什么是Flow
Flow直译过来就是“流”的意思,也就是将我们我们任务如同水流一样一步一步分割做处理。想象一下,现在有一个任务需要从山里取水来用你需要怎么做?
- 扛上扁担走几十里山路把水挑回来。简单粗暴,但是有可能当你走了几十里路发现水干涸了,你就白跑一趟。
- 架设一条从家到水源之间的水管,以后就可以在家打开水管就有水喝了。如果打开水龙头没水了,那就知道水池没水了,也不用白跑一趟。
这其实就延伸到了目前的两种主流编程思想,响应式和非响应式。
所谓的响应式就是通过订阅、监听的方式等待数据源把数据传递过来。他的优势是可以很方便的与数据源逻辑解耦,并且在数据源可以传递过来之前随意的改变数据流。比如上边例子,我想喝柠檬味的水,那我完全可以在我水龙头上接个柠檬味的管子。而像传统的方案就必须要往水源地加入柠檬精,这时候如果另一个人他想喝西瓜味的水,那就实现不了了。
为什么是Flow
在Flow之前,RXjava一直是我们常用的流式写法,那相比较RXjava,Flow的优势是什么呢?ChatGpt认为有以下几点:
- 更加轻量级:Flow 是 Kotlin 标准库的一部分,无需引入额外的依赖库,而 RxJava 需要引入 RxJava 核心库和相关的操作符库,增加了项目的复杂度和体积。
- 更加简单:Flow 基于 Kotlin 协程实现,使用协程的语法糖可以实现代码更加简单和易读,比 RxJava 更加简单。
- 更加灵活:Flow 支持背压处理和多个订阅者同时订阅同一个数据流,而 RxJava 对于多个订阅者需要使用
share()或replay()等操作符进行处理。 - 更加安全:Flow 可以在协程的上下文中运行,因此可以避免 RxJava 中常见的线程安全问题和内存泄漏问题。
- 更加可预测:Flow 使用 Kotlin 的类型安全特性,可以更加容易地避免类型不匹配和空指针异常等问题。
其实作为开发人员最关心的就是简洁。越简洁的用法意味着越低廉的学习成本,也更不容易使用出错出现不可以预知的问题。
传统方案、RXjava、Flow直观对比
我们以一个最常用的例子,子线程网络请求,然后再将数据返回主线程加载UI
传统方案
OkHttpUtils.sendGetRequest("http://example.com", new OkHttpUtils.CallbackListener() {
@Override
public void onSuccess(String response) {
// 在主线程中处理请求成功的结果
textView.setText(response);
}
@Override
public void onFailure(IOException e) {
// 在主线程中处理请求失败的结果
e.printStackTrace();
Toast.makeText(MainActivity.this, "请求失败", Toast.LENGTH_SHORT).show();
}
});
发起一个网络请求并注册一个监听,当请求结果回来的时候把结果callback回来。如果此时我们需要网络请求成功之后再去请求第二个接口回来,那我们就需要再嵌套一个callback,就像这样:
OkHttpUtils.sendGetRequest("http://example.com", new OkHttpUtils.CallbackListener() {
@Override
public void onSuccess(String response) {
// 在主线程中处理请求成功的结果
OkHttpUtils.sendGetRequest("http://example2.com", new OkHttpUtils.CallbackListener() {
@Override
public void onSuccess(String response) {
// 在主线程中处理请求成功的结果
textView.setText(response);
}
@Override
public void onFailure(IOException e) {
// 在主线程中处理请求失败的结果
e.printStackTrace();
Toast.makeText(MainActivity.this, "请求失败", Toast.LENGTH_SHORT).show();
}
});
}
@Override
public void onFailure(IOException e) {
// 在主线程中处理请求失败的结果
e.printStackTrace();
Toast.makeText(MainActivity.this, "请求失败", Toast.LENGTH_SHORT).show();
}
});
可以看到,当两层的时候我们就完全陷入了“回调地狱”中,逻辑越来越难直观看清。更为致命的是这个方法也无法扩展了。比如说另一个使用者要在第一次请求成功之后弹出一个气泡,第二个使用者说我不需要。这样就只能加参数写if-else判断了。长此以往这个方法就会迅速膨胀再也无法复用,紧接着这个方法的CV1.0、2.0版本就开始“闪亮登场”,最后这个类也无法继续维护了。
RXjava方案
RxJavaUtils.sendGetRequest("http://example.com")
.subscribe(new Observer<String>() {
@Override
public void onSubscribe(Disposable d) {
