基本思路:
方法:使用优化算法(如粒子群)优化支持向量机SVM;
本文所使用的应用背景:中文文本分类(同时可以应用到其他背景领域,如)
应用背景(元启发式算法优化SVM):
- 图像分类和识别:图像分类和识别,如人脸识别、数字识别等
- 自然语言处理:SVM可以用于文本分类和情感分析等自然语言处理任务。它可以通过学习文本特征来判断一个文本属于哪个类别或者情感极性。
- 金融预测:SVM可以用于股票价格预测、信用评级、欺诈检测等金融领域的问题。它可以通过学习历史数据来预测未来的趋势或者检测异常交易。
- 医学诊断:SVM可以用于医学诊断,如癌症分类、药物分子筛选等。它可以通过学习医学数据特征来辅助医生进行诊断和治疗。
- 视频分类和检测:SVM可以用于视频分类和检测,如视频目标跟踪、行人检测等。它可以通过学习视频特征来判断一个视频中的目标或者行为。
本文所使用的数据集
数据集:搜狐新闻文本语料库
其他可使用的数据集:复旦大学文本语料库
参考文章:
搜狐新闻文本分类:机器学习大乱斗 - 简书
【Python NLP】:搜狗语料库-新闻语料处理_搜狗新闻语料库_QuantCoder的博客-CSDN博客
源码部分:
工具:pycharm,
PSO代码:
import numpy as np
import random
import copy
from matplotlib import pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
''' 种群初始化函数 '''
def initial(pop, dim, ub, lb):
X = np.zeros([pop, dim])
for i in range(pop):
for j in range(dim):
X[i, j] = random.random()*(ub[j] - lb[j]) + lb[j]
return X,lb,ub
'''边界检查函数'''
def BorderCheck(X,ub,lb,pop,dim):
for i in range(pop):
for j in range(dim):
if X[i,j]>ub[j]:
X[i,j] = ub[j]
elif X[i,j]<lb[j]:
X[i,j] = lb[j]
return X
'''计算适应度函数'''
def CaculateFitness(X,fun):
pop = X.shape[0]
fitness = np.zeros([pop, 1])
for i in range(pop):
fitness[i] = fun(X[i, :])
return fitness
'''适应度排序'''
def SortFitness(Fit):
fitness = np.sort(Fit, axis=0)
index = np.argsort(Fit, axis=0)
return fitness,index
'''根据适应度对位置进行排序'''
def SortPosition(X,index):
Xnew = np.zeros(X.shape)
for i in range(X.shape[0]):
Xnew[i,:] = X[index[i],:]
return Xnew
'''粒子群算法'''
def PSO(pop,dim,lb,ub,MaxIter,fun,Vmin,Vmax):
# 参数设置
w = 0.9 # 惯性因子
c1 = 2 # 加速常数
c2 = 2 # 加速常数
X,lb,ub = initial(pop, dim, ub, lb) #初始化种群
V,Vmin,Vmax = initial(pop, dim, Vmax, Vmin) #初始速度
fitness = CaculateFitness(X,fun) #计算适应度值
fitness,sortIndex = SortFitness(fitness) #对适应度值排序
X = SortPosition(X,sortIndex) #种群排序
GbestScore = copy.copy(fitness[0])
GbestPositon = copy.copy(X[0,:])
Curve = np.zeros([MaxIter,1])
Pbest = copy.copy(X)
fitnessPbest = copy.copy(fitness)
for i in range(MaxIter):
for j in range(pop):
#速度更新
V[j,:] = w*V[j,:] + c1*np.random.random()*(Pbest[j,:] - X[j,:]) + c2*np.random.random()*(GbestPositon - X[j,:])
#速度边界检查
for ii in range(dim):
if V[j,ii]<Vmin[ii]:
V[j,ii]=Vmin[ii]
if V[j,ii]>Vmax[ii]:
V[j,ii] = Vmax[ii]
#位置更新
X[j,:] = X[j,:] + V[j,:]
#位置边界检查
for ii in range(dim):
if X[j,ii]<lb[ii]:
V[j,ii]=lb[ii]
if X[j,ii]>ub[ii]:
V[j,ii] = ub[ii]
fitness[j] = fun(X[j,:])
if fitness[j]<fitnessPbest[j]:
Pbest[j,:]=copy.copy(X[j,:])
fitnessPbest[j] = copy.copy(fitness[j])
if fitness[j]<GbestScore[0]:
GbestScore[0] = copy.copy(fitness[j])
# 修改 2022/07/21 04:51
#if(fitnessPbest[j]>0):
GbestPositon = copy.copy(X[j,:])
Curve[i] = GbestScore
return GbestScore,GbestPositon,Curve
PSO_SVM代码:
# 导包
import re
import jieba
from sklearn.feature_extraction.text import TfidfVectorizer, CountVectorizer
from sklearn.metrics import classification_report, confusion_matrix
from sklearn.pipeline import Pipeline
from sklearn.svm import SVC
import numpy as np
from sklearn.metrics import accuracy_score
import PSO_.PSO # 该行是导入粒子群PSO的源码,可能需要做对应修改
import sys
import os
import time
sys.path.append(os.path.abspath("../"))
#上一行代码和主要是我将PSO.py和PSO_SVM未放到同一个文件夹
#PSO_SVM放入到了202207SSA_SVM_combin,PSO.py放到了PSO_文件夹中
#两个文件夹同级目录
token = "[0-9\s+\.\!\/_,$%^*()?;;:【】+\"\'\[\]\\]+|[+——!,;:。?《》、~@#¥%……&*()“”.=-]+"
