笔记整理:陈子强,天津大学硕士,研究方向为自然语言处理
论文链接:https://arxiv.org/pdf/2205.02357.pdf
动机
尽管多模态知识图谱补全较单模态知识图谱补全已经有了很大的改进,但仍然存在两个限制。(1)架构的通用性。不同的多模态知识图谱补全需要在不同的编码器架构之上建立特定的、单独参数化的融合模块。因此需要一个统一的模型用于各个多模态知识图谱补全任务。(2)模态噪声。当前的大部分多模态知识图谱,一个实体对应于多个图像,部分图像与实体无关,甚至包含大量噪声。
方法
针对动机中提到的两点不足,文章的方法分布两部分:
(1)论文提出提出MKGformer框架,用M-Encoder将视觉Transformer和文本Transformer进行多层级融合。可以构建一个通用的多模态知识图谱补全框架。
(2)对于模态包含的噪声信息。首先,在M-Encoder的自注意力模块提出一个粗粒度的前缀引导交互模块,为下一步减小模态异构性做好准备。其次,在M-Encoder的前馈神经网络部分提出关联感知模块,获取细粒度的图文表示,降低对无关图像的错误敏感性。

MKGformer框架
框架包含三个部分:V-Encoder用于从图片块中捕获视觉特征,T-Encoder从文本中获取句法和语法信息,M-Encoder用于建模图像和文本的高层融合特征。
V-Encoder使用在ImageNet上预训练过的ViT,其公式如下,pc和pos分别表示patch embedding和位置编码。LN表示Layer Norm,MHA表示多头注意力。
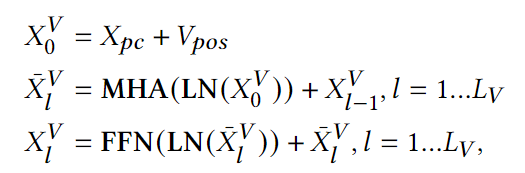
T-Encoder使用BERT作为文本编码器,其公式如下,wd和pos表示词嵌入和位置编码。LN表示Layer Norm,MHA表示多头注意力。
