CONTENTS
- 三、神经网络
- 3.1 从感知机到神经网络
- 3.2 Activation function
- 3.3 多维数组的运算
- 3.4 三层神经网络的实现
- 3.5 输出层的设计
- 3.6 手写数字识别
三、神经网络
3.1 从感知机到神经网络
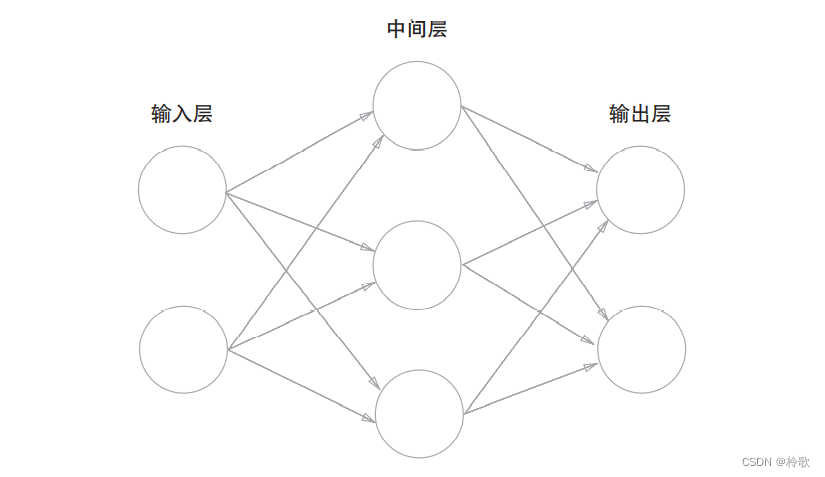
用图来表示神经网络的话,如下图所示,我们把最左边的一列称为输入层,最右边的一列称为输出层,中间的一列称为中间层(隐藏层)。
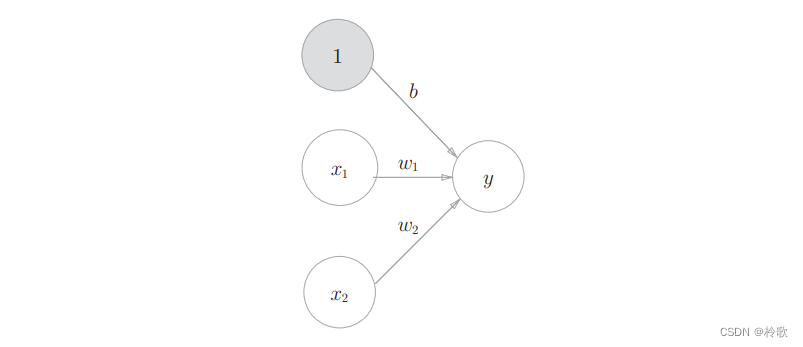
在上图的网络中,偏置 b b b并没有被画出来。如果要明确地表示出 b b b,可以像下图那样做。下图中添加了权重为 b b b的输入信号 1 1 1。这个感知机将 x 1 , x 2 , 1 x_1,x_2,1 x1,x2,1三个信号作为神经元的输入,将其和各自的权重相乘后,传送至下一个神经元。在下一个神经元中,计算这些加权信号的总和。如果这个总和超过 0 0 0,则输出 1 1 1,否则输出 0 0 0。另外,由于偏置的输入信号一直是 1 1 1,所以为了区别于其他神经元,我们在图中把这个神经元整个涂成灰色。
我们用一个函数来表示这种分情况的动作(超过 0 0 0则输出 1 1 1,否则输出 0 0 0),即 y = h ( b + w 1 x 1 + w 2 x 2 ) y=h(b+w_1x_1+w_2x_2) y=h(b+w1x1+w2x2),其中函数 h ( x ) h(x) h(x)如下式所示:
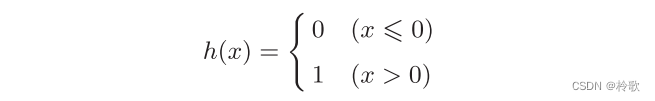
h ( x ) h(x) h(x)函数会将输入信号的总和转换为输出信号,这种函数一般称为激活函数。激活函数的作用在于决定如何来激活输入信号的总和。
可将以上式子细化为如下两个式子:
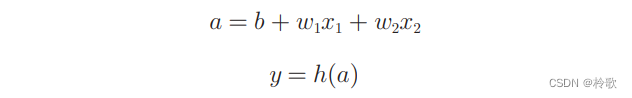
激活函数的计算过程如下图所示:
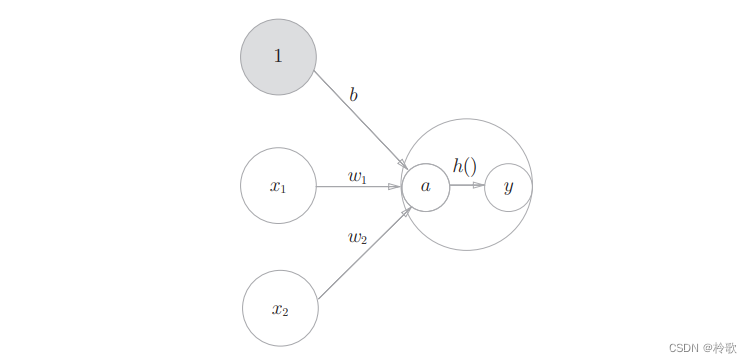
3.2 Activation function
神经网络中经常使用的一个激活函数就是下式表示的 s i g m o i d sigmoid sigmoid函数:

现在,我们先尝试画出阶跃函数的图像,当输入超过 0 0 0时,输出 1 1 1,否则输出 0 0 0。可以像下面这样简单地实现阶跃函数:
# 参数只能为实数
def step_function(x):
if x > 0:
return 1
else:
return 0
# 参数可以为NumPy数组
def step_function(x):
y = x > 0
return y.astype(np.int)
接着进行函数图像的绘制:
import numpy as np
import matplotlib.pylab as plt
def step_function(x):
return np.array(x > 0, dtype=np.int)
x = np.arange(-5.0, 5.0, 0.1)
y = step_function(x)
plt.plot(x, y)
plt.ylim(-0.1, 1.1) # 指定y轴的范围
plt.show()
结果如下图所示:
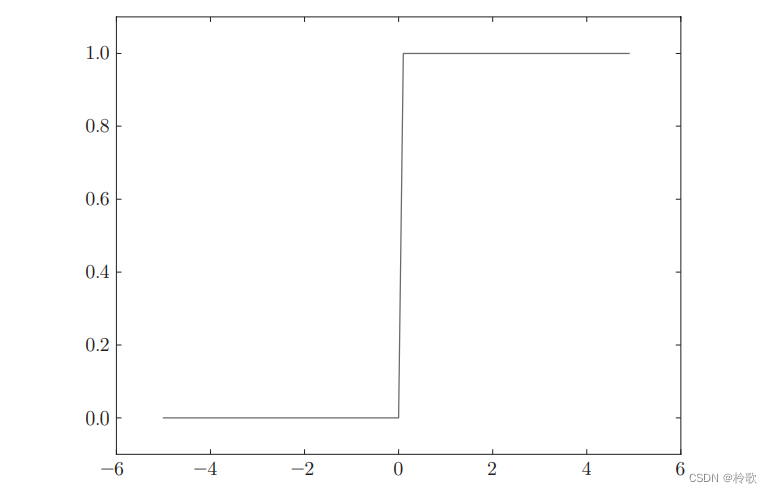
接下来我们实现 s i g m o i d sigmoid sigmoid函数:
def sigmoid(x):
