大家好,我是微学AI,今天给大家介绍一下人工智能基础部分15-神经网络中数据并行训练的原理,在神经网络中,数据并行训练是一种常用的训练技术。它利用多个GPU或多个计算机对同一个模型进行训练,不同的设备处理相同的模型和数据,但会随机选择不同的批次数据,并使用反向传播算法更新梯度,最后将各设备上的梯度结果合并起来,得到新的权重参数。这样的操作是提高模型的训练速度。
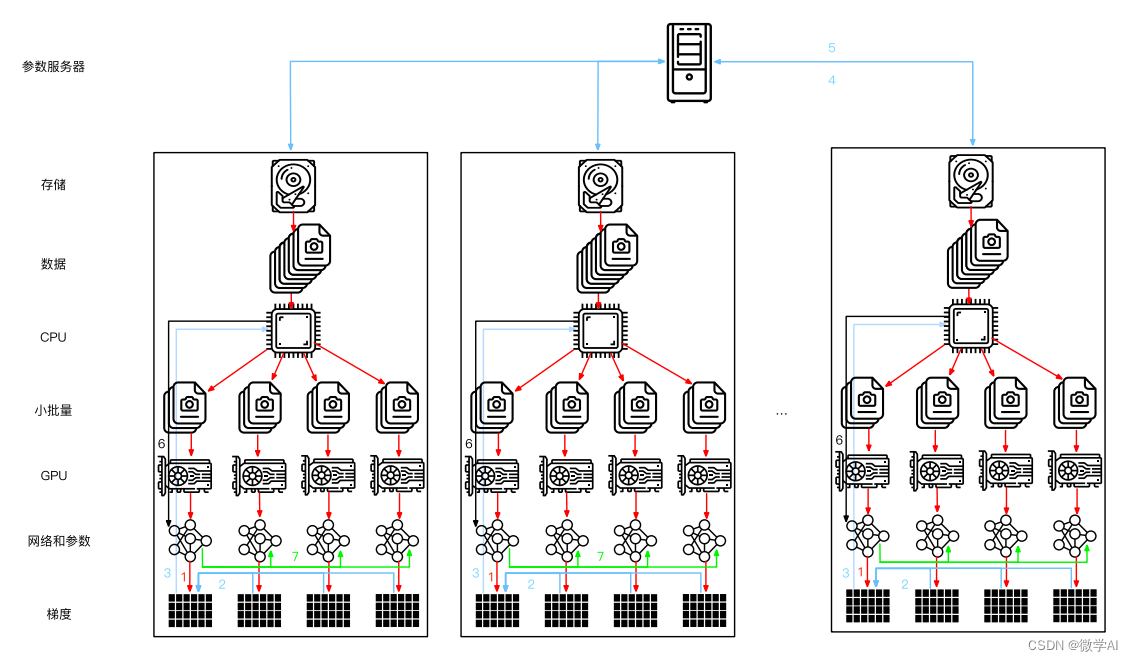
一、数据并行训练过程
前向传播
在前向传播中,每个设备都会接受一个批次的输入数据,并使用当前的权重参数计算输出结果。这些结果被合并成一个大的张量,然后传递给下一层的设备进行处理。每个设备都有自己的损失函数,但是因为它们共享相同的权重参数,所以损失函数的计算结果也是相同的,可以直接累加求和。
反向传播
在反向传播中,每个设备都会根据自己的损失函数计算相应的梯度,并将结果发送给其它设备。当所有设备的梯度计算完成后,它们会把各自的梯度求和,然后通过梯度下降法更新权重参数。
需要注意的是,在数据并行训练中,每个设备的输入数据必须是相同的,并且每个设备的计算结果也必须是一致的。因此,在训练过程中需要使用相同的初始化权重参数,并定期同步这些参数。此外,不同设备之间的通信也会影响到训练的速度和效率。
二、PyTorch中数据并行训练代码
在PyTorch中,可以使用torch.distributed