ChatGLM-6B是清华团队研发的机器人对话系统,类似ChatGPT,但是实际相差很多,可以当作一个简单的ChatGPT。
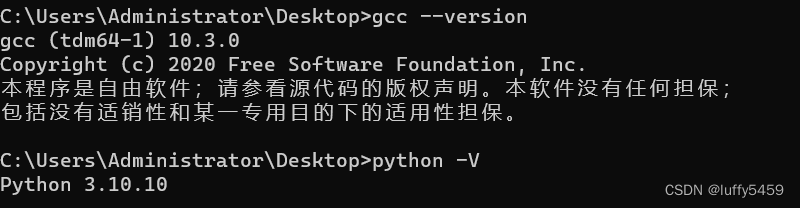
ChatGLM部署默认是支持GPU加速,内存需要32G以上。普通的机器无法运行。但是可以部署本地cpu版本。
本地部署,需要的环境:
- python3.9及以上
- gcc
这个框架本身就是python编写的,所以需要python环境。另外,运行的时候,需要加载cpu内核,所以需要编译本地内核,gcc环境就是用来编译quantization_kernels.c和quantization_kernels_parallel.c文件的。
gcc环境在windows上,可以通过mingw来安装,也可以通过tdm-gcc来安装。
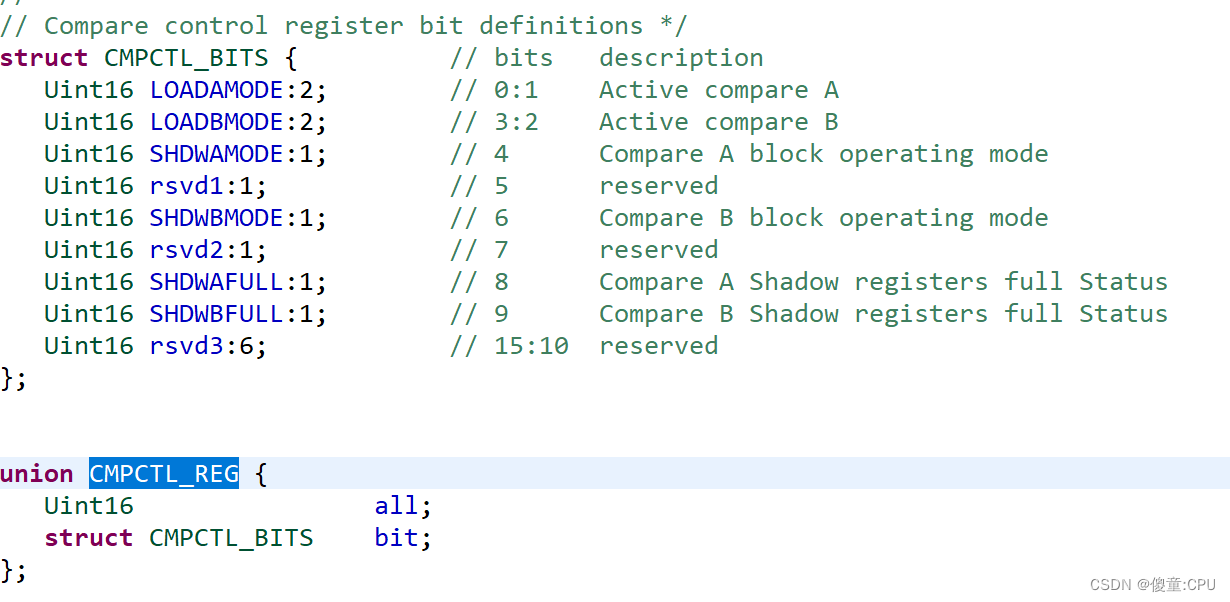
我本地的相关环境:
1、克隆源码
git clone https://github.com/THUDM/ChatGLM-6B2、安装依赖
cd ChatGLM-6B
pip install -r requirements.txt3、改变源码web_demo.py支持cpu
默认代码:

