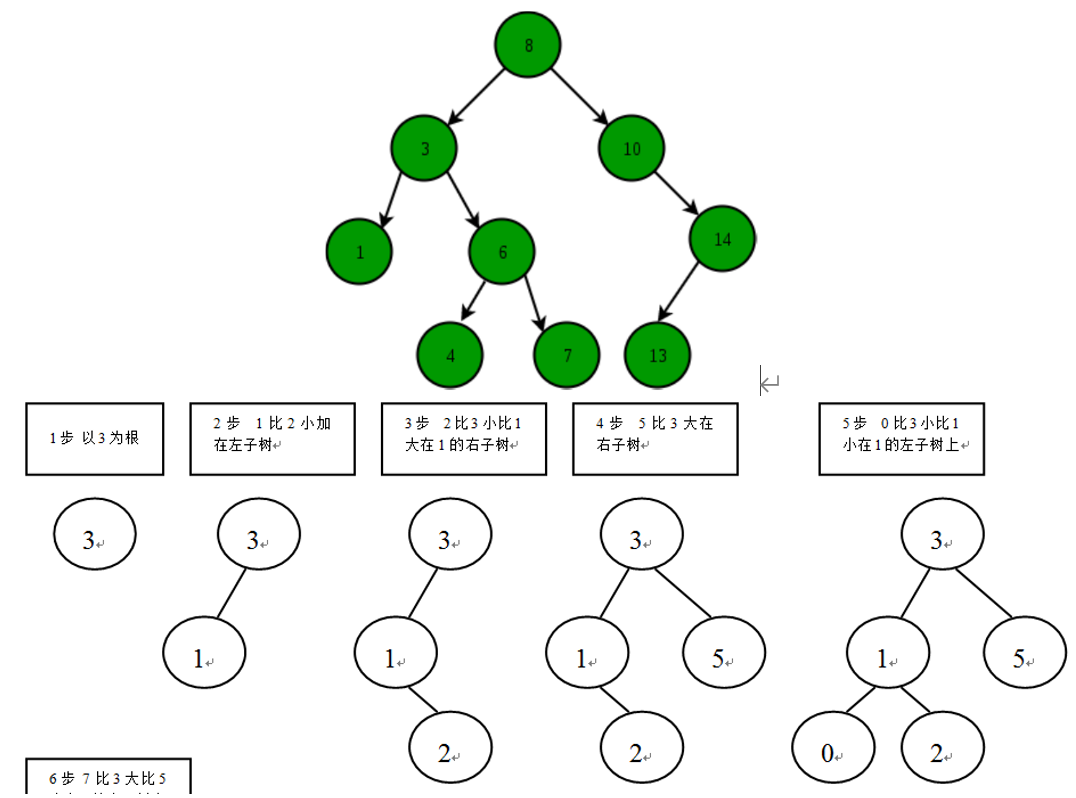
Binary Search Tree 二叉树
(适用于一维数据)
一棵二叉树是结点的一个有限集合,该集合或者为空,或者是由一个根节点加上两棵别称为左子树和右子树的二叉树组成。二叉排序树(BST),任何一个非叶子结点的值,要大于其左子结点的值,小于其右子结点的值。二叉树的特点:
1、每个节点最多有两棵子树,即不存在超过度为2的节点。
2、二叉树的子树有左右之分,且左右不能颠倒。
-
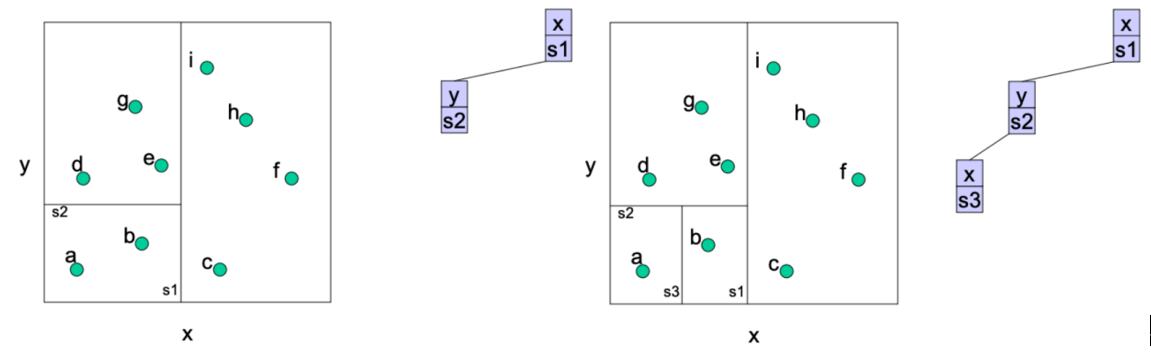
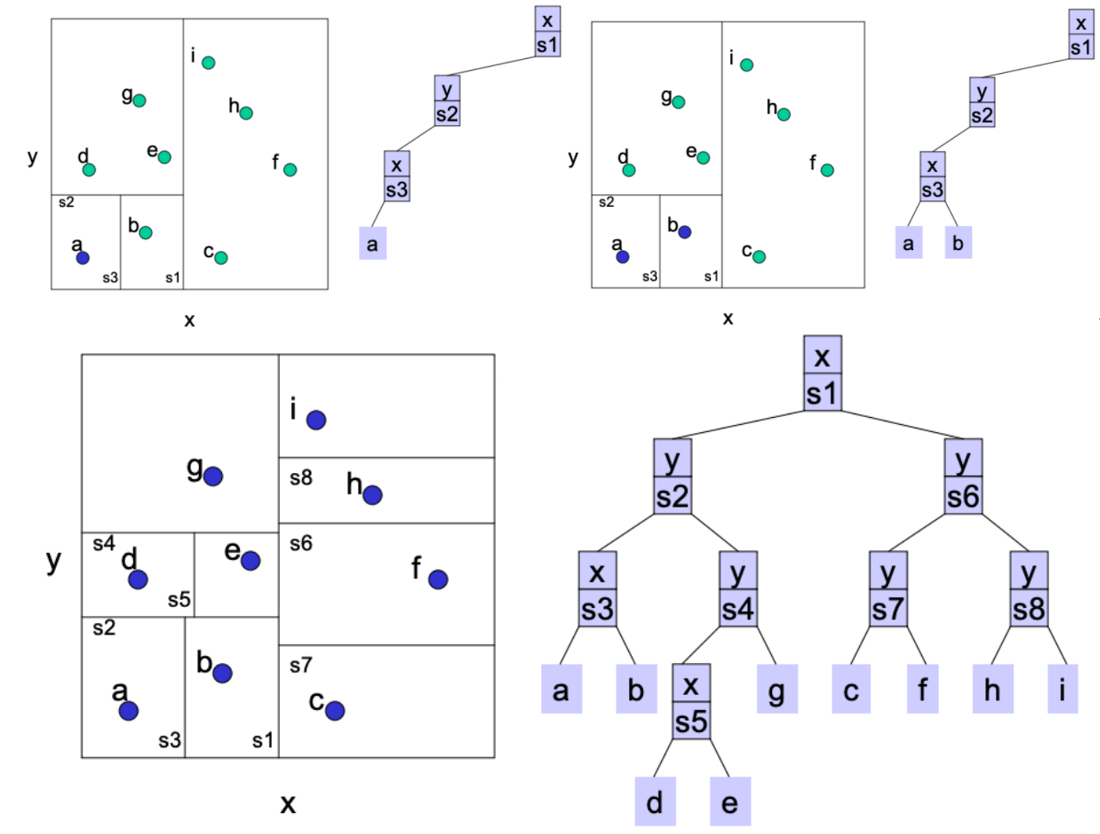
kd-tree
在每个维度应用一下二叉树就是KD树,先随意找一个方向切

按维度轮流切,切到leaf_size=1,即区域中只有一个点。每一层需要排序找中间点进行切割。
-
Oc-tree
专门为三维搜索建立的数据结构,与KD树的区别是一次运用多维度信息进行切割。

KD-tree和Octree都是常用的点云匹配中的搜索数据结构,但在实际应用中,KD-tree通常比Octree更为常用,原因如下:
-
KD-tree的查询速度通常比Octree快,尤其是在高维数据(如3D点云)下,KD-tree的性能更优。这是因为KD-tree中每个节点只需要存储一个划分维度和两个子节点,而Octree中需要存储更多的信息,因此Octree需要更多的存储空间和计算量。
-
KD-tree的建立速度通常比Octree快,尤其是在数据维度较高时,Octree需要更多的时间来构建树状结构。
-
在一些点云匹配的应用中,KD-tree能够提供更好的匹配效果。例如,在最近邻搜索中,KD-tree能够更好地处理密集分布的点云,因为KD-tree在空间中按照一定的规则对点云进行了划分,能够有效地减少搜索空间。而Octree在处理密集点云时可能会出现效率不高的情况,因为Octree需要在每个叶节点上都进行搜索。
虽然KD-tree比Octree在点云匹配中更为常用,但在某些特定的场景下,Octree也可能更适用,例如在处理稀疏分布的点云时。因此,在实际应用中需要根据具体场景选择合适的搜索数据结构。
