note
文章目录
- note
- 零、AIGC生成式模型
- 1. 核心要素
- 2. LLM evolutionary tree
- 3. 几个bigScience里的概念
- 二、LLM大模型
- 1. ChatGLM
- (1)GLM-130B
- (2)ChatGLM-6B
- 2. LLaMA
- 3. RoBERTa
- 4. Bloom
- 5. PaLM
- 三、模型指令微调
- 1. 指令微调的注意事项
- 2. prompt tuning
- 3. prefix tuning
- 5. LoRA模型微调
- 6. p-tuning
- 四、微调模型的应用
- 1. 基于微调的医学问诊模型HuaTuo
- 2. Chinese-LLaMA-Alpace中文模型
- Reference
零、AIGC生成式模型
1. 核心要素
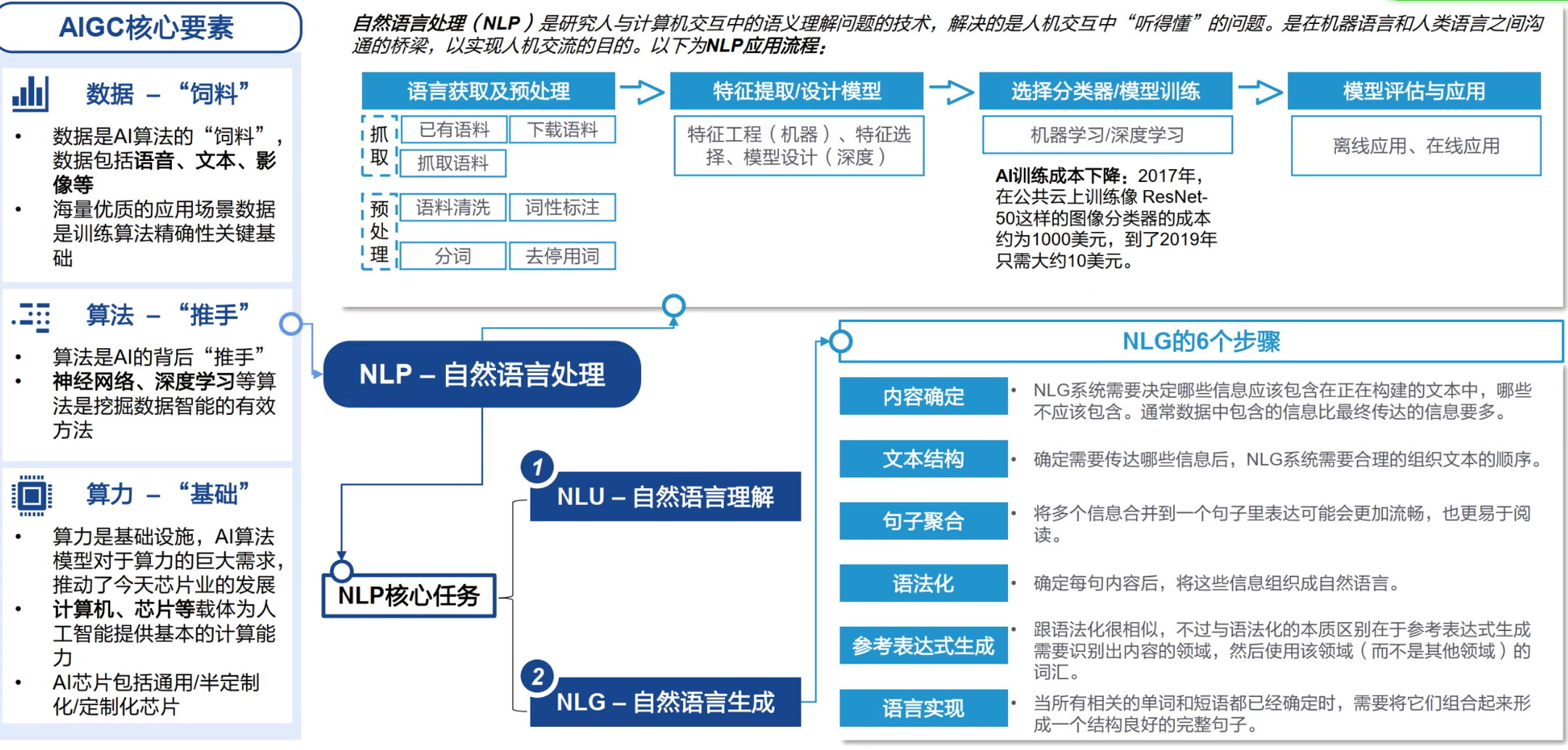
AIGC模型:
NLP:GPT、chatGLM、其他常见LLM模型参考下图
CV:stable diffusion等
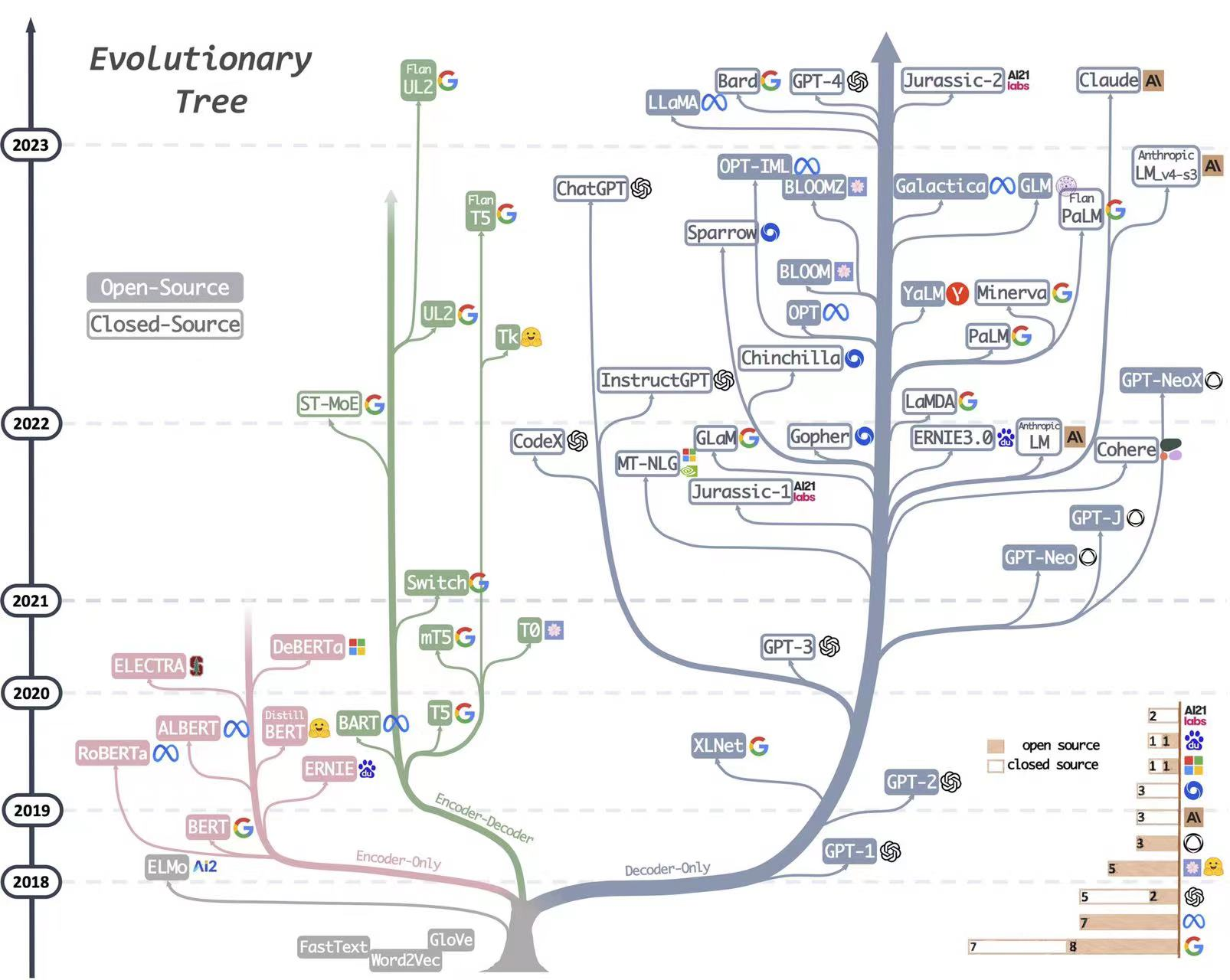
2. LLM evolutionary tree
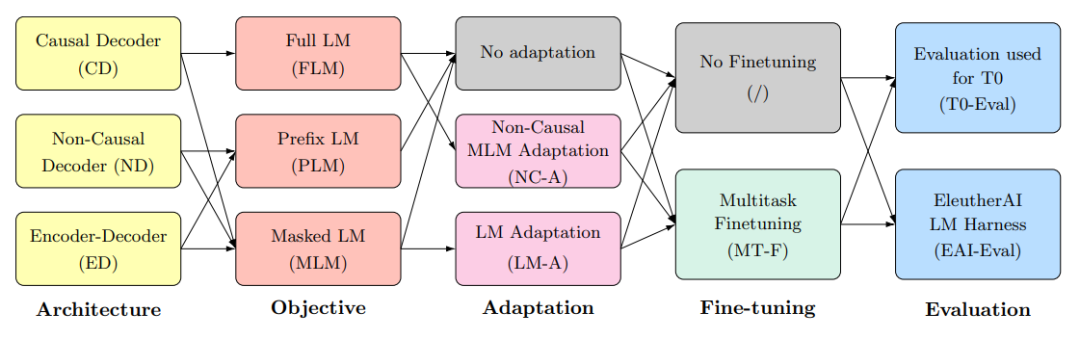
3. 几个bigScience里的概念
- 架构:自回归、非自回归、编码器-解码器
- 目标:全语言模型、前缀语言模型、掩码语言模型
- 适配器:不添加适配器、将自回归模型用于掩码目标训练的适配器、将掩码为目标的模型转化为纯语言模型目标
- 是否经过多任务微调
- 评估数据集:EAI-Eval、T0-Eval
二、LLM大模型
- 当前主流的大预言模型都是decoder-only结构
- OPT、BLOOM、LLaMA 三个模型是主要面向开源促进研究和应用的,中文开源可用的是 GLM,后续很多工作都是在这些开源的基础模型上进行微调优化的
1. ChatGLM
(1)GLM-130B
ChatGLM 参考了 ChatGPT 的设计思路,在千亿基座模型 GLM-130B中注入了代码预训练,通过有监督微调(Supervised Fine-Tuning)等技术实现人类意图对齐。ChatGLM 当前版本模型的能力提升主要来源于独特的千亿基座模型 GLM-130B。它是不同于 BERT、GPT-3 以及 T5 的架构,是一个包含多目标函数的自回归预训练模型。2022年8月,向研究界和工业界开放了拥有1300亿参数的中英双语稠密模型 GLM-130B,该模型有一些独特的优势:
- 双语: 同时支持中文和英文。
- 高精度(英文): 在公开的英文自然语言榜单 LAMBADA、MMLU 和 Big-bench-lite 上优于 GPT-3 175B(API: davinci,基座模型)、OPT-175B 和 BLOOM-176B。
- 高精度(中文): 在7个零样本 CLUE 数据集和5个零样本 FewCLUE 数据集上明显优于 ERNIE TITAN 3.0 260B 和 YUAN 1.0-245B。
