MapReduce调优
- MapReduce应用场景
- 优点
- 缺点
- 擅长应用场景
- 不擅长应用
- MapReduce优化需求与方向
- 文件存储格式
- 行式存储、列式存储
- Sequence File
- 优缺点
- Sequence File格式
- Sequence File 未压缩格式
- Sequence File 基于record压缩格式
- Sequence File基于block压缩格式
- 生成Sequence File文件
- 读取Sequence File文件
- 使用Sequece File合并小文件
- 有序二进制文件 MapFile
- 介绍
- 优点
- 缺点
- 案例
- 生成MapFile文件
- 读取MapFile文件生成Text文件
- 列式存储ORCFIle
- ORC与MapReduce继承
- 数据压缩优化
- 压缩设计与压缩算法
- Gzip压缩
- 读取普通文本文件,将普通文本文件压缩为Gzip格式
- 读取Gzip文件 还原普通文本文件
- Snappy压缩
- Lzo压缩
- MapReduce属性优化
- Uber模式
- 重试机制
- 关闭推测执行
- 小文件优化
- 减少Shuffle时Spill和Merge次数
MapReduce应用场景
优点
易于编程
固定的八股文编程模式,简单的定义即可快速实现开发分布式程序。用户往往专注于业务问题即可
易拓展
可以简单地通过增加机器来拓展MapReduce的计算能力
高容错
Hadoop会自动通过YARN完成机器级别的故障转移,如果某一台机器挂掉了,可以将上面的计算任务转移到另一个节点上运行,不至于任务失败,而且这个过程不需要人工参与,完全是由hadoop内部完成的
适用于PB级别的大数据量
理论上只要机器硬件足够多就可以出路无穷大的数据量,Hadoop设计之初就是基于链接PC机器构建大型分布式集群
缺点
处理速度很慢,不适合时效性要求较高的场景
数据存储主要使用静态数据,不适合实时数据流
MapReduce主要处理的数据来源自文件系统,所以无法向MySQL那样在毫秒或秒级别内返回数据,并且文件系统的数据是静态的,MapReduce则无法处理实时的流式数据
只有Map 和Reduce阶段,缺乏DAG设计
DAG 有向无环图
MapReduce处理数据过程中,如果需要经过多个步骤来实现,一个MapReduce就无法完成,如果通过多个MapReduce来实现,那么就必须将前一个MapReduce的结果写入磁盘,导致大量的IO小号导致MapReduce性能较差
擅长应用场景
TopN 问题
从海量数据中查询出现频率最高的前N个
Web日志访问频率统计
统计url、用户、搜索出现的频率统计
数据倒排索引
基于数据构建倒排索引,实现基于复杂条件词的数据检索
不擅长应用
迭代计算
从某个值开始,不断地由上一部结果计算或者推断出下一步的结果
机器学习
分类、聚类、关联、预测
连接计算
Join关联
MapReduce优化需求与方向
需求
基于MapReduce所存在的优化性能问题,在实际工作中可以通过优化方案来提高MapReduce整体性能,从而节约生产成本
优化方向
- 从文件角度考虑,通过更改二进制文件、列式存储、压缩来降低磁盘以及网络IO,进而提高性能
- 通过控制MapReduce过程中的资源属性,合理分配资源,提高资源利用率,提高程序运行效率
文件存储格式
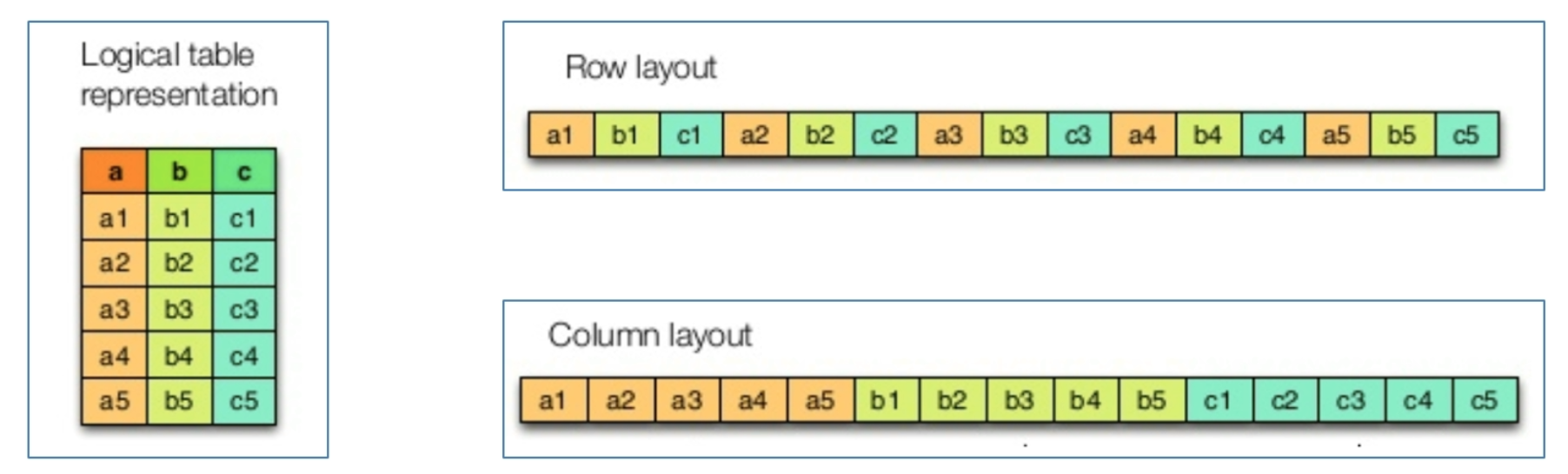
行式存储、列式存储
行式存储(Row - Based) 同一行数据存储在一起