return 1 / (1 + np.exp(-x))
并绘制函数图像:
x = np.arange(-5.0, 5.0, 0.1)
y = sigmoid(x)
plt.plot(x, y)
plt.ylim(-0.1, 1.1) # 指定y轴的范围
plt.show()
结果如下图所示:
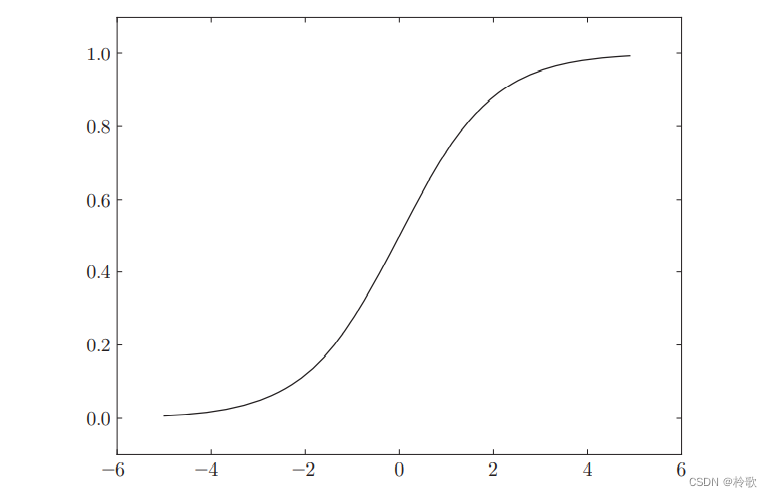
s i g m o i d sigmoid sigmoid函数是一条平滑的曲线,输出随着输入发生连续性的变化。而阶跃函数以 0 0 0为界,输出发生急剧性的变化。 s i g m o i d sigmoid sigmoid函数的平滑性对神经网络的学习具有重要意义。
相对于阶跃函数只能返回 0 0 0或 1 1 1, s i g m o i d sigmoid sigmoid函数可以返回$0.731\dots,0.880\dots $等实数(这一点和刚才的平滑性有关)。也就是说,感知机中神经元之间流动的是 0 0 0或 1 1 1的二元信号,而神经网络中流动的是连续的实数值信号。
阶跃函数和 s i g m o i d sigmoid sigmoid函数虽然在平滑性上有差异,但是它们具有相似的形状。两者的结构均是“输入小时,输出接近 0 0 0(为 0 0 0);随着输入增大,输出向 1 1 1靠近(变成 1 1 1)”。也就是说,当输入信号为重要信息时,阶跃函数和 s i g m o i d sigmoid sigmoid函数都会输出较大的值;当输入信号为不重要的信息时,两者都输出较小的值。
阶跃函数和 s i g m o i d sigmoid sigmoid函数还有其他共同点,就是两者均为非线性函数。神经网络的激活函数必须使用非线性函数。换句话说,激活函数不能使用线性函数。为什么不能使用线性函数呢?因为使用线性函数的话,加深神经网络的层数就没有意义了。
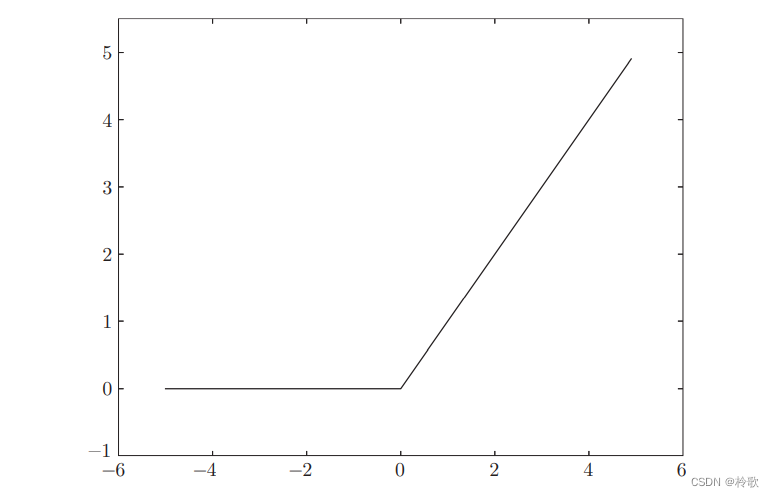
接下来介绍另一个十分重要的激活函数: R e L U ReLU ReLU函数。 R e L U ReLU ReLU函数在输入大于 0 0 0时,直接输出该值;在输入小于等于 0 0 0时,输出 0 0 0,可以用下式表示:
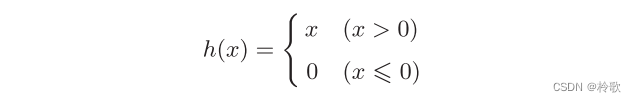
其代码实现以及函数图像如下:
def relu(x):
return np.maximum(0, x)
3.3 多维数组的运算
多维数组就是“数字的集合”,数字排成一列的集合、排成长方形的集合、排成三维状或者(更加一般化的) N N N维状的集合都称为多维数组。
A = np.array([1, 2, 3, 4])
np.ndim(A) # 1,获得数组的维数
A.shape # (4,)
A.shape[0] # 4
B = np.array([[1, 2], [3, 4], [5, 6]])
np.ndim(B) # 2
B.shape # (3, 2)
下面,我们来介绍矩阵(二维数组)的乘积。比如 2 × 2 2\times 2 2×2的矩阵,其乘积可以像下图这样进行计算:
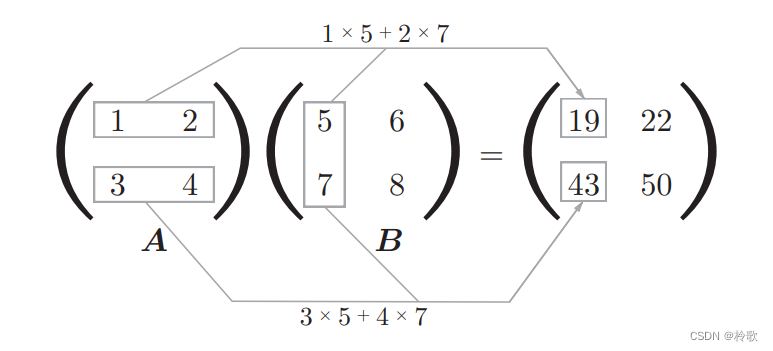
矩阵的乘积是通过左边矩阵的行(横向)和右边矩阵的列(纵向)以对应元素的方式相乘后再求和而得到的。这个运算在Python中可以用如下代码实现:
A = np.array([[1, 2], [3, 4]])
A.shape # (2, 2)