- 快速推理: 首个实现 INT4 量化的千亿模型,支持用一台 4 卡 3090 或 8 卡 2080Ti 服务器进行快速且基本无损推理。
- 可复现性: 所有结果(超过 30 个任务)均可通过我们的开源代码和模型参数复现。
- 跨平台: 支持在国产的海光 DCU、华为昇腾 910 和申威处理器及美国的英伟达芯片上进行训练与推理。
(2)ChatGLM-6B
ChatGLM-6B 是一个具有62亿参数的中英双语语言模型。通过使用与 ChatGLM(chatglm.cn)相同的技术,ChatGLM-6B 初具中文问答和对话功能,并支持在单张 2080Ti 上进行推理使用。具体来说,ChatGLM-6B 有如下特点:
- 充分的中英双语预训练: ChatGLM-6B 在 1:1 比例的中英语料上训练了 1T 的 token 量,兼具双语能力。
- 优化的模型架构和大小: 吸取 GLM-130B 训练经验,修正了二维 RoPE 位置编码实现,使用传统FFN结构。6B(62亿)的参数大小,也使得研究者和个人开发者自己微调和部署 ChatGLM-6B 成为可能。
- 较低的部署门槛: FP16 半精度下,ChatGLM-6B 需要至少 13GB 的显存进行推理,结合模型量化技术,这一需求可以进一步降低到 10GB(INT8) 和 6GB(INT4), 使得 ChatGLM-6B 可以部署在消费级显卡上。
- 更长的序列长度: 相比 GLM-10B(序列长度1024),ChatGLM-6B 序列长度达 2048,支持更长对话和应用。
- 人类意图对齐训练: 使用了监督微调(Supervised Fine-Tuning)、反馈自助(Feedback Bootstrap)、人类反馈强化学习(Reinforcement Learning from Human Feedback) 等方式,使模型初具理解人类指令意图的能力。输出格式为 markdown,方便展示。
因此,ChatGLM-6B 具备了一定条件下较好的对话与问答能力。当然,ChatGLM-6B 也有相当多已知的局限和不足:
- 模型容量较小: 6B 的小容量,决定了其相对较弱的模型记忆和语言能力。在面对许多事实性知识任务时,ChatGLM-6B 可能会生成不正确的信息;她也不擅长逻辑类问题(如数学、编程)的解答。
- 可能会产生有害说明或有偏见的内容:ChatGLM-6B 只是一个初步与人类意图对齐的语言模型,可能会生成有害、有偏见的内容。
- 较弱的多轮对话能力:ChatGLM-6B 的上下文理解能力还不够充分,在面对长答案生成,以及多轮对话的场景时,可能会出现上下文丢失和理解错误的情况。
- 英文能力不足:训练时使用的指示大部分都是中文的,只有一小部分指示是英文的。因此在使用英文指示时,回复的质量可能不如中文指示的回复,甚至与中文指示下的回复矛盾。
- 易被误导:ChatGLM-6B 的“自我认知”可能存在问题,很容易被误导并产生错误的言论。例如当前版本模型在被误导的情况下,会在自我认知上发生偏差。即使该模型经过了1万亿标识符(token)左右的双语预训练,并且进行了指令微调和人类反馈强化学习(RLHF),但是因为模型容量较小,所以在某些指示下可能会产生有误导性的内容。
2. LLaMA
LLaMA-7B
