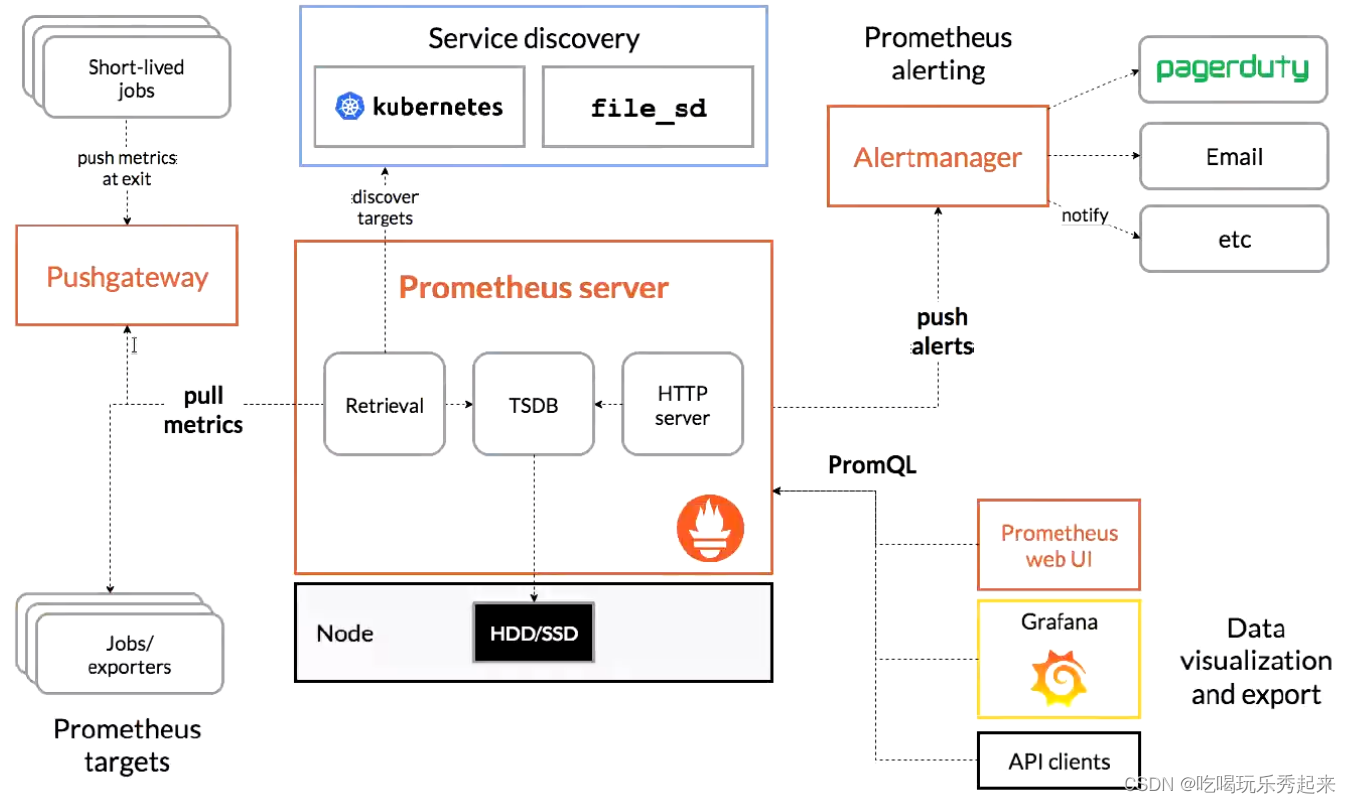
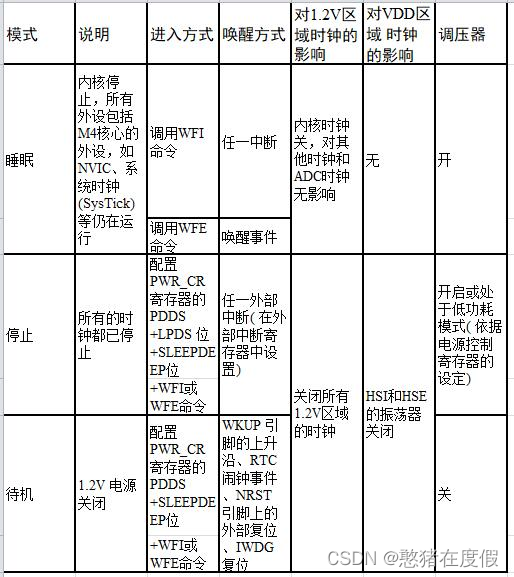
对于一个单线程进程来说,它不需要处理线程同步的问题,所以线程同步是在多线程环境下需要注意的问题。线程的主要优势在于,资源的共享性,譬如通过全局变量来实现信息共享,不过这种便捷的共享是有代价的,那就是多个线程并发访问共享数据所导致的数据不一 致的问题。
为什么需要线程同步?