// 在这里可以做一些准备工作,比如显示进度条等
}
@Override
public void onNext(String response) {
// 在主线程中处理请求成功的结果
textView.setText(response);
}
@Override
public void onError(Throwable e) {
// 在主线程中处理请求失败的结果
e.printStackTrace();
Toast.makeText(MainActivity.this, "请求失败", Toast.LENGTH_SHORT
});
这样的写法相比较传统写法确实优雅了一些,当有多个请求操作的时候可以使用 flatMap 或 concatMap 操作符来实现在一个请求成功之后继续发起另一个请求的功能,就像这样:
RxJavaUtils.sendGetRequest("http://example.com")
.flatMap(response -> RxJavaUtils.sendGetRequest("http://example2.com"))
.subscribe(new Observer<String>() {
@Override
public void onSubscribe(Disposable d) {
// 在这里可以做一些准备工作,比如显示进度条等
}
@Override
public void onNext(String response) {
// 在主线程中处理请求成功的结果
textView.setText(response);
}
@Override
public void onError(Throwable e) {
// 在主线程中处理请求失败的结果
e.printStackTrace();
Toast.makeText(MainActivity.this, "请求失败", Toast.LENGTH_SHORT).show();
}
@Override
public void onComplete() {
// 在请求完成时进行一些收尾工作,比如隐藏进度条等
}
});
这样看起来我们很好的规避了‘回调地狱’的问题,逻辑看起来也非常的清晰。当其他使用者需要扩展这个方法的时候,只需要拿着原始的sendGetRequest方法自己通过rx操作符拼接自己的业务逻辑就可以了。
Flow方案
lifecycleScope.launch {
FlowUtils.sendGetRequest("http://example.com")
.collect { response ->
// 在主线程中处理请求结果
textView.text = response
}
}
就是这么简单,对于Flow的创建也是比较简单的,使用flow函数一包装,我们就得到了任务流。
import android.util.Log
import kotlinx.coroutines.Dispatchers
import kotlinx.coroutines.flow.Flow
import kotlinx.coroutines.flow.flow
import kotlinx.coroutines.flow.flowOn
import okhttp3.Call
import okhttp3.Callback
import okhttp3.OkHttpClient
import okhttp3.Request
import okhttp3.Response
import java.io.IOException
object FlowUtils {
private const val TAG = "FlowUtils"
private val client = OkHttpClient()
fun sendGetRequest(url: String): Flow<String> = flow {
val request = Request.Builder()
.url(url)
.build()
val call = client.newCall(request)
call.enqueue(object : Callback {
override fun onFailure(call: Call, e: IOException) {
Log.e(TAG, "Request failed: ${e.message}")
// 使用 Flow 的 emit 方法将异常抛出
emit(e.message ?: "Unknown error")
}
override fun onResponse(call: Call, response: Response) {
val responseBody = response.body()?.string()
if (response.isSuccessful && responseBody != null) {
// 使用 Flow 的 emit 方法将请求成功的结果抛出
emit(responseBody)
} else {
val errorMessage = response.message()
Log.e(TAG, "Request failed: $errorMessage")
// 使用 Flow 的 emit 方法将异常抛出
emit(errorMessage)
}
}
})
}.flowOn(Dispatchers.IO)
}
而将两个flow任务拼接起来也是极为简单的
lifecycleScope.launch {
