🍥关键词:文本分类、提示学习
🍥发表期刊:Arxiv 2022
🍥原始论文:https://arxiv.org/pdf/2203.00902
最近在做Prompted learning for text classification的工作,Prompted learning的核心在于设计一个好的Template和Verbalizer。这篇文章对当前不同Template性能进行了比较。
一、Prompted Learning for Text classfication
先来看看提示学习如何实现文本分类任务 (图源【NLP】Prompt Learning 超强入门教程 - 知乎)

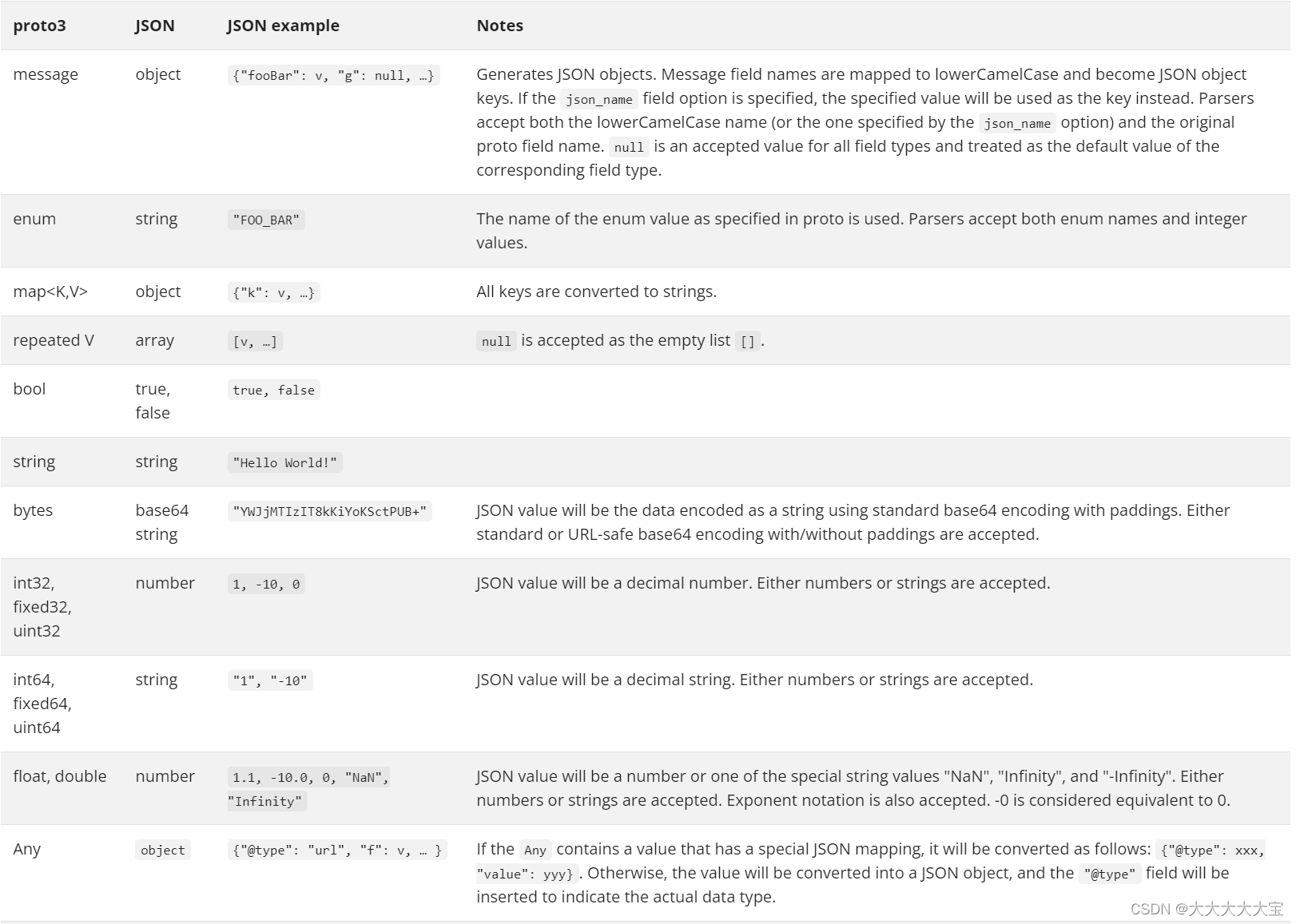
流程:我拿BERT模型为例,输入一个句子,将其放到模板中输送到BERT模型中,然后获取【MASK】处的向量(注意,这里的向量不是一个768维的Token向量,而是预测BERT词表中每个单词可能性的向量,约3w),然后将fanstatic和boring对应在BERT词表中的位置的预测值拿出来,将其比较大小,若是fantastic大,则这个句子预测为1
二、Three different Template and Label word
目前主流的有三种提示模板(前两种能接受,第三种感觉有点扯淡)