线程同步是为了对共享资源的访问进行保护。这里说的共享资源指的是多个线程都会进行访问的资源, 譬如定义了一个全局变量 a,线程 1 访问了变量 a、同样在线程 2 中也访问了变量 a,那么此时变量 a 就是多个线程间的共享资源,大家都要访问它。
保护的目的是为了解决数据一致性的问题。当然什么情况下才会出现数据一致性的问题,根据不同的情况进行区分;如果每个线程访问的变量都是其它线程不会读取和修改的(譬如线程函数内定义的局部变量或者只有一个线程访问的全局变量),那么就不存在数据一致性的问题;同样,如果变量是只读的,多个线程同时读取该变量也不会有数据一致性的问题;但是,当一个线程可以修改的变量,其它的线程也可以读取或者修改的时候,这个时候就存在数据一致性的问题,需要对这些线程进行同步操作,确保它们在访问变量的存储内容时不会访问到无效的值。
出现数据一致性问题其本质在于进程中的多个线程对共享资源的并发访问(同时访问)。前面给大家介绍了,进程中的多个线程间是并发执行的,每个线程都是系统调用的基本单元,参与到系统调度队列中; 对于多个线程间的共享资源,并发执行会导致对共享资源的并发访问,并发访问所带来的问题就是竞争,因此可能会出现数据一致性问题,所以就需要解决这个问题;要防止并发访问共享资源,那么就需要对共享资源的访问进行保护,防止出现并发访问共享资源。
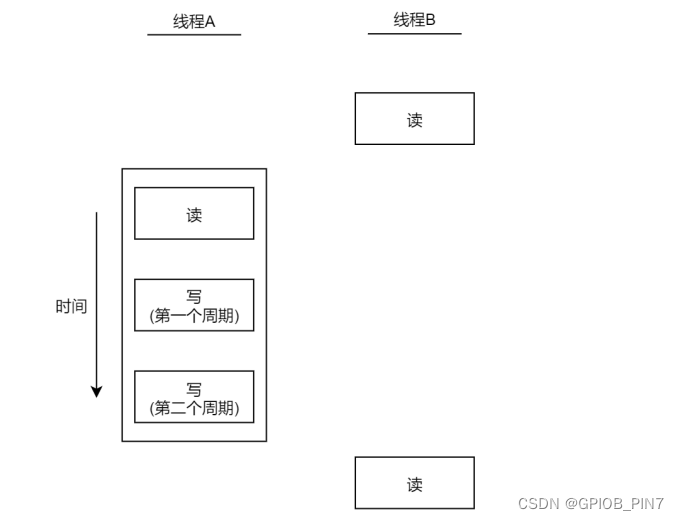
当一个线程修改变量时,其它的线程在读取这个变量时可能会看到不一致的值,下图描述了两个线程读写相同变量(共享变量、共享资源)的假设例子。在这个例子当中,线程 A 读取变量的值,然后再给这个变量赋予一个新的值,但写操作需要 2 个时钟周期(这里只是假设);当线程 B 在这两个写周期中间读取了这个变量,它就会得到不一致的值,这就出现了数据不一致的问题。

我们可以编写一个简单地代码对此文件进行测试,2 个线程在常规方式下访问共享资源,这里的共享资源指的就是静态全局变量 g_count。该程序创建了两个线程,且均执行同一个函 数,该函数执行一个循环,重复以下步骤:将全局变量 g_count 复制到本地变量 l_count 变量中,然后递增 l_count,再把 l_count 复制回 g_count,以此不断增加全局变量 g_count 的值。因为 l_count 是分配于线程栈中的自动变量(函数内定义的局部变量),所以每个线程都有一份。循环重复的次数要么由命令行参数指定, 要么去默认值 1000 万次,循环结束之后线程终止,主线程回收两个线程之后,再将全局变量 g_count 的值打印出来。
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#include <unistd.h>
#include <string.h>
static int g_count = 0;
static void *new_thread_start(void *arg){
int loops = *((int *)arg);
int l_count, j;
for (j = 0; j < loops; j++) {
l_count = g_count;
l_count++;
g_count = l_count;
}
return (void *)0;
}
static int loops;
