声明:
文章中代码及相关语句为自己根据相应理解编写,文章中出现的相关图片为自己实践中的截图和相关技术对应的图片,若有相关异议,请联系删除。感谢。转载请注明出处,感谢。
By luoyepiaoxue2014
B站:https://space.bilibili.com/1523287361 点击打开链接
微博地址: https://weibo.com/luoyepiaoxue2014 点击打开链接
title: Flink系列
大数据分布式计算引擎设计实现剖析
0.1 前言
其实整个互联网行业的所有的产品的本质需求: 存 、取、分析
存:HDFS + HBase + MySQL + Redis + MongoDB+ es + 时序数据库 + 图数据库 + 对象数据库 + 数据湖
取: 单点取(select * from table where id = 1),批量取(类似于 HBase 的范围查询),全量取(文件上传下载)
分析: 计算引擎(MR,spark,Flink),分析型数据库(hive, OLAP 体系)
剩下的都是衍生需求:完整整个体系,保证整个架构平稳高效运行的
0.2 各大分布式引擎剖析
分布式计算引擎:海量大文件的计算,WordCount作为一个入门需求举例理解这些 分布式执行引擎的设计和执行原理:
-
MapReduce 离线批处理 非常大的进步 鼻祖
-
Storm 流式实时处理 开源界第一个最受欢迎的流式计算引擎 不用管了
-
Spark 离线批处理 + 交互式查询 + 伪流式处理/微批处理 + 机器学习 ===> 批处理之王, 几乎所有的离线计算需求都是使用 Spark 去做
-
Flink 实时流式计算引擎 出生就是为了解决流式计算
-
Hive 框架 工具 / 壳 底层的引擎,可以使用 sprak mr tez 等