- iKD-Tree
Ø KdTree的问题
随着节点的“插入”和“删除”,KdTree也得改变,因为KdTree是由无数个节点组成的。在SLAM中,更关心的是KdTree如何删除,KdTree不断地插入新的节点,删除过旧的节点,那么在这个过程中,会导致kdTree结构被破坏(一个完整的结构,其中一部分被删除了,结构肯定被破坏了,而且“树”的平衡性也会被破坏)所谓 “平衡性”,就是“树”的左右两侧,节点数差大于阈值,删除一个中间节点意味着该节点下方的所有节点都要重构新的subtree,因此删除是一个很低效的操作,当KdTree的结构被破坏的时候,搜索效率大幅度下降。针对KdTree,大量的时间并不是花在“搜索”上,而是消耗在“树的构建”,因为每次“删除节点”,都需要重新构建“树”,非常的耗时;
Ø “树”结构完整性
针对Kd-Tree的“结构被破坏,不得不重建”的问题,iKdTree设计了“增量式动态Kd-Tree0”算法,可以实现较好的“搜索/插入/删除”操作,而且不会破坏系统的“平衡性”;
在传统的Kd-Tree中,删除一个中间节点意味着该节点下方的所有节点都要重构新的subtree,因此删除是一个很低效的操作。
但是,在增量式iKd-Tree中,要删除一个节点,先是将这个“要删除”的节点标记为删除,被标记为删除的节点在“KNN近邻搜索”的时候会被 “跳过”,“树”的结构还是存在的,只有当iKd-Tree结构被“彻底重构”的时候,才会借机将这些节点从“tree结构”中删除。
Ø “树”结构平衡性
所谓的平衡性,就是“树”的左右两侧,当发生节点删除后,某一侧可能会大量的点被删除,因为删除某个节点,该节点的子节点可能也要被删除。
(1)方案一:当“树”的结构较小的时候,即使重构,也不会特别麻烦,时间可以忽略不计,直接将节点全部打散,删除“已经被标记的节点”,对剩下的节点执行传统“Kd-Tree”创建的操作;
(2)方案二:当“树”的结构很大的时候,就不能忽略重构的耗时,如果在主线程进行重构,那么就会导致iKd-Tree一直被占用,LIO/VIO系统不能访问“树”的查询与删除,算法阻塞;