ChatGLM-6B是Prefix LM(PLM),LLaMA-7B是Causal LM(CLM)。
(参考google的论文《UL2: Unifying Language Learning Paradigms》)
LLaMA 是 Meta AI 发布的包含 7B、13B、33B 和 65B 四种参数规模的基础语言模型集合,LLaMA-13B 仅以 1/10 规模的参数在多数的 benchmarks 上性能优于 GPT-3(175B),LLaMA-65B 与业内最好的模型 Chinchilla-70B 和 PaLM-540B 比较也具有竞争力。
链接:https://github.com/facebookresearch/llama
3. RoBERTa
源码:https://github.com/pytorch/fairseq
论文:https://arxiv.org/pdf/1907.11692.pdf
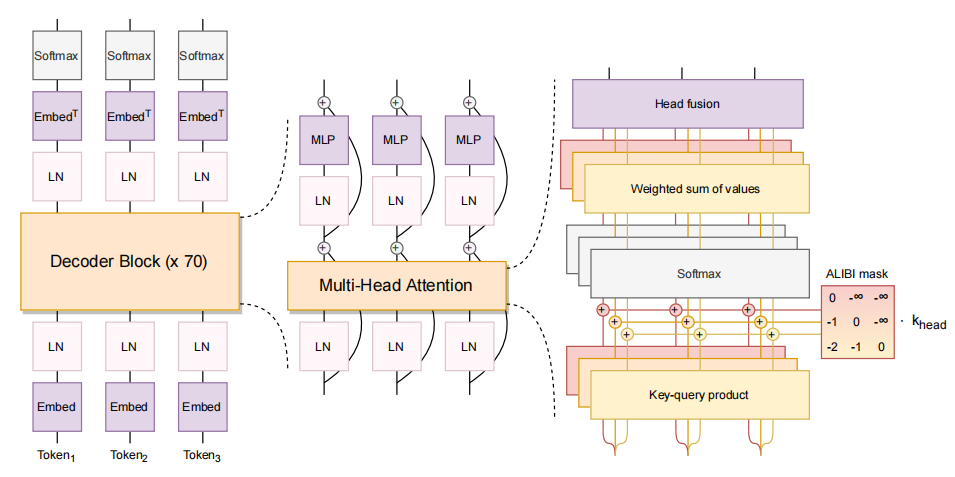
4. Bloom
- BLOOM 是 BigScience(一个围绕研究和创建超大型语言模型的开放协作研讨会)中数百名研究人员合作设计和构建的 176B 参数开源大语言模型,同时,还开源了BLOOM-560M、BLOOM-1.1B、BLOOM-1.7B、BLOOM-3B、BLOOM-7.1B 其他五个参数规模相对较小的模型。
- BLOOM 是一种 decoder-only 的 Transformer 语言模型,它是在 ROOTS 语料库上训练的,该数据集包含 46 种自然语言和 13 种编程语言(总共 59 种)的数百个数据来源。
- 链接:https://huggingface.co/bigscience
5. PaLM
PaLM 是使用谷歌提出的 Pathways[10] 系统(一种新的 ML 系统,可以跨多个 TPU Pod 进行高效训练)在 6144 块TPU v4 芯片上训练完成的。作者在 Pod 级别上跨两个 Cloud TPU v4 Pods 使用数据并行对训练进行扩展,与以前的大多数 LLM 相比,是一个显著的规模增长。
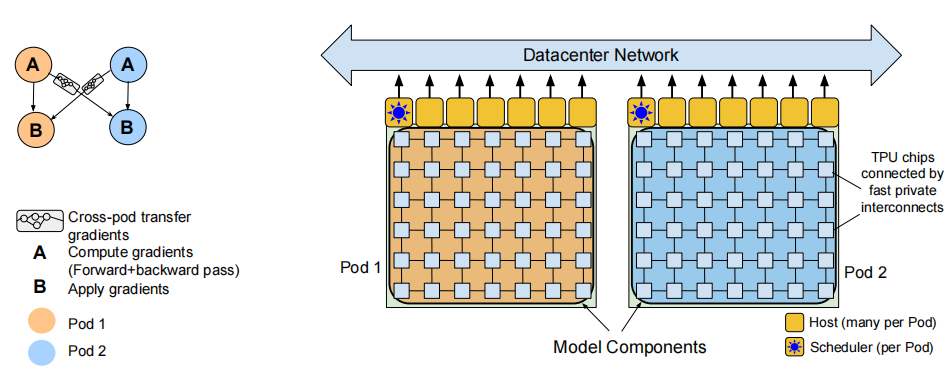
三、模型指令微调
1. 指令微调的注意事项

- 高效指令微调:ChatGLM-6B官方支持的p-tuning-v2,以及最常见的LoRA方式都可以微调,节省显存又高效。
- 参数微调后的常见问题:原有能力可能受损,或循环输出重复文本
- 微调后,可以合并模型为单一模型:根据LoRA的论文,训练得到低秩的权重delta矩阵,所以支持合并
- finetune阶段的batch size通常远小于pretrain阶段,微调的数据量也远小于预训练的数据量。(参考MPT-7B模型的实验)
- 基于LLM大模型构建应用:llama-index(原gpt-index)做文档式的对话系统。或者使用MOSS的思路,把大语言模型做成各种插件
2. prompt tuning

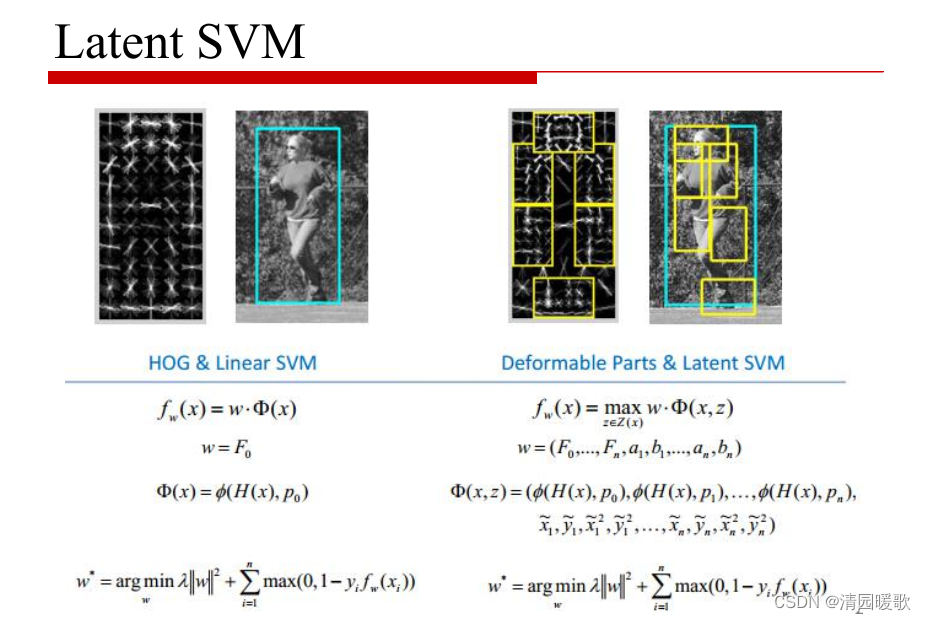