计算引擎:
1、Hive + SparkCore / MR
2、SparkSQL
3、MR + Storm + Spark + Flink 等
数据库:
1、HBase
2、OLAP体系: Clickhouse/Doris/Kylin/Kudu/Druid/Impala/Presto
HBase(低延时的单点随机读写) + Clickhouse(全量分析) 设计分析的对比
也是为了分析!
Flink 的真正的用途是干什么的?有三点!看官网解释!
0.2.1 MapReduce 执行引擎解析
MapReduce 执行引擎解析:
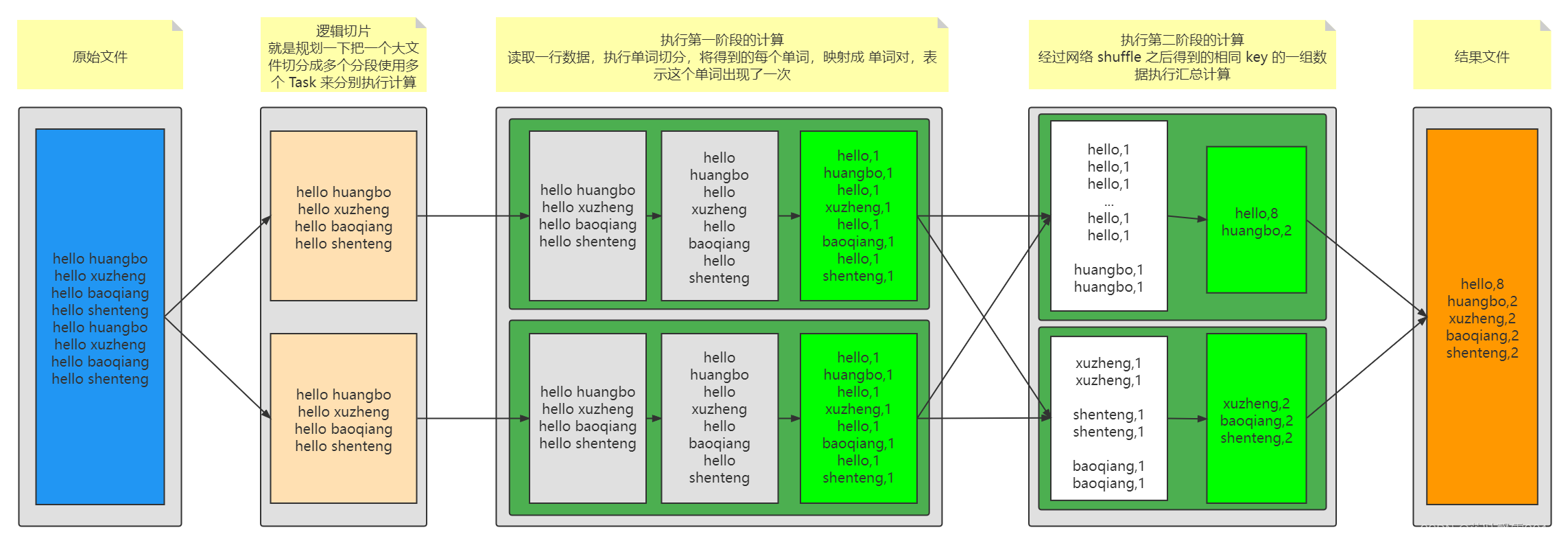
最核心的思想: 分而治之 + 分阶段执行
-
一个任务太大了,太复杂了,分而治之 大事化小 小事化了
-
必然衍生出来 分布式批处理计算必然要分阶段。 第二个阶段中的 Task 是否能执行完全取决于第一个阶段的 Task 是否全部完成
-
中间必然需要通过 网络来执行数据混洗:其实就是把标记相同的 value 传输到同一个节点,启动 Task 来执行聚合计算
MaReduce 引擎:
-
Mapper 分。不是用来做计算的,是用来给第二个阶段准备计算数据的:提取待计算的数据,然后打上标签! Mapper 做计算是谓词下推的体现!本身计算做个事儿 reducer 去做,其实这个事儿,没必要非得等到 reducer 去做,mapper 可以先做一做!
-
Reducer 合。真正的计算在哪里?在这里,拿到了一组 key 相同的 value 数据然后执行聚合逻辑
有同学可能会问到:为什么 mapreduce 中的输出的 key 可以重复呢?不要把 这个key-value 当做 hashmap 中的 键值对来理解!
- Key: 待计算数据的标记