FlowUtils.sendGetRequest("http://example.com")
.flatMapConcat { response ->
// 在请求1的结果基础上发起请求2
FlowUtils.sendGetRequest("http://example2.com")
}
.collect { response ->
// 在主线程中处理请求2的结果
textView.text = response
}
}
可以看到除去我们所说的操作符的学习成本,flow在kotlin语法糖的加持下写法更简洁直观。
Flow学习
与RXJava一样,Flow也可以分为三大块部分。
- Flow的创建,即创建我们的数据源,我们可以通过
flow函数或者其他语法糖开启一个Flow流。 - 中间操作符,像
flatMapConcat、map这些操作符,中间改变数据流向。 - 终止操作符,用来最终接收数据。当执行最终操作符的时候,Flow流就不能再被改变,只能得到结果。
Flow创建
-
通过 Flow 构造器创建
kotlinCopy code val flow = flow { // 在这里定义 Flow 的发射过程 emit(1) emit(2) emit(3) } -
通过集合转换成 Flow
kotlinCopy code val flow = listOf(1, 2, 3).asFlow() -
通过数组转换成 Flow
kotlinCopy code val flow = arrayOf(1, 2, 3).asFlow() -
通过流转换成 Flow
kotlinCopy code val flow = inputStream.bufferedReader().lineSequence().asFlow() -
通过 channelFlow 构建
kotlinCopy code val flow = channelFlow { // 在这里定义 Flow 的发射过程 send(1) send(2) send(3) } -
通过 transform 操作符变换一个 Flow
kotlinCopy code val flow = flowOf(1, 2, 3) .transform { value -> emit(value * 2) } -
通过其他操作符变换一个 Flow
kotlinCopy code val flow = flowOf(1, 2, 3) .map { it * 2 } -
通过 suspendCancellableCoroutine 构建
kotlinCopy code val flow = flow { val data = suspendCancellableCoroutine<String> { continuation -> // 这里是协程挂起等待数据的逻辑 } emit(data) }
中间操作符
map: 将 Flow 中的每个元素转换为另一个元素。filter: 根据指定的谓词过滤 Flow 中的元素。take: 从 Flow 中获取指定数量的元素。drop: 从 Flow 中删除指定数量的元素。flatMap: 将 Flow 中的每个元素转换为另一个 Flow,并将所有结果合并为一个 Flow。zip: 将两个 Flow 中的元素按顺序配对并生成新元素。reduce: 将 Flow 中的所有元素缩减为一个单独的元素。scan: 将 Flow 中的所有元素累积为一个可变状态,并发出每个中间状态。distinctUntilChanged: 仅在 Flow 中出现与上一个不同的元素时才发出元素。buffer: 将 Flow 的元素缓存在内存中,以便在上游产生元素速度很快时缓解下游的压力。onEach: 对 Flow 中的每个元素执行指定操作,而不会修改元素。catch: 处理 Flow 中的错误并将其替换为另一个值或另一个 Flow。
终止操作符
collect():收集Flow流发射的值,并将其处理,直到Flow结束或被取消。toList():将Flow流发射的所有值存储在List集合中,然后返回该集合。toSet():将Flow流发射的所有值存储在Set集合中,然后返回该集合。reduce():将Flow流发射的值进行累加或其他操作,返回一个最终的结果。fold():与reduce()类似,但是可以提供一个初始值,用于指定操作的起始值。first():返回Flow流发射的第一个值。last():返回Flow流发射的最后一个值。single():返回Flow流发射的单个值,如果Flow流中没有值或有多个值则会抛出异常。firstOrNull():返回Flow流发射的第一个值,如果没有值则返回null。lastOrNull():返回Flow流发射的最后一个值,如果没有值则返回null。
Flow背压处理
与RXJava一样,Flow也会遇到背压问题(任何生产者消费者模型都会有这个问题)。Flow提供了专门处理背压的操作符:
- buffer 操作符:可以设置一个缓冲区,使生产者和消费者的处理速度可以有一定的错开,从而避免数据积压。例如:
flow.buffer().collect{...}。 - conflate 操作符:可以丢弃掉生产者发送的部分数据,只保留最新的数据,这样可以保证消费者始终处理最新的数据,避免处理过多的数据。例如:
flow.conflate().collect{...}。
buffer操作符可以设置缓存的大小,比如buffer(2)标识最多缓存两个元素。
