1. 简介
-
使用CPU来运行C++版本的RWKV
-
rwkv.cpp 可以将 RWKV 原始模型的参数转化为 float16,并量化到 int4,可以在 CPU 上更快地运行,也可以节省更多的内存。
2. 下载项目
## git clone --recursive https://github.com/saharNooby/rwkv.cpp.git
cd rwkv.cpp
3. 下载依赖或者自行编译
-
使用CPU-Z 来查看一下自己的CPU是否支持AVX2 or AVX-512,如果支持的话,可以直接下载作者编译好的依赖库
-

-
我这里是支持AVX指令集的,所以直接使用作者编译好的依赖库了
-
打开Releases · saharNooby/rwkv.cpp · GitHub
-
rwkv.cpp 的开发者已经预编译了不同平台上的依赖库,可以在这里下载
-
下载rwkv-master-a3178b2-bin-win-avx-x64.zip
-

-
解压之后是一个dll文件,将其放在根目录下
-
如果上面没有适适合自己平台的依赖库的话,那么需要进行自行编译
编译
cmake .
cmake --build . --config Release
4. 准备模型
- 下载项目权重时,有两种选择,一种是下载作者已经量化好的bin模型,另一种是下载pat模型,然后自己手动量化
- BlinkDL (BlinkDL)
4.1. 模型名称的参数
- 统一前缀 rwkv-4 表示它们都基于 RWKV 的第 4 代架构。
- pile 代表基底模型,在 pile 等基础语料上进行预训练,没有进行微调,适合高玩来给自己定制。
- novel 代表小说模型,在各种语言的小说上进行微调,适合写小说。
- raven 代表对话模型,在各种开源的对话语料上进行微调,适合聊天、问答、写代码。
- 430m、7b 这些指的是模型的参数量。

- 我这边下载的是这个
Q8_0-RWKV-4-Raven-7B-v11-Eng49%-Chn49%-Jpn1%-Other1%-20230430-ctx8192.bin
权重,下载下来可以直接使用,而不必进行转化以及量化。如果想要自己手动量化的话,可以继续看后面的步骤
- Q8_0-RWKV-4-Raven-7B-v11-Eng49%-Chn49%-Jpn1%-Other1%-20230430-ctx8192.bin · BlinkDL/rwkv-4-raven at main
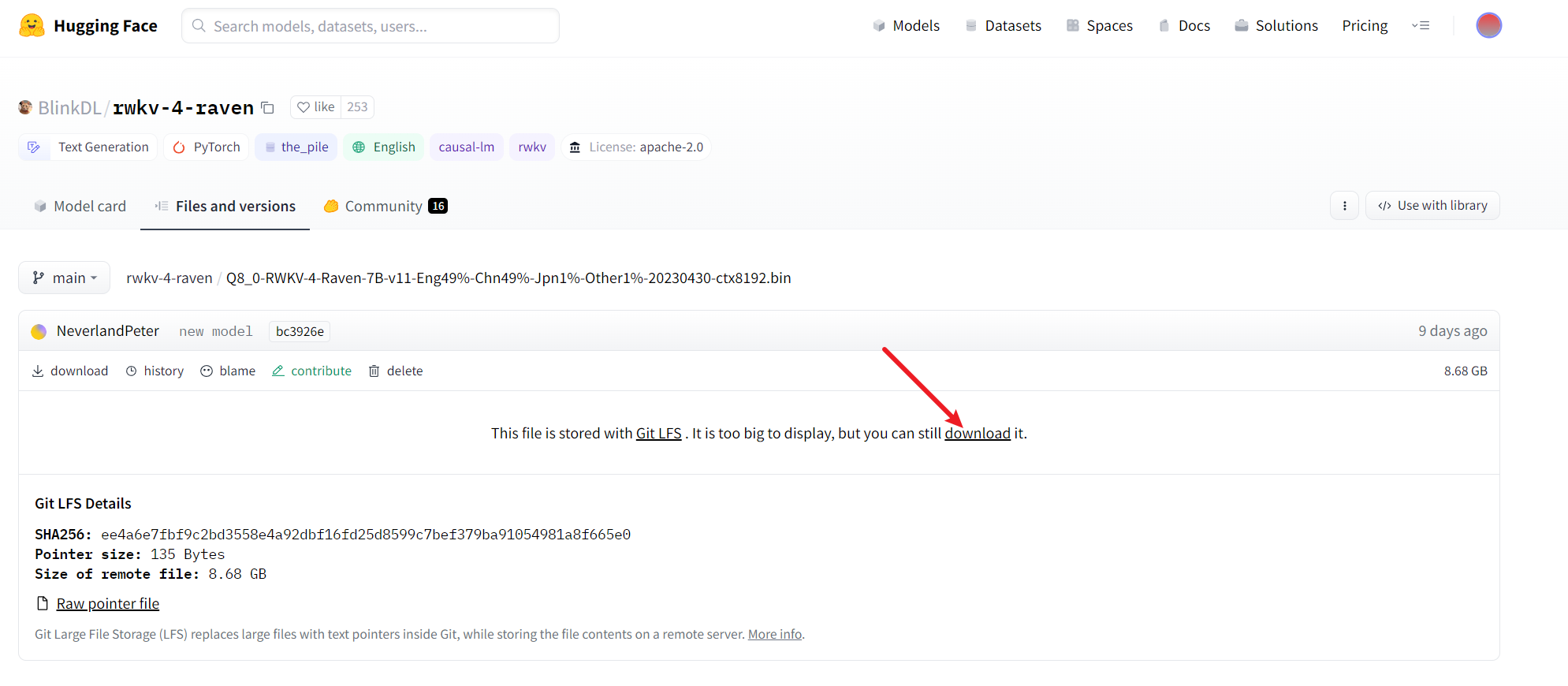
- 文件比较大,网速慢的话,得稍等一会儿
4.2. 转换模型
- 正常情况下,下载后这个模型配合ChatRWKV仓库中的代码就可以跑了,但是他对CPU的支持最低只到FP32i8,7B模型需要12GB内存才能跑起来,因此,我们使用的rwkv.cpp可以将RWKV原始模型的参数转换为float16,并量化到int4,可以在CPU上更快的运行,同时也可以节省更多的内存
- 将下载好的PyTorch模型放在rwkv.cpp的路径下,执行下面的命令
### python rwkv/convert_pytorch_to_ggml.py RWKV-4-Raven-7B-v7-EngAndMore-20230404-ctx4096.pth ./rwkv.cpp-7B.bin float16
- 这个代码的命令就是让Python运行这个rwkv/convert_pytorch_to_ggml.py转换模型的代码,
- RWKV-4-Raven-7B-v7-EngAndMore-20230404-ctx4096.pth是待转换的权重,根据自己下载的文件,适当进行修改
- rwkv.cpp-7B.bin 是转换后的模型路径,float16指的是将模型转换为float16类型


