目录
order by:全局排序
sort by:局部排序
cluster by:簇排序
group by
partition by
order by:全局排序
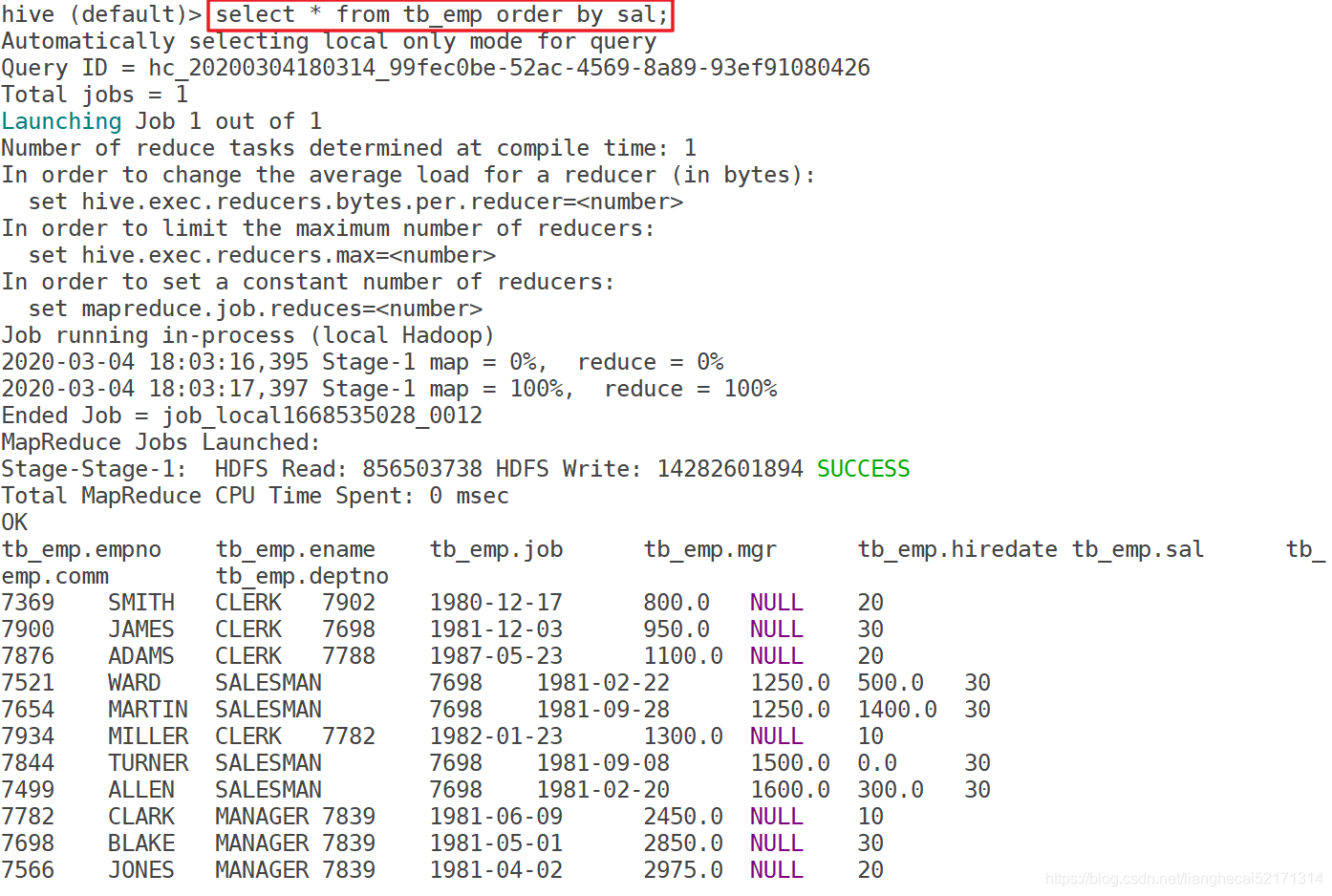
order by 会对数据进行一次全局排序,所以说,只要hive的sql中指定了order by,那么所有的数据都会到同一个reducer进行处理(不管有多少map,也不管文件有多少的block只会启动一个reducer)。
order by 只在一个reduce中进行,所以数据量特别大的时候效率非常低。建议在小的数据集中使用order by进行排序
可以通过设置hive.mapred.mode参数控制执行方式:
若选择strict,则order by 需要指定limit(若有分区还有指定哪个分区)
若为nostrict,则limit不是必需的
即使设置了mapreduce.job.reduces的值大于1, 使用order by,时Hive在运行MR程序时也会设置为1覆盖
示例:
sort by:局部排序
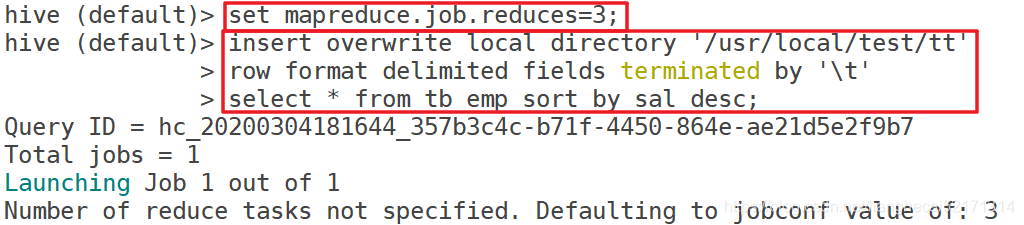
sort by在每个reducer端都会做排序,为每个reduce产生一个排序文件。也就是说sort by能保证局部有序(每个reducer出来的数据是有序的,但是不能保证所有的数据是有序的,除非只有一个reducer)。
使用sort by的好处是:执行了局部排序之后可以为接下去的全局排序提高不少的效率(其实就是做一次归并排序就可以做到全局排序了)。
sort by 的数据在进入reduce前就完成排序。
sort by 基本上不受hive.mapred.mode影响
可以通过mapreduce.job.reduces 指定reduce个数,查询后的数据被分发到相关的reduce中。
如果使用sort by 排序,并且设置mapreduce.job.reduces>1,sort by只能保证每个reducer输出有序,不能保证全局数据有序。
示例:
示例:
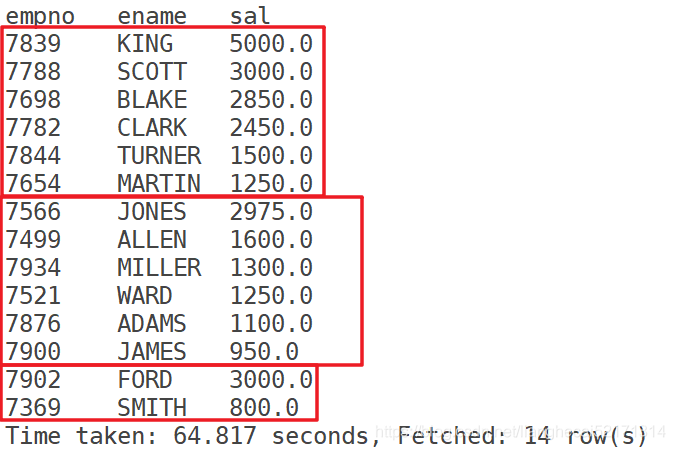
在有些情况下,你需要,这通常是为了进行后续的聚集操作。刚好可以做这件事。因此,distribute by经常和sort by配合使用。
