一、人工智能简单了解

1.人工智能发展必备三要素:
- 数据
- 算法
- 计算力
- CPU,GPU,TPU
 计算力之CPU、GPU对比:
计算力之CPU、GPU对比:-
CPU主要适合I\O密集型的任务
-
GPU主要适合计算密集型任务
2.人工智能、机器学习和深度学习
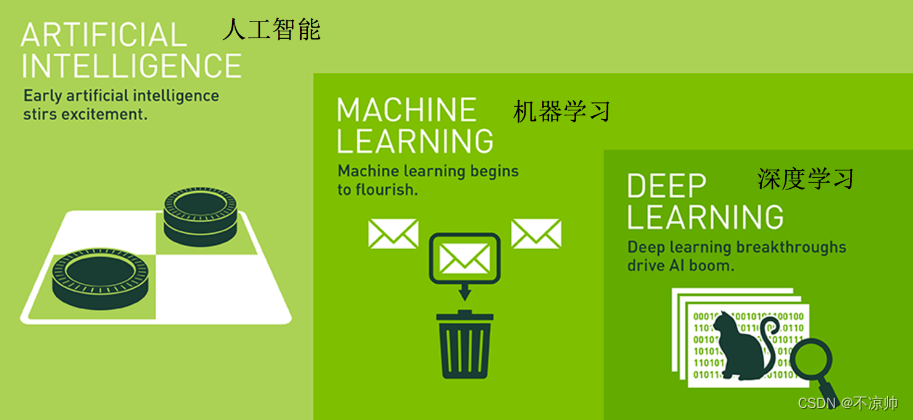
人工智能和机器学习,深度学习的关系
- 机器学习是人工智能的一个实现途径
- 深度学习是机器学习的一个方法发展而来
3.主要分支介绍
通讯、感知与行动是现代人工智能的三个关键能力,在这里我们将根据这些能力/应用对这三个技术领域进行介绍:
- 计算机视觉(CV)、
- 自然语言处理(NLP)。在 NLP 领域中,将覆盖文本挖掘/分类、机器翻译和语音识别。
- 机器人
1)计算机视觉
计算机视觉(CV)是指机器感知环境的能力。这一技术类别中的经典任务有图像形成、图像处理、图像提取和图像的三维推理。物体检测和人脸识别是其比较成功的研究领域。
当前阶段:计算机视觉现已有很多应用,这表明了这类技术的成就,也让我们将其归入到应用阶段。随着深度学习的发展,机器甚至能在特定的案例中实现超越人类的表现。但是,这项技术离社会影响阶段还有一定距离,那要等到机器能在所有场景中都达到人类的同等水平才行(感知其环境的所有相关方面)。
2)语音识别
语音识别是指识别语音(说出的语言)并将其转换成对应文本的技术。相反的任务(文本转语音/TTS)也是这一领域内一个类似的研究主题。
当前阶段:语音识别已经处于应用阶段很长时间了。最近几年,随着大数据和深度学习技术的发展,语音识别进展颇丰,现在已经非常接近社会影响阶段了。语音识别领域仍然面临着声纹识别和「鸡尾酒会效应」等一些特殊情况的难题。现代语音识别系统严重依赖于云,在离线时可能就无法取得理想的工作效果。
3)文本挖掘/分类
这里的文本挖掘主要是指文本分类,该技术可用于理解、组织和分类结构化或非结构化文本文档。其涵盖的主要任务有句法分析、情绪分析和垃圾信息检测。
当前阶段:我们将这项技术归类到应用阶段,因为现在有很多应用都已经集成了基于文本挖掘的情绪分析或垃圾信息检测技术。文本挖掘技术也在智能投顾的开发中有所应用,并且提升了用户体验。文本挖掘和分类领域的一个瓶颈出现在歧义和有偏差的数据上。
4)机器翻译
机器翻译(MT)是利用机器的力量自动将一种自然语言(源语言)的文本翻译成另一种语言(目标语言)。
当前阶段:机器翻译是一个见证了大量发展历程的应用领域。该领域最近由于神经机器翻译而取得了非常显著的进展,但仍然没有全面达到专业译者的水平;但是,我们相信在大数据、云计算和深度学习技术的帮助下,机器翻译很快就将进入社会影响阶段。在某些情况下,俚语和行话等内容的翻译会比较困难(受限词表问题)。专业领域的机器翻译(比如医疗领域)表现通常不好。