int main(int argc, char *argv[]){
pthread_t tid1, tid2;
int ret;
/* 获取用户传递的参数 */
if (2 > argc)
loops = 10000000; //没有传递参数默认为 1000 万次
else
loops = atoi(argv[1]);
/* 创建 2 个新线程 */
ret = pthread_create(&tid1, NULL, new_thread_start, &loops);
if (ret) {
fprintf(stderr, "pthread_create error: %s\n", strerror(ret));
exit(-1);
}
ret = pthread_create(&tid2, NULL, new_thread_start, &loops);
if (ret) {
fprintf(stderr, "pthread_create error: %s\n", strerror(ret));
exit(-1);
}
/* 等待线程结束 */
ret = pthread_join(tid1, NULL);
if (ret) {
fprintf(stderr, "pthread_join error: %s\n", strerror(ret));
exit(-1);
}
ret = pthread_join(tid2, NULL);
if (ret) {
fprintf(stderr, "pthread_join error: %s\n", strerror(ret));
exit(-1);
}
/* 打印结果 */
printf("g_count = %d\n", g_count);
exit(0);
}编译代码,进行测试,首先执行代码,传入参数 1000,也就是让每个线程对全局变量 g_count 递增 1000 次,如下所示:
![]()
从打印结果看,得到了我们想象中的结果,每个线程递增 1000 次,最后的数值就是 2000;接着我们把递增次数加大,采用默认值 1000 万次,如下所示:

可以发现,结果竟然不是我们想看到的样子,执行到最后,应该是 2000 万才对,这里其实就出现了上文提到的问题,数据不一致。
如何解决对共享资源的并发访问出现数据不一致的问题?
为了解决数据不一致的问题,就得需要 Linux 提供的一些方法,也就是接下来将要向大家介绍的线程同步技术,来实现同一时间只允许一个线程访问该变量,防止出现并发访问的情况、消除数据不一致的问题,下图描述了这种同步操作,从图中可知,线程 A 和线程 B 都不会同时访问这个变量,当线程 A 需要修改变量的值时,必须等到写操作完成之后(不能打断它的操作),才运行线程 B 去读取。
线程的主要优势在于,资源的共享性,譬如通过全局变量来实现信息共享。不过这种便捷的共享是有代价的,必须确保多个线程不会同时修改同一变量、或者某一线程不会读取正由其它线程修改的变量,也就是必须确保不会出现对共享资源的并发访问。Linux 系统提供了多种用于实现线程同步的机制,常见的方法有: 互斥锁、条件变量、自旋锁以及读写锁等,将在后续介绍










![Melis4.0[D1s]:8.显示测试:图片格式和透明度](https://img-blog.csdnimg.cn/189f7addd9b949488efb8e9c403fd60c.png)