因此,在方案二中,iKd-Tree设计了 “并行线程”的方案,即在开一个额外的线程,主线程已经对“树”进行删除、增减操作,如果要删除的节点正在“被另一个线程重构”,则将此节点缓存到OperationLogger的容器中;等到“额外的线程完成了重构”,再从OperationLogger的容器中拿出对应的节点来“补上”,从而保证每个节点都不会被落下。
5. 点云聚类
(代码lidar_slam_course/ch2/point_cluster)
把相似的放在一起
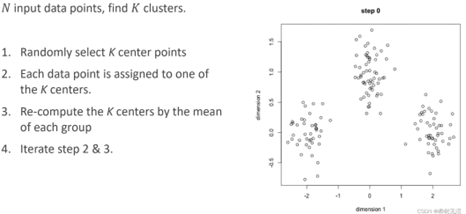
5.1 K-Means算法
1、人工给定K个类 2、每个点是哪一个类 3、更新中心点的位置 4、迭代直到算法收敛
算法收敛的条件: 1、中心点不再移动 2、所有点分配点不再变化
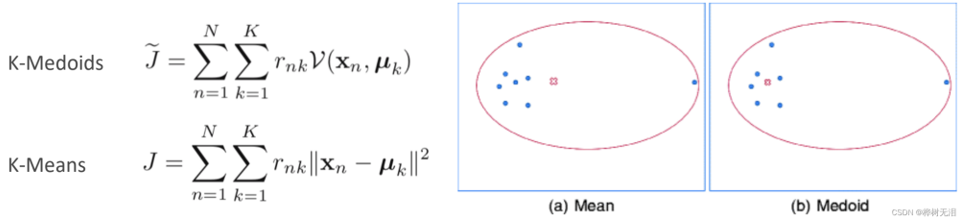
5.2 K-Medoids
K-means对于有噪声存在的点效果不好。K-Medoids不再选平均值,而是选择一个点使得所有点的距离和最小。
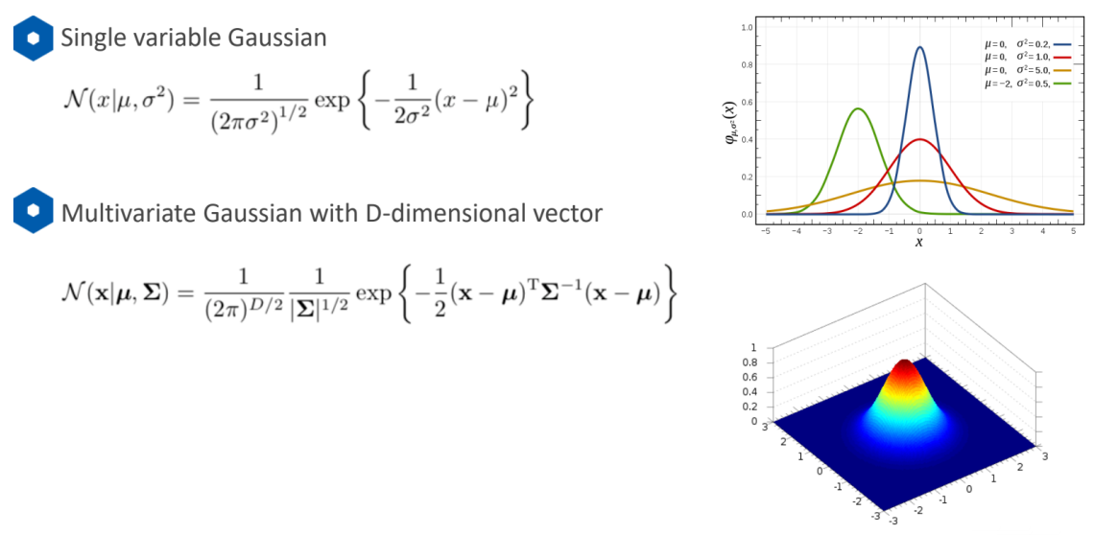
 5.3 高斯GMM模型
5.3 高斯GMM模型
用高斯模型来描绘每个类的,给出每个点是该类的概率n个高斯模型的线性组合
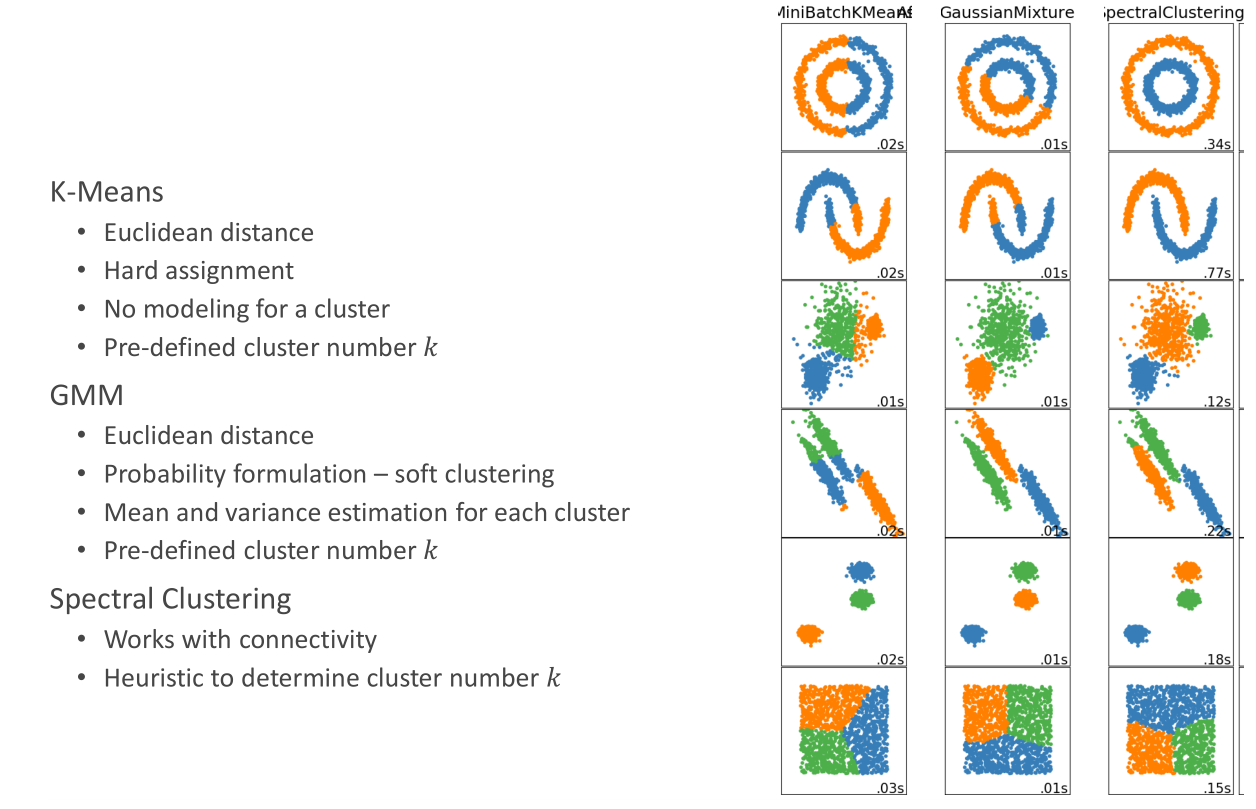
5.4 Spectral Clustering 谱聚类
之前的点是在欧式空间中聚类的,所以对于不规则的分布效果不好。谱聚类是根据点与点之间的连接性。利用点与点之间的关系建立相似度矩阵,求出其特征向量,利用每个点的特征向量进行K-Means聚类。计算点与点之间的相似度。
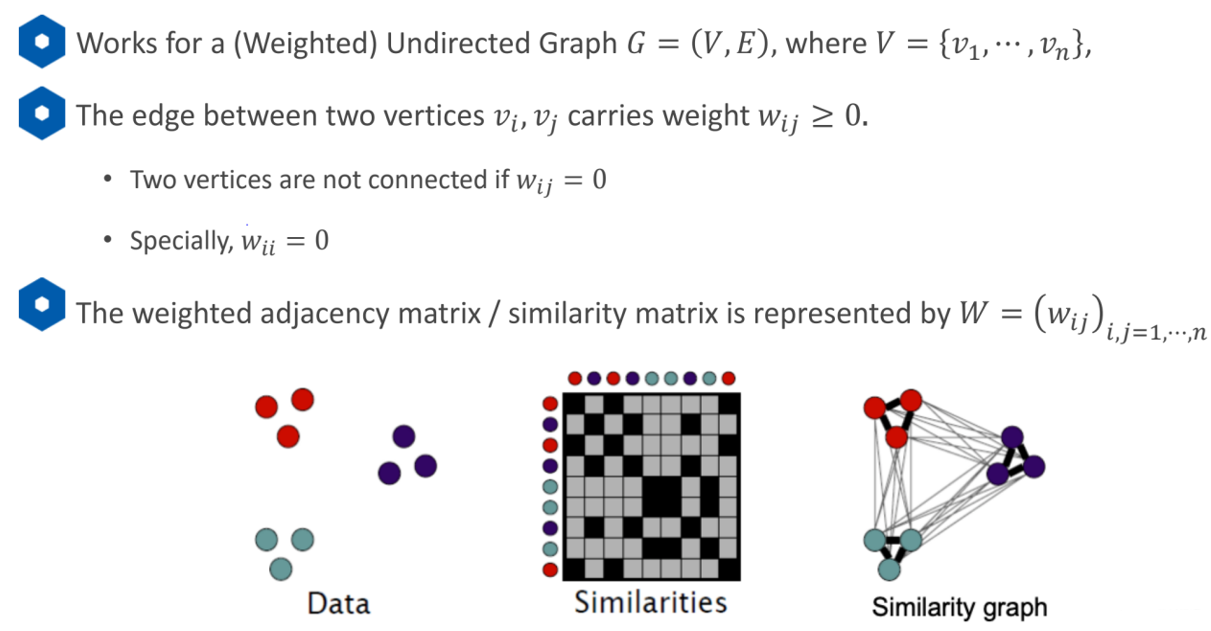
无向图矩阵建立方法:
1、每一个节点之间都有连线,相似度是根据距离
2、每个节点只选择与它距离相近的几个点连线KNN RNN
得到相似矩阵处理得到对角矩阵Degree matrixD,D矩阵对角线的值是所在那一行的和,意义是第i个节点,它所连接所有节点权重的和。
5.5 Mean Shift聚类