B = np.array([[5, 6], [7, 8]])
B.shape # (2, 2)
np.dot(A, B) # array([[19, 22], [43, 50]]),dot()称为点积运算
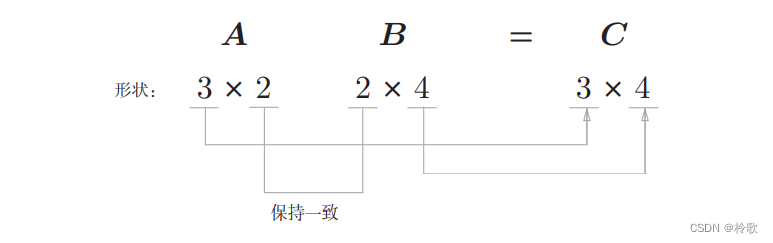
需要注意的是,在多维数组的乘积运算中,必须使两个矩阵中的对应维度的元素个数一致,如下图所示:
下面我们使用NumPy矩阵来实现神经网络。这里我们以下图中的简单神经网络为对象。这个神经网络省略了偏置和激活函数,只有权重:
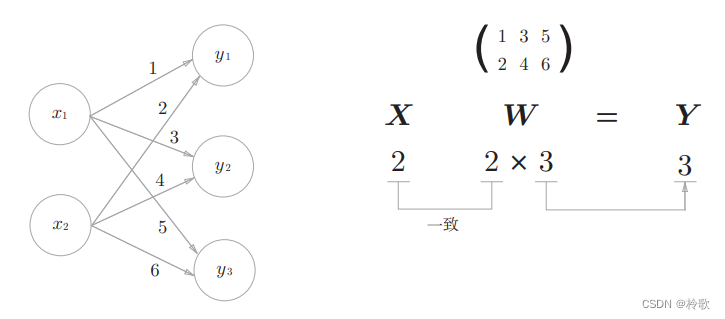
3.4 三层神经网络的实现
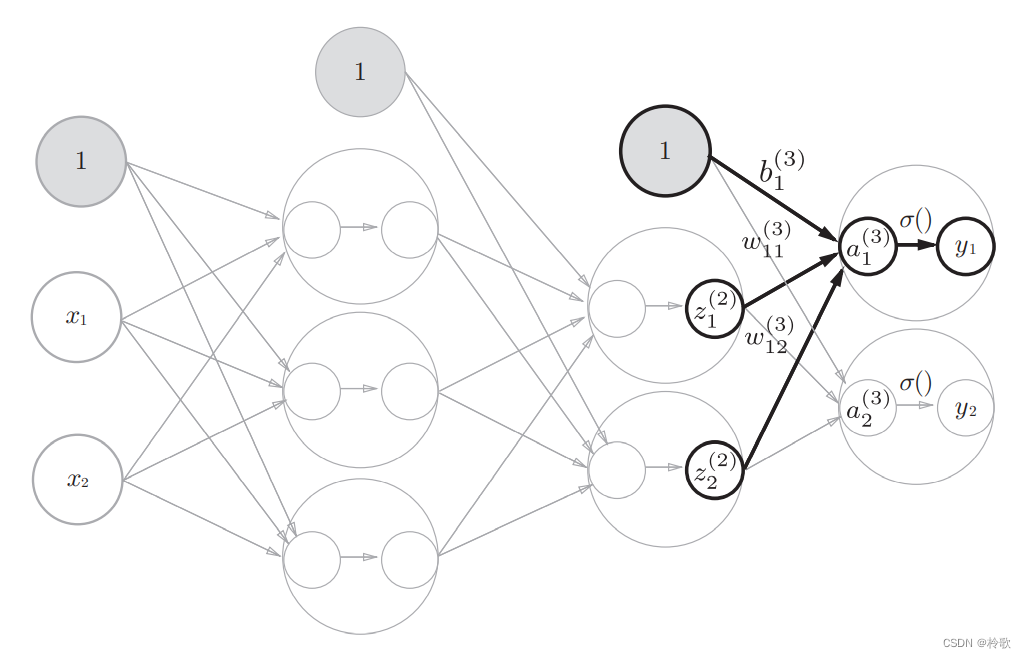
在介绍神经网络中的处理之前,我们先导入 w 12 ( 1 ) w_{12}^{(1)} w12(1)、 a 1 ( 1 ) a_{1}^{(1)} a1(1)等符号。请看下图,下图中只突出显示了从输入层神经元 x 2 x_2 x2到后一层的神经元 a 1 ( 1 ) a_{1}^{(1)} a1(1)的权重。权重和隐藏层的神经元的右上角有一个 “ ( 1 ) ” “(1)” “(1)”,它表示权重和神经元的层号(即第 1 1 1层的权重、第 1 1 1层的神经元)。此外,权重的右下角有两个数字,它们是后一层的神经元和前一层的神经元的索引号。比如, w 12 ( 1 ) w_{12}^{(1)} w12(1)表示前一层的第 2 2 2个神经元 x 2 x_2 x2到后一层的第 1 1 1个神经元 a 1 ( 1 ) a_{1}^{(1)} a1(1)的权重。
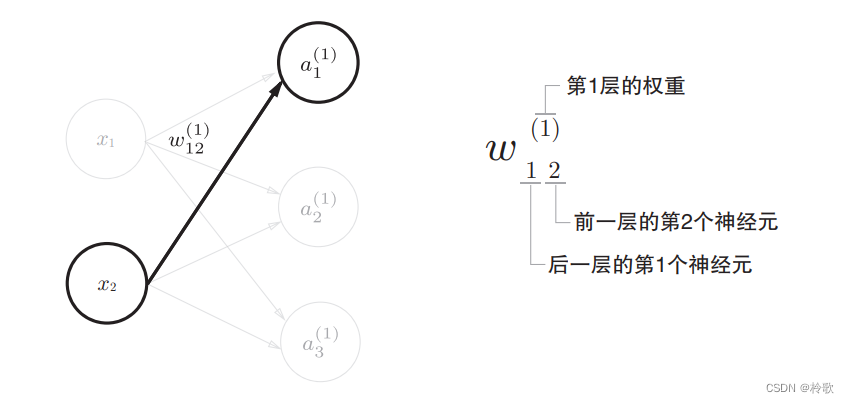
现在看一下从输入层到第 1 1 1层的第 1 1 1个神经元的信号传递过程,如下图所示:

现在用数学式表示 a 1 ( 1 ) a_{1}^{(1)} a1(1)。 a 1 ( 1 ) a_{1}^{(1)} a1(1)通过加权信号和偏置的和按该公式进行计算: a 1 ( 1 ) = w 11 ( 1 ) x 1 + w 12 ( 1 ) x 2 + b 1 ( 1 ) a_{1}^{(1)}=w_{11}^{(1)}x_1+w_{12}^{(1)}x_2+b_{1}^{(1)} a1(1)=w11(1)x1+w12(1)x2+b1(1)。
使用矩阵的乘法运算进行计算的过程如下:
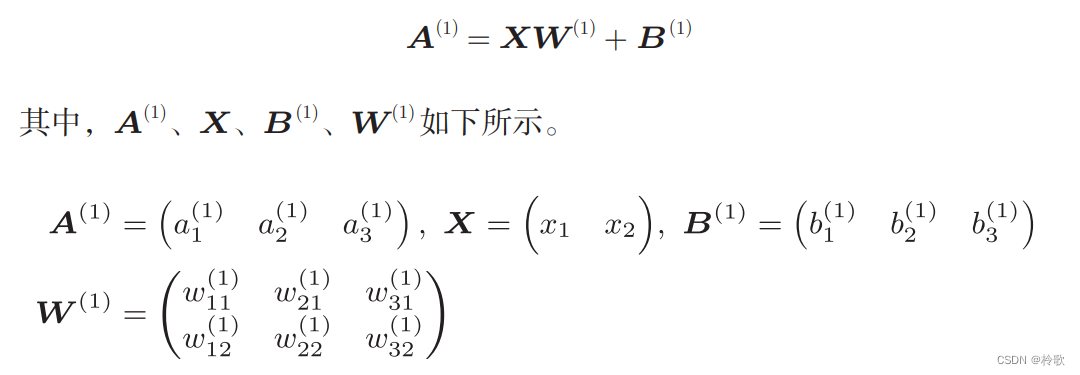
下面我们用NumPy多维数组来实现上式,这里将输入信号、权重、偏置设置成任意值:
X = np.array([1.0, 0.5])
W1 = np.array([[0.1, 0.3, 0.5], [0.2, 0.4, 0.6]])
B1 = np.array([0.1, 0.2, 0.3])
print(W1.shape) # (2, 3)
print(X.shape) # (2,)
print(B1.shape) # (3,)
A1 = np.dot(X, W1) + B1
接下来,我们观察第 1 1 1层中激活函数的计算过程。如果把这个计算过程用图来表示的话,则如下图所示:
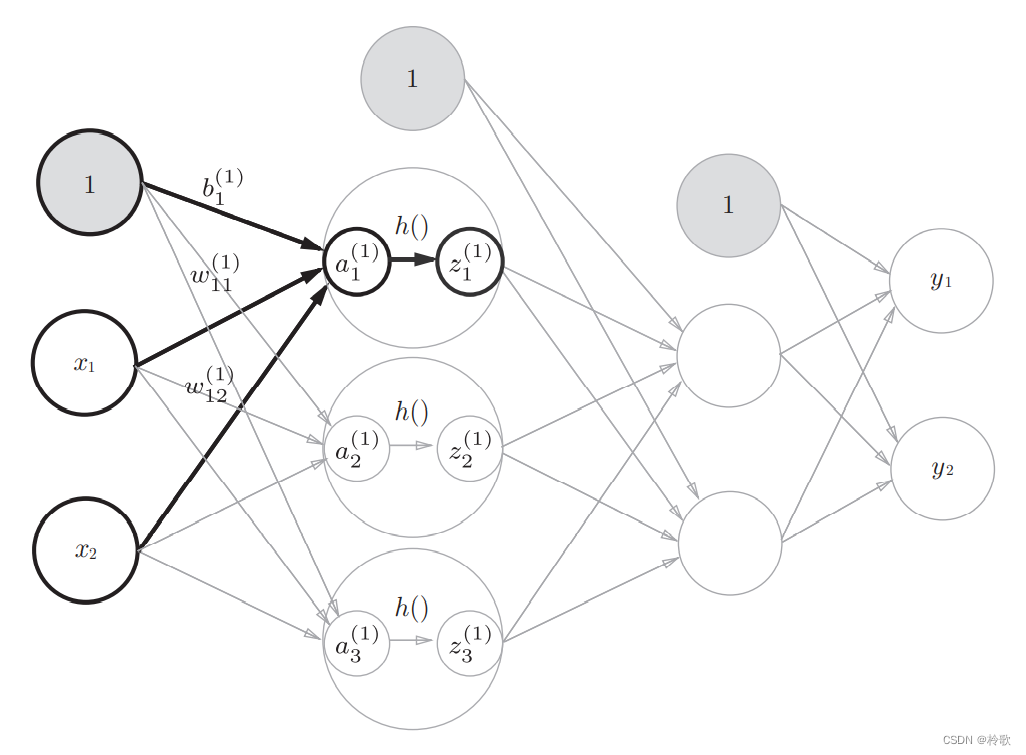
隐藏层的加权和(加权信号和偏置的总和)用 a a a表示,被激活函数转换后的信号用 z z z表示。此外,图中 h ( ) 4 表 示 激 活 函 数 , 这 里 我 们 使 用 的 是 h()4表示激活函数,这里我们使用的是 h()4表示激活函数,这里我们使用的是sigmoid$函数。用Python来实现,代码如下所示:
Z1 = sigmoid(A1)
print(A1) # [0.3, 0.7, 1.1]
print(Z1) # [0.57444252, 0.66818777, 0.75026011]
下面,我们来实现第 1 1 1层到第 2 2 2层的信号传递:
W2 = np.array([[0.1, 0.4], [0.2, 0.5], [0.3, 0.6]])
B2 = np.array([0.1, 0.2])
print(Z1.shape) # (3,)
print(W2.shape) # (3, 2)
print(B2.shape) # (2,)
A2 = np.dot(Z1, W2) + B2
Z2 = sigmoid(A2)
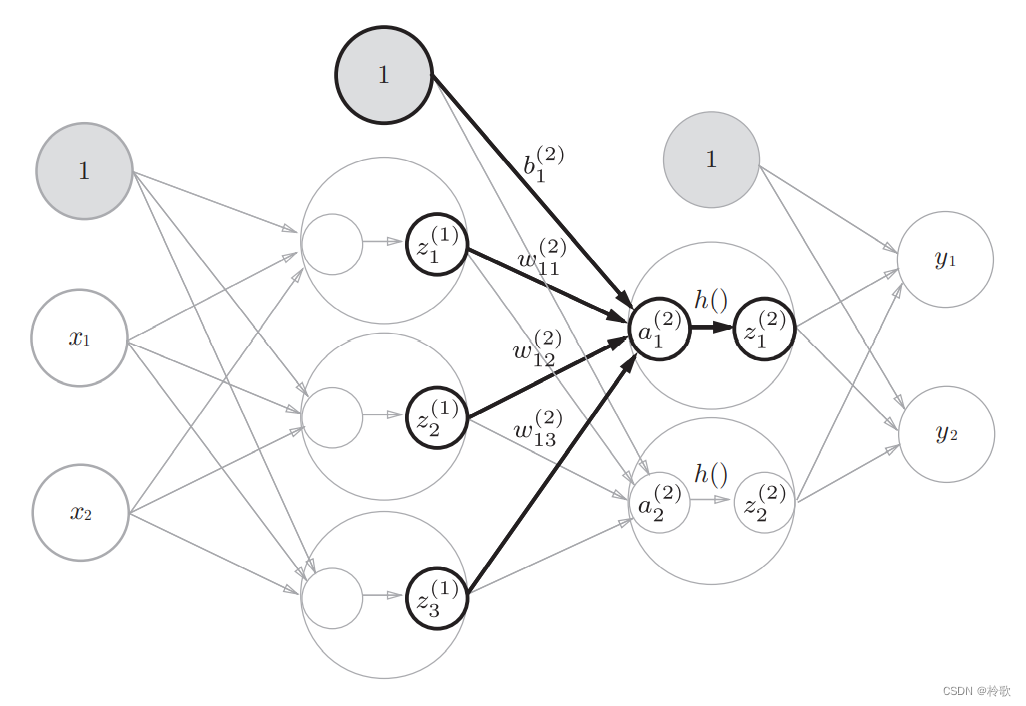
最后是第 2 2 2层到输出层的信号传递。输出层的实现也和之前的实现基本相同。不过,最后的激活函数和之前的隐藏层有所不同。这里我们定义了 i d e n t i t y _ f u n c t i o n ( ) identity\_function() identity_function()函数(也称为“恒等函数”),并将其作为输出层的激活函数。恒等函数会将输入按原样输出,因此,这个例子中没有必要特意定义 i d e n t i t y _ f u n c t i o n ( ) identity\_function() identity_function()。这里这样实现只是为了和之前的流程保持统一。
def identity_function(x):
return x
W3 = np.array([[0.1, 0.3], [0.2, 0.4]])
B3 = np.array([0.1, 0.2])
A3 = np.dot(Z2, W3) + B3
Y = identity_function(A3) # 或者Y = A3
至此,我们已经介绍完了 3 3 3层神经网络的实现。现在我们把之前的代码实现全部整理一下。这里,我们按照神经网络的实现惯例,只把权重记为大写字母 W 1 W1 W1,其他的(偏置或中间结果等)都用小写字母表示。
def init_network():
network = {}
network['W1'] = np.array([[0.1, 0.3, 0.5], [0.2, 0.4, 0.6]])
network['b1'] = np.array([0.1, 0.2, 0.3])
network['W2'] = np.array([[0.1, 0.4], [0.2, 0.5], [0.3, 0.6]])
network['b2'] = np.array([0.1, 0.2])
network['W3'] = np.array([[0.1, 0.3], [0.2, 0.4]])
network['b3'] = np.array([0.1, 0.2])
return network
def forward(network, x):
W1, W2, W3 = network['W1'], network['W2'], network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3']
a1 = np.dot(x, W1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1, W2) + b2