列式存储(Column-Based): 同一列数据存储在一起
优缺点
行式存储的写入时一次性完成的,消耗的时间比列式存储少,并且能够保证数据的完整性,缺点是数据通过读取过程中会产生冗余数据,如果只有少量数据,此影响可以忽略,数量大可能会影响到数据的处理效率。行式存储适合插入,不适合查询
列式存储再写入效率、保证数据完整性上都不如行式存储,它的优点是在读取过程中不会产生冗余数据,这对数据完整性要求不高的大数据处理领域,比如说互联网来说非常重要。列式存储适合查询,不适合插入
Sequence File
SequenceFile时Hadoop提供的一种二进制文件存储格式
一条数据称之为record(记录),底层直接以<Key,Value>键值对形式序列化到文件中

优缺点
优点
二进制格式存储 比文本文件更加紧凑
支持不同级别压缩(基于Record或者Block压缩)
文件可以拆分和并行处理,适用于MapReduce程序
局限性
二进制格式文件不方便查看
特定于Hadoop,只有Java Api可以与之交互,未提供多种语言支持
Sequence File格式
根据压缩类型,有三种不同的Sequence File格式: 未压缩格式、Record压缩格式、Block压缩格式
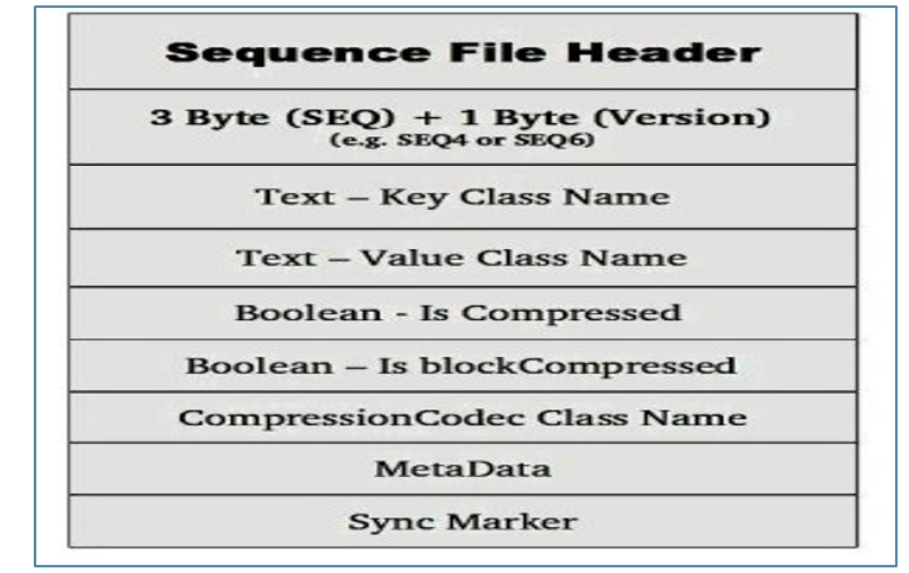
Sequence File有一个header和一个或者多个record组成,以上三种格式均使用相同的header结构:
前三个字节未SEQ,表示该文件是序列文件,后跟一个字节表示实际版本号(例如SEQ4或者SEQ6),Header中也包括其他key、value、class名字、压缩细节、metadata、Sync marker,Sync Marker 同步标记,用于可以读取任务位置的数据。
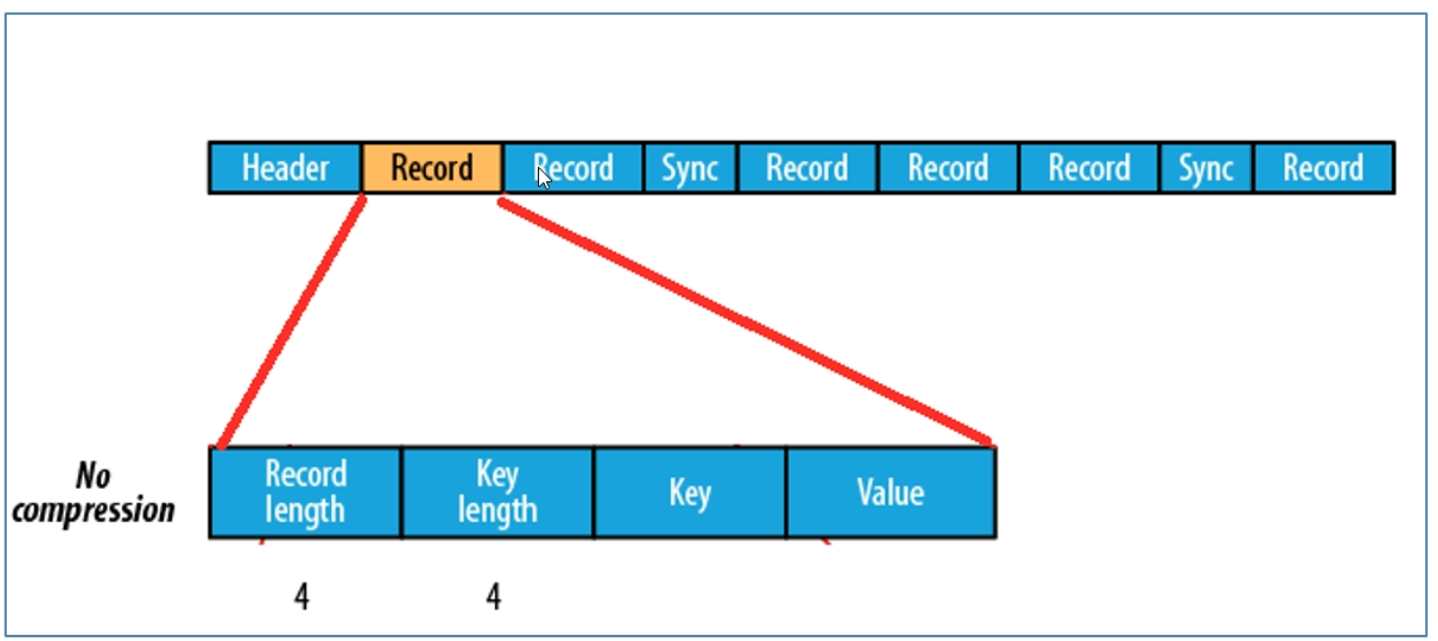
Sequence File 未压缩格式
未压缩Sequence File文件由header、record、sync三部分组成,其中record包括4各部分:record length(记录长度)、key length(键长)、key、value
每隔几个record(100字节左右)就会有一个同步标记
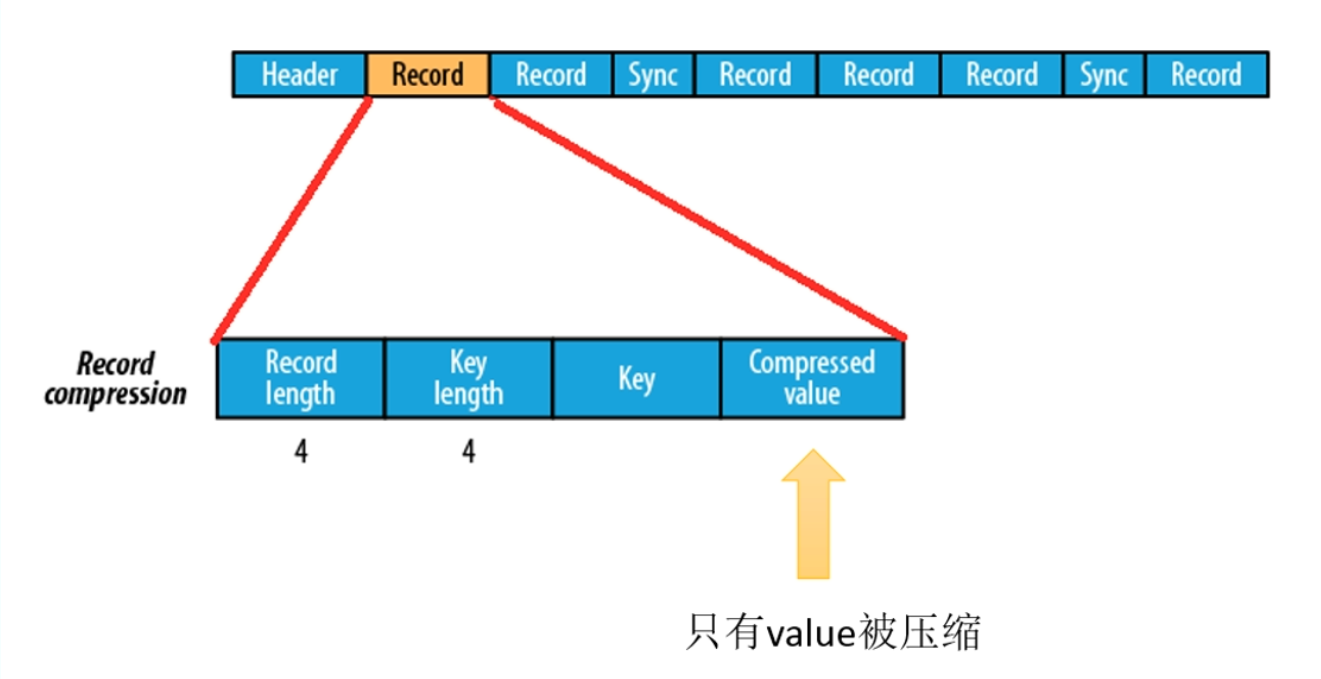
Sequence File 基于record压缩格式
基于record压缩的Sequence File文件由header、record、sync三个部分组成,其中record包含了4各部分:record length(记录长度)、key length(键长)、key、compressed value(被压缩的值)
每隔几个record(100字节左右)就会有一个同步标记
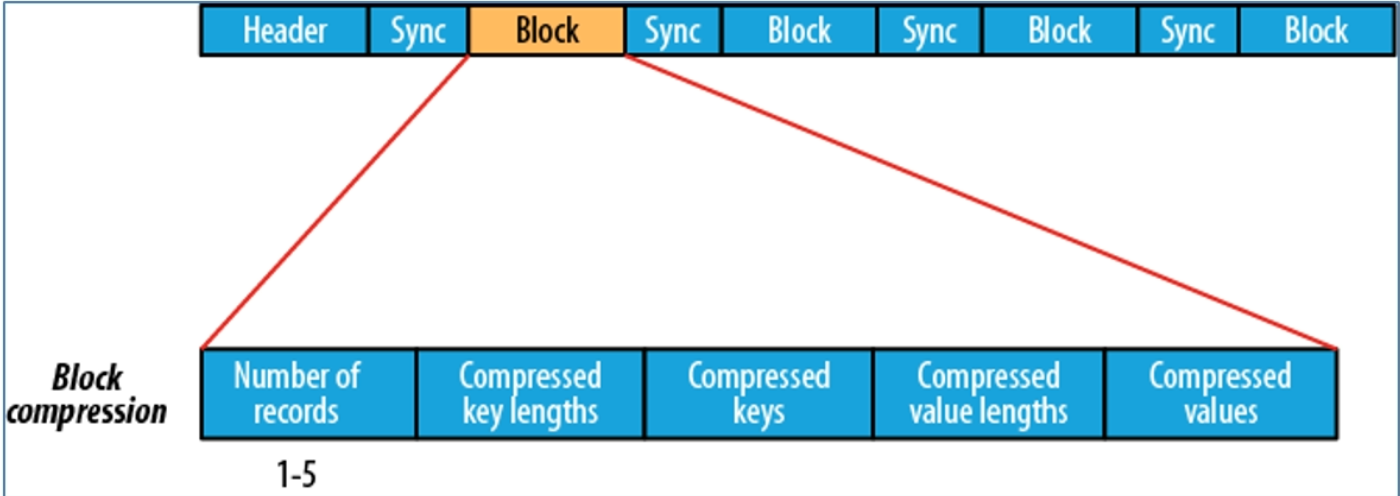
Sequence File基于block压缩格式
基于block压缩的Sequence File文件由header、block、sync三个部分组成
block指的是record block,可以理解为多个record记录组成的块,注意,这个block和HDFS中的分块存储不是一个概念,Block 中包括:record条数、压缩key长度、压缩的keys、压缩的value长度、压缩的values,每隔一个block就有一个同步标记
blocky阿索比record压缩提供更多的压缩率,使用Sequence File时,通常首选块压缩
生成Sequence File文件
- 使用TextInputFormat读取不同文字文件
