文章目录
- 📕 共享内存的原理
- 📕 代码实现 & 深入理解共享内存
- shmget() 函数
- shmctl() 、shmdt()、shmat()
- 特点
- 📕 源代码
- comm.hpp
- server.cc
- client.cc
📕 共享内存的原理
我们知道,如果想实现进程间通信,那么必须要让两个进程看到同一份资源。匿名管道、命名管道 可以实现进程间通信。但是其涉及到文件的创建,所以速度上慢了些。而共享内存就没有这种问题,它是让两个进程直接看到同一份物理内存空间,这样就可以实现进程间通信!!
如下,如果有一种接口,可以在物理内存中开辟出一块空间。
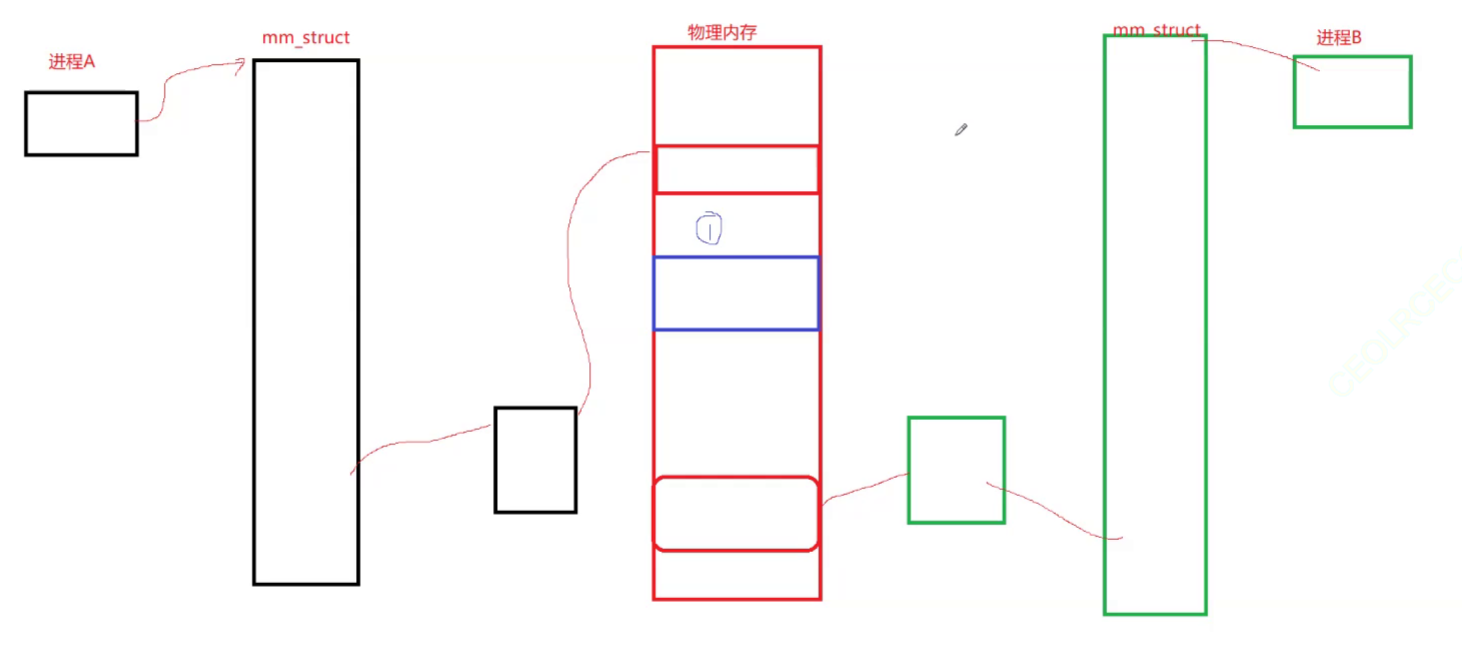
其次,在进程A中,通过页表,将之前在物理空间开辟的那块空间的地址,映射到A进程的地址空间的共享区中的某个区域,然后就可以将其返回给用户。这样,用户就可以通过进程 A 的共享区,进而访问到物理内存开辟的空间。
进程B同理。这样子,进程A和进程B,就可以看到物理内存中同一块空间,具备了进程间通信的条件!如下图。
而进程 A、B 看到的物理内存中的同一块空间,就是共享内存!!
