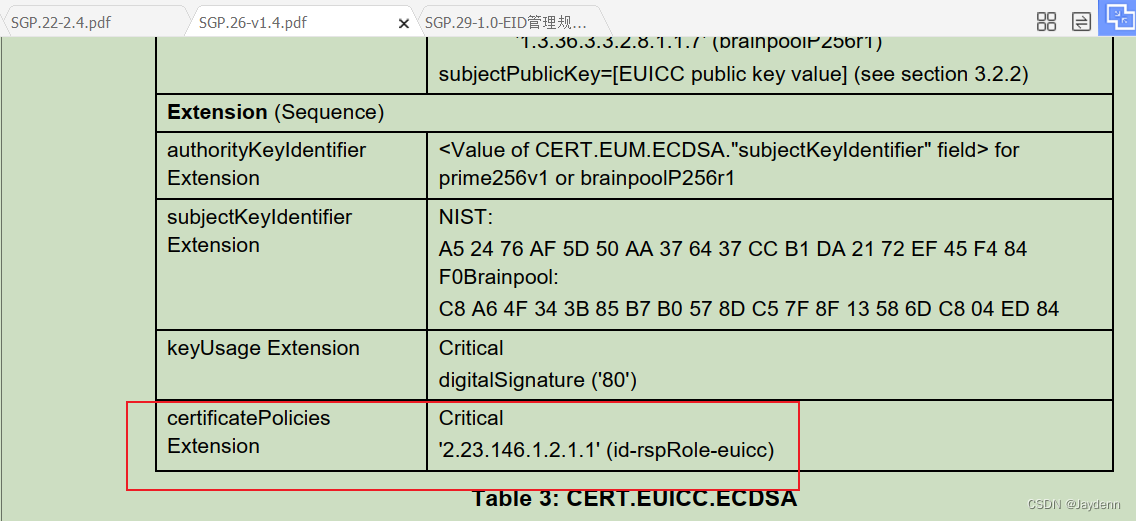
案例说明:
KingbaseES V8R3集群默认在触发failover切换后,为保证数据安全,原主库需要通过人工介入后,恢复为新的备库加入到集群。在无人值守的现场环境,需要在触发failover切换后,主库可以自动恢复为新备考加入集群,提升架构的高可用性。
适用版本: KingbaseES V8R3
集群架构:
node_id | hostname | port | status | lb_weight | role | select_cnt | load_balance_node | replicatio
n_delay
---------+---------------+-------+--------+-----------+---------+------------+-------------------+-----------
--------
0 | 192.168.1.101 | 54321 | up | 0.500000 | standby | 0 | true | 0
1 | 192.168.1.102 | 54321 | up | 0.500000 | primary | 0 | false | 0
(2 rows)一、配置AUTO_PRIMARY_RECOVERY参数
Tips: AUTO_PRIMARY_RECOVERY参数配置在HAmodule.conf文件中,需要修改db和kingbasecluster目录下相关配置文件。
[kingbase@node102 bin]$ cat ../etc/HAmodule.conf |grep -i auto
#automatic recovery log path.example:RECOVERY_LOG_DIR="./log/recovery.log"
#whether to turn on automatic recovery,0->off,1->on.example:AUTO_PRIMARY_RECOVERY="1"
AUTO_PRIMARY_RECOVERY=0
---如上所示,默认AUTO_PRIMARY_RECOVERY=0不支持主库在failover切换后,自动降为备库加入到集群。如下图所示:配置主库自动恢复
二、failover切换测试
1、模拟主库数据库服务down
[kingbase@node102 bin]$ ./sys_ctl stop -D ../data
waiting for server to shut down.... done
server stopped2、切换后集群节点状态
TEST=# show pool_nodes;
node_id | hostname | port | status | lb_weight | role | select_cnt | load_balance_node | replicatio
n_delay
---------+---------------+-------+--------+-----------+---------+------------+-------------------+-----------
--------
0 | 192.168.1.101 | 54321 | up | 0.500000 | primary | 0 | true | 0
1 | 192.168.1.102 | 54321 | up | 0.500000 | standby | 0 | false | 0
(2 rows)
---如上所示,failover切换后,集群恢复正常,原主库(102)作为备库加入到集群。3、主备流复制状态
TEST=# select * from sys_stat_replication;
PID | USESYSID | USENAME | APPLICATION_NAME | CLIENT_ADDR | CLIENT_HOSTNAME | CLIENT_PORT | BACK
END_START | BACKEND_XMIN | STATE | SENT_LOCATION | WRITE_LOCATION | FLUSH_LOCATION | REPLAY_LOCAT
ION | SYNC_PRIORITY | SYNC_STATE
-------+----------+---------+------------------+---------------+-----------------+-------------+-------------
------------------+--------------+-----------+---------------+----------------+----------------+-------------
----+---------------+------------
16942 | 10 | SYSTEM | node2 | 192.168.1.102 | | 16773 | 2023-02-22 1
4:29:08.870998+08 | | streaming | 0/D001FDF0 | 0/D001FDF0 | 0/D001FDF0 | 0/D001FDF0
| 2 | sync
(1 row)三、查看failover切换日志
如下所示,执行failover_stream.sh触发failover切换。
1、新主库failover.log
-----------------2023-02-22 14:28:13 failover beging---------------------------------------
----failover-stats is %H = hostname of the new master node [192.168.1.101], %P = old primary node id [1], %d = node id[1], %h = host name [192.168.1.102], %O = old primary host[192.168.1.102] %m = new master node id [0], %M = old master node id [0], %D = database cluster path [/home/kingbase/cluster/HAR3/db/data].
