目录标题
- 什么是仿函数
- 如何定义一个仿函数
- 什么是优先级队列
- 优先级队列的使用
- 模拟实现priority_queue
- 准备工作
- top函数的实现
- size函数的实现
- empty函数的实现
- adjustup函数的实现
- push函数的实现
- pop函数的实现
- adjustdown函数的实现
- 构造函数的实现
什么是仿函数
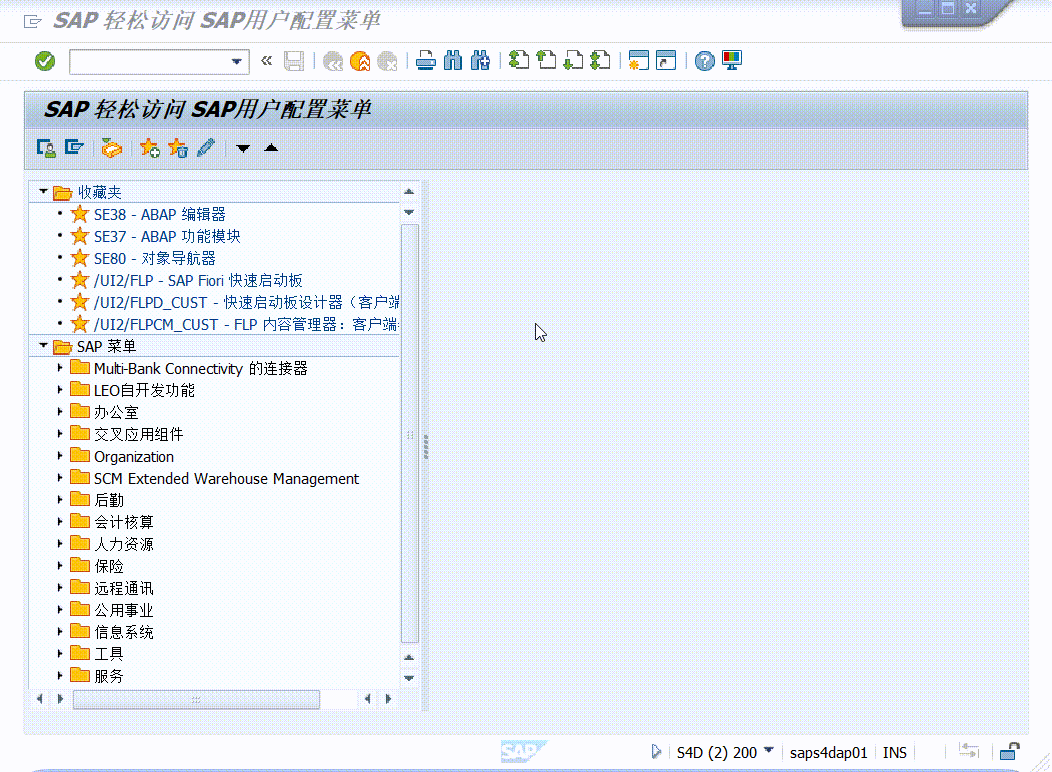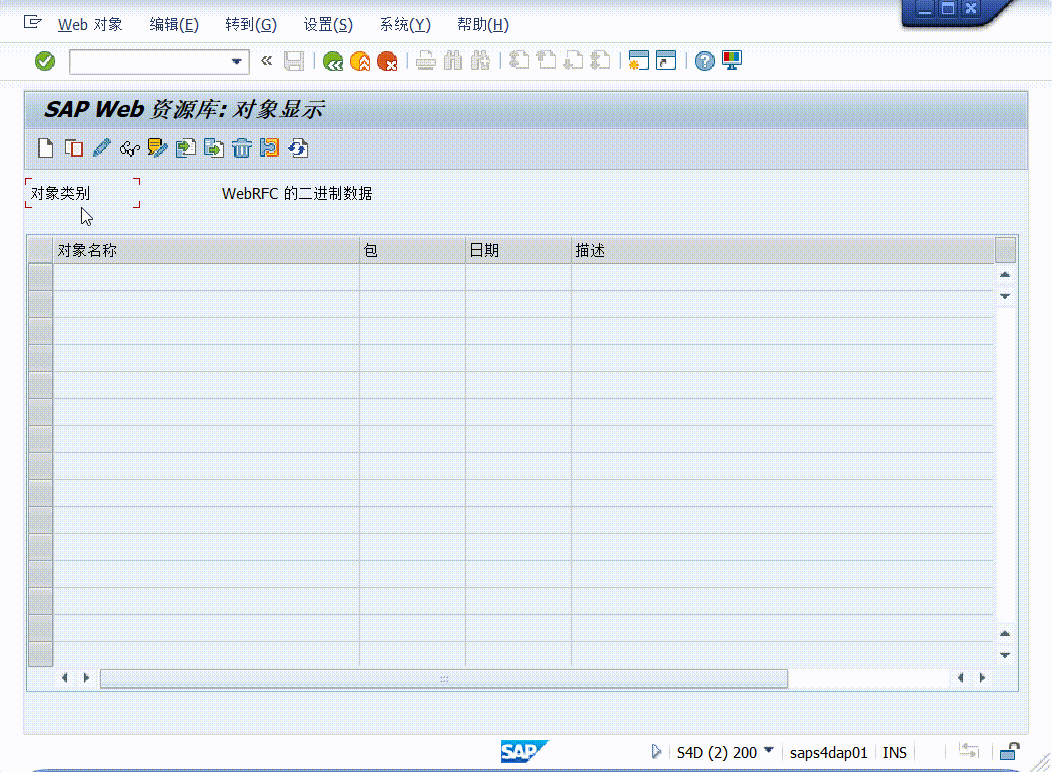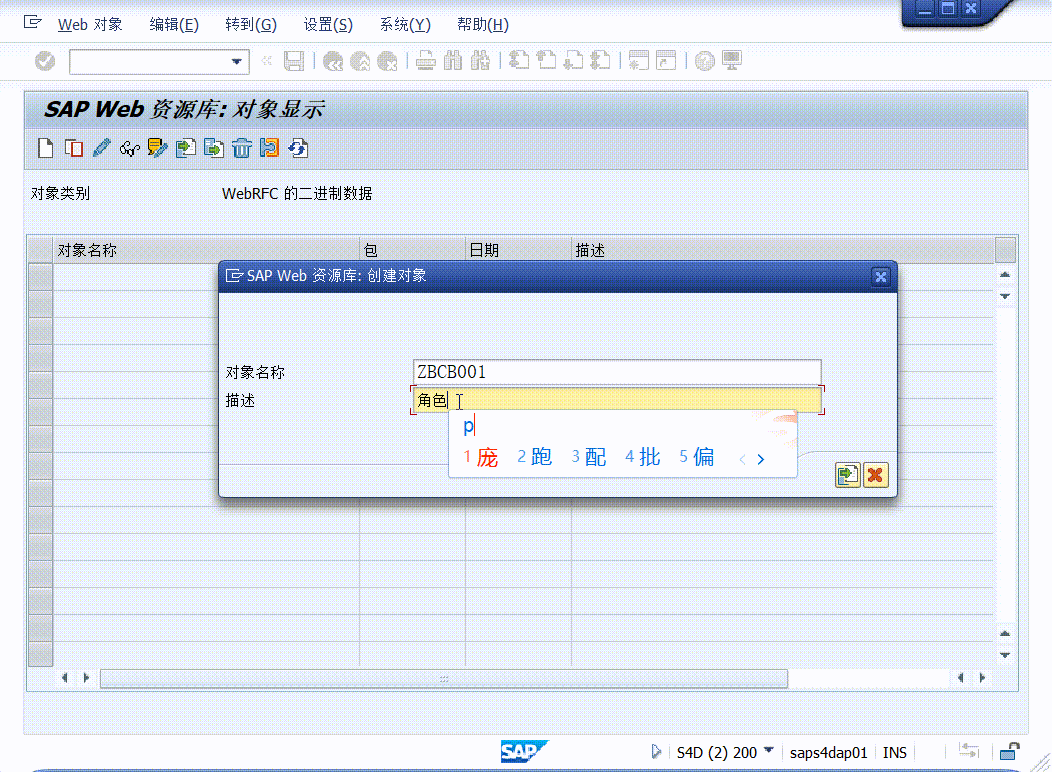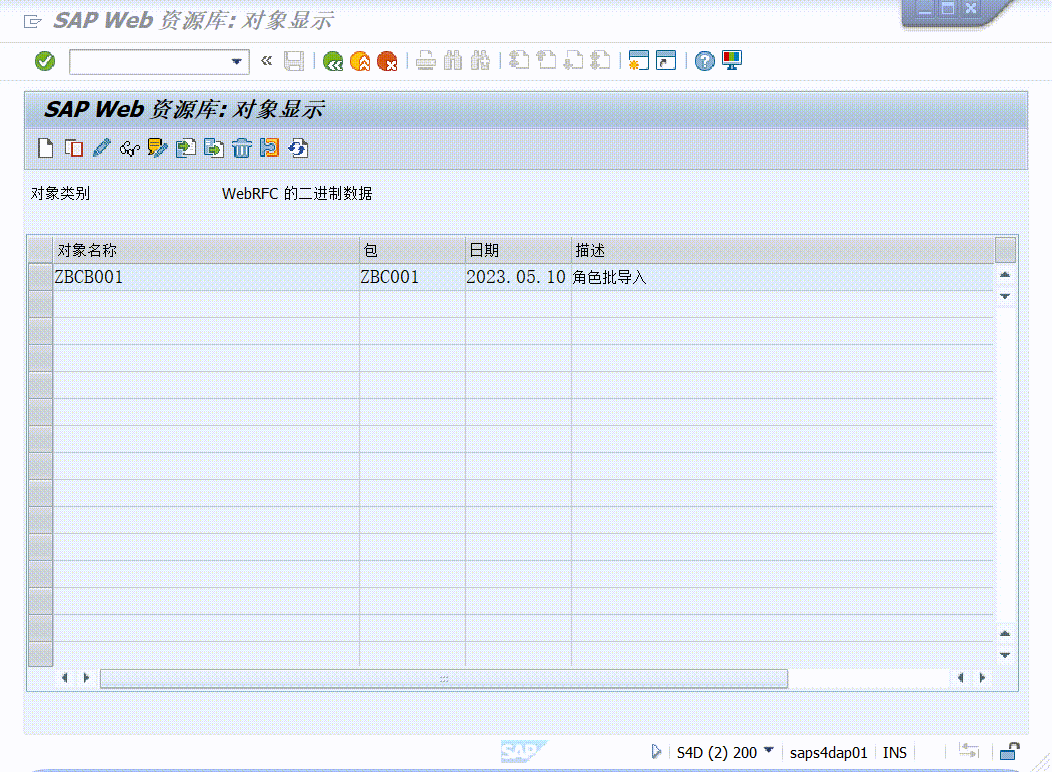
首先仿函数就是一个类,在类里面我们一般可以对各种操作符进行重载比如说对操作符+进行重载使得一个日期类对象加上一个整数可以得到一个新的日期类对象,还可以对操作符++或者–进行重载使得不同的迭代器能够指向新的位置,而()也是一个操作符,这个操作符的功能就是调用函数并传递参数,那这个我们能对()这个操作符进行重载吗?答案是可以的,我们把一个类对象里面重载一个()操作符的类称之为仿函数,然后我们就可以创建类对象,然后通过这个对象来调用仿函数里面的内容。
如何定义一个仿函数
c++中提供了两个仿函数,分别为great和less,这两个仿函数接收两个参数功能就是比较两个数据的大小,如果左边的数据比右边的数据大的话greater仿函数就返回真,如果左边的数据比右边的数据小的话less仿函数就返回真,那这里我们就来模拟实现一下这两个仿函数,首先得创建一个类,并且类的名字就叫greater:
namespace YCF
{
class greater
{
};
}
再在类里面对操作符()进行重载,因为greater仿函数返回的是true或者false,所以重载函数的返回值就是bool,因为这里要接收两个相同且任意类型的参数,所以这里得添加一个类模板,在函数体里面就直接return两个数据相比较的结果就行,那这里的代码就如下:
template<class T>
class greater
{
public:
bool operator()(const T& x, const T& y)
{
return x > y;
}
};
greater是返回x>y的结果,那么less就是返回x<y的结果,所以这里简单的将代码进行一下修改就可以得到less仿函数的模拟实现,那这里的代码如下:
template<class T>
class less
{
public:
bool operator()(const T& x, const T& y)
{
return x < y;
}
};
实现完这两个仿函数之后就可以用这两个仿函数来创建函数对象,并对这个对象进行传参然后就可以实现运算符重载里面的功能,比如说判断打印两个数据中较大的数据就可以这么来实现:
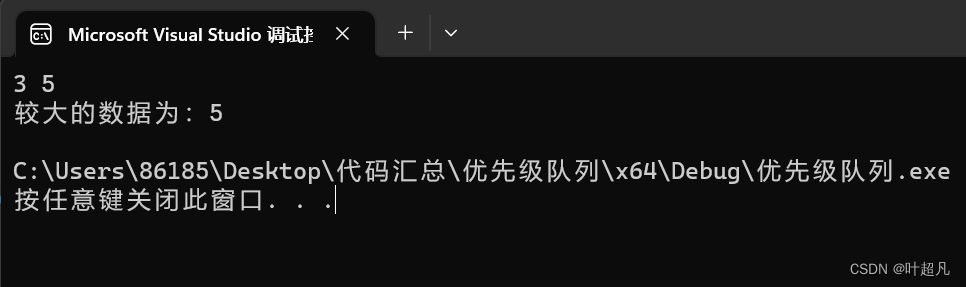
void test2()
{
YCF::greater<int> greaterfunc;
int a, b;
cin >> a >> b;
if (greaterfunc(a, b))
{
cout << "较大的数据为:" << a << endl;
}
else
{
cout << "较大的数据为:" << b << endl;
}
}
这段代码打印的结果如下:

那么这就是仿函数的功能,他跟c语言中的函数指针非常的相似,比如说上面的功能如果使用函数指针的话代码就是这样:
bool func_greater(const int x, const int y)
{
return x > y;
}
typedef bool(*func)(const int x, const int y);
void test3()
{
int a, b;
func p=func_greater;
cin >> a >> b;
if (p(a, b))
{
cout << "较大的数据为:" << a << endl;
}
else
{
cout << "较大的数据为:" << b << endl;
}
}
这段代码运行的结果如下:
那么这就是函数指针实现的代码,大家能够很明显的发现函数指针实现的代码就很麻烦不容易看懂,所以就有了仿函数来代替函数指针,而且仿函数能够添加模板和成员变量进去,能够实现比函数指针更多的功能,比如说我要比较两个浮点数的大小,两个日期类的大小就可以直接通过模板实例化来得到想要的东西,那么这就是仿函数的作用希望大家能够理解。
什么是优先级队列
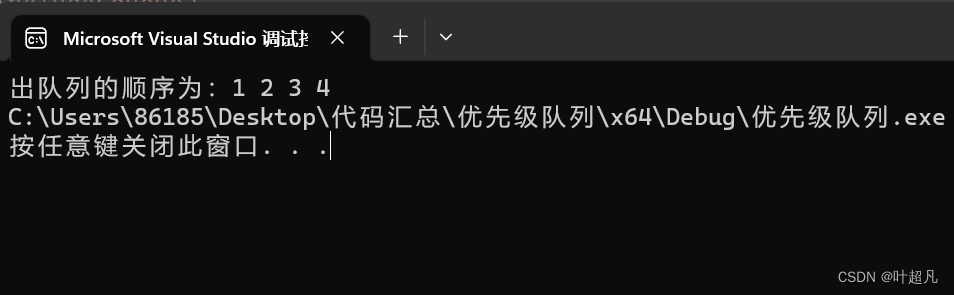
在之前的学习中,大家已经知道了队列对数据处理的方式是先入队列的数据先出数据,后入队列的数据后出队列,比如说下面的代码:
void test1()
{
queue<int> q;
q.push(1);
q.push(2);
q.push(3);
q.push(4);
cout << "出队列的顺序为:";
while (!q.empty())
{
cout << q.front() << " ";
q.pop();
}
}
这段代码的运行结果如下:
queue对数据处理的方式是先入队列的元素先出队列,而身为队列的亲兄弟那优先级队列对数据处理的方式又是什么呢?答案是优先级高的数据优先出队列,比如说把数据的大小作为优先级,那么5的优先级就会比3的优先级要高,在入队列的时候尽管5比3后入队列但是在出队列的时候依然是5先出队列,这里的优先级不仅仅可以是谁的数据大,还可以是谁的数据小,如果把这个作为优先级的话那3的优先级就会比5高,3就会比5先出队列,既然可以将数据的大小作为优先级的话,那我们也可以把日期的远近作为优先级,比如说我们可以创建一个日期类,把谁的日期更加古老作为优先级,那么Data(2018,6,17)的优先级就会比Data(2022,5,2)的优先级要高,在出队列的时候就是Data(2018,6,17)这个数据先出队列,那么这就是优先级队列的用法以及意义,优先级队列的名字叫做 priority_queue,这个容器有如下几个函数:

接下来我们就来看看优先级队列的使用,以及这几个函数的意义。
优先级队列的使用

priority_queue容器有三个模板参数,第一个参数表明容器所容纳的参数类型,第二个参数表明priority_queue底层使用的什么来容纳数据,这里给了一个缺省参数vector说明priority_queue在默认情况下是使用vector来存储数据,第三个参数则是一个仿函,c++提供了两个仿函数:less和greater,priority_queue默认使用less来作为底层的比较逻辑,所以在不传递仿函数的前提下priority_queue创建的是大堆,如果你想要创建小堆的话就得传递一个greater过去,那么这就是priority_queue的三个模板参数,我们再来看看这个容器所包含的函数:

push函数的介绍

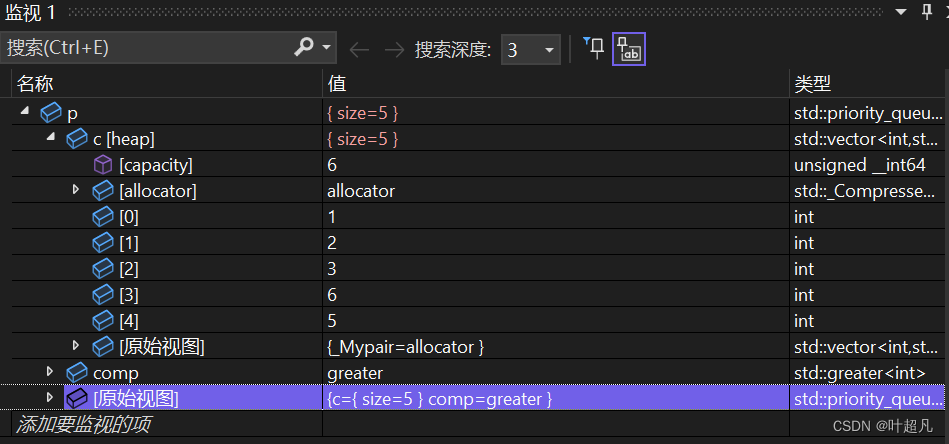
