文章目录
- TGANet: Text-Guided Attention for Improved Polyp Segmentation
- 摘要
- 本文方法
- 编码器模块
- Feature Enhancement Module
- Label Attention
- decoder
- Multi-scale Feature Aggregation
- 损失函数
- 实验结果
TGANet: Text-Guided Attention for Improved Polyp Segmentation
摘要
- 在训练过程中以文本注意力的形式利用了与大小相关和息肉数量相关的特征
- 引入了一个辅助分类任务来对基于文本的嵌入进行加权,该任务允许网络学习额外的特征表示,这些特征表示可以明显适应不同大小的息肉,并且可以适应多个息肉的情况。
- 实验结果表明,与最先进的分割方法相比,这些添加的文本嵌入提高了模型的整体性能。探索了四个不同的数据集,并为特定尺寸的改进提供了见解。我们提出的文本引导注意力网络(TGANet)可以很好地推广到不同数据集中的可变大小息肉
代码地址
本文方法
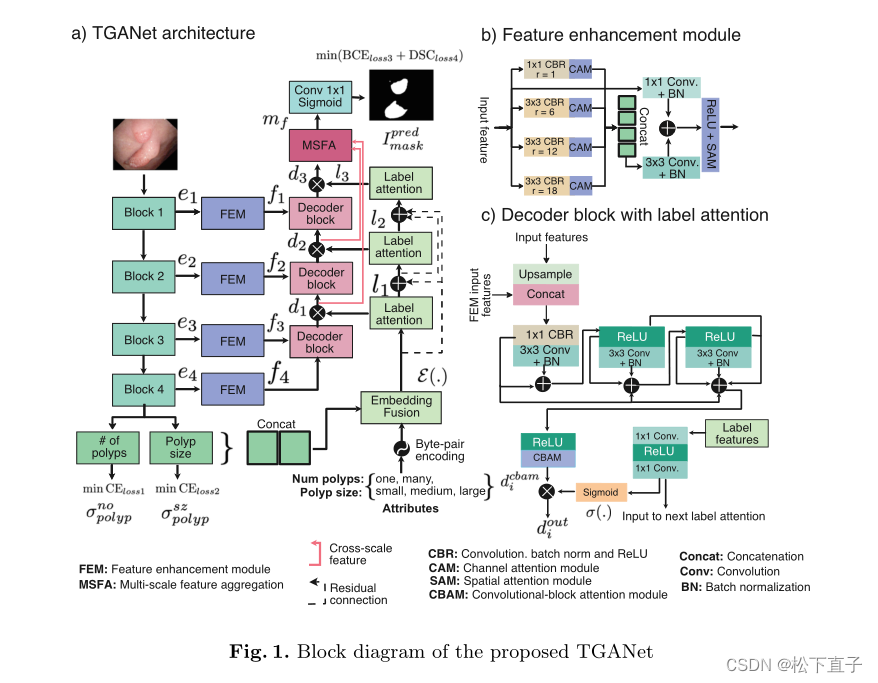
编码器模块
TGANet建立在预先训练的ResNet50作为骨干编码器网络的基础上,我们使用它的四个不同编码块ei,i∈1,2,3,4。这些块被连续用于我们的辅助属性分类任务和主要息肉分割任务。
对于文本属性分类,我们将第四个编码器块的输出分别用作两个分类任务模块,即息肉的数量(一个或多个)及其大小(小、中、大)
多边形大小根据边界框面积与整个图像区域之间的比率r计算,小的指r<0.1,中等的指0.1≤r<0.3,大的指r≥0.3
这里,预测了softmax概率σnopolip(.)a n dσszpolyp(.)。对于主要的分割任务,我们从每个ResNet50块中获取输出,并将其通过特征增强模块(FEM,fi,i∈1,2,3,4),该模块负责通过应用多重扩张卷积和注意力机制来增强特征。
Feature Enhancement Module
主要就是空洞卷积结合
Label Attention