z2 = sigmoid(a2)
a3 = np.dot(z2, W3) + b3
y = identity_function(a3)
return y
network = init_network()
x = np.array([1.0, 0.5])
y = forward(network, x)
print(y) # [ 0.31682708 0.69627909]
3.5 输出层的设计
神经网络可以用在分类问题和回归问题上,不过需要根据情况改变输出层的激活函数。一般而言,回归问题用恒等函数,分类问题用 s o f t m a x softmax softmax函数。
恒等函数会将输入按原样输出,对于输入的信息,不加以任何改动地直接输出。分类问题中使用的 s o f t m a x softmax softmax函数可以用下面的式子表示:
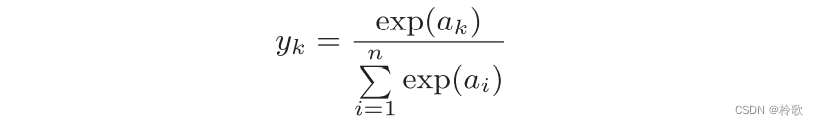
用Python实现:
def softmax(a):
exp_a = np.exp(a)
sum_exp_a = np.sum(exp_a)
y = exp_a / sum_exp_a
return y
观察代码,我们发现由于指数函数存在溢出问题,如果在这些超大值之间进行除法运算,结果会出现“不确定”的情况。因此我们需要对公式进行改进:
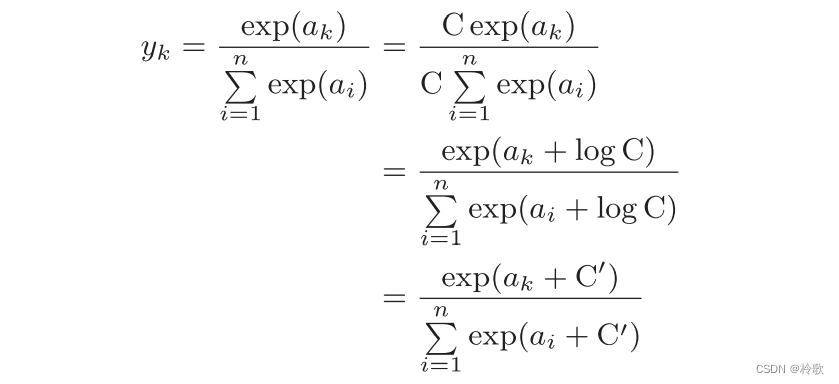
因此在进行 s o f t m a x softmax softmax的指数函数的运算时,加上(或者减去)某个常数并不会改变运算的结果。这里的 C ′ C' C′可以使用任何值,但是为了防止溢出,一般会使用输入信号中的最大值。例如:
a = np.array([1010, 1000, 990])
np.exp(a) / np.sum(np.exp(a)) # softmax函数的运算
# 返回结果为array([nan, nan, nan]),没有被正确计算
c = np.max(a) # 1010
a - c # array([0, -10, -20])
np.exp(a - c) / np.sum(np.exp(a - c))
# 返回结果为array([9.99954600e-01, 4.53978686e-05, 2.06106005e-09])
综上,我们可以像下面这样实现 s o f t m a x softmax softmax函数:
def softmax(a):
c = np.max(a)
exp_a = np.exp(a - c) # 溢出对策
sum_exp_a = np.sum(exp_a)
y = exp_a / sum_exp_a
return y
s o f t m a x softmax softmax函数的输出是 0.0 0.0 0.0到 1.0 1.0 1.0之间的实数。并且, s o f t m a x softmax softmax函数的输出值的总和是 1 1 1。输出总和为 1 1 1是 s o f t m a x softmax softmax函数的一个重要性质。正因为有了这个性质,我们才可以把 s o f t m a x softmax softmax函数的输出解释为“概率”。
输出层的神经元数量需要根据待解决的问题来决定。对于分类问题,输出层的神经元数量一般设定为类别的数量。比如,对于某个输入图像,预测是图中的数字 0 0 0到 9 9 9中的哪一个的问题( 10 10 10类别分类问题),可以像下图这样,将输出层的神经元设定为 10 10 10个(假定 y 2 y_2 y2的输出值最大)。