这个函数的作用就是往容器里面插入一个数据,比如说下面的代码:
void test4()
{
priority_queue<int, vector<int>, greater<int>> p;
p.push(5);
p.push(3);
p.push(2);
p.push(6);
p.push(1);
}
通过调试便可以看到对象p中含有我们刚刚插入进去的数据:
empty函数的介绍

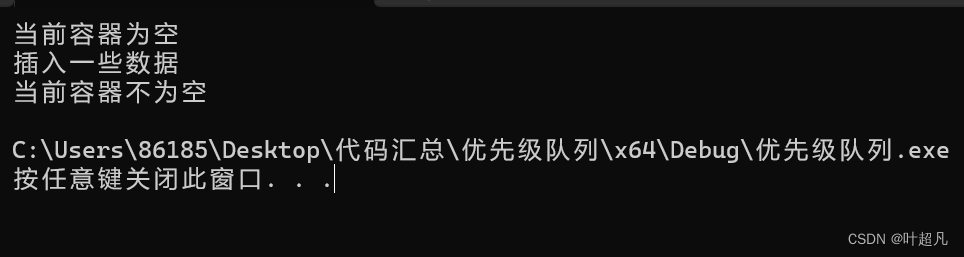
该函数的作用就是检查当前容器是否为空?如果不为空的话就返回false,如果为空的话empty函数就返回true,比如说下面的代码:
void test5()
{
priority_queue<int> p;
if (p.empty())
{
cout << "当前容器为空" << endl;
}
else
{
cout << "当前容器不为空" << endl;
}
cout << "插入一些数据" << endl;
p.push(1);
p.push(2);
if (p.empty())
{
cout << "当前容器为空" << endl;
}
else
{
cout << "当前容器不为空" << endl;
}
}
这段代码运行的结果如下:
那么这就是empty函数的作用。
top函数的介绍
因为priority_queue容器的底层是一个堆,所以堆顶元素是所有元素中优先级最高的,而top函数的作用就是取堆顶元素,比如说下面的代码
void test6()
{
priority_queue<int> big_p;
priority_queue<int, vector<int>, greater<int>> small_p;
big_p.push(1);
small_p.push(1);
big_p.push(3);
small_p.push(3);
big_p.push(5);
small_p.push(5);
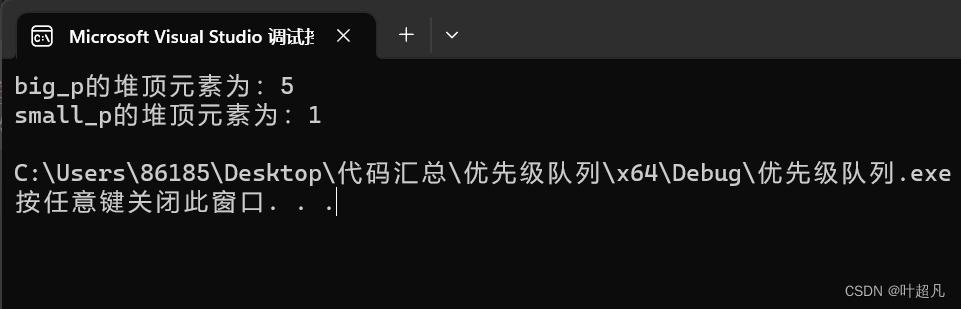
cout << "big_p的堆顶元素为:" << big_p.top() << endl;
cout << "small_p的堆顶元素为:" << small_p.top() << endl;
}
这两个对象当中含有相同的数据内容但是一个是大堆一个是小堆,所以堆顶的元素都不一样,大堆的堆顶元素是所有元素中的最大的,而小堆的堆顶元素是所有元素中最小的,那么这段代码的运行结果如下:
pop函数的介绍
pop函数的官方介绍如下:
pop函数的作用就是删除堆顶的元素也就是删除优先级最高的元素,pop函数执行完之后堆顶元素就会变成优先级第二高的元素比如说下面的代码:
void test7()
{
priority_queue<int> big_p;
big_p.push(1);
big_p.push(2);
big_p.push(3);
big_p.push(4);
cout << "此时容器中的元素为:1 2 3 4" << endl;
cout << "堆顶的元素为:" << big_p.top() << endl;
cout << "删除堆顶的元素" << endl;
big_p.pop();
cout << "此时堆顶的元素为:" << big_p.top() << endl;
}
代码的运行结果为:

size函数的介绍
首先来看看size函数的官方介绍:
这个函数的作用就是告诉你容器里面元素的个数,如果容器里面含有三个元素的话这个函数就会返回3,比如说下面的代码:
void test8()
{
vector<int> v;
v.push_back(1);
v.push_back(2);
v.push_back(3);
v.push_back(4);
v.push_back(5);
v.push_back(6);
priority_queue<int> p(v.begin(),v.end());
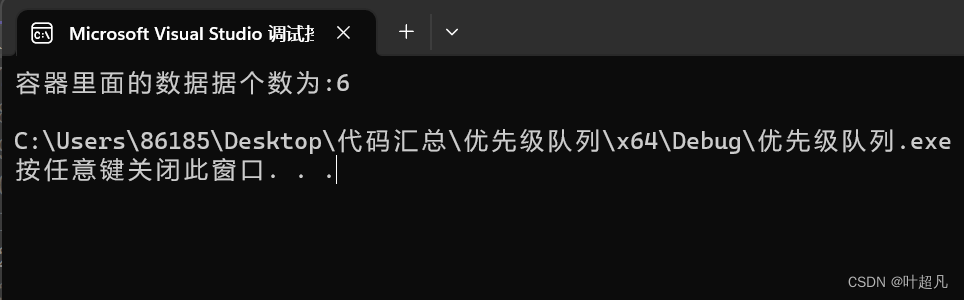
cout << "容器里面的数据据个数为:" << p.size() << endl;
}
这段代码的运行结果如下:
constructor函数介绍

第一个是默认构造函数,第二个就是利用任意类型的迭代器区间来构造priority_queue,比如说采用vector的迭代器区间或者list的迭代器区间来构造priority_queue,比如说下面的代码:
void test8()
{
vector<int> v;
v.push_back(1);
v.push_back(2);
v.push_back(3);
v.push_back(4);
v.push_back(5);
v.push_back(6);
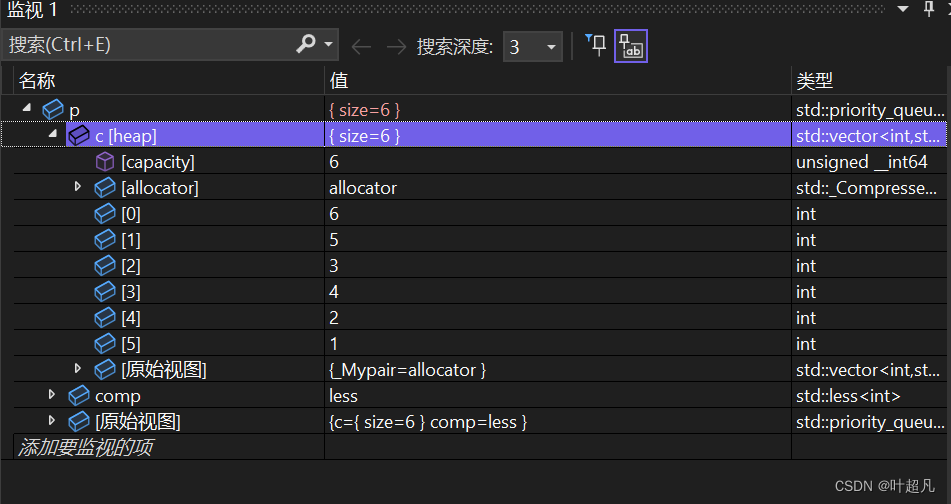
priority_queue<int> p(v.begin(),v.end());
}
通过调试便可以看到容器里面的内容跟迭代器区间里面的内容一摸一样:
那么这就是构造函数的作用。看到这里想必大家应该知道priority_queue的基本用法,那么接下来我们就来尝试模拟实现这个容器。
模拟实现priority_queue
准备工作
首先得创建一个类,并给这个类取名字为priority_queue,因为这个类要容纳各种各样的数据,所以得添加一个模板,又因为该容器采用的是适配器模式,所以我们得在模板中再添加一个参数用于表示底层容乃数据的容器,又因为仿函数有很多种,所以还得添加一个参数用于接收各种各样的仿函数,那这里的代码就如下:
namespace YCF
{
template<class T>
class less
{
public:
bool operator()(const T& x, const T& y)
{
return x < y;
}
};
template<class T>
class greater
{
public:
bool operator()(const T& x, const T& y)
{
return x > y;
}
};
template<class T,class continer=vector<T>,class compare=less<T> >
class priority_queue
{
public:
private:
continer con;
};
}
top函数的实现
因为这里采用的是容器适配器模式,所以我们可以直接使用方括号重载调用下标为0的元素来实现该函数,那么这里的代码如下:
const T& top()
{
return con[0];
}
size函数的实现
这个也是同样的道理调用底层容器的size函数来实现该函数,那这里的代码就如下:
size_t size()
{
return con.size();
}
empty函数的实现
这个也是同样的代码可以调用底层容器的empty函数来实现该函数,那这里的代码就如下:
bool empty()
{
return con.empty();
}
adjustup函数的实现