- Map阶段对读取文件的每一行进行输出
- Reduce阶段直接输出每条数据
- 使用SequenceFileOutPutFormat将结果进行SequenceFile
// 设置输出格式 在这里输出格式为SequenceFile格式
job.setOutputFormatClass(SequenceFileOutputFormat.class);
// 设置压缩类型 在这里选择的是BLOCK压缩格式
SequenceFileOutputFormat.setOutputCompressionType(job, SequenceFile.CompressionType.BLOCK);
去查看输出的样式
读取Sequence File文件
- 使用SequenceFileInputFormat读取SequenceFile
- Map姐u但直接读取每一条数据
- Reduce阶段直接输出,每一条数据
- 使用TextOutputFormat将结果保存为文本文件
只需要在这里进行修改即可
job.setInputFormatClass(SequenceFileInputFormat.class);
使用Sequece File合并小文件
假设HDFS某个目录下有多个小文件,这些文件虽然磁盘占用空间不大,但是内存空间中用却不少(元数据存储在内存中)
可以编写一个程序将所有的小文件写入到一个Sequence File中,即将文件名作为key,文件内容作为value序列化到Sequence File大文件中,这就是所谓的使用Sequence File合并小文件
有序二进制文件 MapFile
介绍
可以理解MapFile是排序后的SequenceFile,通过观察结构可以看到MapFile由两部分组成,分别是data和index,data为存储数据的文件,index作为文件的数据索引,主要记录了每个Record的Key值以及Record在文件中的偏移位置
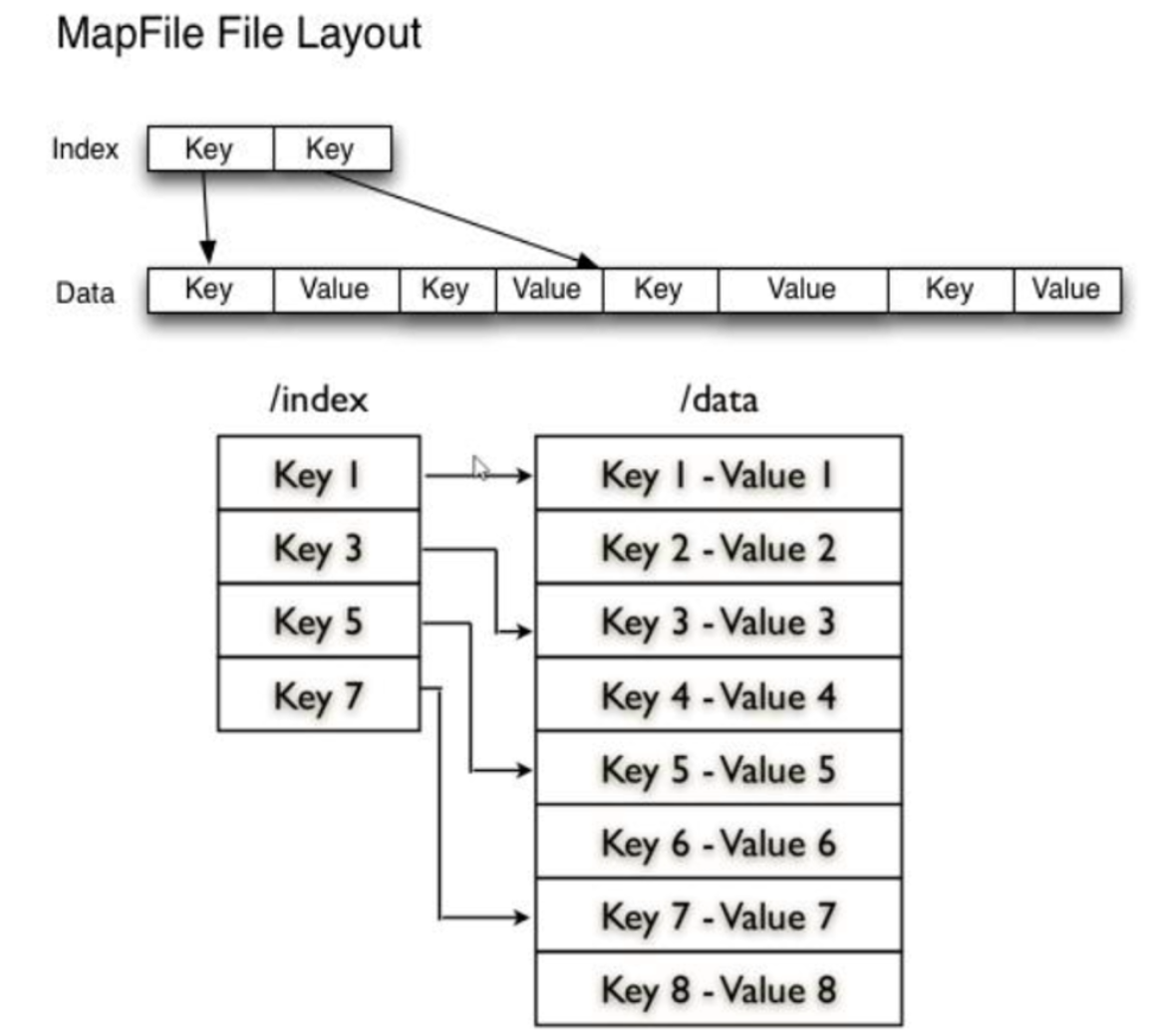
优点
在MapFile被访问的时候,索引文件会被索引映射关系可以迅速定位到指定的Record文件所在的文件位置,因此,相对于Sequence File而言,MapFile加载到内存,通过索引效率最高
缺点
会消耗一部分内存来存储index数据
案例
生成MapFile文件
生成MapFile文件和生成Sequence File的方法相同,其他地方无需改动,只需要在Driver阶段指定输出的格式就可
package MapFileTest;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.MapFileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.io.IOException;
import java.util.Iterator;
import java.util.Random;
public class MapFileCreate extends Configured implements Tool {
private static class MapFileMapper extends Mapper<LongWritable, Text, IntWritable,Text> {
private IntWritable outKey =new IntWritable();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
Random random = new Random();