标签注意力模块旨在为我们的TGANet中解码器块的输出特征提供基于文本的学习注意力。在这里,我们使用三个标签注意模块li,i∈1,2,3作为对三个解码器输出的软通道注意,这使得能够对代表性特征进行更大的权重并抑制冗余特征。第一个标签注意力模块使用嵌入融合E(.)的输出,该嵌入融合E是通过softmax概率级联{σone,σmany,σsmall,σmedium,σlarg}与编码文本嵌入之间的逐元素点积获得的。假设,A={one,many,small,median,larg}是使用字节对编码(BPE,一种简单的数据压缩形式编码的属性,并由Aencode表示,其中{akj}作为长度为|k|的每个属性j的向量嵌入,则E(.)由下式给出:
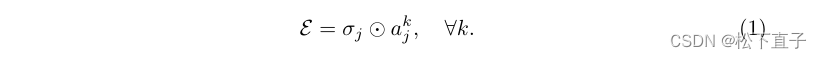
decoder
所提出的TGANet中的解码器由三个不同的解码器块di,i∈1,2,3组成,其中每个解码器块利用输入特征对其进行上采样,并使其通过一些卷积层以产生输出。该输出使用标签注意力模块li进行细化,并传递给随后的解码器块di(见图1(c))。第一解码器块获取第四FEM f4的输出,以使用双线性插值将其上采样2倍,然后将其与来自第三FEM f3的输出特征级联。所得到的级联特征通过称为CBR的Conv1×1-BN-ReLU,然后是三个Conv3×3-BN的序列,进一步伴随着它们的多个残差连接和ReLU激活函数,随后的卷积块注意力模块表示为dcbami。对每个解码器块输出douti,i∈1,2,3使用S形函数进行n元素乘法,以允许来自计算的标签特征lf的额外软关注,由下式给出
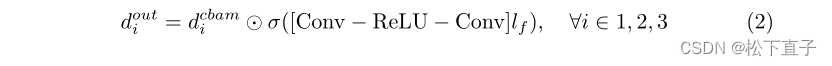
Multi-scale Feature Aggregation
多尺度特征聚合(MSF A)模块(参见补充图1)用于在各种解码器输出douti,i∈1,2,3处融合多尺度特征表示,从而可以捕获学习的特征。我们取前两个特征{dout1,dout2},并将它们通过双线性上采样,以确保所有三个特征都具有精确的空间维度,然后在级联之前进行线性1×1卷积层、BN和ReLU激活。为了增强对非线性特征的捕获,我们进一步应用了一系列卷积层、BN和ReLU以及多个残差连接,以改善信息流
损失函数
我们以相等的权重联合最小化辅助分类任务(交叉熵损失,CEloss1,CEloss2)和分割任务(二进制交叉熵,BCLoss3和骰子损失,DSCloss4)的损失。
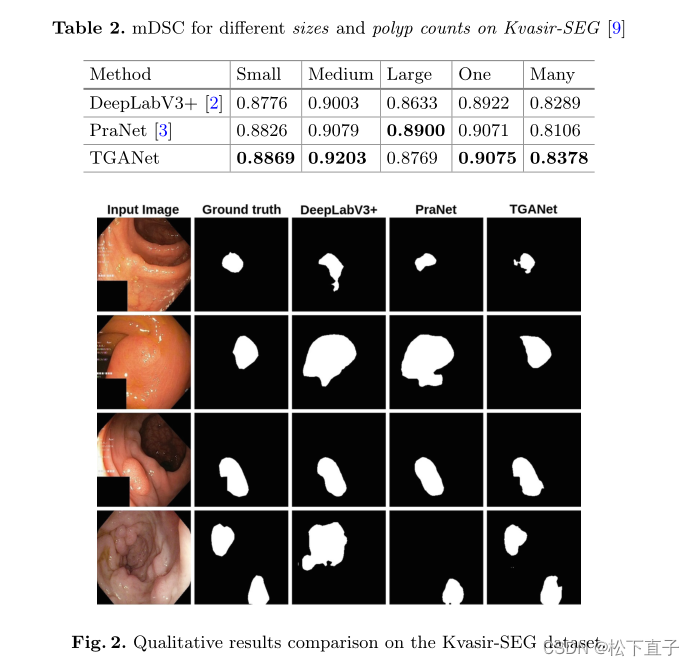
实验结果