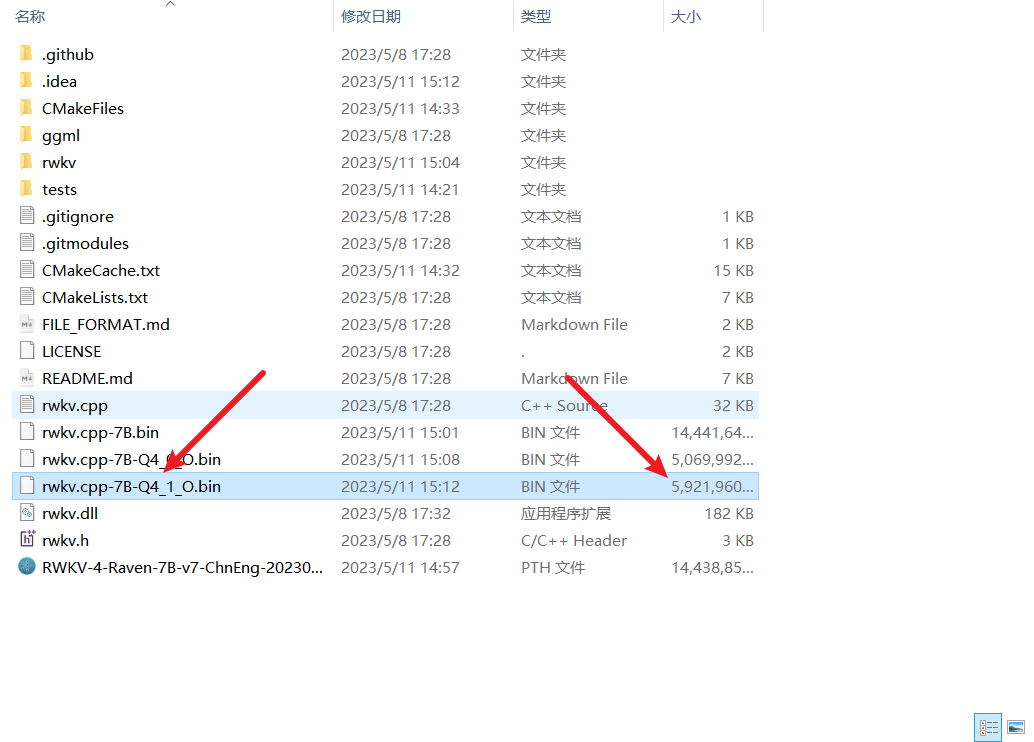
- 生成的模型,与原模型相比,尺寸并没有发生改变

4.3. 量化模型
- 上面转换之后的rwkv.cpp-7B.bin模型其实已经可以用了,但是它占用的显存内存依然比较多,大约需要16GB内存,为了进一步的减少内存占用,也为了加快模型的推理速度,可以将这个模型量化为int4,这样可以省一半的内存
### python rwkv/quantize.py ./rwkv.cpp-7B.bin ./rwkv.cpp-7B-Q4_1_O.bin Q4_0