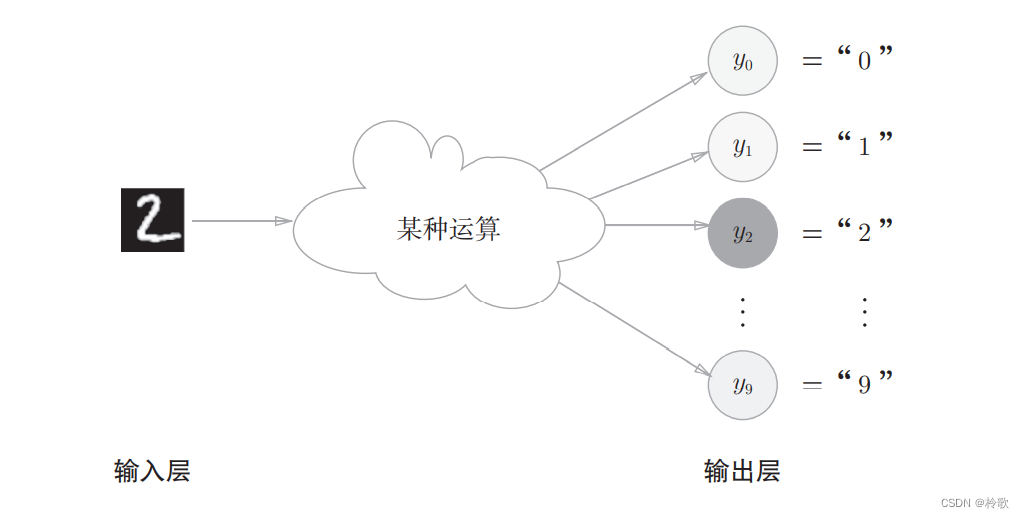
3.6 手写数字识别
假设神经网络的学习已经全部结束,我们使用学习到的参数,先实现神经网络的“推理处理”。这个推理处理也称为神经网络的前向传播。
这里使用的数据集是MNIST手写数字图像集。MNIST是机器学习领域最有名的数据集之一,被应用于从简单的实验到发表的论文研究等各种场合。
MNIST的图像数据是 28 × 28 28\times 28 28×28像素的灰度图像( 1 1 1通道),各个像素的取值在 0 0 0到 255 255 255之间。每个图像数据都相应地标有 “ 7 ” , “ 2 ” , “ 1 ” “7”,“2”,“1” “7”,“2”,“1”等标签。
假设已经提供了便利的Python脚本mnist.py,该脚本支持从下载MNIST数据集到将这些数据转换成NumPy数组等处理,使用mnist.py中的
l
o
a
d
_
m
n
i
s
t
(
)
load\_mnist()
load_mnist()函数,就可以按下述方式轻松读入MNIST数据。
import sys, os
sys.path.append('D:\VS Code Project\Deep Learning') # 为了导入父目录中的文件而进行的设定
from dataset.mnist import load_mnist
# 第一次调用会花费几分钟 ……
(x_train, t_train), (x_test, t_test) = load_mnist(flatten=True, normalize=False)
# 输出各个数据的形状
print(x_train.shape) # (60000, 784)
print(t_train.shape) # (60000,)
print(x_test.shape) # (10000, 784)
print(t_test.shape) # (10000,)
load_mnist函数以(训练图像, 训练标签), (测试图像, 测试标签)的形式返回读入的MNIST数据。此外,还可以像load_mnist(normalize=True, flatten=True, one_hot_label=False)这样,设置
3
3
3个参数。第
1
1
1个参数normalize设置是否将输入图像正规化为
0.0
∼
1.0
0.0\sim 1.0
0.0∼1.0的值。如果将该参数设置为False,则输入图像的像素会保持原来的
0
∼
255
0\sim 255
0∼255。第
2
2
2个参数flatten设置是否展开输入图像(变成一维数组)。如果将该参数设置为False,则输入图像为
1
×
28
×
28
1\times 28\times 28
1×28×28的三维数组;若设置为True,则输入图像会保存为由
784
784
784个元素构成的一维数组。第
3
3
3个参数one_hot_label设置是否将标签保存为
o
n
e
−
h
o
t
one-hot
one−hot表示(
o
n
e
−
h
o
t
r
e
p
r
e
s
e
n
t
a
t
i
o
n
one-hot\ representation
one−hot representation)。
o
n
e
−
h
o
t
one-hot
one−hot表示是仅正确解标签为
1
1
1,其余皆为
0
0
0的数组,就像[0,0,1,0,0,0,0,0,0,0]这样。当one_hot_label为False时,只是像