----ping trust ip
ping trust ip 192.168.1.1 success ping times :[3], success times:[2]
----determine whether the faulty db is master or standby
master down, let 192.168.1.101 become new primary.....
2023-02-22 14:28:15 del old primary VIP on 192.168.1.102
es_client connect host:192.168.1.102 success, will stop old primary db and del the vip
stop the old primary db
DEL VIP NOW AT 2023-02-22 14:28:15 ON enp0s3
sys_ctl: PID file "/home/kingbase/cluster/HAR3/db/data/kingbase.pid" does not exist
Is server running?
execute: [/sbin/ip addr del 192.168.1.204/24 dev enp0s3]
Oprate del ip cmd end.
2023-02-22 14:28:15 add VIP on 192.168.1.101
ADD VIP NOW AT 2023-02-22 14:28:15 ON enp0s3
execute: [/sbin/ip addr add 192.168.1.204/24 dev enp0s3 label enp0s3:2]
execute: /home/kingbase/cluster/HAR3/db/bin//arping -U 192.168.1.204 -I enp0s3 -w 1
Success to send 1 packets
2023-02-22 14:28:15 promote begin...let 192.168.1.101 become master
check db if is alive
ksql "port=54321 user=SUPERMANAGER_V8ADMIN dbname=TEST connect_timeout=10" -c "select 33333;"
2023-02-22 14:28:16 kingbase is ok , to prepare execute promote
execute promote
server promoting
check db if is alive after promote
ksql "port=54321 user=SUPERMANAGER_V8ADMIN dbname=TEST connect_timeout=10" -c "select 33333;"
2023-02-22 14:28:16 after execute promote , kingbase status is ok.
after execute promote, kingbase is ok.
2023-02-22 14:28:16 sync to async
ALTER SYSTEM
SYS_RELOAD_CONF
-----------------
t
(1 row)
2023-02-22 14:28:16 make checkpoint
check the db to see if it is alive
ksql "port=54321 user=SUPERMANAGER_V8ADMIN dbname=TEST connect_timeout=10" -c "select 33333;"
2023-02-22 14:28:16 kingbase is ok , to prepare execute checkpoint
execute checkpoint
CHECKPOINT
check the db to see if it is alive after execute checkpoint
ksql "port=54321 user=SUPERMANAGER_V8ADMIN dbname=TEST connect_timeout=10" -c "select 33333;"
2023-02-22 14:28:16 after execute checkpoint, kingbase is ok.
after execute checkpoint, kingbase is ok.
-----------------2023-02-22 14:28:16 failover end---------------------------------------2、原主库recovery.log
如下所示,在failover切换后,通过sys_rewind将原主库恢复为备库,并加入到集群。
---------------------------------------------------------------------
2023-02-22 14:29:01 recover beging...
my pid is 21729,officially began to perform recovery
2023-02-22 14:29:01 check read/write on mount point
2023-02-22 14:29:01 check read/write on mount point (1 / 6).
2023-02-22 14:29:01 stat the directory of the mount point "/home/kingbase/cluster/HAR3/db/data" ...
2023-02-22 14:29:01 stat the directory of the mount point "/home/kingbase/cluster/HAR3/db/data" ... OK
2023-02-22 14:29:01 create/write the file "/home/kingbase/cluster/HAR3/db/data/rw_status_file_625758242" ...
........
2023-02-22 14:29:01 success to check read/write on mount point (1 / 6).