我们还可以设置BufferOverflow来约定超过缓存区后的处理逻辑。比如: val channel = producer.buffer(Channel.BUFFERED, onBufferOverflow = BufferOverflow.SUSPEND)
BufferOverflow 背压策略
- SUSPEND,默认策略,填满后再来的数据流,发送会被挂起,若 bufferSize <= 0,此策略不可更改。
- DROP_OLDEST,丢弃最旧的值。
- DROP_LATEST,丢弃最新的值。
Flow原理
我们从一个简单的demo开始
fun test() {
runBlocking(Dispatchers.Main) {
//生产者
flow {
println("flow block")
//发射数据
emit(1)
emit(2)
}.flowOn(Dispatchers.IO).collect {
//消费者
println("collect block $it")
}
}
}
以上代码涉及到三个关键函数(flow、emit、collect),两个闭包(flow闭包、collect闭包。
从上面的调用图可知,以上五者的调用关系:
flow–>collect–>flow闭包–>emit–>collect闭包
接下来我们逐步分析。
flow()
flow函数实现:
public fun <T> flow(@BuilderInference block: suspend FlowCollector<T>.() -> Unit): Flow<T> = SafeFlow(block)
别看这个函数只有一行,其实他所声明的东西还不少。
- 首先flow()接受一个block参数,这个参数就是我们demo里的flow闭包。
- 其次这个参数的类型是
FlowCollector<T>.() -> Unit,表明他是FlowCollector的一个扩展。 - 同时这个函数又声明了suspend,也就是说flow闭包是一个挂起函数。
- 最后这个函数的实际逻辑是返回了一个SafeFlow(),我们的flow闭包作为参数。返回类型是Flow。
我们再看SafeFlow的实现:
private class SafeFlow<T>(private val block: suspend FlowCollector<T>.() -> Unit) : AbstractFlow<T>() {
override suspend fun collectSafely(collector: FlowCollector<T>) {
collector.block()
}
}
SafeFlow的父类就是AbstractFlow,这个block参数就是我们上边所说的flow闭包。他重写了collectSafely()方法,这个方法里调用了collector.block()。
collector.block()实际在调用谁?实际调用的是参数里的block,也就是flow闭包的执行。
可以看到flow函数主要作用就是构建flow流,并没有实际启动这个流任务。而实际启动任务流是在调用collect()方法的时候,也就是实际消费的时候。这也就是所谓的冷流。
collect()
我们还是先看源码定义
public interface Flow<out T> {
public suspend fun collect(collector: FlowCollector<T>)
}
点击demo的collect()方法就进入这里,可以看到Flow其实是一个接口,只有一个方法collect,接收FlowCollector参数。这里的collector就是我们外部传来的collect闭包。
上边我们讲到fllow()方法最终返回的是SafeFlow对象,而SafeFlow的父类就是AbstractFlow。所以我们接着看AbstractFlow的collect方法。
public abstract class AbstractFlow<T> : Flow<T>, CancellableFlow<T> {
public final override suspend fun collect(collector: FlowCollector<T>) {
val safeCollector = SafeCollector(collector, coroutineContext)
try {
collectSafely(safeCollector)
} finally {
safeCollector.releaseIntercepted()
}
}
public abstract suspend fun collectSafely(collector: FlowCollector<T>)
}
}
可以看到我们传递的collector闭包最终又被包装成了SafeCollector,然后调用抽象函数collectSafely。而collectSafely的具体实现则是由子类实现。而AbstractFlow子类又是谁?是SafeFlow。所以最终又走到了SafeFlow的collectSafely方法,而collectSafely方法又触发了flow闭包的执行。此时,消费者通过collect函数已经调用到生产者的闭包里
emit()
上边我们提到Flow在调用collect方法的时候就触发了flow闭包的执行,而在flow闭包怎么把数据传递给collect闭包的呢?对就是通过emit()方法。我们看下emit()方法的实现。