7
,
2
7,2
7,2这样简单保存正确解标签;当one_hot_label为True时,标签则保存为
o
n
e
−
h
o
t
one-hot
one−hot表示。
接下来使用PIL模块显示训练图像的第一张图像:
import sys, os
sys.path.append('D:\VS Code Project\Deep Learning')
import numpy as np
from dataset.mnist import load_mnist
from PIL import Image
def img_show(img):
pil_img = Image.fromarray(np.uint8(img))
pil_img.show()
(x_train, t_train), (x_test, t_test) = load_mnist(flatten=True, normalize=False)
img = x_train[0]
label = t_train[0]
print(label) # 5
print(img.shape) # (784,)
img = img.reshape(28, 28) # 把图像的形状变成原来的尺寸
print(img.shape) # (28, 28)
img_show(img)
显示结果如下图所示:
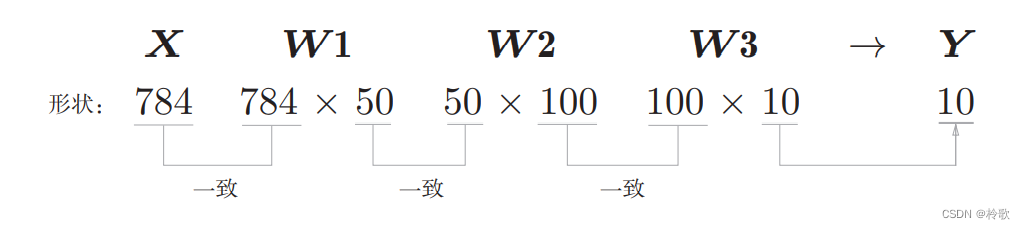
神经网络的输入层有 784 784 784个神经元,输出层有 10 10 10个神经元。输入层的 784 784 784这个数字来源于图像大小的 28 × 28 = 784 28\times 28=784 28×28=784,输出层的 10 10 10这个数字来源于 10 10 10类别分类(数字 0 ∼ 9 0\sim 9 0∼9,共 10 10 10类别)。此外,这个神经网络有 2 2 2个隐藏层,第 1 1 1个隐藏层有 50 50 50个神经元,第 2 2 2个隐藏层有 100 100 100个神经元。这个 50 50 50和 100 100 100可以设置为任何值。
下面我们先定义 3 3 3个函数:
def get_data():
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, flatten=True, one_hot_label=False)
return x_test, t_test
def init_network():
with open("sample_weight.pkl", 'rb') as f:
network = pickle.load(f)
return network
def predict(network, x):
W1, W2, W3 = network['W1'], network['W2'], network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3']
a1 = np.dot(x, W1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1, W2) + b2
z2 = sigmoid(a2)
a3 = np.dot(z2, W3) + b3
y = softmax(a3)
return y
init_network()会读入保存在pickle文件sample_weight.pkl中的学习到的权重参数
A
A