标签映射词的构造也有三种
注意前两种方式的单词都必须是在BERT词表中出现过的,第三种是随机初始化的

三、Experiment
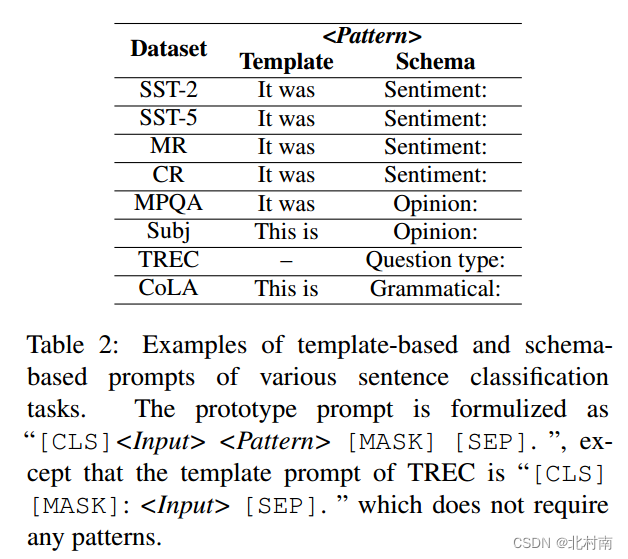
作者在使用Roberta-large预训练的基础上,对使用以下固定的Query信息,对三种不同的Template进行测试

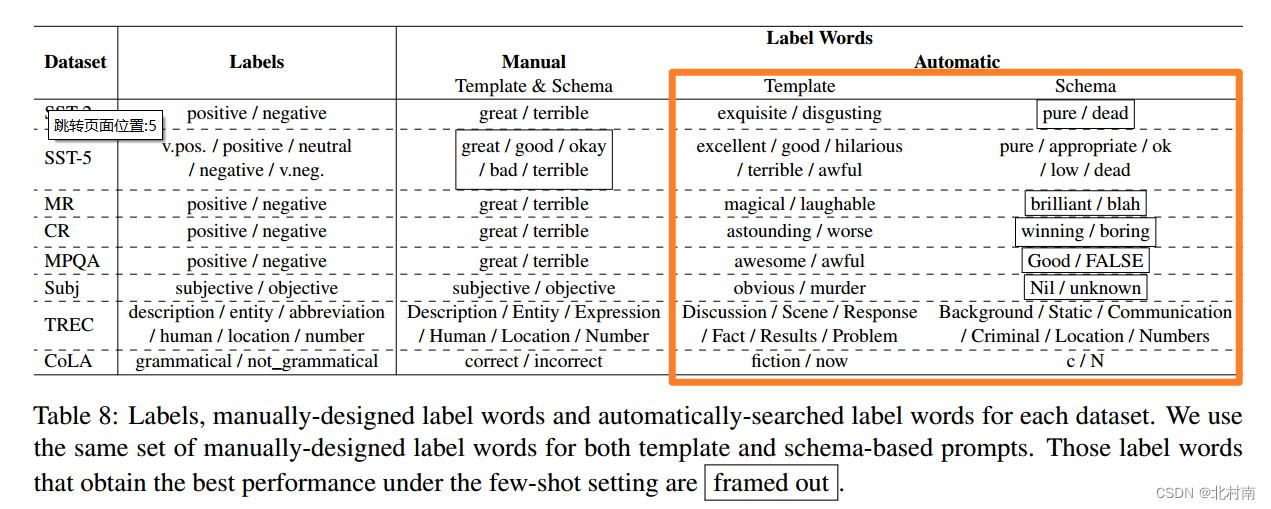
作者还对自动提取的Label word提取的单词进行研究,看看性能优异的单词究竟是哪些
四、Conclusion
结论一:无论高、低资源环境,Schama Template的方式都是最优的,而且在低资源环境中表现更甚
结论二:对于哪些表现优异的自动提取的标签往往是不自然的,因此提示其实不需要严格的按照人类的说话和写作

![[Mysql] MySQL索引与事务](https://img-blog.csdnimg.cn/bd36db165d094f4ba9e9ba2c941e3104.png)