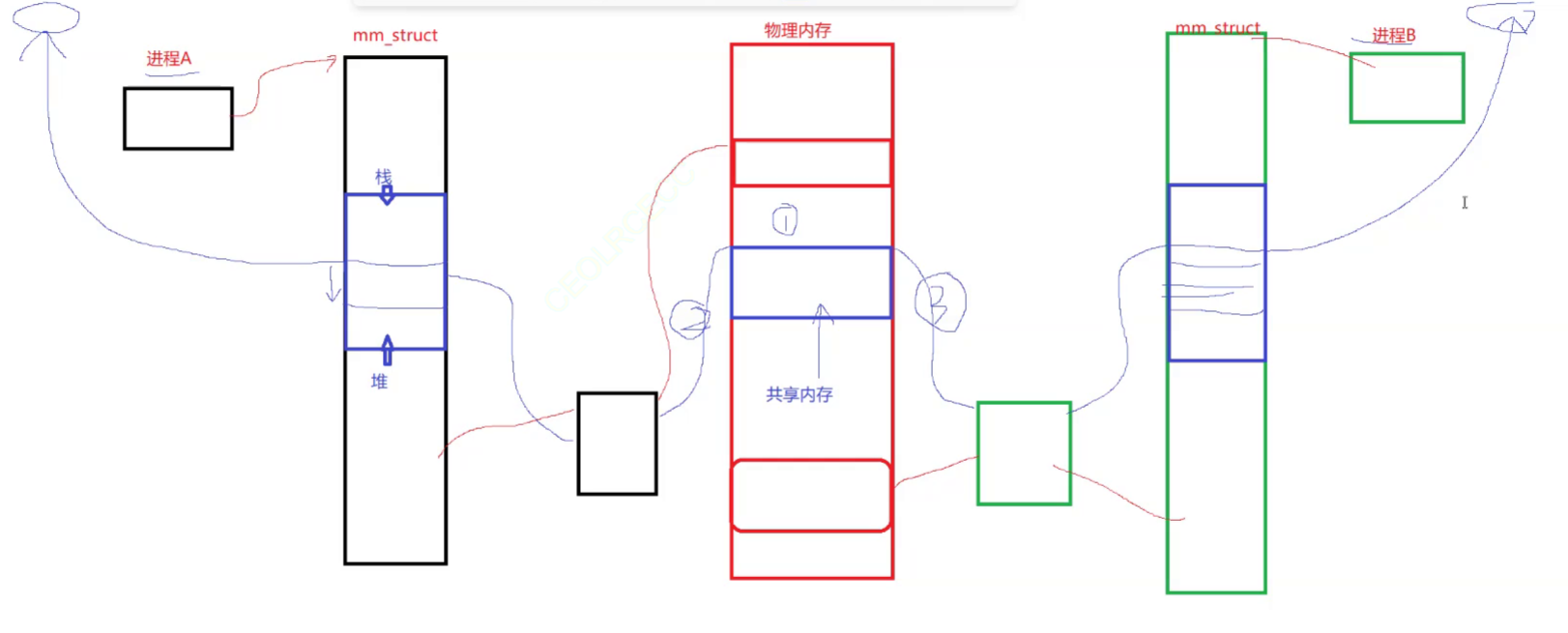
管道是让两个进程看到同一个文件,而共享内存是让两个进程看到同一块物理地址,清楚两者的差别!
当不需要进行进程间通信的时候,只需要通过页表,将进程的虚拟地址和物理地址(共享内存)之间的映射关系去掉,然后释放共享内存块,就可以了!