public fun interface FlowCollector<in T> {
public suspend fun emit(value: T)
}
可以看到又是一个接口FlowCollector。在上边我们分析flow方法的时候看到,flow方法将flow闭包转换为FlowCollector的扩展方法。所以FlowCollector可以理解为我们flow闭包。他有一个emit方法,这也就是为什么我们在flow闭包里可以直接调用emit的原因。
那这个接口具体实现是谁呢?我们上边看AbstractFlow源码的时候提到,flow闭包被包装成了SafeCollector,然后调用collectSafely。在collectSafely最终触发了flow闭包的执行。而flow闭包实现了emit接口。所以最终触发emit的就是SafeCollector。
override suspend fun emit(value: T) {
return suspendCoroutineUninterceptedOrReturn sc@{ uCont ->
try {
emit(uCont, value)
} catch (e: Throwable) {
lastEmissionContext = DownstreamExceptionContext(e, uCont.context)
throw e
}
}
}
private fun emit(uCont: Continuation<Unit>, value: T): Any? {
val currentContext = uCont.context
currentContext.ensureActive()
val previousContext = lastEmissionContext
if (previousContext !== currentContext) {
checkContext(currentContext, previousContext, value)
lastEmissionContext = currentContext
}
completion = uCont
val result = emitFun(collector as FlowCollector<Any?>, value, this as Continuation<Unit>)
if (result != COROUTINE_SUSPENDED) {
completion = null
}
return result
}
private val emitFun = FlowCollector<Any?>::emit as Function3<FlowCollector<Any?>, Any?, Continuation<Unit>, Any?>
这样在flow闭包里调用emit函数后,将会调用到collect的闭包里,此时数据从flow的上游流转到下游。
有同学就问了private val emitFun = FlowCollector<Any?>::emit as Function3<FlowCollector<Any?>, Any?, Continuation<Unit>, Any?>就这么一行,怎么理解说调到collect的闭包里的?
说实话刚开始我也不懂,不得不说kotlin的高阶语法真是太难理解了。不过我们换种思路来,通过kotlin转java看下这行代码转换后的样子。
private static final Function3 emitFun = (Function3)TypeIntrinsics.beforeCheckcastToFunctionOfArity(new Function3() {
// $FF: synthetic method
// $FF: bridge method
public Object invoke(Object var1, Object var2, Object var3) {
return this.invoke((FlowCollector)var1, var2, (Continuation)var3);
}
@Nullable
public final Object invoke(@NotNull FlowCollector p1, @Nullable Object p2, @NotNull Continuation continuation) {
return p1.emit(p2, continuation);
}
}, 3);
这下就简单明了了吧?p1对应的是就是我们的collector,那这个collector又是什么鬼?他是SafeCollector类的参数。
internal actual class SafeCollector<T> actual constructor(@JvmField internal actual val collector: FlowCollector<T>,@JvmField internal actual val collectContext: CoroutineContext ) : FlowCollector<T>, ContinuationImpl(NoOpContinuation, EmptyCoroutineContext), CoroutineStackFrame{
····
}
而我们往上翻SafeCollector的collector参数不就是AbstractFlow类中collect方法传递进去的collect闭包吗?
