目录
1、混淆矩阵
2、代码实现
2.1、OA
2.2、AA
2.3、kappa
2.4、用户精度(User Accuracy, UA)
2.5、生产者精度(Producer Accuracy, PA)
2.6、f1_score
2.7、混淆矩阵
2.8、分类报告
1、混淆矩阵
以二分类问题为例,混淆矩阵表现形式如下:

- TP(True Positive,真正例):将真实情况为正例的类型正确地预测为正例
- FN(False Negative,假反例):将真实情况为正例的类型错误地预测为反例
- FP(False Positive,假正例):将真实情况为反例的类型错误地预测为正例
- TN(True Negative,真反例):将真实情况为反例的类型正确地预测为反例


2、代码实现
2.1、OA
- 总体准确度(OA)—表示总测试样本中正确分类的样本数
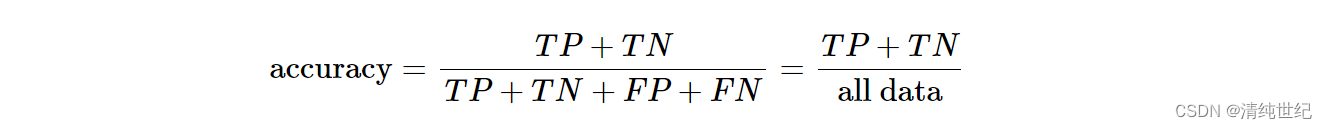
import numpy as np
from sklearn.metrics import accuracy_score
y_test = np.array([0,1,1,2,2,0,0,1,2,3,3,2,3,1,0,3,1,2,3,3,2,0,])
y_predict = np.array([1,1,0,2,2,2,0,2,0,3,0,2,3,1,0,2,1,2,1,3,1,3,])
# 也叫准确率
OA = accuracy_score(y_test, y_predict)
print(OA)2.2、AA
- 平均准确度(AA)—表示分类精度的平均值
import numpy as np
from sklearn.metrics import recall_score
y_test = np.array([0,1,1,2,2,0,0,1,2,3,3,2,3,1,0,3,1,2,3,3,2,0,])
y_predict = np.array([1,1,0,2,2,2,0,2,0,3,0,2,3,1,0,2,1,2,1,3,1,3,])
# 当average=None时,计算的是每一个类别的精度。也相当于生产者精度
# 也叫召回率
AA = recall_score(y_test, y_predict,average='macro')
print(AA)2.3、kappa
- kappa系数(kappa)提供了关于地面真值图和分类图之间的强一致性的相互信息
import numpy as np
from sklearn.metrics import cohen_kappa_score
y_test = np.array([0,1,1,2,2,0,0,1,2,3,3,2,3,1,0,3,1,2,3,3,2,0,])
y_predict = np.array([1,1,0,2,2,2,0,2,0,3,0,2,3,1,0,2,1,2,1,3,1,3,])
kappa = cohen_kappa_score(y_test, y_predict)
print(kappa)2.4、用户精度(User Accuracy, UA)
import numpy as np
from sklearn.metrics import precision_score
y_test = np.array([0,1,1,2,2,0,0,1,2,3,3,2,3,1,0,3,1,2,3,3,2,0,])
y_predict = np.array([1,1,0,2,2,2,0,2,0,3,0,2,3,1,0,2,1,2,1,3,1,3,])
# 当average='macro'时,计算的是平均的用户精度(UA)
# 也叫精确率
UA = precision_score(y_test, y_predict,average=None)
print(UA)2.5、生产者精度(Producer Accuracy, PA)
import numpy as np
from sklearn.metrics import recall_score
y_test = np.array([0,1,1,2,2,0,0,1,2,3,3,2,3,1,0,3,1,2,3,3,2,0,])
y_predict = np.array([1,1,0,2,2,2,0,2,0,3,0,2,3,1,0,2,1,2,1,3,1,3,])
# 当average='macro'时,计算的是平均的生产者精度(PA)。也相当于是每个类别的精度
PA = recall_score(y_test, y_predict,average=None)
print(PA)2.6、f1_score


import numpy as np
from sklearn.metrics import f1_score
y_test = np.array([0,1,1,2,2,0,0,1,2,3,3,2,3,1,0,3,1,2,3,3,2,0,])
y_predict = np.array([1,1,0,2,2,2,0,2,0,3,0,2,3,1,0,2,1,2,1,3,1,3,])
# 当average=None时,计算的每个类别的f1_score
f1_s = f1_score(y_test, y_predict,average="macro")
print(f1_s)2.7、混淆矩阵
import numpy as np
from sklearn.metrics import confusion_matrix
y_test = np.array([0,1,1,2,2,0,0,1,2,3,3,2,3,1,0,3,1,2,3,3,2,0,])
y_predict = np.array([1,1,0,2,2,2,0,2,0,3,0,2,3,1,0,2,1,2,1,3,1,3,])
matrix = confusion_matrix(y_test, y_predict)
print(matrix)2.8、分类报告
import numpy as np
from sklearn.metrics import classification_report
y_test = np.array([0,1,1,2,2,0,0,1,2,3,3,2,3,1,0,3,1,2,3,3,2,0,])
y_predict = np.array([1,1,0,2,2,2,0,2,0,3,0,2,3,1,0,2,1,2,1,3,1,3,])
report = classification_report(y_test, y_predict, digits=4)
print(report)




![Prompt learning 教学[基础篇]:prompt基本原则以及使用场景技巧助力你更好使用chatgpt,得到你想要的答案](https://img-blog.csdnimg.cn/img_convert/cd93c27a13c217e61c77559a5d1d0010.png)