核心思想:一堆点,怎样让一个固定半径的圆尽可能的包含较多的点。将圆的中心随便放在一个位置坐标,计算所包含所有点的平均坐标,圆的中心再移动到平均坐标,再次计算包含所有点的平均坐标,如此重复,直到点中心坐标不再改变为止。 其结果并不是最优的。输入只需要设定圆的半径,并不需要设定多少类,自动去发现。(爬山思想)
 5.6 DBSCAN
5.6 DBSCAN
核心思想:水漫金山,基于点与点连接,只要能够连接到就是一类

6. 点云拟合
6.1 最小二乘法
最小二乘方法,即通过最小化误差的平方和寻找数据的最佳函数匹配,最小二乘得到的是针对所有数据的全局最优,但是并不是所有数据都是适合去拟合的。

6.2 RANSAC随机抽样一致算法
采用迭代的方式从一组包含离群(outlier或者错误数据)的被观测数据中估算出数学模型的参数,相比最小二乘方法,它融合了剔除不合格数据的思想,因此对于有部分错误数据的数据样本,能够更快更准的给出辨识结果。用于三维点云处理中的模型提取,比如直线、球、圆柱、平面等的拟合与分割。
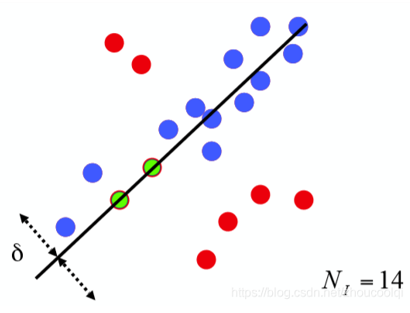
输入:
data —— 一组观测数据
model —— 适应于数据的模型
n —— 适用于模型的最少数据个数
k —— 算法的迭代次数
t —— 用于决定数据是否适应于模型的阀值
d —— 判定模型是否适用于数据集的数据数目
输出:
best_model —— 跟数据最匹配的模型参数
best_consensus_set —— 估计出模型的数据点
best_error —— 跟数据相关的估计出的模型错误
7. 点云特征点提取与描述
特征点的数量相比于原始点云或图像的数据量减小很多,与局部特征描述子结合在一起,组成特征点描述子常用来形成原始数据的表示,而且不失代表性和描述性,从而加快了后续的识别,追踪等对数据的处理了速度,特征点技术成为在2D和3D 信息处理中非常关键的技术。关键点检测往往需要和特征提取联合在一起,关键点检测的一个重要性质就是旋转不变性。
7.1 特征点提取
-
3DHarris
Harris 算法,其思想及数学推导大致如下:
1. 在图像中取一个窗 w (矩形窗,高斯窗,XX窗,各种窗)
2. 获得在该窗下的灰度 I
3.移动该窗,则灰度会发生变化,平坦区域灰度变化不大,
边缘区域沿边缘方向灰度变化剧烈,角点处各个方向灰度变化均剧烈
依据3中条件选出角点
① 两个特征值都很大==========>角点(两个响应方向)
② 一个特征值很大,一个很小=====>边缘(只有一个响应方向)
③ 两个特征值都小============>平原地区(响应都很微弱)
3DHarris利用方块体内点数量变化确定角点,想象一下,如果在 点云中存在一点p:
1、在p上建立一个局部坐标系:z方向是法线方向,x,y方向和z垂直。
2、在p上建立一个小正方体,不要太大,大概像材料力学分析应力那种就行
3、假设点云的密度是相同的,点云是一层蒙皮,不是实心的。
a、如果小正方体沿z方向移动,那小正方体里的点云数量应该不变。
b、如果小正方体位于边缘上,则沿边缘移动,点云数量几乎不变,沿垂直边缘方向移动,点云数量改。
c、如果小正方体位于角点上,则有两个方向都会大幅改变点云数量。
如果由法向量x,y,z构成协方差矩阵,那么它应该是一个对称矩阵,而且特征向量有一个方向是法线方向,另外两个方向和法线垂直。那么直接用协方差矩阵替换掉图像里的M矩阵,就得到了点云的Harris算法。其中,半径r可以用来控制角点的规模,r小则对应的角点越尖锐(对噪声更敏感),r大则可能在平缓的区域也检测出角点。
-
NARF
对点云而言,场景的边缘代表前景物体和背景物体的分界线。所以,点云的边缘又分为三种:前景边缘,背景边缘,阴影边缘。NARF(Normal Aligned Radial Feature)关键点是为了从深度图像中识别物体而提出的,关键点探测的重要一步是减少特征提取时的搜索空间,把重点放在重要的结构上。
对NARF关键点提取过程有以下要求:提取的过程必须将边缘以及物体表面变化信息考虑在内;关键点的位置必须稳定,可以被重复探测,即使换了不同视角;关键点所在的位置必须具有稳定的支持区域,可以计算描述子并进行唯一的法向量估计。该方法提取步骤如下:
1、遍历每个深度图像点,通过寻找在邻近区域有深度突变的位置进行边缘检测。