当然,这只是一个宏观上的感知, 要深入理解,必然是要通过写代码的方式!!
📕 代码实现 & 深入理解共享内存
shmget() 函数
申请共享内存块,需要通过 shmget() 函数实现,如下是其介绍。
shmget()
功能:用来创建共享内存
原型
int shmget ( key_t key, size_t size, int shmflg);
参数
key:这个共享内存段名字
size:共享内存大小
shmflg:由九个权限标志构成,它们的用法和创建文件时使用的mode模式标志是一样的(位图结构)
返回值:成功返回一个非负整数,即该共享内存段的标识码;失败返回-1
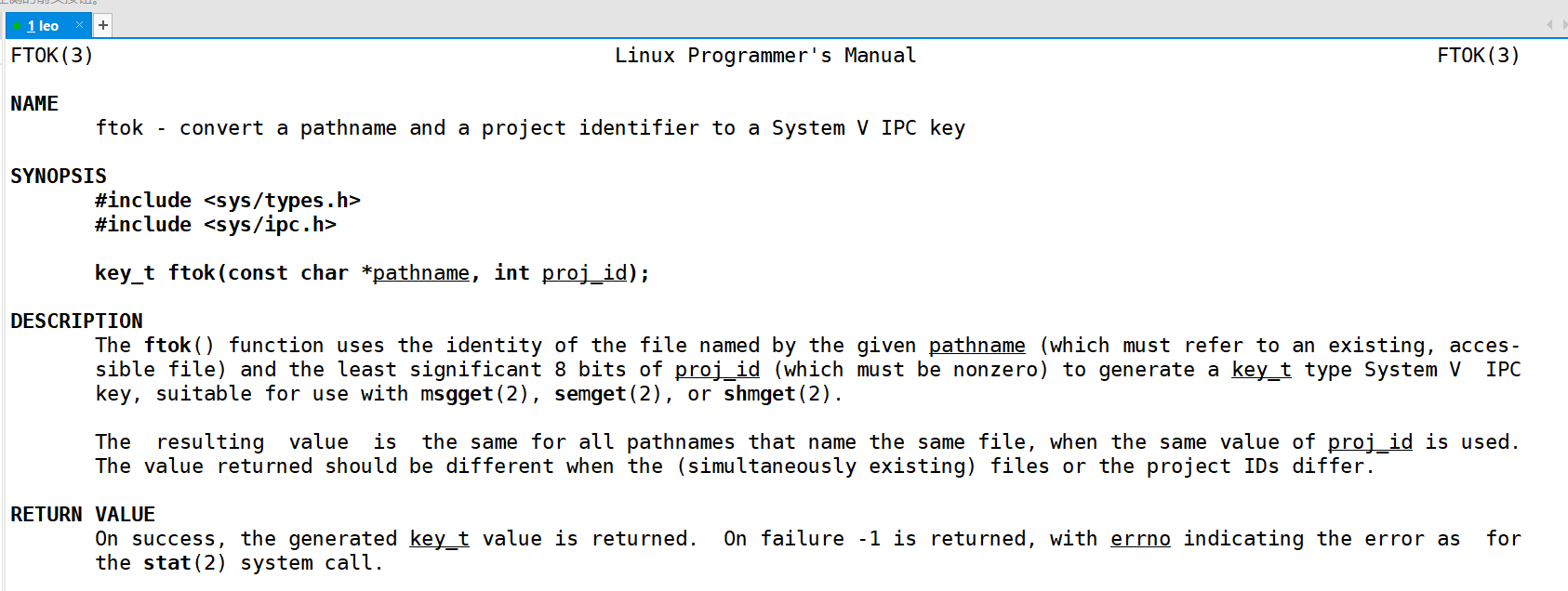
对于该函数第一个参数 key ,它随便怎么设置都可以,只要是一个唯一标识即可,但是一般而言,不会随便传入参数,而是通过另一个函数 ftok() 来得到。
为什么要确保 key 的唯一性呢?这是因为,在操作系统中,不一定 只有一对进程 在进行 进程间通信,可能有多对进程同时通信,每一对通信的进程(假设都使用共享内存方式),都要创建新的共享内存块来维持其通信。那么系统中一定同时存在大量的共享内存,那么操作系统就需要管理它们!当然是先描述、再组织。
所以,共享内存 并不是 只需要在内存中开辟空间那么简单,操作系统还要为共享内存创建结构体,里面存放的是共享内存的属性。