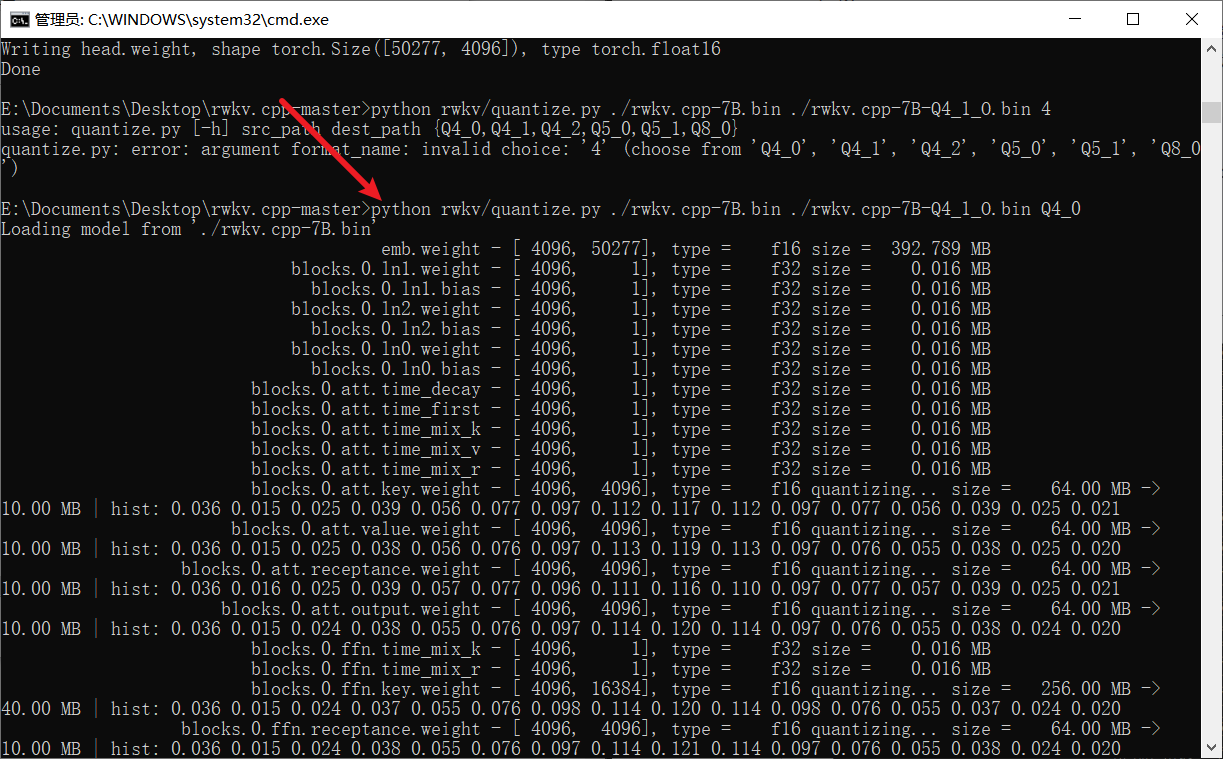

5. 运行模型
- 经过前面的转化和量化之后,运行模型就非常简单了,只需要一行命令就可以搞定
- 如果想要生成模型,那么使用下面的人来运行
### python rwkv\generate_completions.py rwkv.cpp-7B-Q4_1_O.bin
### python rwkv/chat_with_bot.py rwkv.cpp-7B-Q4_1_O.bin
- 启动需要的时间还是比较长的,耐心等一会儿

启动完毕,进行测试

6. 测试效果
- 不知道为什么,他回答自己是OpenAI训练的ChatGPT

- 生成的文字长度还是挺可以的,对话的时候告诉他继续,他就可以一直生成下去

而且也可以进行编程
-

-
但是在写代码的时候,依然存在一次输出的长度太短的问题
-
[外链图片转存中…(img-zVNWyhth-1683796408249)]
而且也可以进行编程
- [外链图片转存中…(img-KiL0hZzE-1683796408250)]
- 但是在写代码的时候,依然存在一次输出的长度太短的问题