中间操作符
最后我们来研究下Flow中间操作符是怎么运作的,我们还是以最关心的flowOn线程切换操作符来说明吧。点进flowOn的源码看下:
public fun <T> Flow<T>.flowOn(context: CoroutineContext): Flow<T> {
checkFlowContext(context)
return when {
context == EmptyCoroutineContext -> this
this is FusibleFlow -> fuse(context = context)
else -> ChannelFlowOperatorImpl(this, context = context)
}
}
看方法签名,又是给Flow类扩展了一个flowOn方法,最终又返回了一个Flow类。所以可以猜想这个方法其实是做了一层包装。在这里我们的demo逻辑走ChannelFlowOperatorImpl这个分支(为啥?打断点啊!)。
internal class ChannelFlowOperatorImpl<T>(flow: Flow<T>,context: CoroutineContext = EmptyCoroutineContext,capacity: Int =Channel.OPTIONAL_CHANNEL,onBufferOverflow: BufferOverflow = BufferOverflow.SUSPEND ) : ChannelFlowOperator<T, T>(flow, context, capacity, onBufferOverflow) {
override fun create(context: CoroutineContext, capacity: Int,onBufferOverflow: BufferOverflow): ChannelFlow<T> = ChannelFlowOperatorImpl(flow, context, capacity, onBufferOverflow)
override fun dropChannelOperators(): Flow<T>? = flow
override suspend fun flowCollect(collector: FlowCollector<T>) = flow.collect(collector)
}
- 首先ChannelFlowOperatorImpl的父类实现了Flow接口,所以我们可以认为这里就是flow闭包。
- 其次create方法创建了ChannelFlowOperatorImpl实体对象。flowCollect方法里最终调用了flow.collect(collector)。也就是我们上边分析的触发消费者执行。
- 所以我们得出结论,中间操作符其实也是一个小的Flow流,有生产者、消费者。生产者就是上一级传来的流,消费者就是自己。将流改变之后再调用原来的消费者,就是拦截器的原理。
那flowOn的实际处理逻辑在哪呢?上边我们分析了Flow类只有一个collect函数。所以我们找父类看collect函数的实现就行了。
private suspend fun collectWithContextUndispatched(collector: FlowCollector<T>, newContext: CoroutineContext) {
val originalContextCollector = collector.withUndispatchedContextCollector(coroutineContext)
// invoke flowCollect(originalContextCollector) in the newContext
return withContextUndispatched(newContext, block = { flowCollect(it) }, value = originalContextCollector)
}
// Slow path when output channel is required
protected override suspend fun collectTo(scope: ProducerScope<T>) = flowCollect(SendingCollector(scope))
// Optimizations for fast-path when channel creation is optional
override suspend fun collect(collector: FlowCollector<T>) {
// Fast-path: When channel creation is optional (flowOn/flowWith operators without buffer)
if (capacity == Channel.OPTIONAL_CHANNEL) {
val collectContext = coroutineContext
val newContext = collectContext + context // compute resulting collect context
// #1: 上下文相同 直接调用flowCollect,就是上边看到的子类,也就是执行下一步流转。
if (newContext == collectContext)
return flowCollect(collector)
// #2: 检验上下文拦截器是否相同,如果相同就走不用分发的逻辑。
if (newContext[ContinuationInterceptor] == collectContext[ContinuationInterceptor])
return collectWithContextUndispatched(collector, newContext)
}
// 最终都不相同走了父类处理。
super.collect(collector)
}
我们这里没有设置拦截器,只是修改了线程。所以肯定走collectWithContextUndispatched逻辑。
internal suspend fun <T, V> withContextUndispatched(
newContext: CoroutineContext, value: V, countOrElement: Any = threadContextElements(newContext), block: suspend (V) -> T ): T =
suspendCoroutineUninterceptedOrReturn { uCont ->
//瞅这个,是不是很亲切?