outKey.set(random.nextInt(10000));
context.write(outKey,value);
}
}
private static class MapFileReduce extends Reducer<IntWritable,Text,IntWritable,Text>{
@Override
protected void reduce(IntWritable key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
Iterator<Text> iterator = values.iterator();
while (iterator.hasNext()){
context.write(key,iterator.next());
}
}
}
public static void main(String[] args) throws Exception {
ToolRunner.run(new MapFileCreate(),args);
}
@Override
public int run(String[] args) throws Exception {
Job job = Job.getInstance(getConf(), MapFileCreate.class.getSimpleName());
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(Text.class);
job.setMapOutputKeyClass(IntWritable.class);
job.setMapOutputValueClass(Text.class);
job.setJarByClass(MapFileCreate.class);
job.setMapperClass(MapFileMapper.class);
job.setReducerClass(MapFileReduce.class);
// todo 在这里进行设置,设置最终的输出格式是MapFile格式
job.setOutputFormatClass(MapFileOutputFormat.class);
FileInputFormat.addInputPath(job,new Path("E:\\MapReduceTest\\input"));
FileOutputFormat.setOutputPath(job,new Path("E:\\MapReduceTest\\MapFileOut"));
return job.waitForCompletion(true) ? 0 : 1;
}
}
运行后查看输出效果


查看data文件内容

可见本质上就是Sequence 文件
读取MapFile文件生成Text文件
MapReduce中没有封装MapFile的读取输入类,工作中可以根据情况选择以下两种方案来实现:
- 自定义InputFormat,使用MapFileOutputFormat中的getReader方法来获取读取对象
- 使用SequenceFileInputFormat对MapFile文件进行解析
- 因为MapFile本质上就是一个Sequence + 索引优化,直接使用SequenceFileOutputFormat无非是放弃了索引优化直接来获取内容罢了
列式存储ORCFIle
ORC(OptimizedRC File)文件格式是一种Hadoop生态圈中的类是存储格式,他被生产自Hive用来降低hadoop数据存储空间和加速Hive查询速度。ORC并不是单纯的列式存储,仍然是首先根据Stripe(条纹、组行)分割整个表,在每一个Stripe内进行按列存储。