2、遍历每个深度图像点,根据邻近区域的表面变化决定一种测度表面变化的系数,以及变化的主方向。
3、根据第二步找到的主方向计算兴趣值,表征该方向与其它方向的不同,以及该处表面的变化情况,即该点有多稳定。
4、对兴趣值进行平滑滤波。
5、进行无最大值压缩找到最终的关键点,即为NARF关键点。
-
SIFT3D
在高斯金字塔上来计算DoG,在尺度和空间上搜索图像的局部极值。例如在图像一个像素点的四邻域内进行比较,判断是否是局部极值,如果是局部极值,则可能是关键点。
PCL类SIFTKeypoint是将二维图像中的 SIFT 算子调整后移植到 3D 空间的 SIFT算子的实现。输入为带有 XYZ 坐标值和强度的点云,输出为点云中的 SIFT 关键点。
7.2 特征点描述
-
PFH
PFH通过参数化查询点和紧邻点之间的空间差异,形成了一个多维直方图对点的近邻进行几何描述,直方图提供的信息对于点云具有平移旋转不变性,对采样密度和噪声点具有稳健性。PFH是基于点与其邻近之间的关系以及它们的估计法线,也即是它考虑估计法线之间的相互关系,来描述几何特征。为了计算两个点及其相关法线之间的偏差,在其中一个点上定义了一个固定坐标系。

两个点之间的坐标系转换,利用α,φ,θ,d,四个元素可以构成PFH描述子。
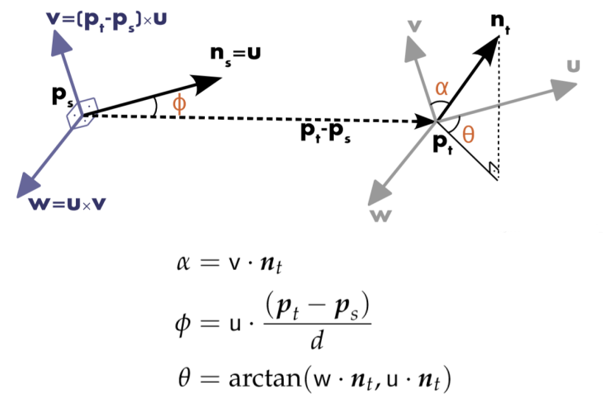
首先计算查询点Pq近邻内的对应的所有四个元素,如图所示,表示的是一个查询点(Pq) 的PFH计算的影响区域,Pq 用红色标注并放在圆球的中间位置,半径为r, (Pq)的所有k邻元素(即与点Pq的距离小于半径r的所有点)全部互相连接在一个网络中。最终的PFH描述子通过计算邻域内所有两点之间关系而得到的直方图。
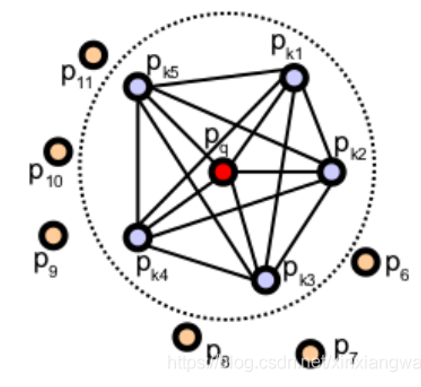
生成最终的对每个查询点的PFH代表,四要素这个集合将放到直方图里面。分发的过程是把所有的特征(上面的3个角度,一个距离的平方)平均分割成b小份,然后数每个子区间上的个数。因为有3个特征是法线间的角度,所以他们可以很好的归一化并把它们放到三角函数的圆(高中知识)里面。一个分发的案例是把每个特征区间进行平均分配,然后我们就有了一个有b的四次方分发的柱状图。在这个图里面有一个区间的值不为0代表着,它这个特征有一定的值。下面的这幅图展示了一个点云里面不同点的PFH图。