那么,共享内存 = 内核数据结构(伪代码 struct shm) + 物理内存开辟的空间。
如下,进程 A 创建一块共享内存(红色的),然后进程 B 想要访问这块共享内存,和进程A实现通信。那么,进程 B 就要遍历内存中的 struct shm 对象,找到进程 A 创建的,然后通过该对象,找到共享内存。
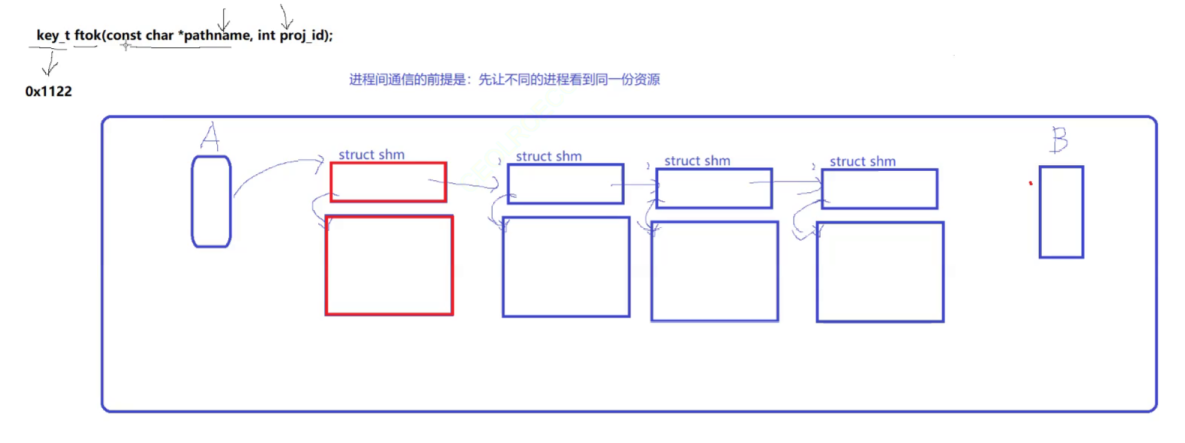
如下,有了 ftok() 创建出的唯一标识,就可以在多个 struct shm 结构体对象中,A进程创建的,从而实现A、B进程的进程间通信。
进程 A 在创建共享内存的时候,调用的 shmget() 函数的第一个参数 key,这是通过 ftok() 函数唯一生成的一个标识,进程A创建共享内存的时候,会把这个唯一标识放到对应的 struct shm 对象里面,进程 B 只需要知道 进程A 创建的 key 值(只要 ftok() 的两个参数一样,生成的 key 值就一样,所以实际上是知道 pathname 和 proj_id),即可找到进程A创建的共享内存。
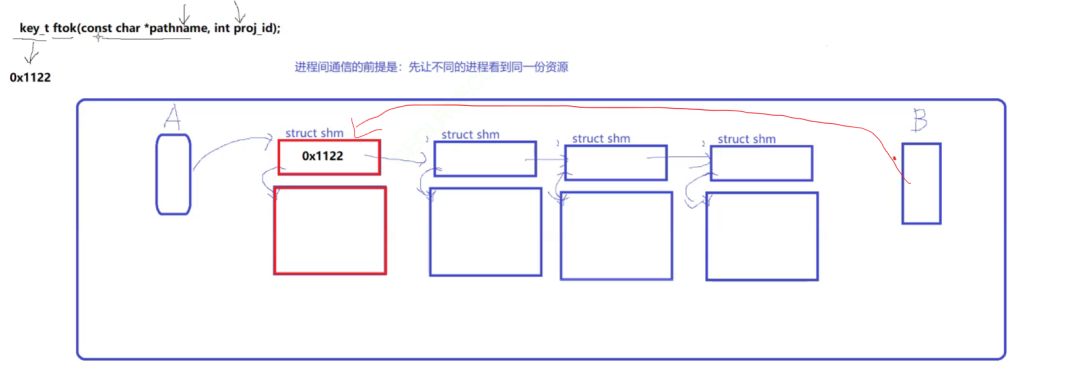
如下是对 ftok() 的介绍。第一个参数是路径,第二个参数是项目的 ID。
如下,可以直接调用 getkey() 函数获得特定的 key 值。 两个进程可以分别调用该函数,获得同一个 key 值。
#define PATH "."