2023-02-22 14:29:01 check read/write on mount point ... ok
2023-02-22 14:29:01 check if the network is ok
ping trust ip 192.168.1.1 success ping times :[3], success times:[2]
determine if i am master or standby
node_id | hostname | port | status | lb_weight | role | select_cnt | load_balance_node | replication_delay
---------+---------------+-------+--------+-----------+---------+------------+-------------------+-------------------
0 | 192.168.1.101 | 54321 | up | 0.500000 | primary | 0 | true | 0
1 | 192.168.1.102 | 54321 | down | 0.500000 | standby | 0 | false | 0
(2 rows)
i am standby in cluster,determine if recovery is needed
2023-02-22 14:29:03 now will del vip [192.168.1.204/24]
now, there is no 192.168.1.204/24 on my DEV
sys_ctl: PID file "/home/kingbase/cluster/HAR3/db/data/kingbase.pid" does not exist
Is server running?
primary node/Im node status is changed, primary ip[192.168.1.101], recovery.conf NEED_CHANGE [1] (0 is need ), I,m status is [2] (1 is down), I will be in recovery.
node_id | hostname | port | status | lb_weight | role | select_cnt | load_balance_node | replication_delay
---------+---------------+-------+--------+-----------+---------+------------+-------------------+-------------------
0 | 192.168.1.101 | 54321 | up | 0.500000 | primary | 0 | true | 0
1 | 192.168.1.102 | 54321 | down | 0.500000 | standby | 0 | false | 0
(2 rows)
if recover node up, let it down , for rewind
2023-02-22 14:29:03 sys_rewind...
sys_rewind --target-data=/home/kingbase/cluster/HAR3/db/data --source-server="host=192.168.1.101 port=54321 user=SUPERMANAGER_V8ADMIN dbname=TEST"
datadir_source = /home/kingbase/cluster/HAR3/db/data
rewinding from last common checkpoint at 0/CF000028 on timeline 4
find last common checkpoint start time from 2023-02-22 14:29:03.926782 CST to 2023-02-22 14:29:03.985859 CST, in "0.059077" seconds.
reading source file list
reading target file list
reading WAL in target
Rewind datadir file from source
Get archive xlog list from source
Rewind archive log from source
update the control file: minRecoveryPoint is '0/D001F0B0', minRecoveryPointTLI is '5', and database state is 'in archive recovery'
rewind start wal location 0/CF000028 (file 0000000400000000000000CF), end wal location 0/D001F0B0 (file 0000000500000000000000D0). time from 2023-02-22 14:29:05.926782 CST to 2023-02-22 14:29:06.184927 CST, in "2.258145" seconds.
Done!
sed conf change #synchronous_standby_names
2023-02-22 14:29:08 file operate
cp recovery.conf...
change recovery.conf ip -> primary.ip
2023-02-22 14:29:08 no need change recovery.conf, primary node is 192.168.1.101
delete pid file if exist
del the replication_slots if exist
drop the slot [slot_node1].
drop the slot [slot_node2].
2023-02-22 14:29:08 start up the kingbase...
waiting for server to start....LOG: redirecting log output to logging collector process
HINT: Future log output will appear in directory "/home/kingbase/cluster/HAR3/db/data/sys_log".
done
server started
ksql "port=54321 user=SUPERMANAGER_V8ADMIN dbname=TEST connect_timeout=10" -c "select 33333;"
SYS_CREATE_PHYSICAL_REPLICATION_SLOT
--------------------------------------
(slot_node1,)
(1 row)
2023-02-22 14:29:10 create the slot [slot_node1] success.
SYS_CREATE_PHYSICAL_REPLICATION_SLOT
--------------------------------------
(slot_node2,)
(1 row)
2023-02-22 14:29:10 create the slot [slot_node2] success.
2023-02-22 14:29:10 start up standby successful!
cluster is sync cluster.
SYNC RECOVER MODE ...
2023-02-22 14:29:10 remote primary node change sync
ALTER SYSTEM
SYS_RELOAD_CONF
-----------------
t
(1 row)
SYNC RECOVER MODE DONE
2023-02-22 14:29:13 attach pool...
IM Node is 1, will try [pcp_attach_node -U kingbase -W MTIzNDU2 -h 192.168.1.205 -n 1]
pcp_attach_node -- Command Successful
node_id | hostname | port | status | lb_weight | role | select_cnt | load_balance_node | replication_delay
---------+---------------+-------+--------+-----------+---------+------------+-------------------+-------------------
0 | 192.168.1.101 | 54321 | up | 0.500000 | primary | 0 | true | 0
1 | 192.168.1.102 | 54321 | up | 0.500000 | standby | 0 | false | 0
(2 rows)
2023-02-22 14:29:14 attach end..
recovery success,exit script with success
------------------------------------------------------------------------如上所示,原主库在failover切换后,触发auto-recovery,被恢复为新的备库加入到集群。