adjustup函数的功就是将新插入进行来的数据进行向上调整,虽然堆的底层看上去是vector,各种数据没有任何的联系,但事实上每个数据都是有联系的,比如说vector中的元素为:1 2 3 4 5 6 7 8 9,但是通过一些联系,我们可以将这一行元素想象成为这样:
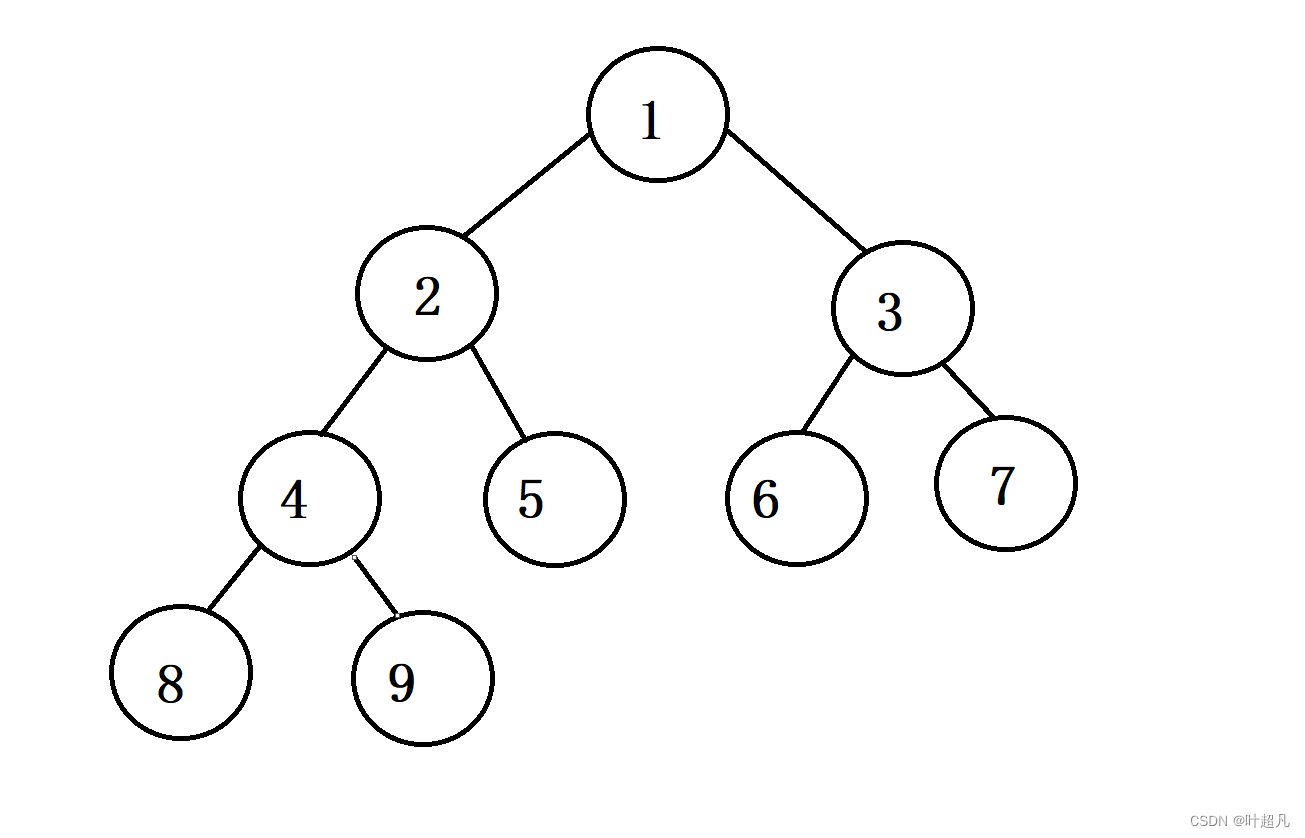
下标为i的节点的父节点的下标为(i-1)/2,根据这个关系我们就可以找到每个节点的父节点,我们把上面的树状结构称为堆,堆又分为大堆和小堆,大堆的每个节点的值都要比子节点的值要大,而小堆的每个节点的值都要比子节点要小,所以当我们往容器的尾部插入一个数据时,这个数据可能会破坏原来的树状结构使得不再成为大堆或者小堆,比如说尾插一个0到容器的尾部,这个时候树状结构就变成了这样:
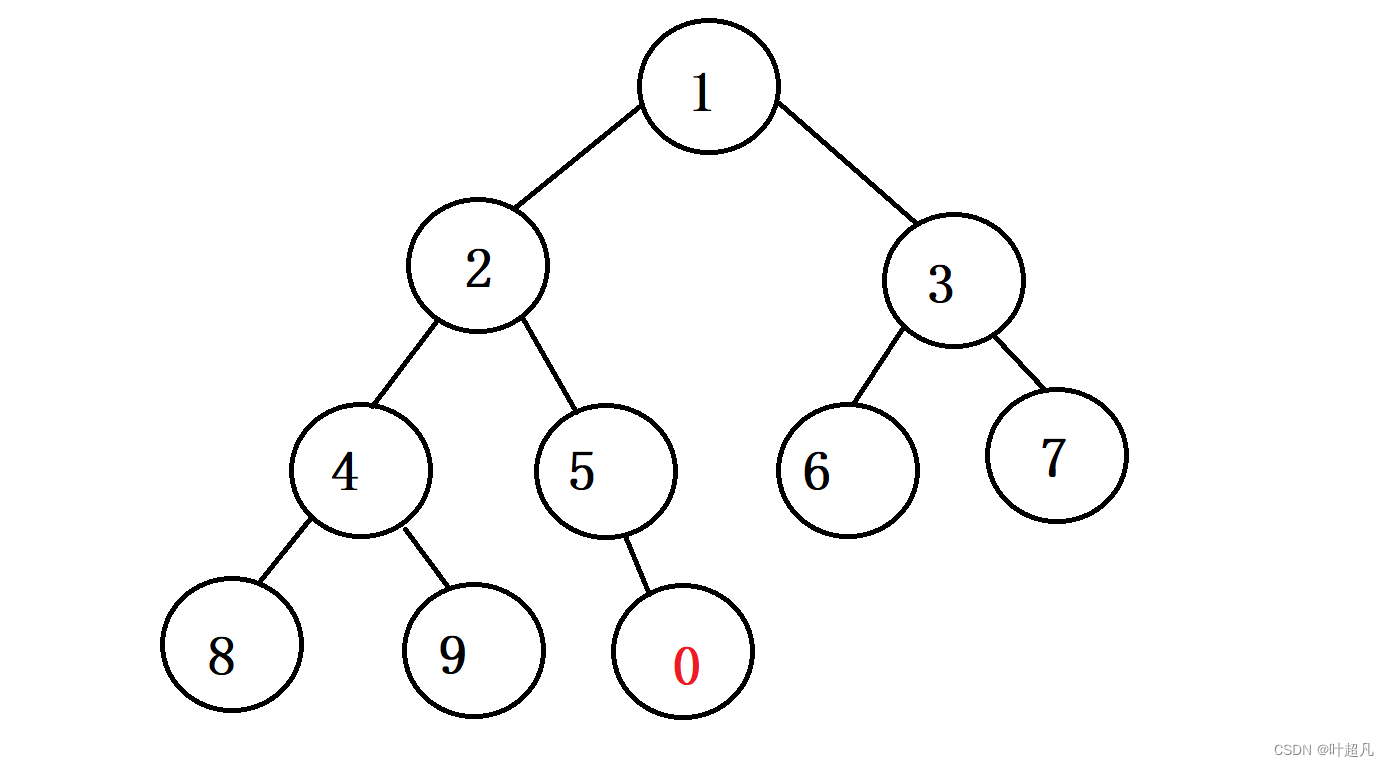
不符合小堆的规律所以就得对值为0的节点进行向上调整,首先值为0的节点下标为9,那么他的父节点的下标就为(9-1)/2等于4,将子节点的值与父节点进行比较,因为这是小堆并且子节点的值要比父节点的小,所以我们得把子节点的值和父节点的值进行一下交换,那这时树状图就变成了这样:
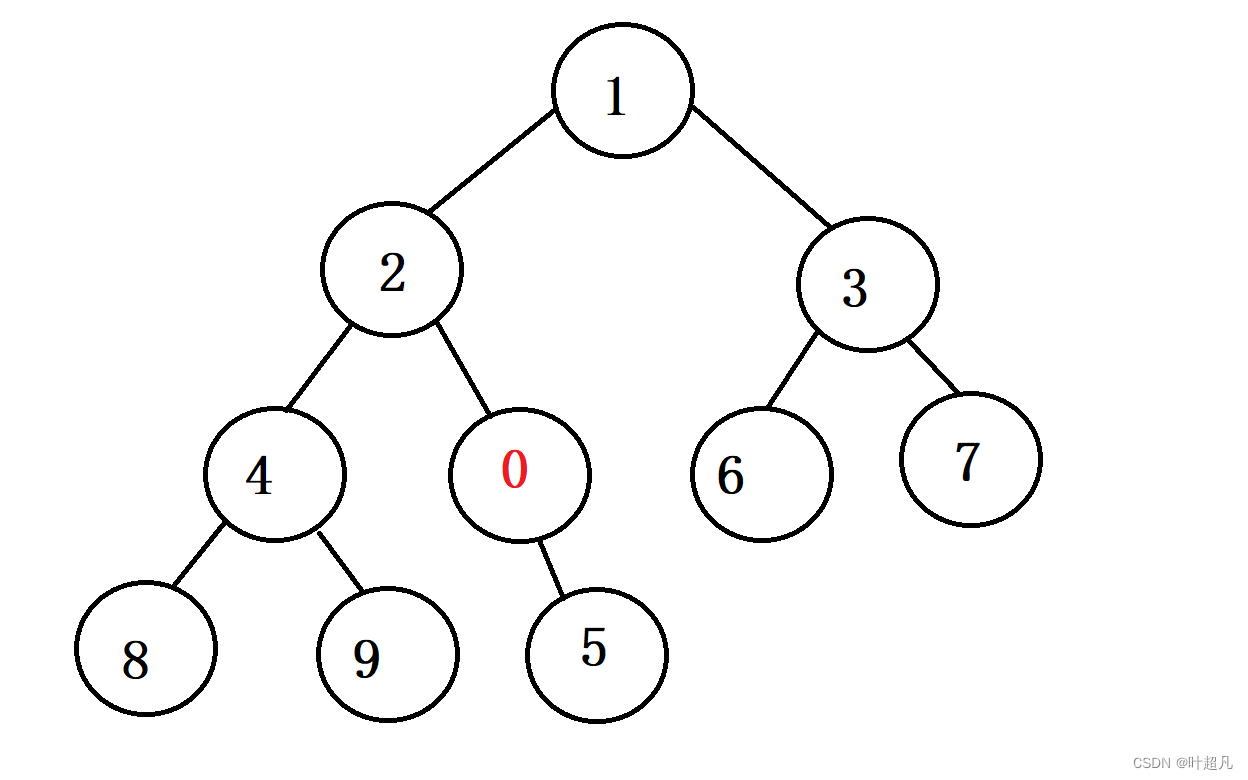
交换完之后,调整的任务依然没有结束,因为这时新插入的节点下标变成了4他有了一个新父亲,父亲节点的下标为1,所以还得进行一次比较又因为子节点的值比父节点的值要小,所以还得进行一下交换,那这时树状图变成了这样;
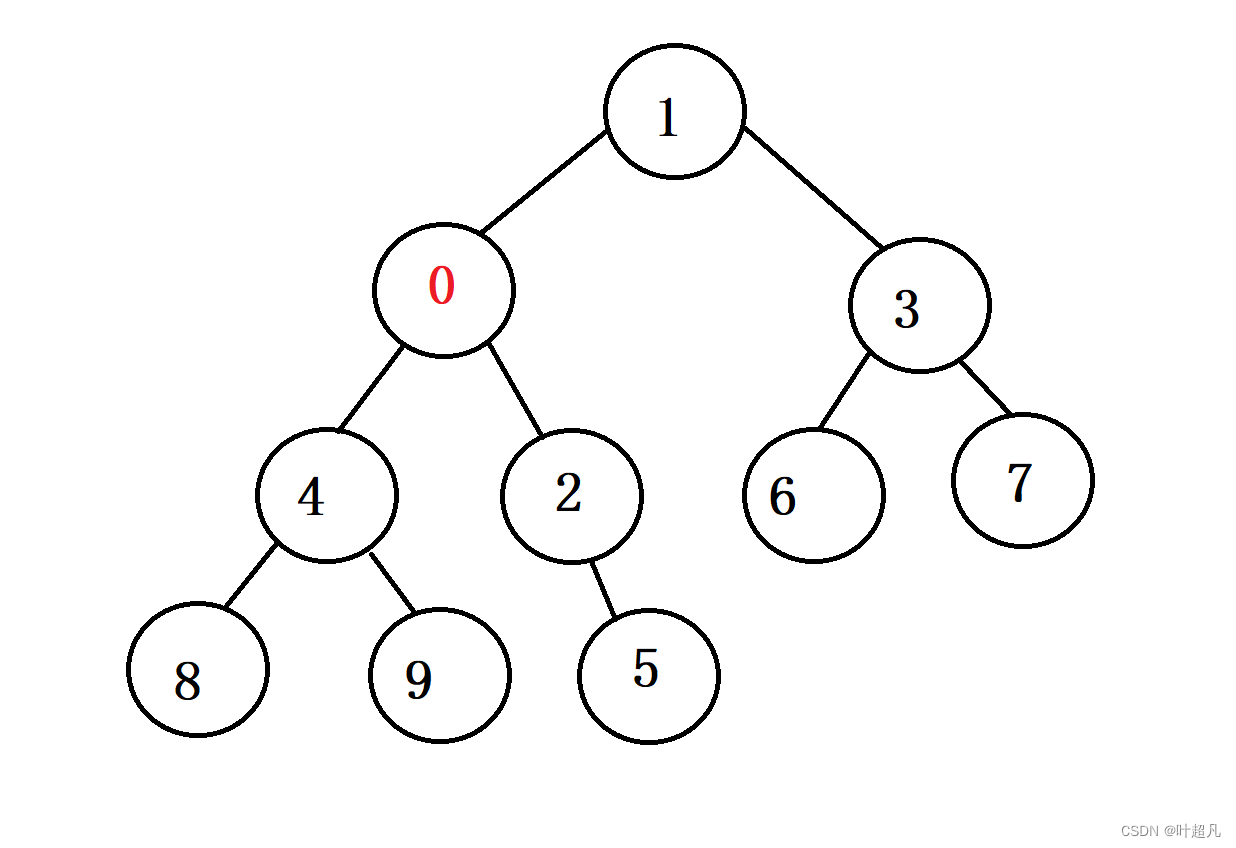
同样的道理这里依然会再进行一次比较,因为父节点比子节点大,所以这里又会进行一次交换,那这时树状图的形状就成为了这样:
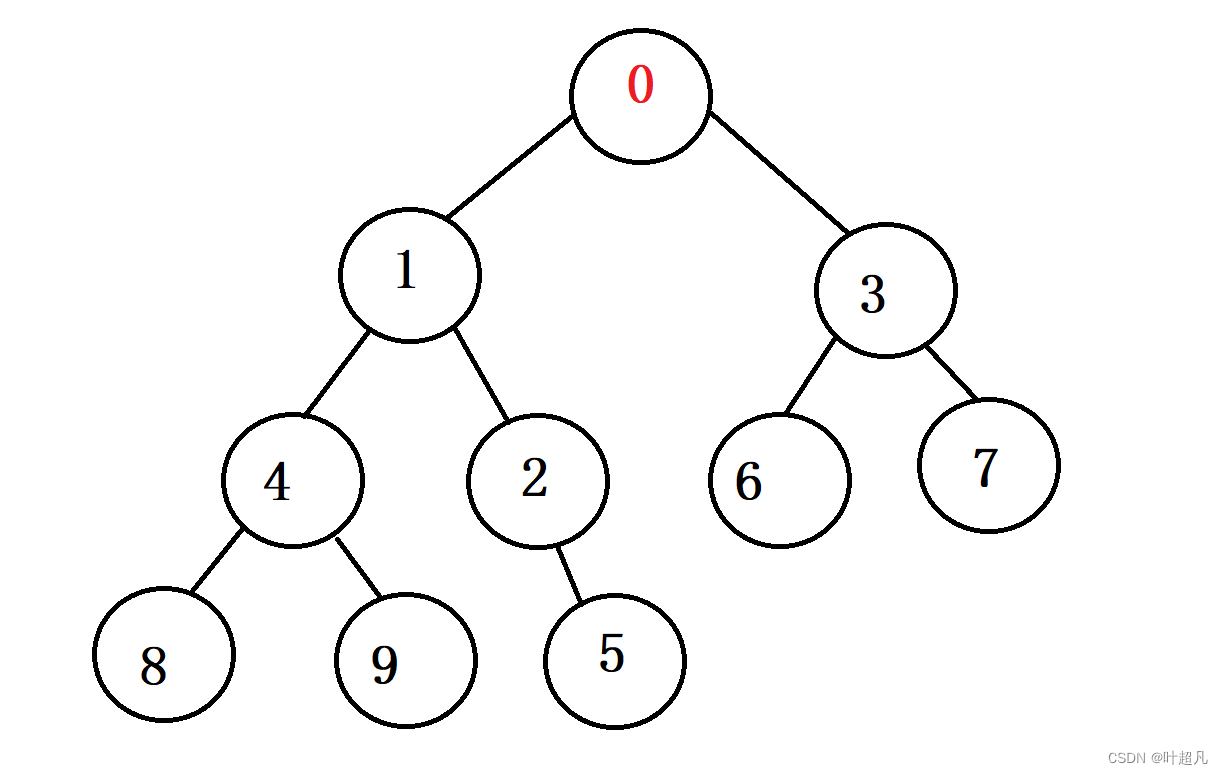
那这时就不会再进行比较因为新插入的节点已经来到了根节点的位置他没有父节点了所以就不用再进行比较,这里只展示了一种情况,还有一种就是当子节点的优先级比父节点低时就不用进行比较(就是大堆时,子节点的值比父节点的值要小,小堆时子节点的值要比大堆大),有了上面的过程想必大家应该能够理解调整的过程,那这里我们就来实现一个adjustup函数,首先这个函数得接收一个参数用于告诉我们要调整的参数的下标为多少,并且函数的返回值为void,那这里函数的声明如下:
void adjustup(size_t child)
{
}
因为模板中有个参数为仿函数,所以首先得通过这个仿函数创建出来一个仿函数对象用于以后的比较,然后再创建一个名为_child的变量并使用函数的参数child对其进行初始化,因为这里需要多次进行调整,所以我们创建一个while循环,每一次循环都将子节点的值与父节点进行比较,如果比较的结果为真那么就对数据进行交换并修改迟child的值,如果比较的结果为假,那么就使用break语句跳出循环,这时数据的调整就完成了,那么这里的代码就如下:
void adjustup(size_t child)
{
size_t _child = child;
compare com;
while ()
{
size_t _parent = (_child - 1) / 2;
if (com())
{
swap(con[_parent], con[_child]);
_child = _parent;
}
else
{
break;
}
}
}