#define PROJID 0x1111
key_t getkey()
{
key_t k=ftok(PATH,PROJID);
if(k == -1)
{
cout<<"ftok error:"<<errno<<strerror(errno)<<endl;
exit(1);
}
return k;
}
然后就是使用 shmget() 函数,创建共享内存。
如下是对其封装,第三个参数是位图结构,和文件系统里面的 bitmap 有异曲同工之妙。主要用到 IPC_CREAT 和 IPC_EXCL 。
- 单独使用IPC_CREAT: 创建一个共享内存,如果共享内存不存在,就创建之,如果已经存在,获取已经存在的共享内存并返回。
- IPC_EXCL不能单独使用,一般都要配合IPC_CREAT。
- IPC_CREAT | IPC_EXCL: 创建一个共享内存,如果共享内存不存在,就创建之, 如果已经存在,则立马出错返回 —— 如果创建成功,对应的shm,一定是最新的!
这里设计 CreateShm 和 Getshm 接口的目的也就很清楚了:如果 进程 A 创建共享内存,那么必定是使用 IPC_CREAT | IPC_EXCL ,那么进程 B 就要通过 key 值找到共享内存,根据上面的规则,需要使用 IPC_CREAT ,所以要设计两个接口,一个给创建共享内存的进程,一个给获取共享内存的进程。