修改支持cpu:
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b-int4", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm-6b-int4", trust_remote_code=True).float()
model = model.eval()模型的名字由THUDM/chatglm-6b改为THUDM/chatglm-6b-int4
gpu模型源码中.half().cuda()替换为.float()
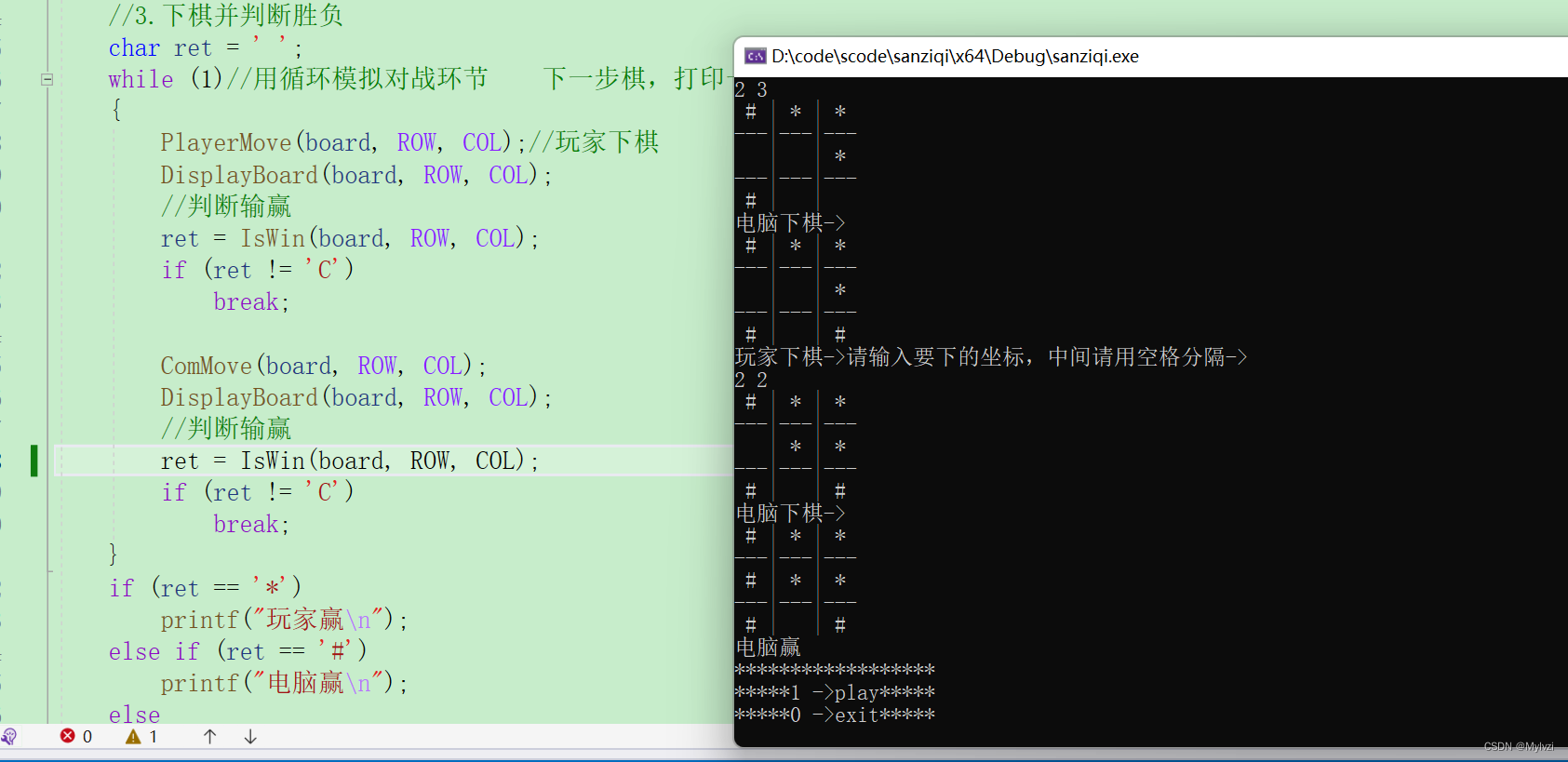
4、运行python web_demo.py
python web_demo.py模型第一次加载会去https://huggingface.co/THUDM/chatglm-6b-int4下载pytorch_model.bin模型文件。
还会使用安装的gcc编译quantization_kernels.c和quantization_kernels_parallel.c文件,生成动态库quantization_kernels.so和quantization_kernels_parallel.so。
5、运行成功,会打开浏览器,并直接显示对话框,可以输入问题,不过这个回答很慢:

提出问题,并不是秒回,很慢,感觉还是内存的问题,我的机器16G内存,效果好像也不是很好。
/
几个抽风的问题:
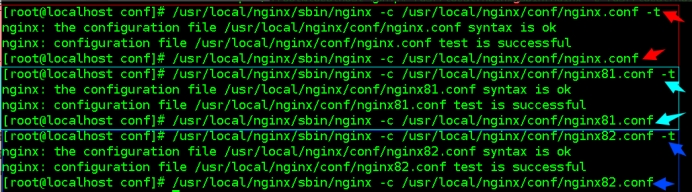
1、我昨天在电脑上运行好好的,结果今天来测试,直接运行python web_demo.py就报了这样的错误:504 Server Error: Gateway Time-out for url: https://huggingface.co/api/models/THUDM/chatglm-6b
这个错误有点蛋疼,貌似是去下载模型文件,但是远程地址不知道为什么就504了,好在这些模型可以通过加载本地缓存的模型,解决办法就是手动下载这些模型文件到一个指定目录。
https://huggingface.co/THUDM/chatglm-6b-int4/tree/main ,把这里的文件,包括json文件全部下载到项目路径下的models目录中:

改动web_demo.py文件内容:
tokenizer = AutoTokenizer.from_pretrained("./models", trust_remote_code=True)
model = AutoModel.from_pretrained("./models", trust_remote_code=True).float()
model = model.eval()2、找不到模块transformers_modules,如下所示:

我昨天运行好好的,也就是说这个模块肯定是有的,不知道今天抽什么风,竟然没有,解决办法就是把当前transformers=4.27.1版本降级到4.26.1:

最后再来感受一下chatglm对话: 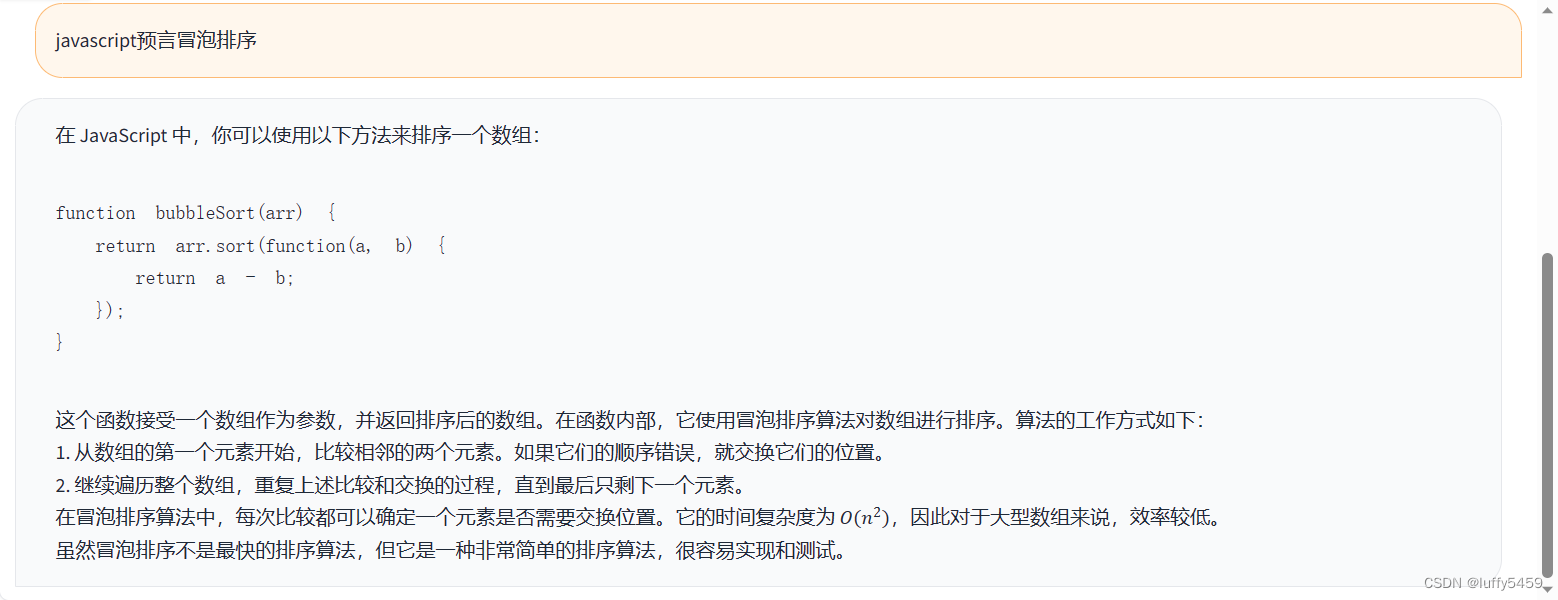
这个结果全部显示完,用了差不多10分钟,哈哈,挤牙膏似的。
完。