固定预训练参数,为每一个任务额外添加一个或多个embedding,之后拼接query正常输入LLM,并只训练这些embedding。左图为单任务全参数微调,右图为prompt tuning。
prompt tuning将fine tune任务转为mlm任务。自动学习模板:离散的主要包括 Prompt Mining, Prompt Paraphrasing, Gradient-based Search, Prompt Generation 和 Prompt Scoring;连续的则主要包括Prefix Tuning, Tuning Initialized with Discrete Prompts 和 Hard-Soft Prompt Hybrid Tuning。
正常微调举例:[cls]今天天上都出太阳了,阳光明媚。[SEP]
prompt输入举例:[cls]今天天气是[MASK]。[SEP] 今天天上都出太阳了,阳光明媚。[SEP]
from peft import PromptTuningConfig, get_peft_model
model_name_or_path = "./unsup-simcse-roberta-base"
peft_type = PeftType.PROMPT_TUNING
lr = 1e-3
peft_config = PromptTuningConfig(task_type="SEQ_CLS", num_virtual_tokens=10)
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, return_dict=True)
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()
3. prefix tuning
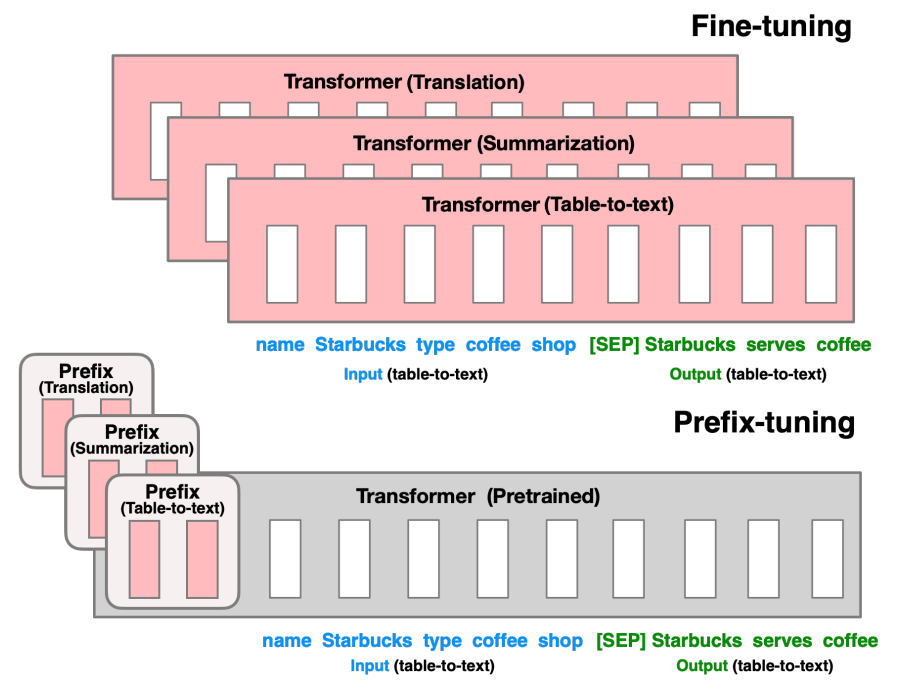
prefix tuning还是固定预训练参数,但除为每一个任务额外添加一个或多个embedding之外,利用多层感知编码prefix,注意多层感知机就是prefix的编码器,不再像prompt tuning继续输入LLM。
embedding = torch.nn.Embedding(num_virtual_tokens, token_dim)
transform = torch.nn.Sequential(
torch.nn.Linear(token_dim, encoder_hidden_size),
torch.nn.Tanh(),
torch.nn.Linear(encoder_hidden_size, num_layers * 2 * token_dim),
)
5. LoRA模型微调

LoRA冻结了预训练模型的参数,并在每一层decoder中加入dropout+Linear+Conv1d额外的参数。
model_name_or_path = "./unsup-simcse-roberta-base"
peft_type = peft_type = PeftType.LORA
lr = 3e-4