withCoroutineContext(newContext, countOrElement) { block.startCoroutineUninterceptedOrReturn(value,StackFrameContinuation(uCont,newContext))
}
}
看到withCoroutineContext这个方法我们就明白了
总结
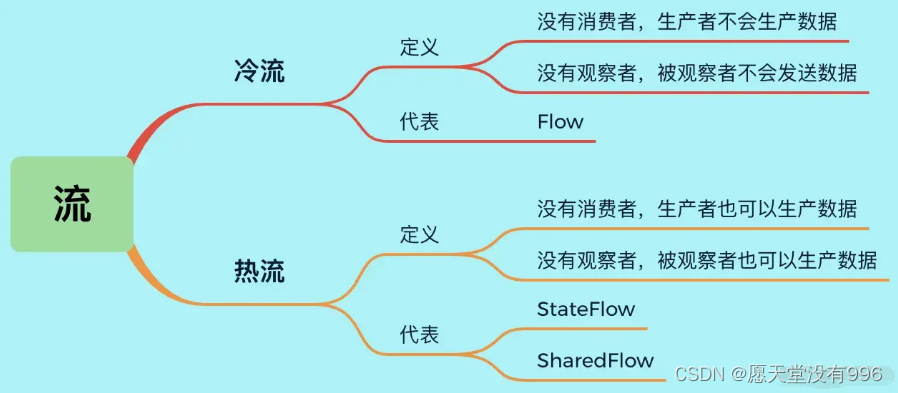
- 什么是冷流?什么是热流?
- 冷流:没有消费者,生产者不会生产数据 没有观察者,被观察者不会发送数据
- 热流:没有消费者,生产者也会生产数据 没有观察者,被观察者也会发送数据
- Flow是怎么流转的?
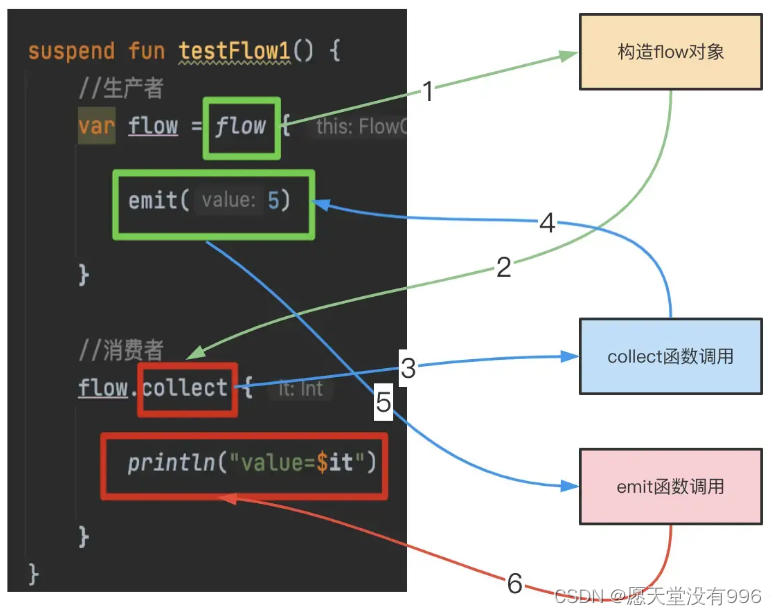
直接搬大佬的图。 - Flow中间操作符是怎么做转换的?
- 本质也是一个小的Flow流,在collect逻辑中终止上一步的流转,插入自己的逻辑,然后调用下一步流转
- Flow相比较RXJava有什么优势?
- 更加轻量级:Flow 是 Kotlin 标准库的一部分,无需引入额外的依赖库,而 RxJava 需要引入 RxJava 核心库和相关的操作符库,增加了项目的复杂度和体积。
- 更加简单:Flow 基于 Kotlin 协程实现,使用协程的语法糖可以实现代码更加简单和易读,比 RxJava 更加简单。
- 更加灵活:Flow 支持背压处理和多个订阅者同时订阅同一个数据流,而 RxJava 对于多个订阅者需要使用
share()或replay()等操作符进行处理。 - 更加安全:Flow 可以在协程的上下文中运行,因此可以避免 RxJava 中常见的线程安全问题和内存泄漏问题。
- 更加可预测:Flow 使用 Kotlin 的类型安全特性,可以更加容易地避免类型不匹配和空指针异常等问题。