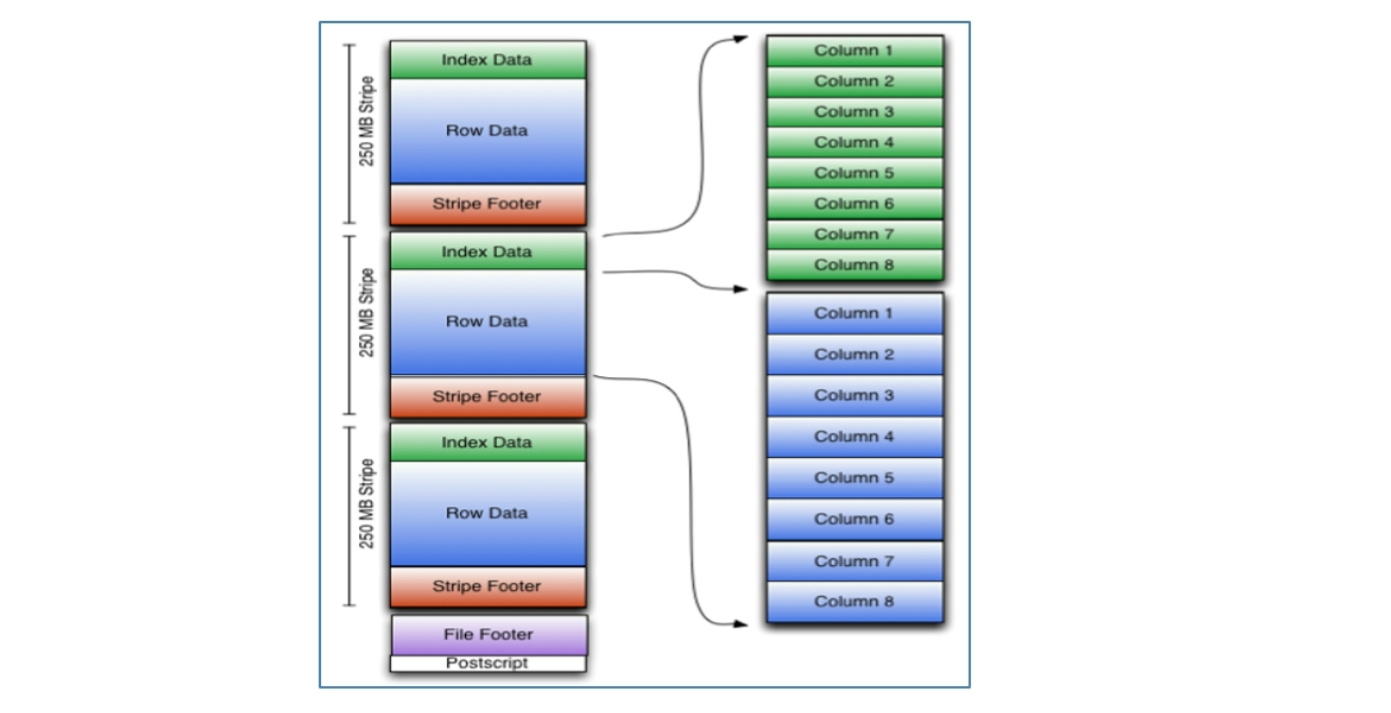
ORC 文件时子描述的,他的元数据使用Protocol Buffers序列化,并且文件中的数据尽可能的压缩以降低存储空间的小号,目前也被Spark SQL、Presto等查询引擎支持
ORC文件是以二进制方式存储的,所以是不可以直接读取的
ORC与MapReduce继承
关联Maven依赖
<!--ORC 关联MapReduce-->
<dependency>
<groupId>org.apache.orc</groupId>
<artifactId>orc-shims</artifactId>
<version>1.8.3</version>
</dependency>
<dependency>
<groupId>org.apache.orc</groupId>
<artifactId>orc-core</artifactId>
<version>1.8.3</version>
</dependency>
<dependency>
<groupId>org.apache.orc</groupId>
<artifactId>orc-mapreduce</artifactId>
<version>1.8.3</version>
</dependency>
关键的两个类OrcOutputFormat: 用于生成ORC文件、OrcInputFormat:用于实现读取ORC文件类型
数据压缩优化
压缩设计与压缩算法
优点
- 减少文件存储所占的空间
- 加快文件传输效率,减少网络传输带宽
- 降低IO读写次数
缺点
使用数据是需要先对文件进行解压,加重了CPU负荷,压缩算法越复杂,解压时间越长
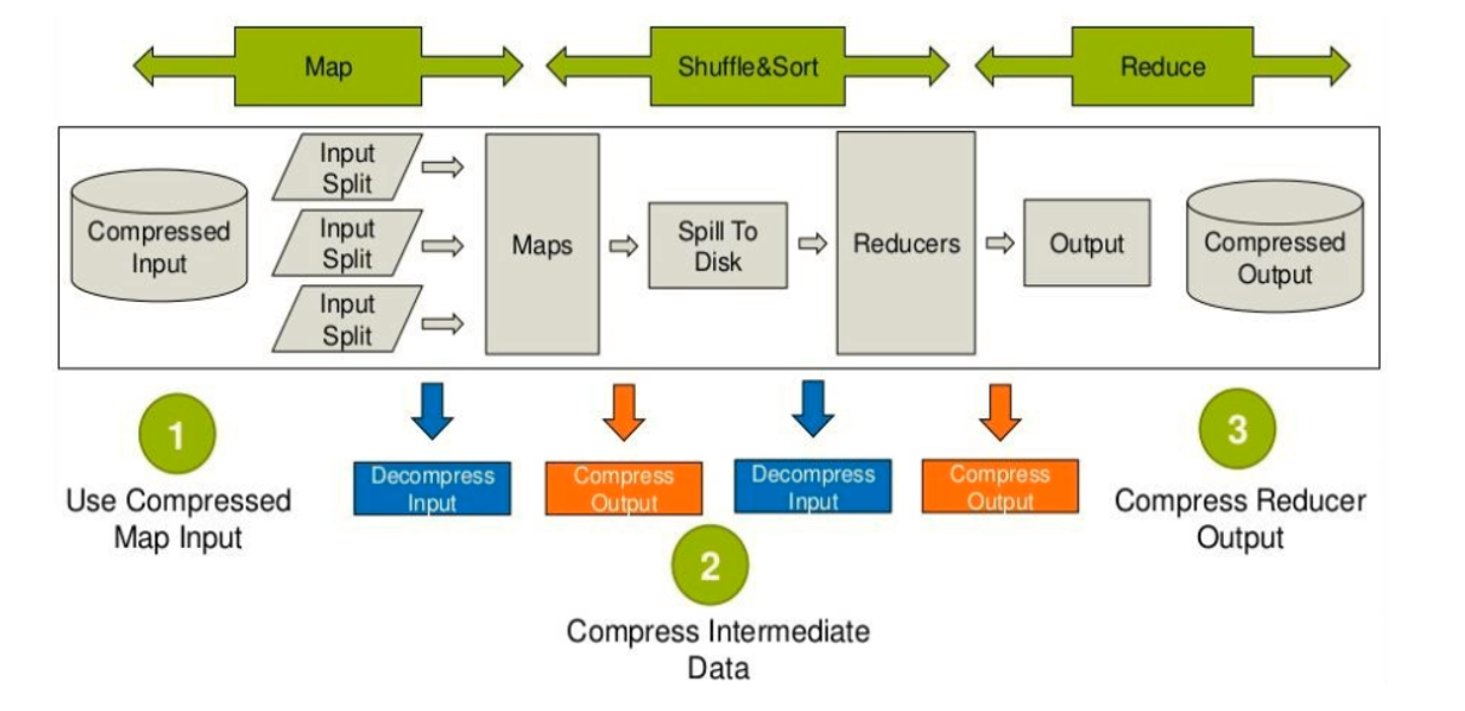
压缩的位置
压缩配置
在Hadoop中配置压缩
Input:MapReduce输入通过文件后名进行判断,自动识别读取压缩类型,不需要做任何配置
Map output:需要配置以下参数

Reduce Output:需要配置以下参数

Gzip压缩
优缺点
| 压缩算法 | 优点 | 缺点 |
|---|---|---|
| Gzip | 压缩比较高; hadoop本身支持,在应用中处理gzip格式文件就和直接处理文本文件一样 有hadoop native库 大部分linux系统都自带gzip命令,使用起来比较方便 | 不支持split |
编码器
org.apache.hadoop.io.compress.GzipCodec
读取普通文本文件,将普通文本文件压缩为Gzip格式
在进行压缩这个过程,整体上不需要进行大的改动,无非是在最后的输入阶段进行一个修改
Java文件
package Zip;
import MapFileTest.MapFileCreate;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.io.IOException;
import java.util.Iterator;
/**
* @author wxk
* @date 2023/05/11/10:52
*/
public class GzipTest extends Configured implements Tool {
private static class MRMapper extends Mapper<LongWritable, Text, NullWritable,Text> {