peft_config = LoraConfig(task_type="SEQ_CLS", inference_mode=False, r=8, lora_alpha=16, lora_dropout=0.1)
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, return_dict=True)
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()
6. p-tuning
p-tuning依然是固定LLM参数,利用多层感知机和LSTM对prompt进行编码,编码之后与其他向量进行拼接之后正常输入LLM。
chatglm使用p tuning v2微调代码:https://github.com/THUDM/ChatGLM-6B/tree/main/ptuning
参考:大模型微调之P-tuning方法解析
self.lstm_head = torch.nn.LSTM(
input_size=self.input_size,
hidden_size=self.hidden_size,
num_layers=num_layers,
dropout=lstm_dropout,
bidirectional=True,
batch_first=True,
)
self.mlp_head = torch.nn.Sequential(
torch.nn.Linear(self.hidden_size * 2, self.hidden_size * 2),
torch.nn.ReLU(),
torch.nn.Linear(self.hidden_size * 2, self.output_size),
)
self.mlp_head(self.lstm_head(input_embeds)[0])
四、微调模型的应用
1. 基于微调的医学问诊模型HuaTuo
LLM模型(如LLaMa,ChatGLM)因为缺乏一定的医学专业知识语料而表现不佳。该项目通过医学知识图谱和GPT3.5API构建了中文医学指令数据集,并对LLaMa模型进行了指令微调得到了一个针对医学领域的智能问诊模型HuaTuo,相比于未经过医学数据指令微调的原LLaMa而言,HuaTuo模型在智能问诊层面表现出色,可生成一些更为可靠的医学知识回答。
华佗 HuaTuo: Tuning LLaMA Model with Chinese Medical Knowledge
PDF: https://arxiv.org/pdf/2304.06975v1.pdf
Code: https://github.com/scir-hi/huatuo-llama-med-chinese
2. Chinese-LLaMA-Alpace中文模型
论文链接:https://arxiv.org/pdf/2304.08177.pdf
github链接:https://github.com/ymcui/Chinese-LLaMA-Alpaca
chinese LLaMA alpaca模型
论文:《EFFICIENT ANDEFFECTIVETEXTENCODING FORCHINESELLAMAANDALPACA》
Alpaca基于LLaMA的构造数据进行微调:
- 增加词表,增加编码效率:为了增强分词器对中文文本的支持,首先使用SentencePiece在中文语料库上训练一个中文分词器,词汇量为20,000。然后将中文分词器与原始LLaMA分词器合并,组合它们的词汇表。最终,得到一个合并后的分词器,称为中文LLaMA分词器,词汇量为49,953。
- 使用低秩自使用LoRA,减少训练参数
- LLaMA参数量在7B-65B
- Georgi Gerganov. llama.cpp.https://github.com/ggerganov/llama.cpp, 2023
- LLaMA包括预归一化、多transformer块和一个语言模型head层、如预归一化、SwiGLU激活和Rotary Embeddings等的改进;LLaMA缺乏指令微调,非商业许可,Alpaca是基于该模型生成;指令数据是基于OpenAI的text-davinci-003,其使用条款禁止开发与OpenAI竞争的模型
- 使用GPT4作为评分工具
Reference
[1] mT5: A Massively Multilingual Pre-trained Text-to-Text Transformer https://arxiv.org/pdf/2010.11934.pdf
[2] Language Models are Few-Shot Learners https://link.zhihu.com/?target=https%3A//arxiv.org/pdf/2005.14165.pdf
[3] LaMDA: Language Models for Dialog Applications:https://arxiv.org/pdf/2201.08239.pdf
[4] Jurassic-1: Technical Details and Evaluation https://uploads-ssl.webflow.com/60fd4503684b466578c0d307/61138924626a6981ee09caf6_jurassic_tech_paper.pdf
[5] Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, the World’s Largest and Most Powerful Generative Language Model https://arxiv.org/pdf/2201.11990.pdf
[6] Scaling Language Models: Methods, Analysis & Insights from Training Gopher https://storage.googleapis.com/deepmind-media/research/language-research/Training%20Gopher.pdf
[7] Training Compute-Optimal Large Language Models https://arxiv.org/pdf/2203.15556.pdf