stopwords = open('../dict/stop_words.txt', encoding='utf-8').read().split() # read() split()
#上两行分词去停用词
def preprocess(text):
text1 = re.sub(' ', ' ', text) #去掉text中的 空格
str_no_punctuation = re.sub(token, ' ', text1) # 去掉标点
text_list = list(jieba.cut(str_no_punctuation)) # 分词列表
text_list = [item for item in text_list if item != ' '] # 去掉空格
return ' '.join(text_list)
def load_datasets():
base_dir = '../data/'
#base_idr需要注意!放的是对应的数据集
X_data = {'train': [], 'test': []}
y = {'train':[], 'test':[]}
for type_name in ['train', 'test']:
corpus_dir = os.path.join(base_dir, type_name)
corpus_list = [] ###
for label in os.listdir(corpus_dir): #
label_dir = os.path.join(corpus_dir, label) #标签
file_list = os.listdir(label_dir) #标签目录下对应的文件数
print("label: {}, len: {}".format(label, len(file_list)))
for fname in file_list:
file_path = os.path.join(label_dir, fname)
with open(file_path, encoding='gb2312', errors='ignore') as text_file:
text_content = preprocess(text_file.read()) # 使用preprocess处理文件的内容
X_data[type_name].append(text_content) #
y[type_name].append(label) #
print("{} corpus len: {}\n".format(type_name, len(X_data[type_name])))
return X_data['train'], y['train'], X_data['test'], y['test']
def fun(parameter): ##适应度函数!优化算法的关键
#data_train, label_train, data_test, label_test = load_datasets(
# 自己单独修改的 20220721 5:02
# 下面的if多余了,只要__main__方法中的lb 和ub的范围即可
if(parameter[0]<=0 ):
parameter[0] = -1 * parameter[0] + 0.1
if(parameter[1]<0 ):
parameter[1] = -1 * parameter[1]
text_clf_svm = Pipeline([
('vect', TfidfVectorizer()),
('svm_clf', SVC(C=parameter[0], kernel='rbf', gamma=parameter[1])),
])
text_clf_svm.fit(X_train_data, y_train)
y_predict = text_clf_svm.predict(X_test_data)
acc = accuracy_score(y_test, y_predict)
print(1-acc)
return 1-acc
if __name__ == '__main__':
start_time = time.time() # 设置起始的时间
X_train_data, y_train, X_test_data, y_test = load_datasets()
# 设置参数
pop = 2 # 种群数量 默认是50
MaxIter = 2 # 最大迭代次数 默认是1000
dim = 2 # 维度 默认是10最后输出时设置10会报错的
lb = np.matrix([[0.1], [0.1]]) # 下边界
ub = np.matrix([[200], [200]]) # 上边界
Vmin = -5 * np.ones([dim, 1]) # 速度下边界
Vmax = 5 * np.ones([dim, 1]) # 速度上边界
fobj = fun
# 设置麻雀参数
# pop = 20 # 种群数量
# MaxIter = 50 # 最大迭代次数
# dim = 2 # 维度
# lb = np.matrix([[0.1], [0.1]]) # 下边界
# ub = np.matrix([[200], [200]]) # 上边界
# fobj = fun
# 出错的粒子群PSO, 多了参数Vmin,Vmax 先设置-1 和 1 试试,还是有问题
GbestScore, GbestPositon, Curve = PSO_.PSO.PSO(pop, dim, lb, ub, MaxIter, fobj, Vmin, Vmax)
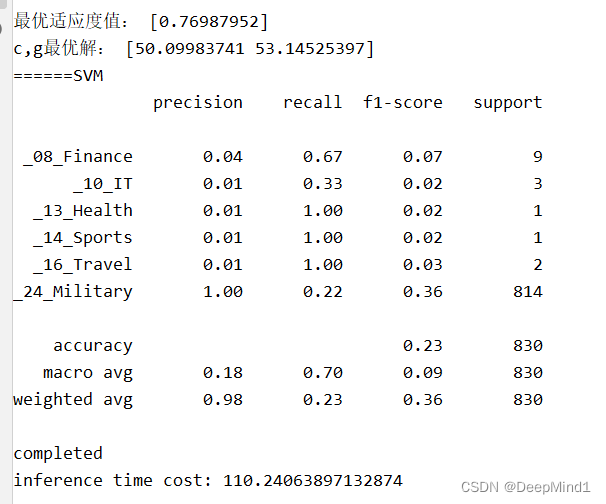
print('最优适应度值:', GbestScore)
print('c,g最优解:', GbestPositon)
# # 构建 SVM分类器
print("======SVM")
text_clf_svm = Pipeline([
('vect', TfidfVectorizer()),
('svm_clf', SVC(C=GbestPositon[0], kernel='rbf', gamma=GbestPositon[1])),
])
text_clf_svm.fit(X_train_data, y_train)
predicted_svm = text_clf_svm.predict(X_test_data)
print(classification_report(predicted_svm, y_test))
print('completed')
elapsed_time = time.time() - start_time # 设置截止时间
print('inference time cost: {}'.format(elapsed_time)) # 输出消耗的时间
运行结果这样:(由于种群数和迭代次数只设置了,效果会较差,而且PSO可能存在局部最优解等问题)
改进思路1:
使用麻雀搜索算法/改进的麻雀搜索算法对支持向量机进行优化;
使用其他优化算法对支持向量机进行优化;
目前可以参考的其他优化算法:资源文件正在审核,后面可能放在评论区
改进思路2:
使用优化算法优化LSTM等深度学习模型的相关参数!(目前自己在情感分析中有实现,最差和最好的效果大概相差2%-3%左右)
完整代码文件正在审核,后面可能放在评论区