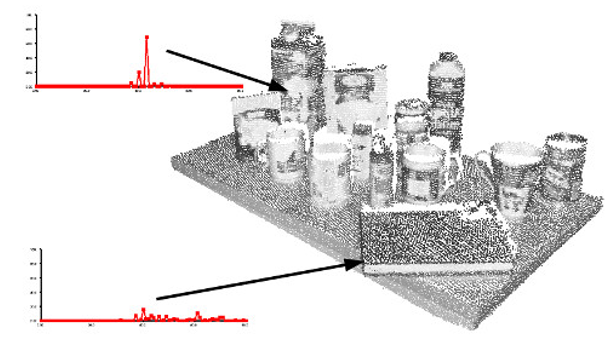
-
SPFH
只计算每个查询点Pq和它邻域点之间的三个特征元素(参考PFH),在这里不同于PFH:PFH是计算邻域点所有组合的特征元素,而这一步只计算查询点和近邻点之间的特征元素。如下图,第一个图是PFH计算特征过程,即邻域点所有组合的特征值(图中所有连线,包括但不限于Pq和Pk之间的连线),第二个图是step1中计算内容,只需要计算Pq(查询点)和紧邻点(图2中红线部分)之间的特征元素。可以看出降低了复杂度我们称之为SPFH(simple point feature histograms)
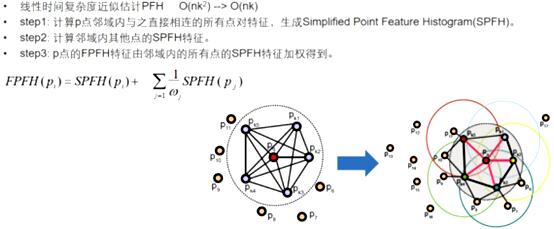
-
基于坐标系Signature based
SHOT:首先将点邻域空间分成几个子空间,然后对子空间中每个点的法向特征统计到直方图进行编 码,再将每个子空间的直方图联合到一起得到三维描述子。此方法对于含有噪声、杂波的点云以及密度不均的点云都具有一定的鲁棒性、高效性和较好的描述性。
1. 建立坐标系LRF
2. 将特征点周围空间分成32块
3. 计算每个小空间的直方图,每个直方图长度是11
8. 点云匹配
8.1 ICP基于距离
ICP通过迭代的方式,通过优化相对位姿,不断减小两帧点云之间点到点的距离,直到迭代收敛,最终计算出两帧点云的相对位姿。首先找到两组点云之间的对应问题,在ICP里面找最邻近的点,强行得到R,t,点一开始显然是不对的,但这是一个迭代的过程,直到R,t变化很小。可以用IMU来得到初始化的R,t。

ICP改进:
① 减少点
不用所有的点做ICP
对点云下采样
Normal Space Sampling(NSS)
② 数据关联
最邻近搜寻
Normal shooting:适用与平滑的点云
Projection
Feature descriptor matching
③ 去除噪点
去除远距离
去除不匹配的点