A。这个文件中以字典变量的形式保存了权重和偏置参数。剩余的
2
2
2个函数和前面介绍的代码实现基本相同,无需再解释。现在,我们用这
3
3
3个函数来实现神经网络的推理处理,并评价它的识别精度:
x, t = get_data()
network = init_network()
accuracy_cnt = 0
for i in range(len(x)): # 逐一取出保存在x中的图像数据
y = predict(network, x[i])
p = np.argmax(y) # 获取概率最高的元素的索引
if p == t[i]:
accuracy_cnt += 1
print("Accuracy:" + str(float(accuracy_cnt) / len(x)))
# Accuracy:0.9352
下面我们使用Python解释器,输出刚才的神经网络的各层的权重的形状:
x, _ = get_data()
network = init_network()
W1, W2, W3 = network['W1'], network['W2'], network['W3']
x.shape # (10000, 784)
x[0].shape # (784,)
W1.shape # (784, 50)
W2.shape # (50, 100)
W3.shape # (100, 10)
确认矩阵的形状:
现在我们来考虑打包输入多张图像的情形。比如,我们想用predict()函数一次性打包处理
100
100
100张图像。为此,可以把
x
x
x的形状改为
100
×
784
100\times 784
100×784,将
100
100
100张图像打包作为输入数据,这种打包式的输入数据称为批(
b
a
t
c
h
batch
batch)。批有“捆”的意思,图像就如同纸币一样扎成一捆,如下图所示:
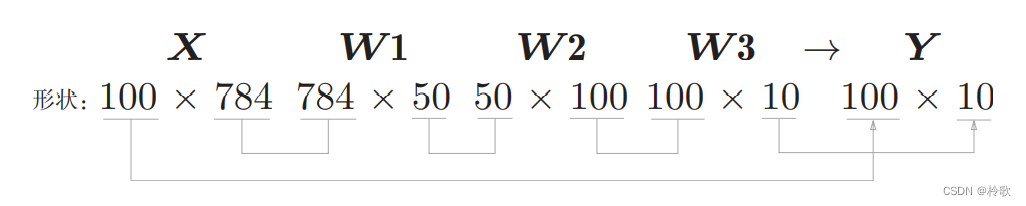
下面我们进行基于批处理的代码实现:
x, t = get_data()
network = init_network()
batch_size = 100 # 批数量
accuracy_cnt = 0
for i in range(0, len(x), batch_size):
x_batch = x[i:i + batch_size]
y_batch = predict(network, x_batch)
p = np.argmax(y_batch, axis=1)
accuracy_cnt += np.sum(p == t[i:i + batch_size])
print("Accuracy:" + str(float(accuracy_cnt) / len(x)))
下一节:【学习笔记】深度学习入门:基于Python的理论与实现-神经网络的学习。



![[附源码]计算机毕业设计springboot软考刷题小程序](https://img-blog.csdnimg.cn/fb3d8bed9fd749edb1bfb20ebc6d4bf1.png)


![[附源码]Python计算机毕业设计Django电子相册管理系统](https://img-blog.csdnimg.cn/d3ad9bd6b6b54007ace2b9f776e4ca8d.png)


![[附源码]Python计算机毕业设计Django高校后勤保障系统](https://img-blog.csdnimg.cn/8d90f89c48124768b2cb8a1cbda4914d.png)