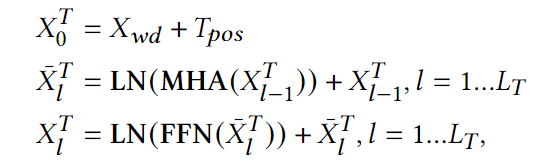
M-Encoder
T-Encoder使用BERT作为文本编码器,其公式如下,wd和pos表示词嵌入和位置编码。LN表示Layer Norm,MHA表示多头注意力。
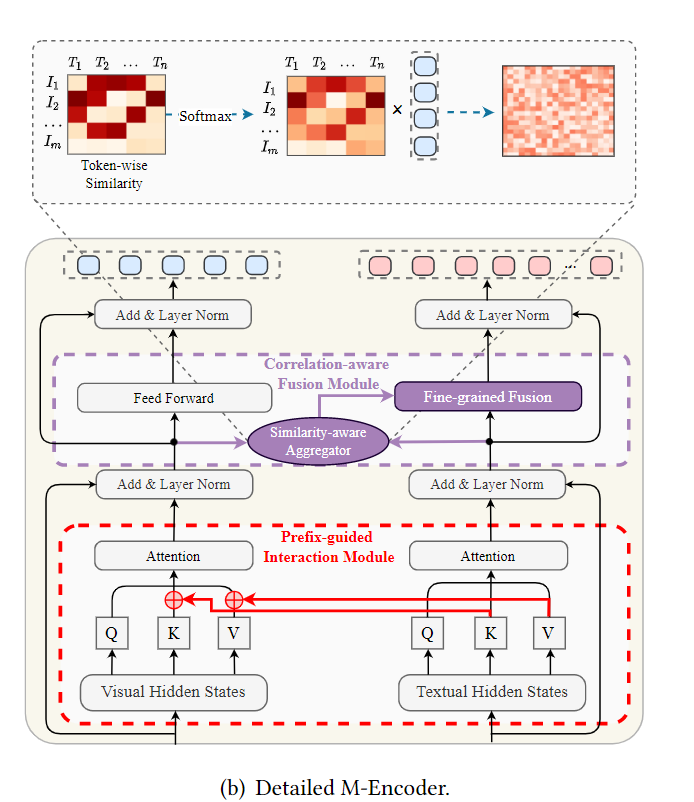
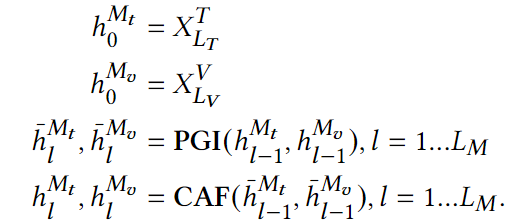
Prefix Guided Interaction Module (PGI)
受到prefix tuning的启发,PGI模块中优化了视觉注意力头的计算,将文本的key和value拼接到图像的key和value之后。通过这样的对key和value的处理,从而降低模态间的异构性。
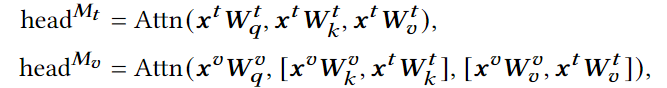
Correlation-aware Fusion Module (CAF)
为了缓解噪声的消极影响,用CAF模块捕获两个模态间的交互(token-patch间对齐)。具体地,首先计算text token和visual token的相似度矩阵。
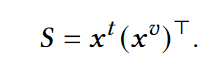
然后对相似度矩阵中的第i个text token做softmax再乘图像向量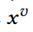 得到第i个text token的聚合向量。如此重复,得到相似度感知的聚合图像表示
得到第i个text token的聚合向量。如此重复,得到相似度感知的聚合图像表示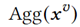
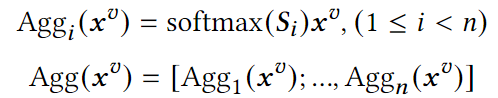