5)机器人
机器人学(Robotics)研究的是机器人的设计、制造、运作和应用,以及控制它们的计算机系统、传感反馈和信息处理。
机器人可以分成两大类:固定机器人和移动机器人。固定机器人通常被用于工业生产(比如用于装配线)。常见的移动机器人应用有货运机器人、空中机器人和自动载具。机器人需要不同部件和系统的协作才能实现最优的作业。其中在硬件上包含传感器、反应器和控制器;另外还有能够实现感知能力的软件,比如定位、地图测绘和目标识别。
当前阶段:自上世纪「Robot」一词诞生以来,人们已经为工业制造业设计了很多机器人。工业机器人是增长最快的应用领域,它们在 20 世纪 80 年代将这一领域带入了应用阶段。在安川电机、Fanuc、ABB、库卡等公司的努力下,我们认为进入 21 世纪之后,机器人领域就已经进入了社会影响阶段,此时各种工业机器人已经主宰了装配生产线。此外,软体机器人在很多领域也有广泛的应用,比如在医疗行业协助手术或在金融行业自动执行承销过程。但是,法律法规和「机器人威胁论」可能会妨碍机器人领域的发展。还有设计和制造机器人需要相对较高的投资。
总的来说,人工智能领域的研究前沿正逐渐从搜索、知识和推理领域转向机器学习、深度学习、计算机视觉和机器人领域。大多数早期技术至少已经处于应用阶段了,而且其中一些已经显现出了社会影响力。一些新开发的技术可能仍处于工程甚至研究阶段,但是我们可以看到不同阶段之间转移的速度变得越来越快。
二、机器学习工作原理及流程
1.什么是机器学习
机器学习是从数据中自动分析获得模型,并利用模型对未知数据进行预测。
 2.机器学习工作流程
2.机器学习工作流程
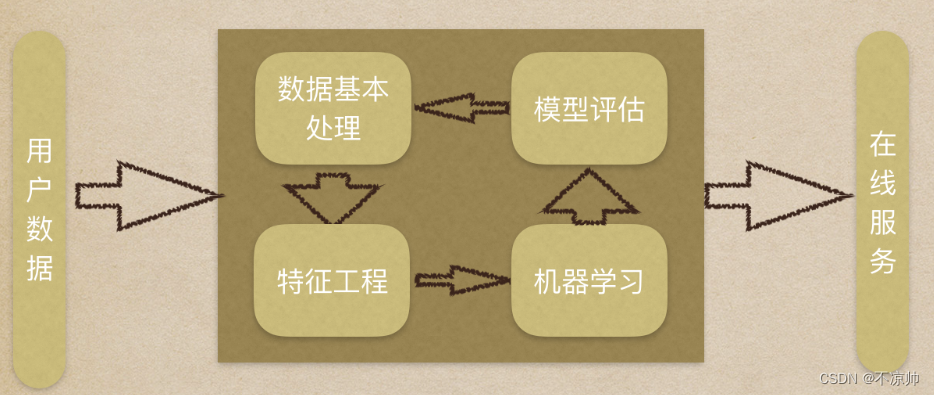
机器学习工作流程总结
- 1.获取数据
- 2.数据基本处理
- 3.特征工程
- 4.机器学习(模型训练)
- 5.模型评估
结果达到要求,上线服务;没有达到要求,重新上面步骤
1)获取数据集
获取数据集的方式有很多:web爬虫、数据抓包、文本资料、人工获取数据等等。
数据简介
-
在数据集中一般:
- 一行数据我们称为一个样本
- 一列数据我们成为一个特征
- 有些数据有目标值(标签值),有些数据没有目标值
-
数据类型构成:
- 数据类型一:特征值+目标值(目标值是连续的和离散的)
- 数据类型二:只有特征值,没有目标值
-
数据分割:
- 机器学习一般的数据集会划分为两个部分:
- 训练数据:用于训练,**构建模型** - 测试数据:在模型检验时使用,用于**评估模型是否有效** - 划分比例:
- 训练集:70% 80% 75% - 测试集:30% 20% 25%
- 机器学习一般的数据集会划分为两个部分:
2)数据基本处理
即对数据进行缺失值、去除异常值、去重等处理。
3)特征工程