④ Loss function
Point-to-point
point-to-plane
点到最邻近点平面的距离,point-to-point可能会强行对应点,point-to-plane收敛更快。LOAM
点云ICP算法的优点包括:
- 算法简单易懂,易于实现和理解;
- 对于初始位姿估计较为准确的情况下,配准精度较高。
点云ICP算法的缺点包括:
- 对于大规模点云数据,算法的时间和空间复杂度较高,难以实现实时处理;
- 对于初始位姿估计不准确或存在环路等情况时,算法易受局部极小值的影响,可能导致配准失败或者配准精度较低。
8.2 NDT基于概率
NDT是将参考点云转换成多维变量的正态分布来进行配准。以一个格子一个格子为单位,找点落在哪个格子,格子里面的信息是一个高斯模型来描述点云的分布。

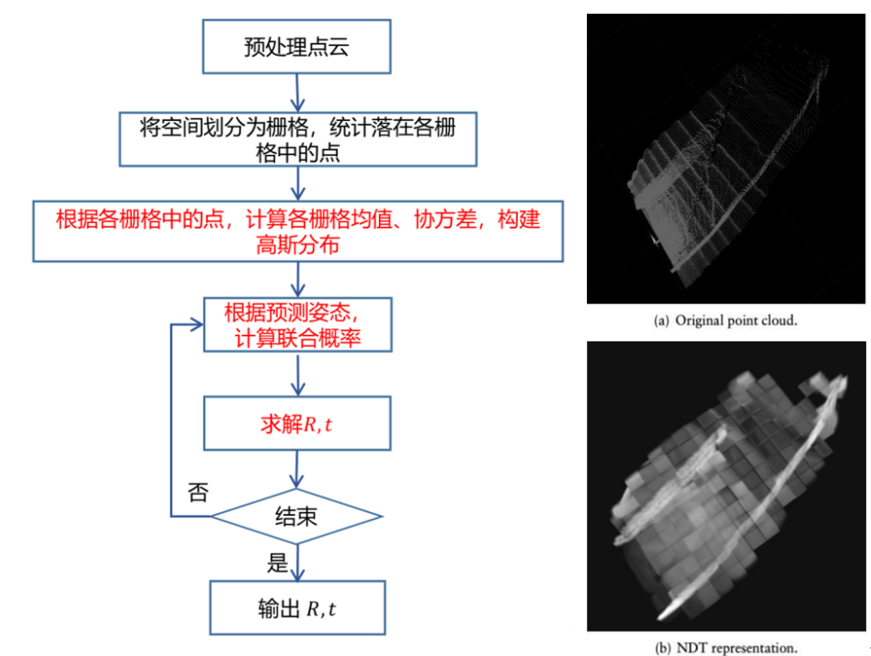
NDT缺点:格子参数最重要,太大导致精度不高,太小导致内存过高,并且只有两幅图像相差不大的情况才能匹配。
改进:
① 八叉树建立,格子有大有小 ,迭代,每次使用更精细的格子
② K聚类,有多少个类就有多少个cell,格子大小不一
③ 三线插值 平滑相邻的格子cell导致的不连续,提高精度
NDT算法的优点包括:
- 算法不受初始位姿的影响,配准精度较高;
- 对于大规模点云数据,算法的时间和空间复杂度较低,适合实现实时处理。
NDT算法的缺点包括:
- 对于运动过程中,点云数据的变形和变化较大的情况下,算法的配准精度较低;
- 算法对点云数据的密度和分布有一定的要求,需要较为均匀和连续的点云数据才能达到较好的配准效果。
用PCL库实现点云基础操作的代码在我之前的博客中
C++点云PCL基础ROS代码_c++可以直接替换pcl::pointxyz_桦树无泪的博客-CSDN博客
现在,你应该对点云这一数据类型有了充足的认识,下一次将讲述一些SLAM中的数学概念




![【数据结构】[LeetCode138. 复制带随机指针的链表]](https://img-blog.csdnimg.cn/760f1822da91496181f99aad6f0b98f0.png)