文章目录
- 一、什么是正则表达式
- 二、正则表达式的使用
一、什么是正则表达式
正则表达式是由普通字符与元字符组成:
-
普通字符 包括大小写字母、数字、标点符号及一些其他符号。
-
元字符 是指在正则表达式中具有特殊意义的专用字符,可以用来规定其前导字符(即位于元字符前面的字符或表达式)在目标对象中的出现模式。
二、正则表达式的使用
适合awk,sed,grep,egrep等文本工具使用
常用选项:
| 选项 | 作用 |
|---|---|
| \ | 转义字符,用于取消特殊符号的含义,如:\!、\n、\$ |
| ^ | 匹配字符串开始的位置,如:^a、^the、^#、^[a-z] |
| $ | 匹配字符串结束的位置,如:word$、^$匹配空行 |
| . | 匹配除\n之外的任意的一个字符,如:go.d、g…d |
| * | 匹配前面子表达式0次或多次,如:goo*d、go.*d |
| [list] | 匹配list列表中的一个字符(列表中只要有一个符合即可) |
| [^list] | 匹配任意非list列表中的一个字符 |
| \ {n\ } | 匹配前面的子表达式n次 |
| \ {n,\ } | 匹配前面的子表达式不少于n次 |
| \ {n,m\ } | 匹配前面的子表达式n到m次(m必须大于n,不然会报错) |
注意:egrep、 awk使用{n}、{n,}、{n, m}匹配时 “{ }” 前不用加" \ "
| 选项 | 作用 |
|---|---|
| \n | 拥有换行的作用 |
| \t | 转化为制表符(能让输出结果呈现表格的格式) |
| \w(小写) | 匹配包括下划线的任何单词字符 |
| \W(大写) | 匹配任何非单词字符。等通于"[^A-Za-z0-9_]" |
| \r | 转换后是回车符 |
| \d | 匹配一个数字字符 |
| \D | 匹配一个非数字字符。等价于[^0-9] |
| \s(小写) | 空白符 |
| \S(大写) | 非空白符 |
扩展正则表达式元字符:(支持的工具:egrep、awk)
+:匹配前面子表达式1次以上,如:go+d,将至少匹配一个o,god、good、goood
?:匹配前面子表达式0次或1次,如:go?d将匹配gd、god
():将括号中的字符串作为一个整体,如:g(oo)+d,将匹配oo整体1次以上,如good、goood等
|:以或的方式匹配字符串,如:g(oo|al)d,将匹配good或gald
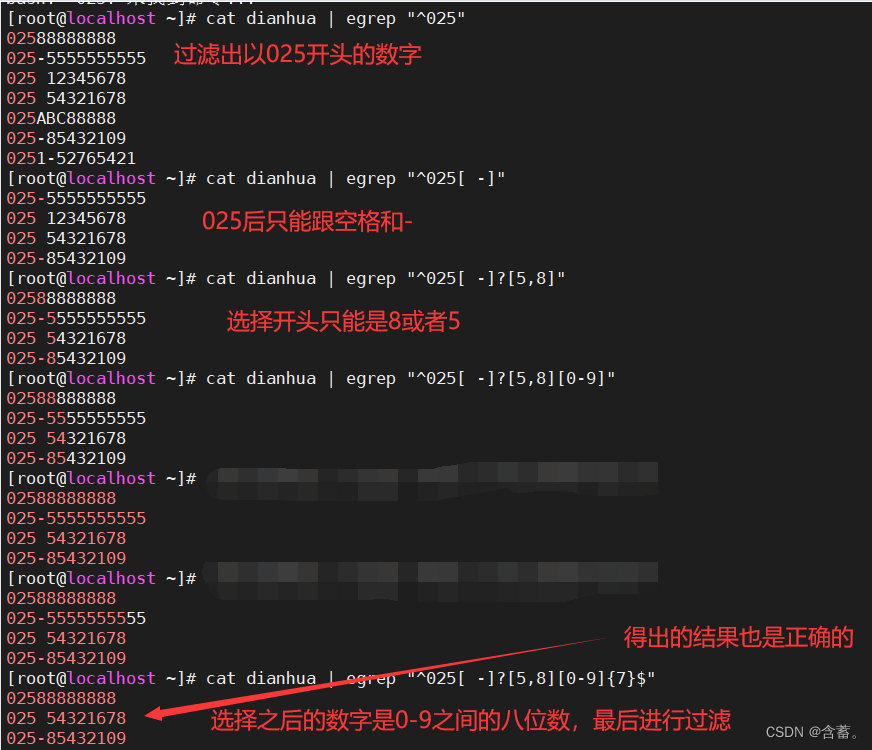
示例一:
区号025开头,号码与区号间可以是空格、-、没有,号码必须是5或者8开头的八位数
示例二:
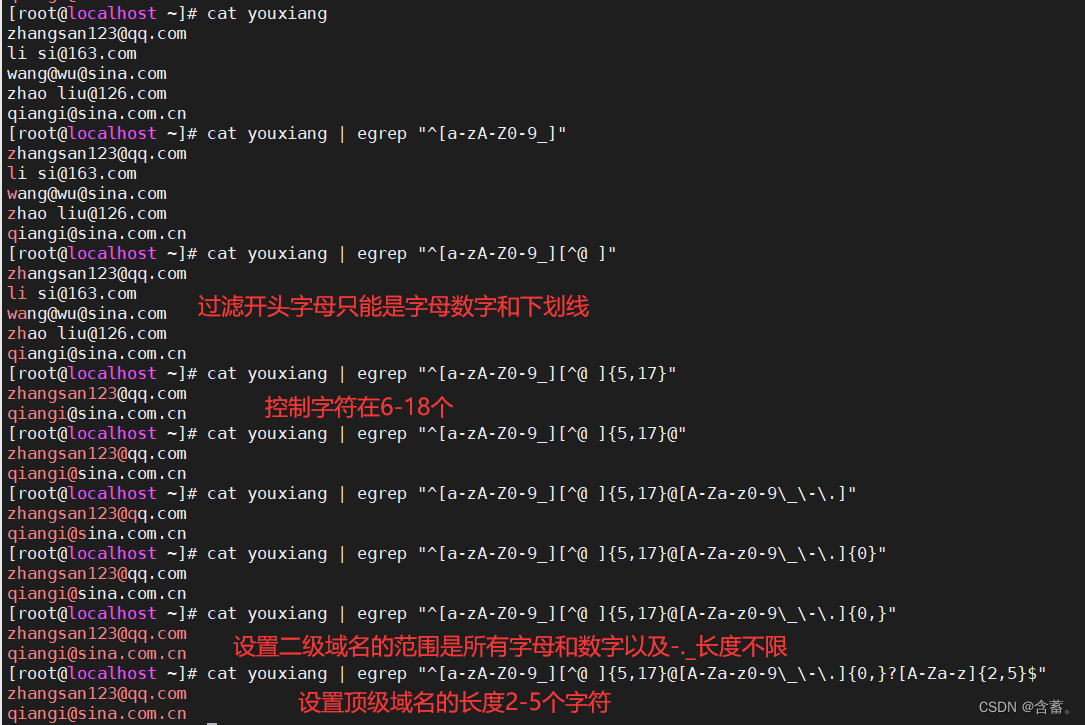
正则表达式匹配E-mail地址




![基于.NET实现的家电维修保养信息系统[含文档+PPT+源码等]精品](https://img-blog.csdnimg.cn/img_convert/aa44cf5dd296e9053e96f10d9c8cfe88.png)