特征工程(Feature Engineering)是使用专业背景知识和技巧处理数据,使得特征能在机器学习算法上发挥更好的作用的过程。
特征工程包含内容:
- 特征提取(将任意数据(如文本或图像)转换为可用于机器学习的数字特征)
- 特征预处理(通过一些转换函数将特征数据转换成更加适合算法模型的特征数据过程)
- 特征降维(指在某些限定条件下,降低随机变量(特征)个数,得到一组“不相关”主变量的过程)
4)机器学习(模型训练)
根据数据集组成不同,可以把机器学习算法分为:
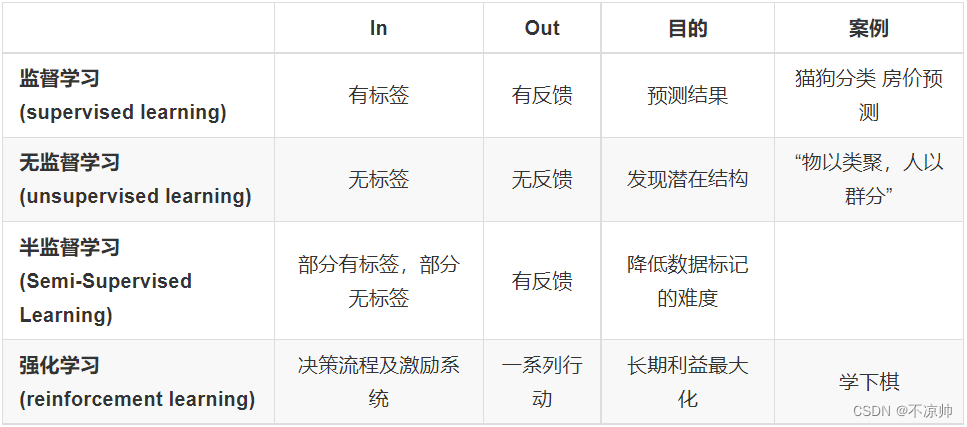
- 监督学习:输入数据是由输入特征值和目标值所组成。
- 无监督学习:输入数据是由输入特征值组成,没有目标值。
- 半监督学习:训练集同时包含有标记样本数据和未标记样本数据。
- 强化学习:实质是make decisions 问题,即自动进行决策,并且可以做连续决策。
5)模型评估
按照数据集的目标值不同,可以把模型评估分为分类模型评估和回归模型评估。
分类模型评估:
- 准确率:预测正确的数占样本总数的比例。
- 其他评价指标:精确率、召回率、F1-score、AUC指标等
回归模型评估:
- 均方根误差(Root Mean Squared Error,RMSE):RMSE是一个衡量回归模型误差率的常用公式。 不过,它仅能比较误差是相同单位的模型。
- 相对平方误差(Relative Squared Error,RSE)、
- 平均绝对误差(Mean Absolute Error,MAE)、
- 相对绝对误差(Relative Absolute Error,RAE)
拟合:模型评估用于评价训练好的的模型的表现效果,其表现效果大致可以分为两类:过拟合、欠拟合。
- 过拟合:在训练过程中,你可能会遇到这个问题:训练数据训练的很好啊,误差也不大,为什么在测试集上面有问题呢?当算法在某个数据集当中出现这种情况,可能就出现了拟合问题。所建的机器学习模型或者是深度学习模型在训练样本中表现得过于优越,导致在测试数据集中表现不佳。
- 欠拟合(under-fitting):模型学习的太过粗糙,连训练集中的样本数据特征关系都没有学出来。
![[附源码]计算机毕业设计JAVA校园飞毛腿系统](https://img-blog.csdnimg.cn/47173add29db4886bc31516ee0944517.png)




![[附源码]计算机毕业设计springboot葡萄酒销售管理系统论文](https://img-blog.csdnimg.cn/45e505333b9649608488b197cc0720f2.png)


![[附源码]Python计算机毕业设计Django港口集团仓库管理系统](https://img-blog.csdnimg.cn/58eae02168d94ab6b446eb119a426e29.png)