private NullWritable outKey= NullWritable.get();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
context.write(outKey,value);
}
}
private static class MRReduce extends Reducer<NullWritable,Text, NullWritable,Text> {
@Override
protected void reduce(NullWritable key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
Iterator<Text> iterator = values.iterator();
while (iterator.hasNext()){
context.write(key,iterator.next());
}
}
}
public static void main(String[] args) throws Exception {
Configuration cfg =new Configuration();
// 配置输出结果压缩为gzip格式
cfg.set("mapreduce.output.fileoutputformat.compress","true");
cfg.set("mapreduce.output.fileoutputformat.compress.codec","org.apache.hadoop.io.compress.GzipCodec");
// 提交job
final int run = ToolRunner.run(cfg, new GzipTest(), args);
System.exit(run);
}
@Override
public int run(String[] args) throws Exception {
Job job = Job.getInstance(getConf(), MapFileCreate.class.getSimpleName());
job.setOutputKeyClass(NullWritable.class);
job.setOutputValueClass(Text.class);
job.setMapOutputKeyClass(NullWritable.class);
job.setMapOutputValueClass(Text.class);
job.setJarByClass(GzipTest.class);
job.setMapperClass(MRMapper.class);
job.setReducerClass(MRReduce.class);
FileInputFormat.addInputPath(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
return job.waitForCompletion(true) ? 0 : -1;
}
}
运行jar包之后查看运行结果
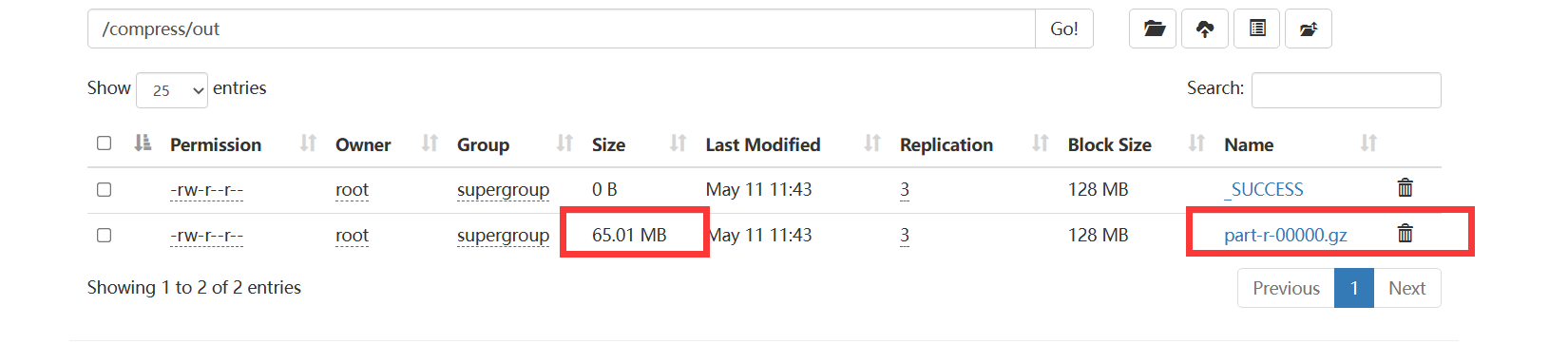
原来的文件大小

读取Gzip文件 还原普通文本文件
在上文中我们讲过hadoop在读取过程中会根据文件后缀自动的进行解压缩,所以我们在读取的过程中不需要任何的操作,我们使用原来的代码但是仅仅注掉压缩的两行代码,其余无需修改,直接打成jar包直接运行