最后,在FFN模块中,将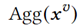 融合到文本表示中。
融合到文本表示中。
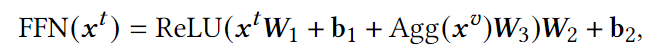
实验
多模态链接预测
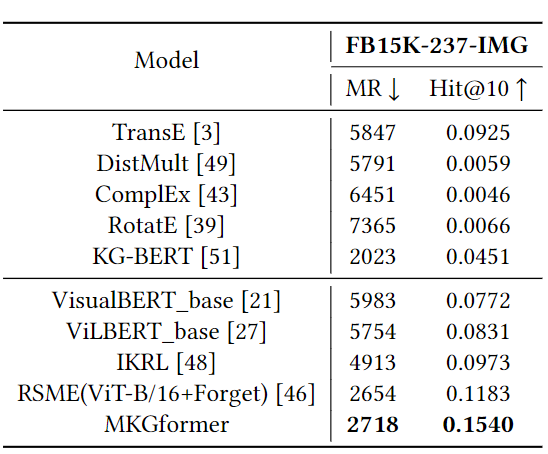
在FB-15k-247-IMG和WN18-IMG数据集上都取得了SOTA性能
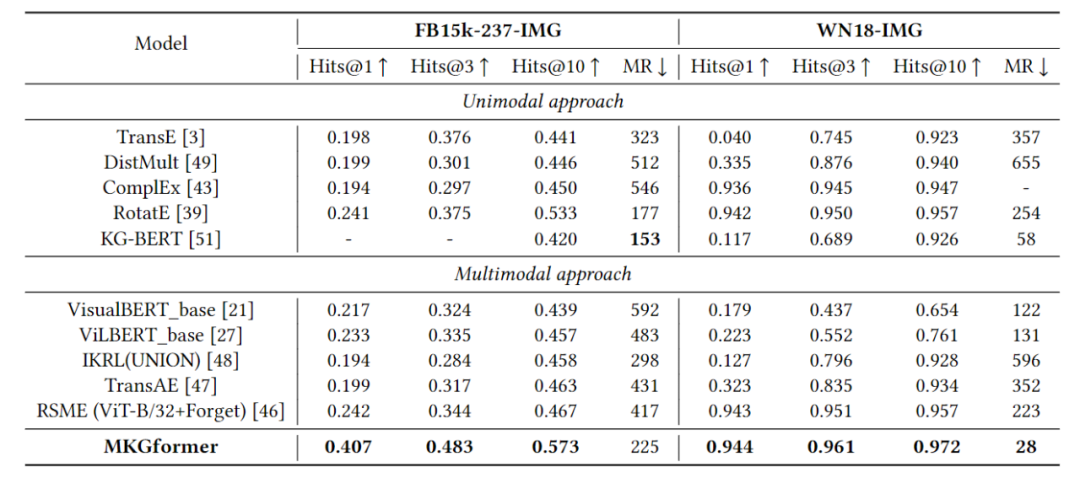
多模态关系抽取
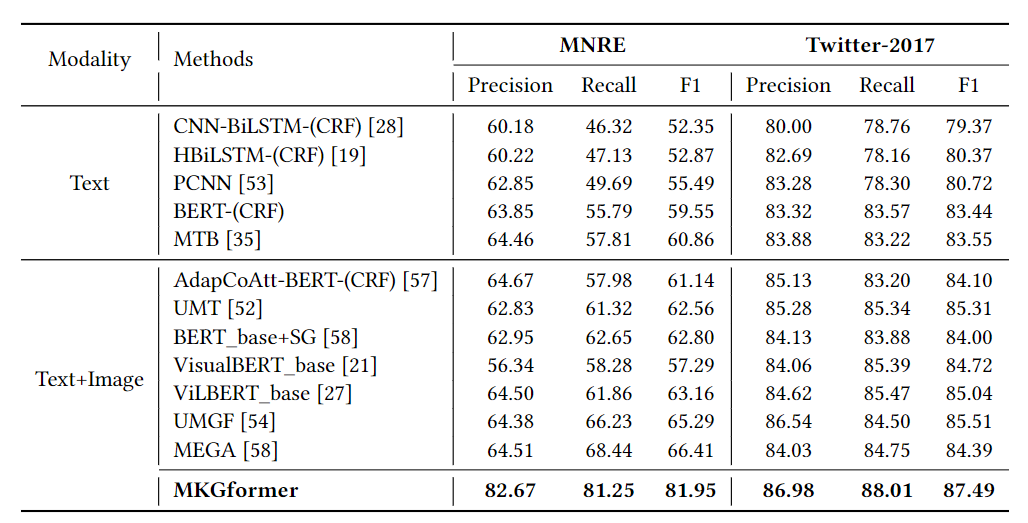
多模态关系抽取和命名实体识别
总结
文章提出一种多模态知识图谱补全的Transformer,在ViT和BERT的最后几层采用多级融合的M-Encoder进行图文融合的实体建模。MKGformer是第一个用统一的架构进行多个知识图谱补全的工作。具体地说,文章在自我注意层提出了前缀引导的交互模块来预先降低通道异构性,并在此基础上设计了相关性感知融合模块,在FFN层实现了token级别的细粒度融合,以减少无关图像/对象的噪声。在四个数据集上的大量实验结果证明了该算法的有效性和健壮性。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。


![[附源码]SSM计算机毕业设计学院竞赛管理信息系统JAVA](https://img-blog.csdnimg.cn/f2adf0aab3214982852882ef33e1eb2a.png)




![[ Linux ] Linux信号概述 信号的产生](https://img-blog.csdnimg.cn/img_convert/9aa71d7ff6f45fdf318af92f00796e0f.png)