- value:待计算的数据
经典面试题:现在 有 1000亿 条数据,反正很大(1000T)(反正就一台机器搞不定),我需要统计一下,这些数据中最大的 50 条是谁?
-
堆排序! 数据量小,确实可用。花的时间会特别长,占用的资源少
-
1000T 分成 1000 个任务,每个任务执行 1T 数据的计算,可以采用堆(堆中只保存了最大的50条)的方式来搞定,每个堆得到 50 条数据,1000个堆 就是50000 条数据,再维护一个最终的堆就搞定了(因为这 1000 个小任务是并行执行的)
大数据的分布式批处理计算引擎:分布式分阶段并行执行引擎
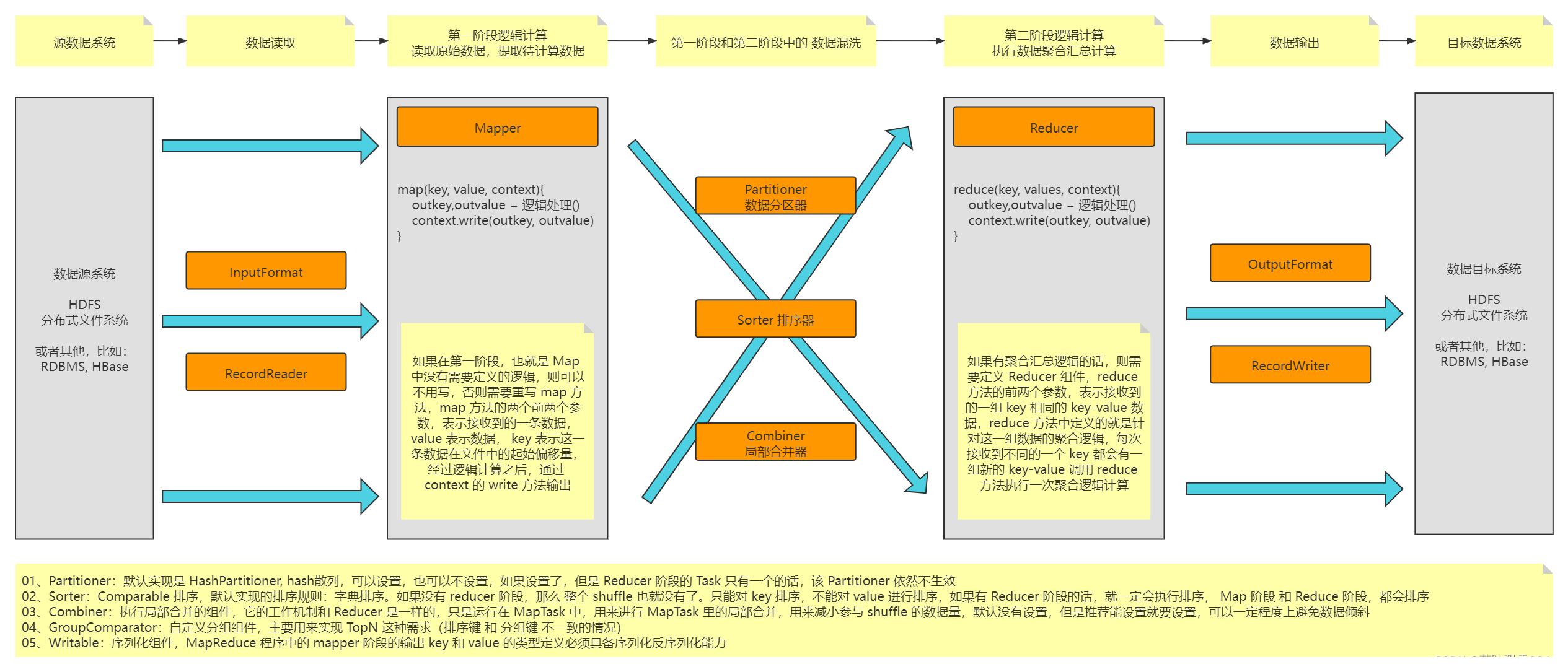
MapReduce 的组件设计实现图:
面试题举例:使用 MR 来实现:
1000T数据求TopN 数据存储在HDFS 默认实现
定义 Mapper 逻辑 可选的动作 定义 Reducer 逻辑 默认组件 HDFS
读取一个分段文件 把1000个任务输出堆
维护一个小根堆 从5W条数据中求最大50
框架:半成品,把很多应用程序的共同部分做一个抽象和沉淀!
MapReduce : 分布式计算引用程序的编程框架!
类似于 责任链设计模式! 处理器1 -> 处理器2 -> 处理器3 -> 处理器4
1、数据源: 存储数据的
数据读取组件:InputFormat + RecordReader 提供了一种抽象,不管从读哪里读取数据都可以,有默认实现,有内置实现,当然也可以自定义
- FileInputFormat + LineRecordReader 逐行读取文件,默认实现
- DBInputFormat 读取数据库 MySQL 批量读取 + 单条记录读取
2、Mapper: 定义了每一条数据到底执行什么样的处理(怎么提取数据打标记?用户来写)