// cfg.set("mapreduce.output.fileoutputformat.compress","true");
// cfg.set("mapreduce.output.fileoutputformat.compress.codec","org.apache.hadoop.io.compress.GzipCodec");
运行结果如下

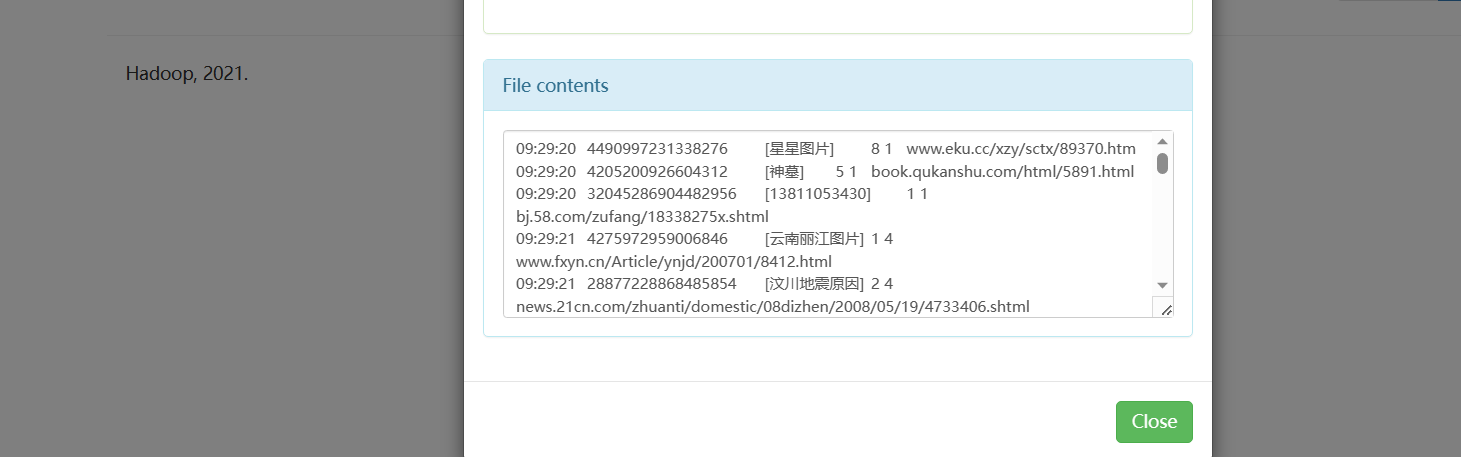
文件也可以正常读,和以前的一样
Snappy压缩
优缺点
| 压缩算法 | 优点 | 缺点 |
|---|---|---|
| Snappy | 压缩速度快 支持Hadoop native库 | 不支持spilt 压缩比低 hadoop本身不支持 需要安装 linux系统下没有对应的位置 |
编码器 org.apache.hadoop.io.compress.SynappyCodec
Lzo压缩
优缺点
| 压缩算法 | 优点 | 缺点 |
|---|---|---|
| Lzo | 压缩/解压速度比较快,合理的压缩率 支持spilt,时hadoop中最流行的压缩格式 支持hadoop native库 需要Linux 系统下自行安装lzop命令,使用方便 | 压缩率比gzip要低 hadoop本身不支持,需要安装 lzo支持split,但是需要对lzo文件建索引,否则hadoop也会将lzo文件看成一个普通文件(为了支持split需要建立索引,需要指定inputformat为lzo格式) |
编码器1 : org.apache.hadoop.io.compress.LzoCodec [结尾为.lzo_deflate] 不能够建索引 不兼容lzop
编码器2:com.hadoop.compression.lzo.LzopCodec [结尾.lzo 可以构建索引,兼容lzo]
MapReduce属性优化
MapReduce的核心优化在于修改文件类型、合并小文件、使用压缩等方式,通过降低Io 开销来提升MapReduce过程中Task的执行效率;除此之外,MapReduce中也可以通过调节一些参数来从整体上提升MapReduce的性能,可以通过基准测试来测试MapReduce集群对应的性能,观察实施了优化以后MapReduce的性能是否得到了提升等
基准测试概述
yarn jar hadoop安装路径/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-hadoop版本号-tests.jar
例如我的hadoop时3.3.1 ,安装路径为/opt/module/hadoop-3.3.1

测试基准 -MR Bench
功能:用于指定生成文件,MapTask、ReduceTask的个数,并且可以指定执行的次数
例如:生成每隔文件10000行、20个mapper、5个reducer、执行两次
yarn jar hadoop-mapreduce-client-jobclient-3.3.1-tests.jar mrbench -numRuns 2 -inputLines 10000 -maps 20 -reduces 5

最后会输出相应的数据,可以看到我们这个需要平均需要1分多钟
基准测试 -Load Gen
功能: 指定对某个数据进行加载、处理、测试性能耗时,可以调整Map和Reduce个数
例如: 对150M的数据进行测试,10个Map、1个Reduce
yarn jar hadoop-mapreduce-client-jobclient-3.3.1-tests.jar loadgen -m 10 -r 1 -indir 数据位置 -outdir 输出位置