[8] PaLM: Scaling Language Modeling with Pathways https://arxiv.org/pdf/2204.02311.pdf
[9] Pathways: Asynchronous Distributed Dataflow for ML https://arxiv.org/pdf/2203.12533.pdf
[10] Transcending Scaling Laws with 0.1% Extra Compute https://arxiv.org/pdf/2210.11399.pdf
[11] UL2: Unifying Language Learning Paradigms https://arxiv.org/pdf/2205.05131.pdf
[12] OPT: Open Pre-trained Transformer Language Models https://arxiv.org/pdf/2205.01068.pdf
[13] LLaMA: Open and Efficient Foundation Language Models https://arxiv.org/pdf/2302.13971v1.pdf
[14] BLOOM: A 176B-Parameter Open-Access Multilingual Language Model https://arxiv.org/pdf/2211.05100.pdf
[15] GLM-130B: An Open Bilingual Pre-Trained Model https://arxiv.org/pdf/2210.02414.pdf
[16] ERNIE 3.0 Titan: Exploring Larger-scale Knowledge Enhanced Pre-training for Language Understanding and Generation https://arxiv.org/pdf/2112.12731.pdf
[17] ERNIE 3.0: Large-scale Knowledge Enhanced Pre-training for Language Understanding and Generation https://arxiv.org/pdf/2107.02137.pdf
[18] Is Prompt All You Need? No. A Comprehensive and Broader View of Instruction Learning https://arxiv.org/pdf/2303.10475v2.pdf
[19] T0 Multitask Prompted Training Enables Zero-Shot Task Generalization https://arxiv.org/pdf/2110.08207.pdf
[20] Finetuned Language Models Are Zero-shot Learners https://openreview.net/pdf?id=gEZrGCozdqR