3、Shuffle:到底使用哪个规则来决定什么样的数据作为一组传输到同一个节点来执行 reduce 计算
- Paritioner 分区规则: 用户要写
- Sorter 排序器: MR 内部直接默认使用了 归并排序 + 快速排序
- Combiner 局部合并器: 取决你的逻辑要不要,如果能写,最好写一个
4、Reducer: 定义了每一组数据到底执行什么样的处理(拿到key相同的一组数据之后,怎么执行计算呢?用户来写)
5、数据输出组件:OutputFormat + RecordWriter
FileOutputFormat + LineRecordWriter 默认实现
补充:海量数据的常见面试题
Spark、Flink 或者说 Java、Scala 到底谁多一点?归根结底都是工具。你的团队对那个熟悉就可以考虑用哪个,生态的多样性。
0.2.2 Spark 执行引擎解析
Spark 执行引擎解析:
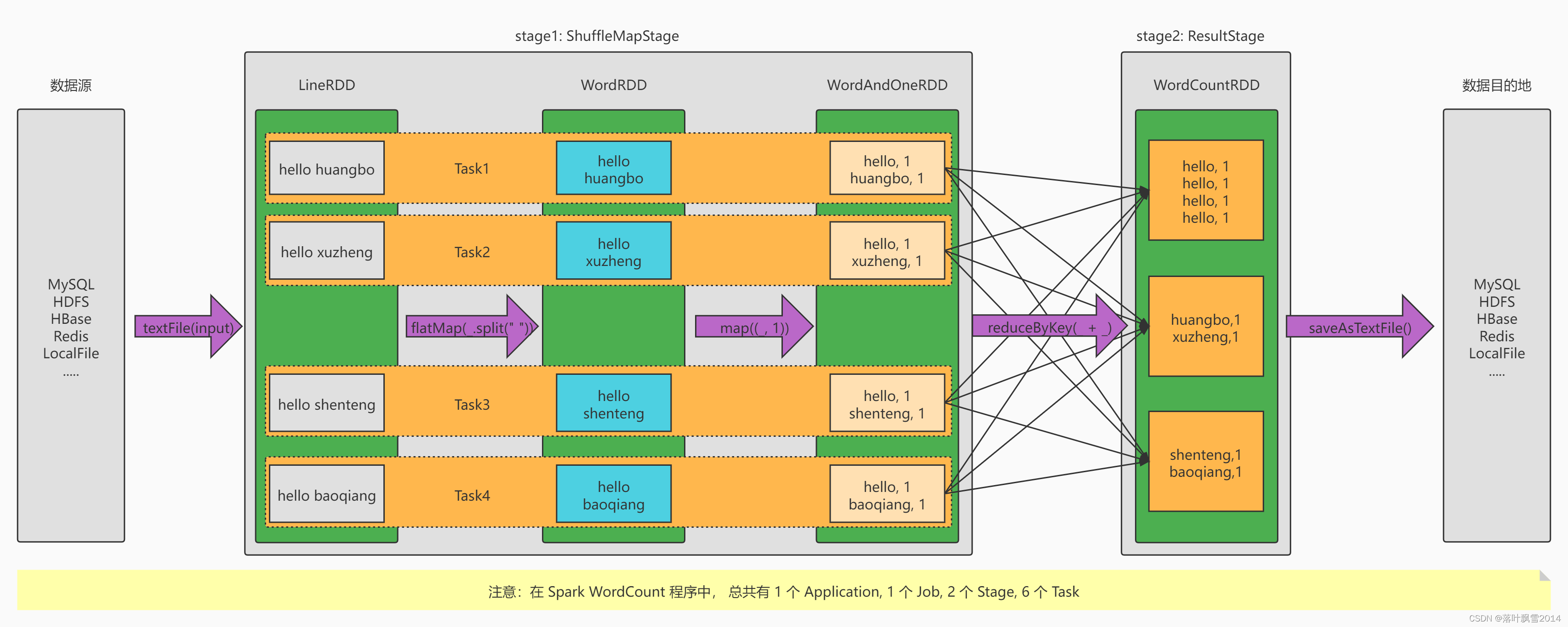
Spark 相比于 MR的真正优势的地方在哪里:Simple Fast Scalable Unified
- DAG 引擎
- 中间计算结果可以进行内存持久化
- 基于内存计算(不合适,如果要解释合理一些:我们可以把数据都加载(从内存中间件中读取)到内存中,然后来执行计算)
- 生态多样,算子丰富,API 应用库丰富,支持的资源调度也丰富
真正的计算,都是迭代: 从文件中,读取一条,执行一条数据的计算 MR、Spark 读取 HDFS 的数据,执行计算的方式是一样的,因为底层使用的 读取数据是一样的
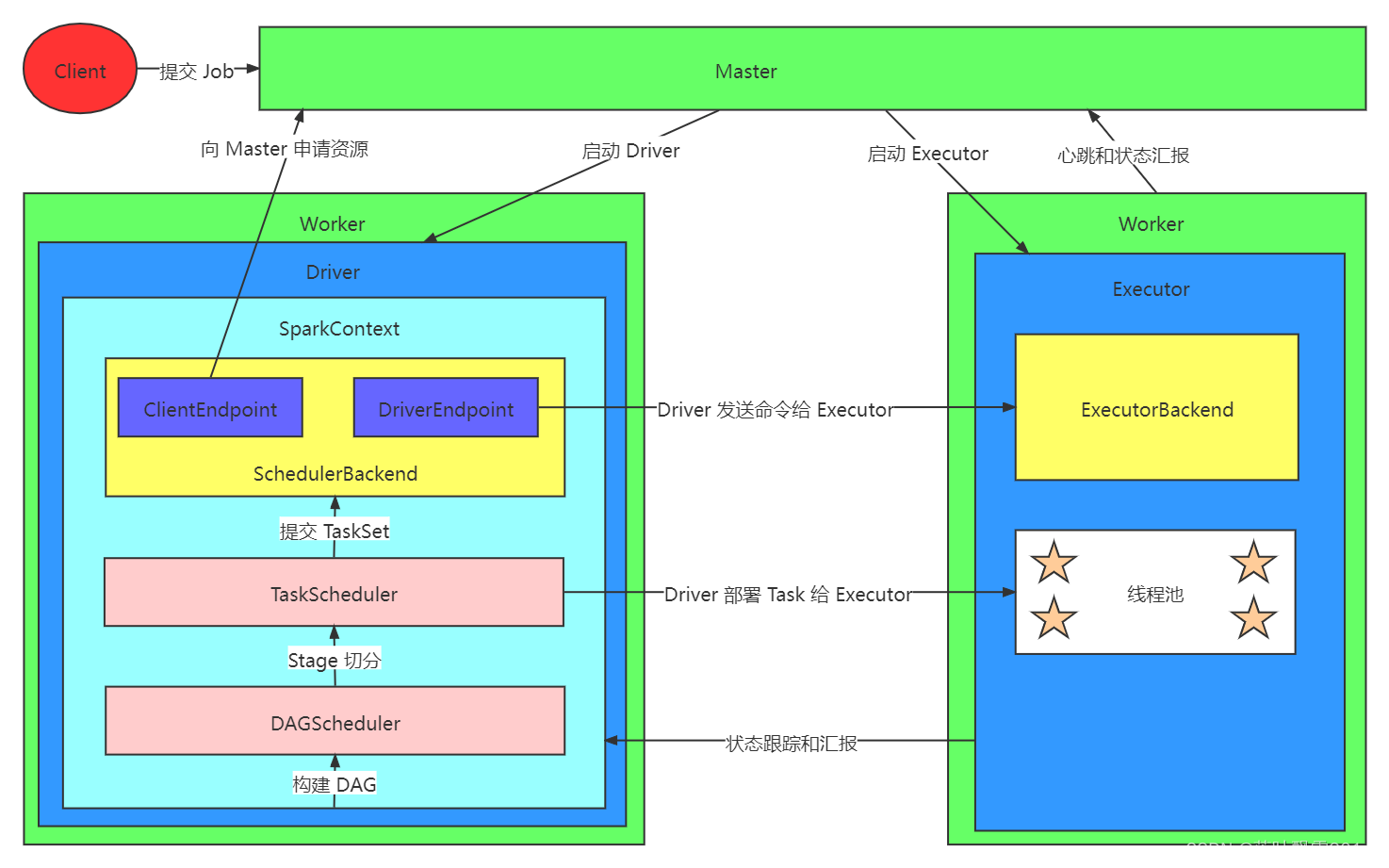
Spark 执行引擎组件图:
总结一下:
- MapReduce:批计算引擎