distribute by:分区排序
DISTRIBUTE BY是控制map的输出在reducer是如何划分的
DISTRIBUTE BY是控制在map端如何拆分数据给reduce端的。
DISTRIBUTE BY可以控制某个特定行应该到哪个reducer。
distribute by 采集hash算法,在map端将查询结果中hash值相同的结果分发到对应的reduce文件中。
hive会根据distribute by后面列,对应reduce的个数进行分发,默认是采用hash算法。
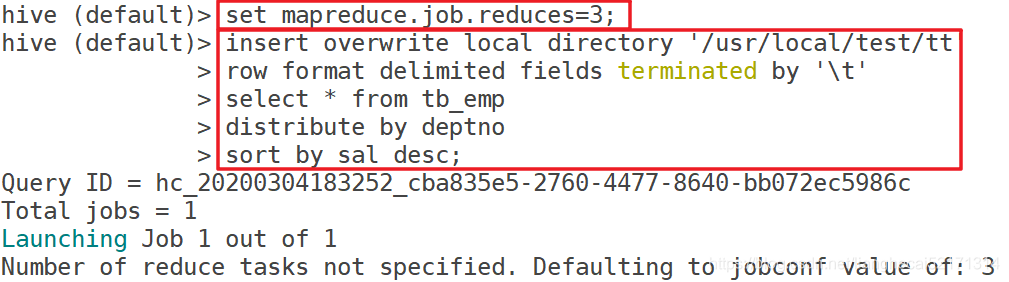
注意:distribute by必须要写在sort by之前
示例:
我们所有的deptno相同的数据会被送到同一个reducer去处理,这就是因为指定了distribute by deptno,这样的话就可以统计出每个部门中各个员工sal的排序了(这个肯定是全局有序的,因为相同部门的员工会放到同一个reducer去处理)。
cluster by:簇排序
cluster by 除了distribute by 的功能外,还会对该字段进行排序,所以cluster by = distribute by +sort by 。
distribute by 和 sort by 合用就相当于cluster by,但是cluster by 不能指定排序规则为asc或 desc ,只能是升序排列。
比如下面两个hql语句是等价的:
insert overwrite local directory '/usr/local/test/tt'
row format delimited fields terminated by '\t'
select * from tb_emp
distribute by deptno
sort by deptno;
--两者功能等价
insert overwrite local directory '/usr/local/test/tt'
row format delimited fields terminated by '\t'
select * from tb_emp
cluster by deptno;
示例:
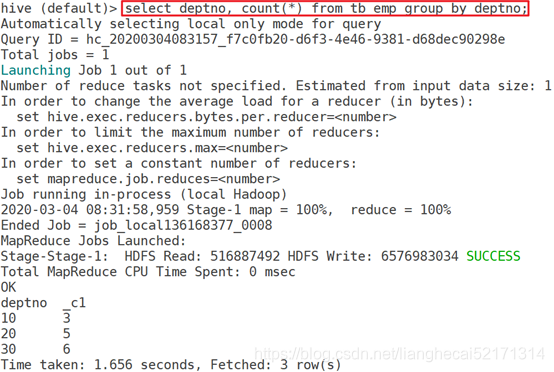
group by
和distribute by类似 都是按key值划分数据,都使用reduce操作
唯一不同的是,distribute by只是单纯的分散数据,distribute by col – 按照col列把数据分散到不同的reduce。
group by把相同key的数据聚集到一起,后续必须是聚合操作。
示例:
partition by
通常查询时会对整个数据库查询,而这带来了大量的开销,因此引入了partition的概念,在建表的时候通过设置partition的字段, 会根据该字段对数据分区存放,更具体的说是存放在不同的文件夹,这样通过指定设置Partition的字段条件查询时可以减少大量的开销。
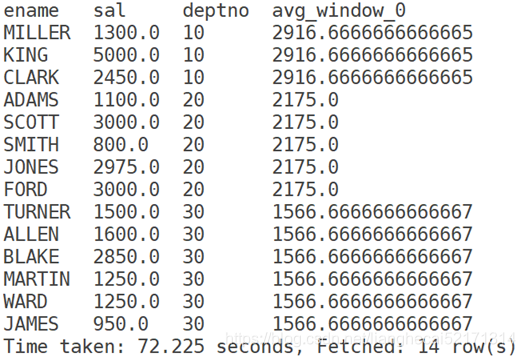
示例:查询某一个人的工资并和其所在的部门的平均薪资进行对比。
select ename,sal,deptno,avg(sal) over(partition by deptno)
from tb_emp;
结果:
![[附源码]Python计算机毕业设计Django房屋租赁信息系统](https://img-blog.csdnimg.cn/56a2fa548ad54dbda92fc67a25d628f7.png)
![[附源码]Python计算机毕业设计SSM-乐室预约小程序(程序+LW)](https://img-blog.csdnimg.cn/a4792969146147b783f6cabf29bd7437.png)
![[附源码]计算机毕业设计JAVA校园飞毛腿系统](https://img-blog.csdnimg.cn/47173add29db4886bc31516ee0944517.png)




![[附源码]计算机毕业设计springboot葡萄酒销售管理系统论文](https://img-blog.csdnimg.cn/45e505333b9649608488b197cc0720f2.png)


![[附源码]Python计算机毕业设计Django港口集团仓库管理系统](https://img-blog.csdnimg.cn/58eae02168d94ab6b446eb119a426e29.png)