这里我们就得思考两个问题,第一个就是循环什么时候结束,答案很简单新插入的节点调到了正确的位置时就结束,这个正确的位置分为两种情况一个是根节点,另外一个是子节点的优先级比父节点的优先级低的位置,第二个情况通过if else语句的break实现了,那么第一种情况就是当子节点的下标小于等于0时就结束循环,好解决完循环的问题之后就来看看第二个问题,com仿函数对象的参数怎么传,库中的priority_queue传递less函数时建立的是一个大堆,当less的第一个参数小于第二个参数时这个仿函数对象就会返回true,所以当父节点的值小于子节点的值时就交换两个节点的值,所以com仿函数对象的第一个参数就是parent,第二个参数就是child,那么这里代码就如下
void adjustup(size_t child)
{
size_t _child = child;
compare com;
while (_child>0)
{
size_t _parent = (_child - 1) / 2;
if (com(con[_parent],con[_child]))
{
swap(con[_parent], con[_child]);
_child = _parent;
}
else
{
break;
}
}
}
push函数的实现
有了adjustup函数,push函数的实现就非常的简单,首先调用底层容器的push_back函数将数据尾插到容器的尾部,然后再调用adjustup函数对其进行向上调整便可以实现数据插入的功能,那么这里的代码实现如下:
void push(const T& x)
{
con.push_back(x);
adjustup(con.size() - 1);
}
有了push函数我们就可以对上面写的函数来进行一下验证看看函数的实现是否是正确的,那这里测试的代码就如下:
void test9()
{
YCF::priority_queue<int> q;
q.push(1);
q.push(2);
q.push(3);
q.push(4);
q.push(5);
if (!q.empty())
{
cout << "此时的容器不为空" << endl;
}
cout << "容器的顶部数据为:" << q.top() << endl;
cout << "容器的数据个数为:" << q.size() << endl;
}
这段代码的运行结果如下:
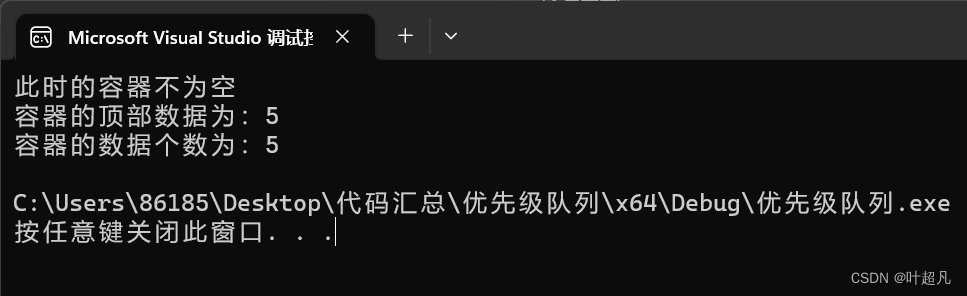
那么这里的运行结果就是正确的,说明我们上面的代码实现的是正确的。
pop函数的实现
pop函数的功能就是删除堆顶的元素,但是这里的删除并不是简单的删除,因为我们得保证删除数据之后还能维持大堆或者小堆属性,那么这里就得采用特殊的删除策略,首先得将堆顶的元素和最后一个元素进行交换,然后再删除容器中的最后一个元素,比如说下面的图片:
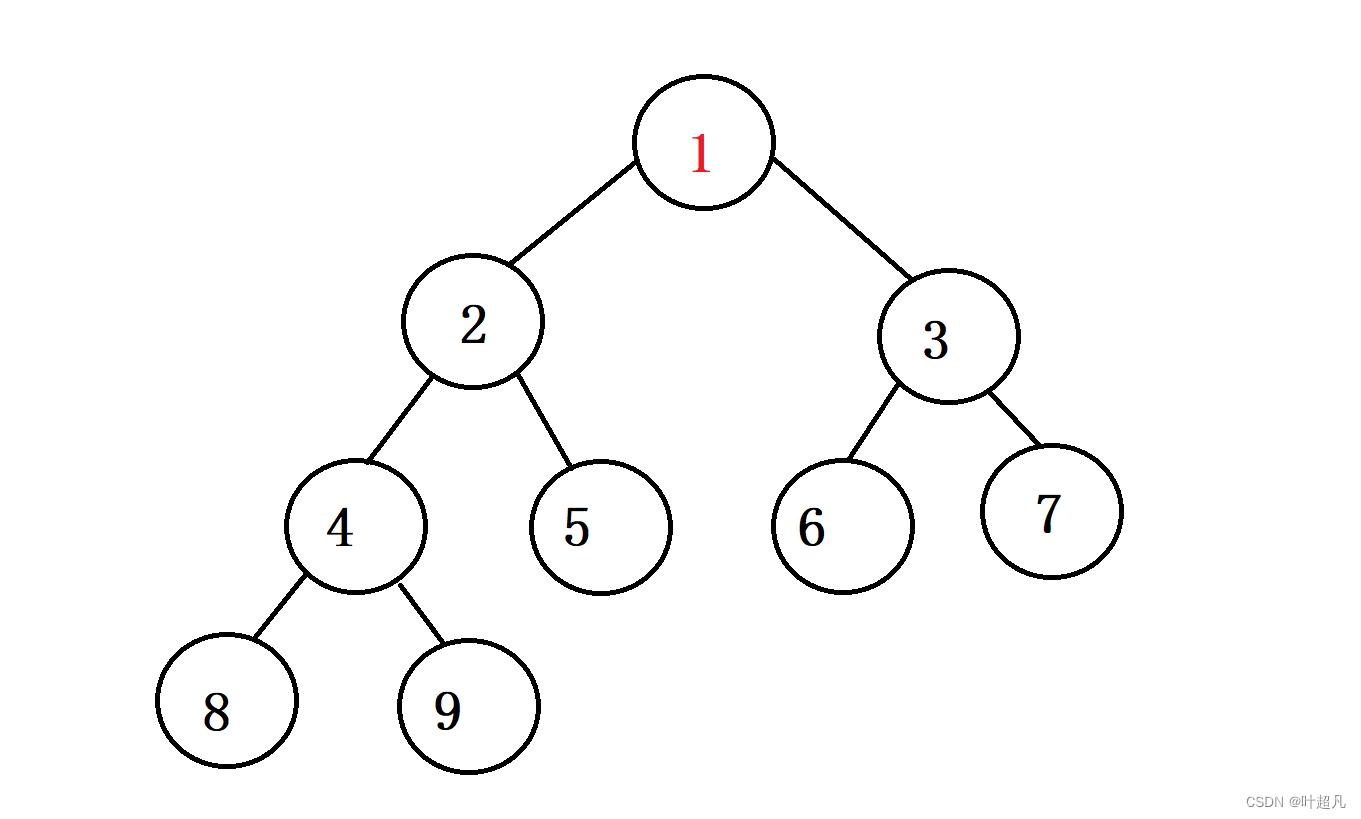
将堆顶的元素和队尾的元素进行交换:
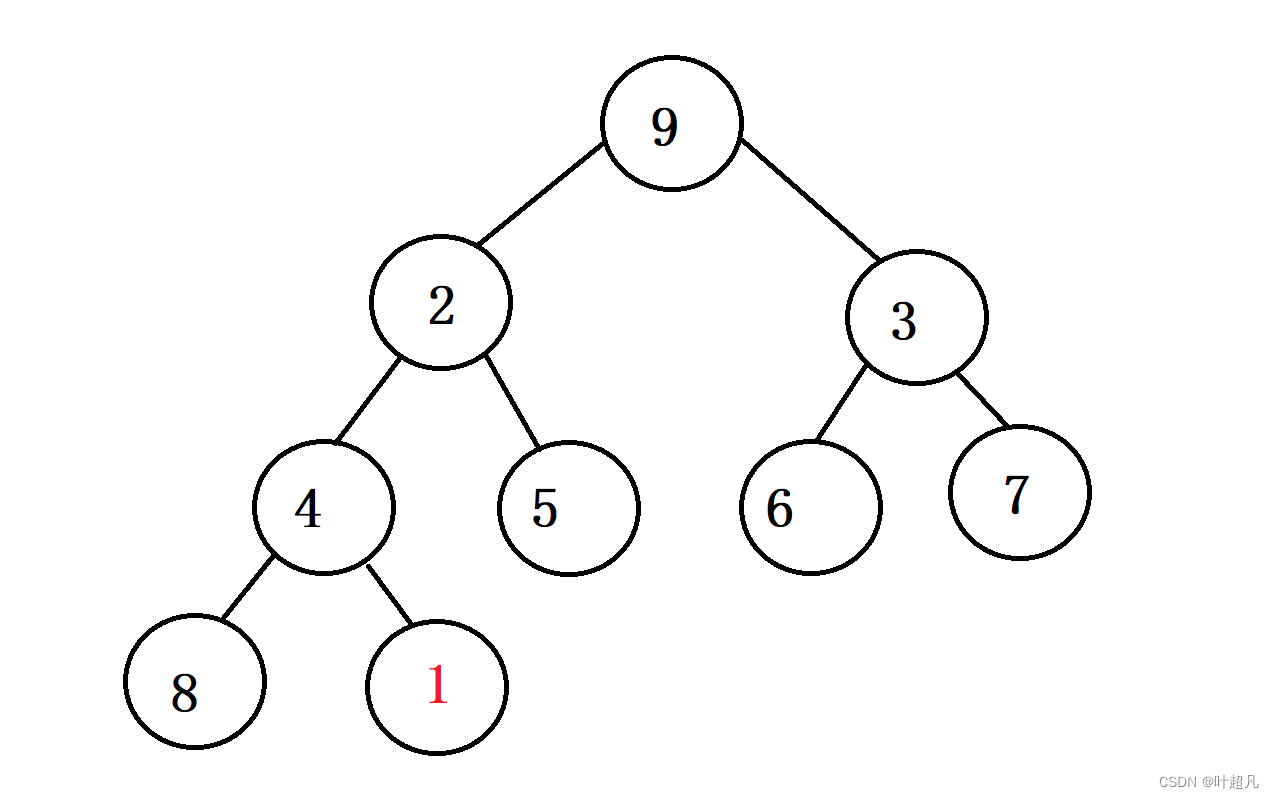
再将队尾的元素进行删除
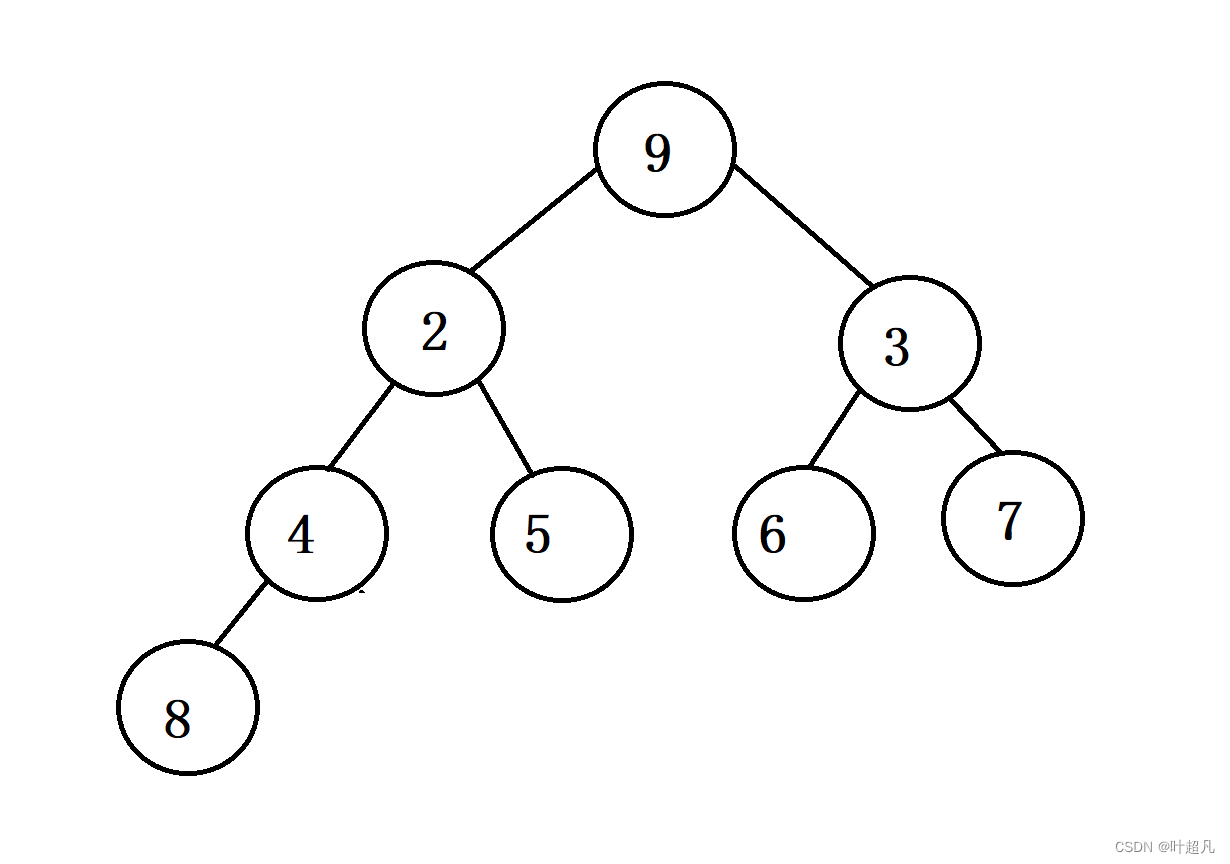
经过上面的操作我们已将之前头顶的数据给删除了,但是我们还得做一个操作就是将当前头顶的元素向下调整使得他在一个正确的位置这样才能成为堆。那么这里就得实现一个adjustdown函数,那么pop函数的完整代码就如下:
void pop()
{
swap(con[0], con[con.size() - 1]);
con.pop_back;
adjustdown(0);
}
