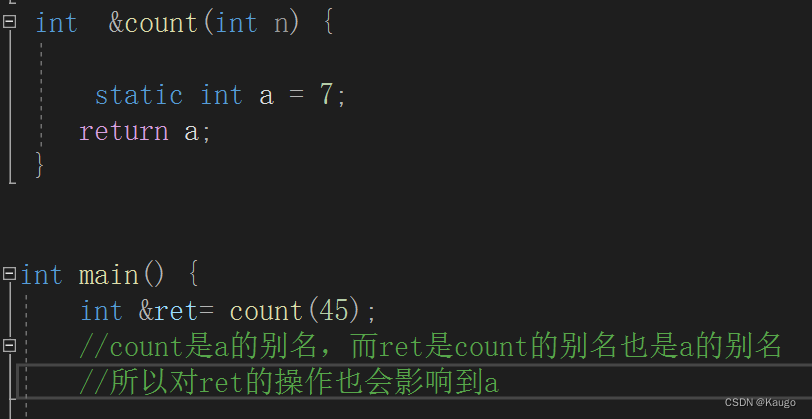
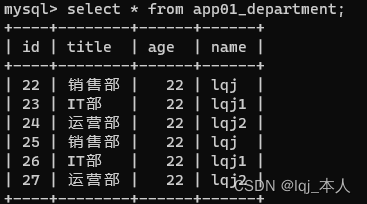
1、租赁环境

2、vscode 连接 矩池云
教程:https://www.matpool.com/supports/doc-vscode-connect-matpool/
3、进入mnt文件夹
cd ../mnt4、克隆代码
git clone https://github.com/jiayi-ma/FusionGAN.git如果克隆不下来,就自己下载,上传到矩池云网盘中,并解压

 解压
解压
unzip FusionGAN.zip -d FusionGAN 
5、进入到代码目录
cd FusionGAN
cd FusionGAN-master/
6、打开项目文件夹



7、测试预测过程
运行:
python test_one_image.py报错:
AttributeError: module 'scipy.misc' has no attribute 'imread'解决办法:
pip install scipy==1.1.0再运行:
python test_one_image.py
8、测试训练过程
运行:
python main.py
报错:
File "/mnt/FusionGAN/FusionGAN-master/utils.py", line 150, in input_setup
for i in xrange(len(data)):
NameError: name 'xrange' is not defined解决办法:指定行的xrange改为range

报错:
File "/mnt/FusionGAN/FusionGAN-master/utils.py", line 164, in input_setup
sub_label = label_[x+padding:x+padding+config.label_size, y+padding:y+padding+config.label_size] # [21 x 21]
TypeError: slice indices must be integers or None or have an __index__ method解决办法:浮点型改为整型

报错:
killed解决办法:系统内存不够,换用内存更大的cpu
(1)先保存环境

租用2080Ti


(2)按照上述步骤继续连接服务器并打开项目,继续运行main.py会生成h5文件,用于训练的数据

9、论文理解
为了同时保持红外图像的热辐射信息和可见光图像丰富的纹理信息,从一个新的角度提出了一种新的融合策略。我们制定的红外和可见光图像融合问题作为一个对抗性的问题,如下图

(1)按通道维度拼接红外+可见光图像
(2)将拼接好的图像送入生成器,输出融合图像If
(3)将融合图像If和可见光图像Iv送入到判别器中,判别If和Iv,如此在生成器和判别器之间形成对抗。目的是让,If将逐渐包含可见光图像Iv中越来越多的细节信息,如果在训练阶段期间,一旦生成器GθG生成样本(即,如果)不能被鉴别器DθD区分,则期望的融合图像If,说明包含了足够多的细节信息。
损失函数分为两部分:生成器+鉴别器
生成器损失函数的设计:

VFusionGAN(G)表示生成器GθG和鉴别器DθD之间的对抗损失

其中Inf表示融合图像,其中n ∈ IINN,N表示融合图像的数量,c是生成器希望鉴别器相信假数据的值
Lcontent表示内容损失,并且λ用于在VFusionGAN(G)和Lcontent之间取得平衡。由于红外图像的热辐射信息由其像素强度表征,并且可见光图像的纹理细节信息可以部分地由其梯度表征[18],因此我们强制融合图像If具有与Ir相似的强度和与Iv相似的梯度。

Lcontent的第一项旨在保持融合图像If中的红外图像Ir的热辐射信息,Lcontent的第二项旨在保持可见图像Iv中包含的梯度信息,并且ξ是控制两项之间的折衷的正参数。
鉴别器损失函数的设计:

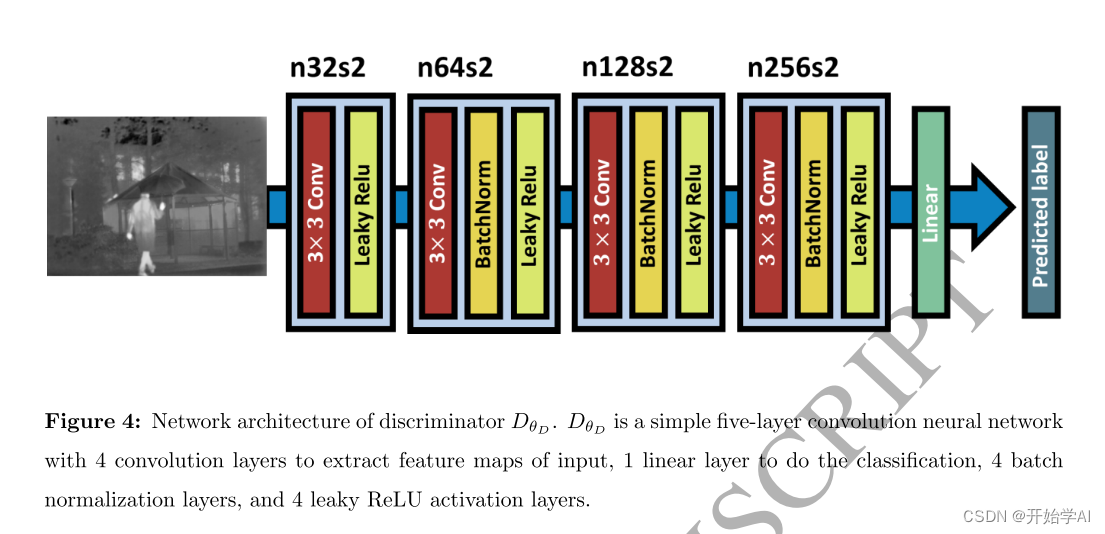
其中a和B分别表示融合图像If和可见光图像Iv的标签,DθD(Iv)和DθD(If)分别表示可见光图像和融合图像的分类结果。鉴别器被设计成基于从它们中提取的特征来区分融合图像和可见光图像。
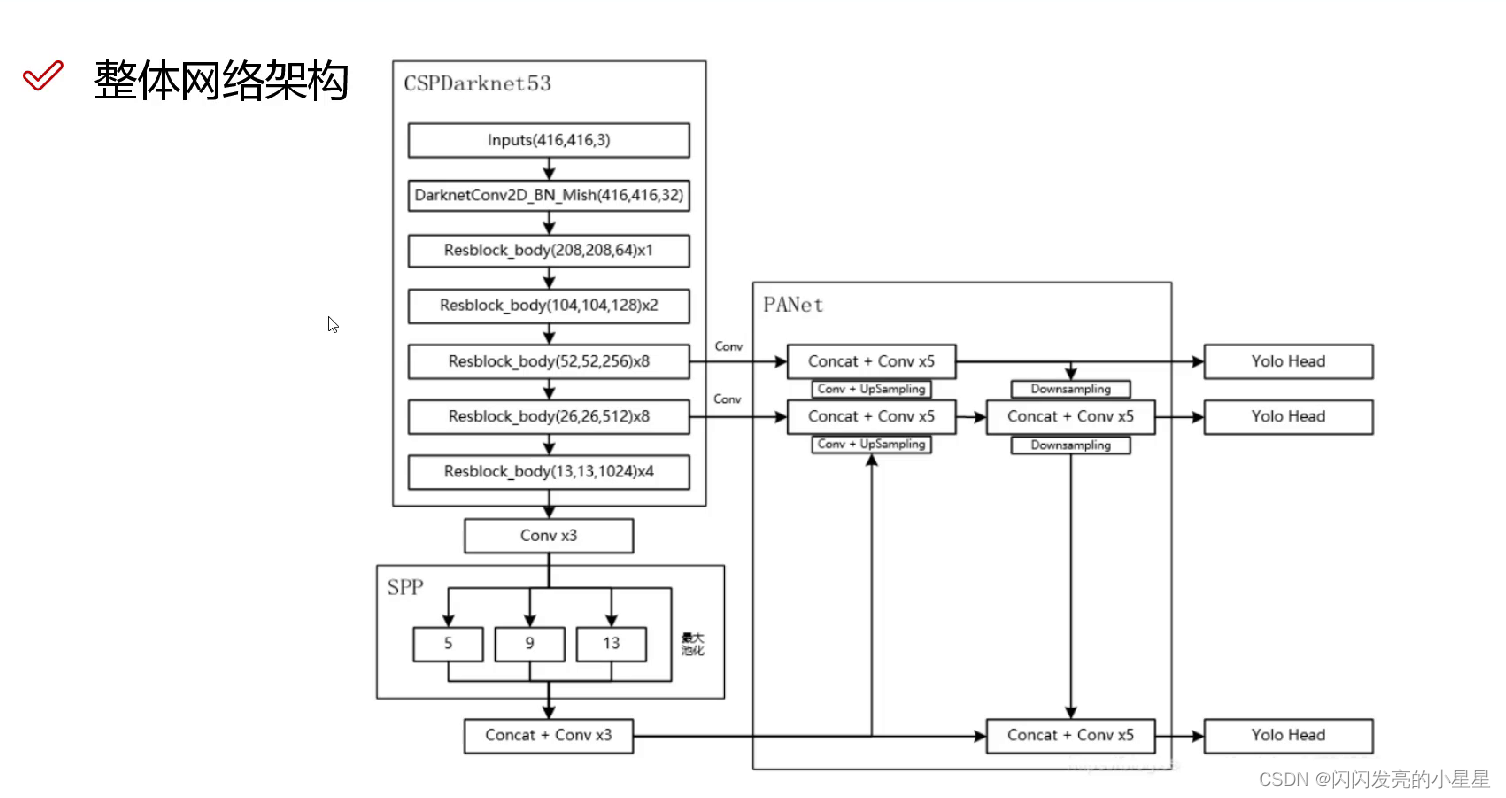
网络设计