- Storm:流计算引擎
- Spark:批计算引擎 + 流计算引擎(微批/伪流式)
- Flink:批计算引擎 + 流计算引擎
目前开源大数据计算引擎有很多选择,流计算如 Storm,Samza,Flink,Kafka Stream 等,批处理如 MapReduce,Spark,Hive,Pig,Flink 等。而同时支持流处理和批处理的计算引擎,只有两种选择:一个是 Apache Spark,一个是 Apache Flink。
而 Flink 和 Spark 的不同点在于:
1、Spark的技术理念是基于批计算来模拟流计算。认为批处理是常态,而把流式处理看做是批处理的特例。
2、Flink的技术理念是基于流计算来模拟批计算。认为流处理是常态,而把批处理看做是流式处理的特例。
用批来模拟流有一定的技术局限性,所以从技术的长远发展来看,Flink会更持久。
针对待计算的数据来说的:
有开始,有结束
有开始,没有结束
经典:
1、Spark的技术理念是基于批实现批和流。
2、Flink的技术理念是基于流实现流和批。


![[附源码]Python计算机毕业设计SSM考试排考系统(程序+LW)](https://img-blog.csdnimg.cn/e8ed59854a404557a5e66484e7b917e0.png)



![[附源码]Python计算机毕业设计Django二手书店设计论文](https://img-blog.csdnimg.cn/39c2e3a490b14be0b82e16b6e788c56c.png)



![[附源码]SSM计算机毕业设计学院竞赛管理信息系统JAVA](https://img-blog.csdnimg.cn/f2adf0aab3214982852882ef33e1eb2a.png)