接下来我们就要看看adjustdown函数是如何来实现的。
adjustdown函数的实现
经过一些操作数据的形状就变成了这样:
我们要对堆顶的元素进行向下调整,第一步就是将该节点的两个子节点进行比较,得到优先级较高的节点,然后再有优先级较高的节点和该节点进行比较,看谁的优先级更高,比如说上面的图片,由于这里建立的是小堆所以字节2的优先级要比子节点3的优先级要高,所以拿2和9进行比较,因为子节点2 的优先级又比根节点9的优先级要高所以这里得将2和9的位置进行一下替换,那么图片就变成了下面的样子:
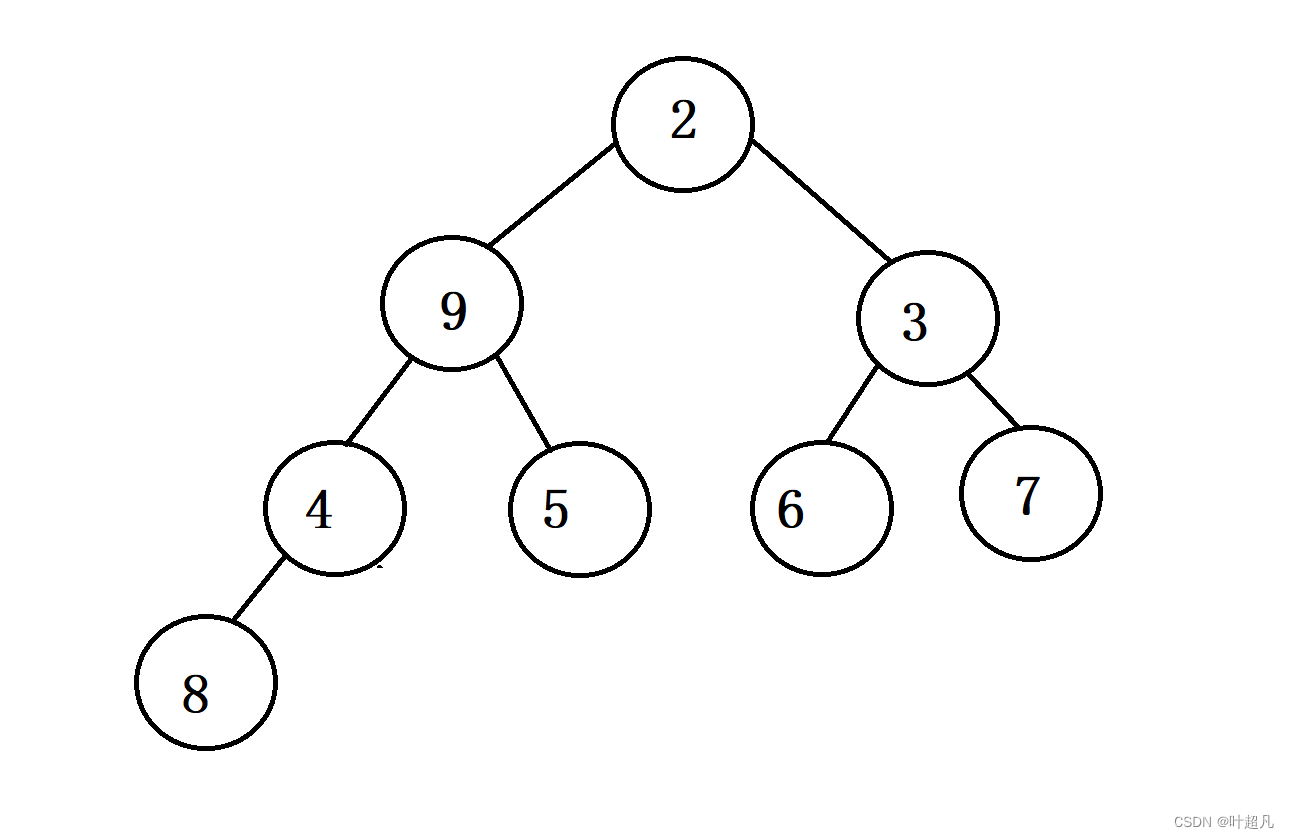
同样的道理9又会和新的两个两个子节点进行比较这样一直不停的比较替换比较下去,知道9没有根节点为止或者9的两个子节点的优先级都比它小为止,那么接下我们就实现一下这个代码,首先来实现一下这个函数的声明,这个函数有一个参数表明要向下调整的元素下标为多少,然后这个函数的返回值为void,那么这里的代码就如下:
void adjustdown(size_t size)
{
}
然后创建两个变量一个称为parent一个称为child,将参数size的值初始化给parent,那child的值该是多少呢?那么这里我们采用这样的一个方法,首先默认child的值是左孩子,然后让左孩子和右孩子进行比较,如果右孩子存在且右孩子的优先级比左孩子大的话我们就让child指向右孩子,那么这里的代码就如下:
void adjustdown(size_t size)
{
size_t _parent = size;
size_t _child = _parent * 2 + 1;
if ((_child + 1 < con.size() - 1) && com(con[_child], con[_child + 1]))
{
_child += 1;
}
}
然后我们就要比较parent和child的优先级,因为这里的比较不只比较一次,所以我们得创建一个while循环,在循环体里面如果子节点的优先级大于父节点就使用swap函数交换两个节点的值并更新parent和child的值,相反则使用break函数结束循环,当child的值大于容器数据个数的时候则结束循环,那么完整的代码就如下:
void adjustdown(size_t size)
{
compare com;
size_t _parent = size;
size_t _child = _parent * 2 + 1;
while (_child < con.size())
{
if ((_child + 1 < con.size()) && com(con[_child], con[_child + 1]))
{
_child += 1;
}
if (com(con[_parent], con[_child]))
{
swap(con[_parent], con[_child]);
_parent = _child;
_child = _parent * 2 + 1;
}
else
{
break;
}
}
}
我们可以通过下面的代码来测试一下:
void test9()
{
YCF::priority_queue<int> q;
q.push(1);
q.push(2);
q.push(3);
q.push(4);
q.push(5);
if (!q.empty())
{
cout << "此时的容器不为空" << endl;
}
cout << "容器的顶部数据为:" << q.top() << endl;