[21] Scaling Instruction-Finetuned Language Models https://arxiv.org/pdf/2210.11416.pdf
[22] Crosslingual Generalization through Multitask Finetuning https://arxiv.org/pdf/2211.01786.pdf
[23] GPT-3.5 https://platform.openai.com/docs/models/gpt-3-5
[24] Evaluating Large Language Models Trained on Code https://arxiv.org/pdf/2107.03374.pdf
[25] Training language models to follow instructions with human feedback https://arxiv.org/pdf/2203.02155.pdf
[26] OpenAI Blog: Introducting ChatGPT https://openai.com/blog/chatgpt
[27] mT5: A Massively Multilingual Pre-trained Text-to-Text Transformer
[28] OpenAI Blog: GPT-4 https://openai.com/research/gpt-4
[29] Alpaca: A Strong, Replicable Instruction-Following Model https://crfm.stanford.edu/2023/03/13/alpaca.html
[30] ChatGLM:千亿基座的对话模型开启内测 https://chatglm.cn/blog
[31] UC伯克利发布大语言模型排行榜
[32] https://zhuanlan.zhihu.com/p/624918286
[33] https://xv44586.github.io/2023/03/10/llm-inf/
[34] 大语言模型调研汇总
[45] Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer https://arxiv.org/pdf/1910.10683.pdf
[46] 论文解读 Chinese-LLaMA-Alpaca 中文版大语言模型
[47] 预训练技术及应用. 华菁云 澜舟科技 算法研究员
[48] 华佗 HuaTuo: Tuning LLaMA Model with Chinese Medical Knowledge
PDF: https://arxiv.org/pdf/2304.06975v1.pdf
Code: https://github.com/scir-hi/huatuo-llama-med-chinese
[49] 极低资源条件下如何微调大模型:LoRA模型思想与BLOOM-LORA代码实现分析
[50] 大模型主流微调范式、性能对比与开源项目汇总:也看Freeze、P-Tuning、Lora、full-Finetune开源实现
[51] 大模型训练之微调篇(理解篇+代码篇)