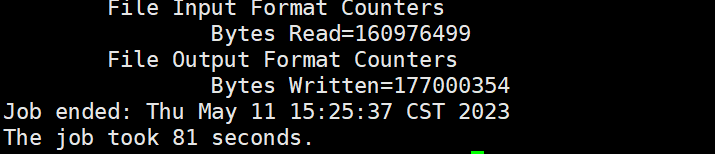
大概80多秒
Uber模式
Uber运行模式对小作业进行优化,不会给每隔认为u分配Container资源,这些小任务将统一在一个Container中按照先执行map任务后执行reduce任务的顺序串行执行
开启
mapreduce.job.unbertask.enable = true,默认为false可以在mapred-site.xml中修改
限制条件
map任务的数量不大于mapreduce.job.unbertask.maxmaps参数(默认值为9)
reduce 任务的数量不大于mapreduce.job.unbertask.maxreduces参数(默认值是1)
输入文件大小不大于mapreduce.job.unbertask.maxbytes参数(默认为一个块的大小128MB)
map任务和reduce任务需要的资源不能大于MRAppMaster可用的资源总量
重试机制
功能:如果出现MapTask或者ReduceTask,由于网络、资源等外部因素导致TGask失败,AppMaster会检测到Task的任务失败,会立即重分配资源,如果重试以后人没有运行成功,那么整个Job会终止,程序运行失败。
每隔task的最大尝试次数,换句话说,框架将在放弃之前多次尝试执行Task
mapreduce.map.maxattempts=4
mapreduce.reduce.maxattempts=4
关闭推测执行
功能
推测执行是指在一个Task任务执行比预期慢时,程序会尽量检测并启动一个相同的任务作为备份,这就是推测执行,但是如果同时启动两个相同的任务,他们就会相互竞争,导致推测执行无法正常工作,这对资源是一种良妃,默认开启,实际中基于性能可以考虑选择关闭
配置
mapreduce.map.speculative =true
mapreduce.reduce.speculative=true
小文件优化
针对于小文件处理场景,默认每个小文件都会构建一个切片,启动一个maptask处理,可以使用CombineTextInputFormat代替TextInputFormat,将多个小文件合并成为一个切片
CombineTextInputFormat切片机制包括:虚拟存储过程和切片过程两个部分
虚拟过程
将输入目录下所有的文件大小,一次和设置的setMaxInputSplitSize值进行比较,如果不大于设置的最大值,逻辑上划分一个块,如果输入文件大于设置的最大值且大于两倍,那么以最大值切割一块,当剩余数据大小超过了设置的最大值但是不大于两倍,那么旧文件平均分成两个虚拟存储块(防止出现太小的切片)
切片过程
判断虚拟存储的文件是否大于setMaxInputSplitSize值,大于等于则单独形成一个切片,如果不大于则跟下一个虚拟存储文件进行合并,共同形成一个切片
//设置输入类
job.setInputFormatClass(CombinTextInputFormat.class);
CombineTextinputFormat.setMaxInputSplitSize(job,4194304);//4MB
减少Shuffle时Spill和Merge次数
默认每隔缓冲区大小为100MB,每次达到80%开始Spill,如果调大这两个值,可以减少数据spill的次数,从而减少磁盘IO,默认每次生成10个小文件开始进行合并,如果增大文件个数,可以减少merge的次数,从而减少磁盘IO