cout << "容器的数据个数为:" << q.size() << endl;
q.pop();
cout << "删除堆顶的数据" << endl;
cout << "容器的顶部数据为:" << q.top() << endl;
cout << "容器的数据个数为:" << q.size() << endl;
q.pop();
cout << "删除堆顶的数据" << endl;
cout << "容器的顶部数据为:" << q.top() << endl;
cout << "容器的数据个数为:" << q.size() << endl;
}
代码的运行结果如下:
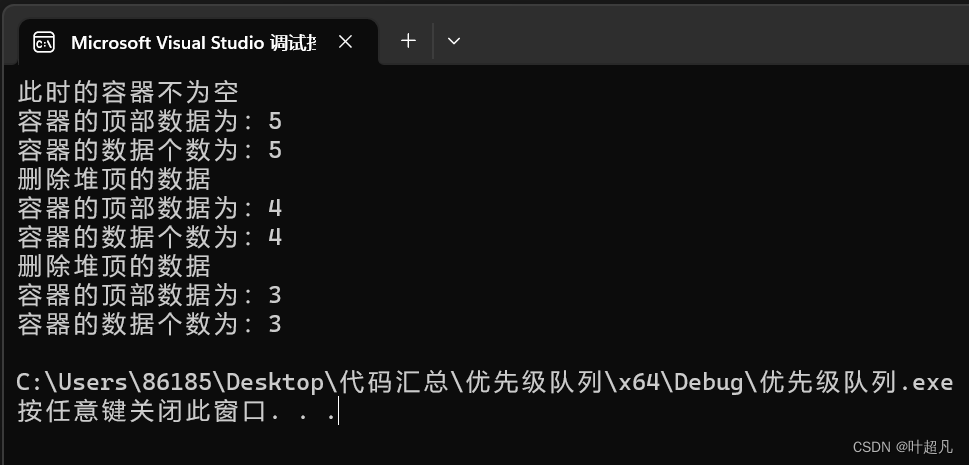
那么这就说明我们的代码实现是正确的。
构造函数的实现
本篇文章的最后再来看看该容器的构造函数如何来实现,一个是默认构造函数,一个是迭代器区间的构造函数,因为该容器的底层采用其他的容器来记录数据,所以在默认构造函数里面我们就什么事情也用干,编译器自己会调用底层容器的默认构造来初始化数据,那么这个构造函数的代码如下:
priority_queue()
{
}
另外一个构造函数就是迭代器区间构造函数,这个构造函数得接收两个迭代器,因为迭代器的形式各种各样,所以得对这个函数添加一个模板,那么这里的代码如下:
template<class iterator>
priority_queue(iterator begin, iterator end)
{
}
在函数体里面我们就可以创建一个while循环,在循环里面不停的使用push函数将输出插入到优先级队列里面,循环结束的条件就是当begin等于end的时候结束循环,那么这里的代码就如下:
template<class iterator>
priority_queue(iterator begin, iterator end)
{
while (begin != end)
{
push(*begin);
++begin;
}
}
那这里我们可以写一段代码来测试一下上面的函数正确性:
void test10()
{
vector<int> v;
v.push_back(1);
v.push_back(2);
v.push_back(3);
v.push_back(4);
v.push_back(5);
YCF::priority_queue<int> q(v.begin(), v.end());
}
这里采用的是自己写的构造函数,我们可以通过调试来看看容器里面的内容:
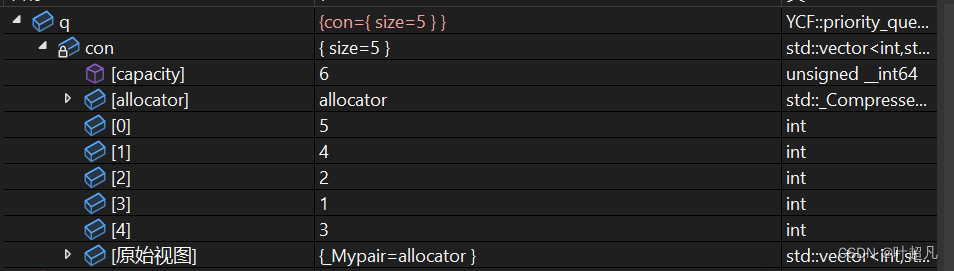
数据的顺序为5 4 2 1 3 ,我们将前面的命名空间去掉,使用库中的优先级队列再查看里面的内容就会发现好像内容不大一样:
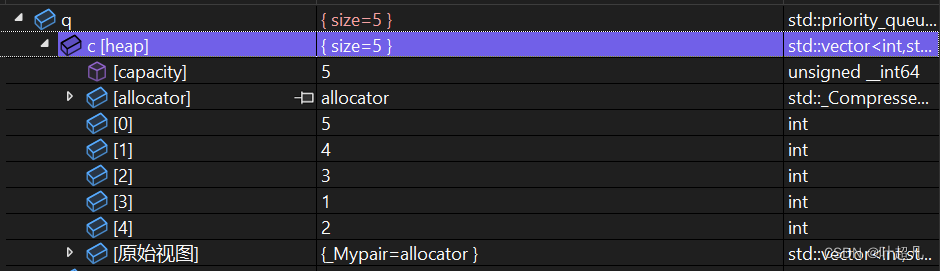
库中的数据顺序为 5 4 3 1 2 那这是为什么呢?难道我们之前写的代码是错误的吗?答案是库中采用向下调整的方法来实现的构造函数,向下调整的代码如下:
template<class iterator>
priority_queue(iterator begin, iterator end)
:con(begin,end)
{
for (int i = (con.size() - 1) / 2; i >= 0; --i)
{
adjustdown(i);
}
}
那么这就是向下调整的代码,使用这种方式初始化代码得到的结果就和库中的一摸一样。那么以上就是本篇文章的全部内容希望大家能够理解。