当然了,创建共享内存要涉及到权限问题,这里让 拥有者、所属组、other 都是具有读写权限。
#define SIZE 4096 // 共享内存的大小
static int tocreateshm(key_t k,int size,int flag)
{
int shmid=shmget(k,size,flag);
if(shmid == -1)
{
cout<<"shmget error:"<<errno<<strerror(errno)<<endl;
exit(2);
}
return shmid;
}
int CreateShm(key_t k,int size)
{
umask(0);
return tocreateshm(k,size,IPC_CREAT | IPC_EXCL | 0666);
}
int GetShm(key_t k,int size)
{
return tocreateshm(k,size,IPC_CREAT);
}
shmget() 的返回值是 shmid,以后对这块共享内存的一切操作,都是依靠 shmid 的。但是要区分 shmid 和 key ,key 只是用于创建/找到 共享内存,对共享内存进行操作(应用层),是依靠 shmid。
shmctl() 、shmdt()、shmat()
一个进程创建了共享内存,这个进程也无法直接使用该共享内存,因为进程还没有和共享内存关联起来。还需要链接,需要用到 shmat() ,调用该函数之后,进程就和共享内存关联起来,共享内存就可以映射到进程地址空间的共享区, 该函数返回的是 虚拟内存的地址。
shmat()
功能:将共享内存段连接到进程地址空间
原型
void *shmat(int shmid, const void *shmaddr, int shmflg);
参数
shmid: 共享内存标识
shmaddr:指定连接的地址(虚拟地址,一般而言我们不知道挂接在哪里,所以设为 nullptr)
shmflg:它的两个可能取值是SHM_RND和SHM_RDONLY
返回值:成功返回一个指针,指向共享内存第一个节;失败返回-1
如下,可以验证链接这个过程。 使用 ipcs -m 可以查看共享内存,其中 nattch 就代表其链接数。
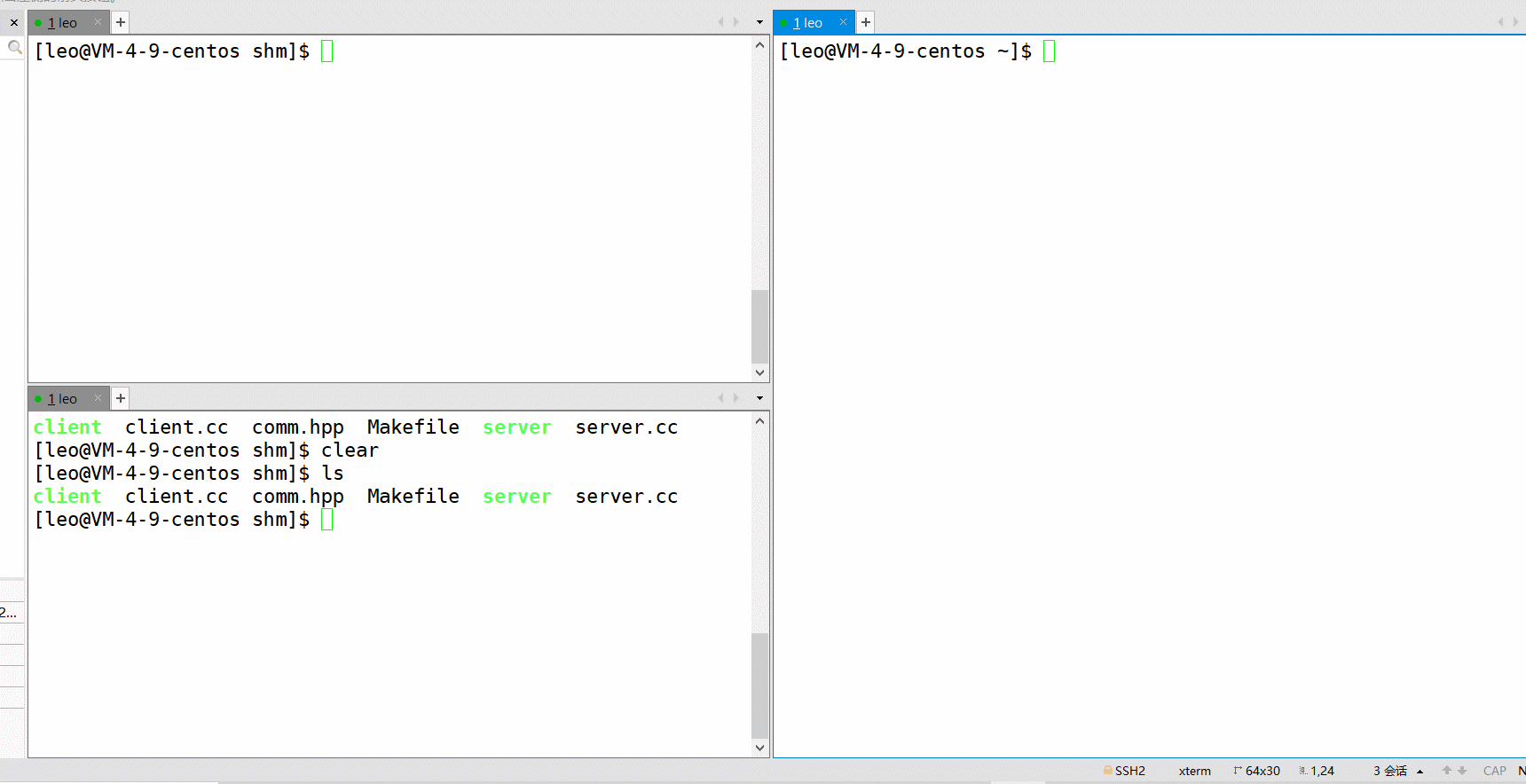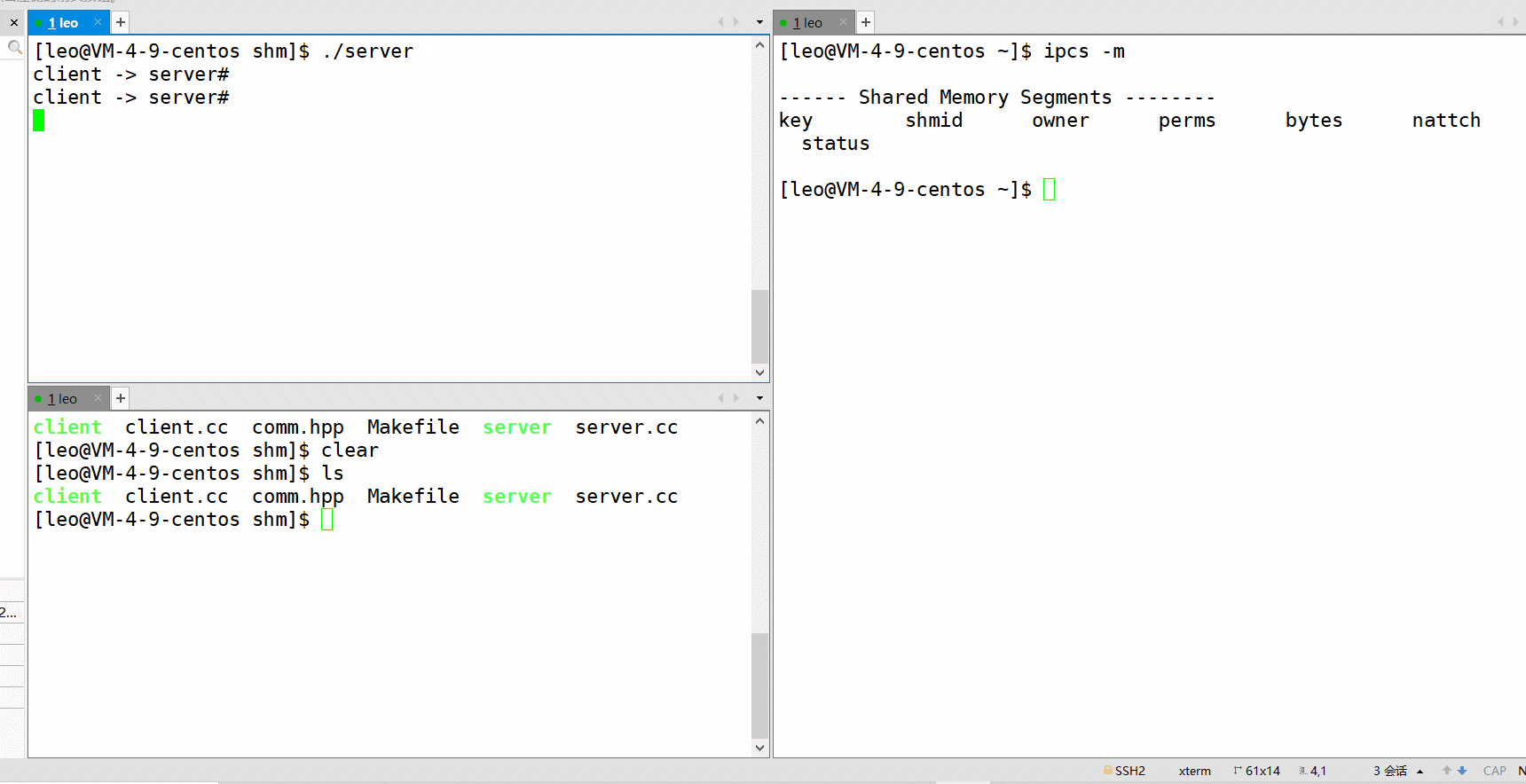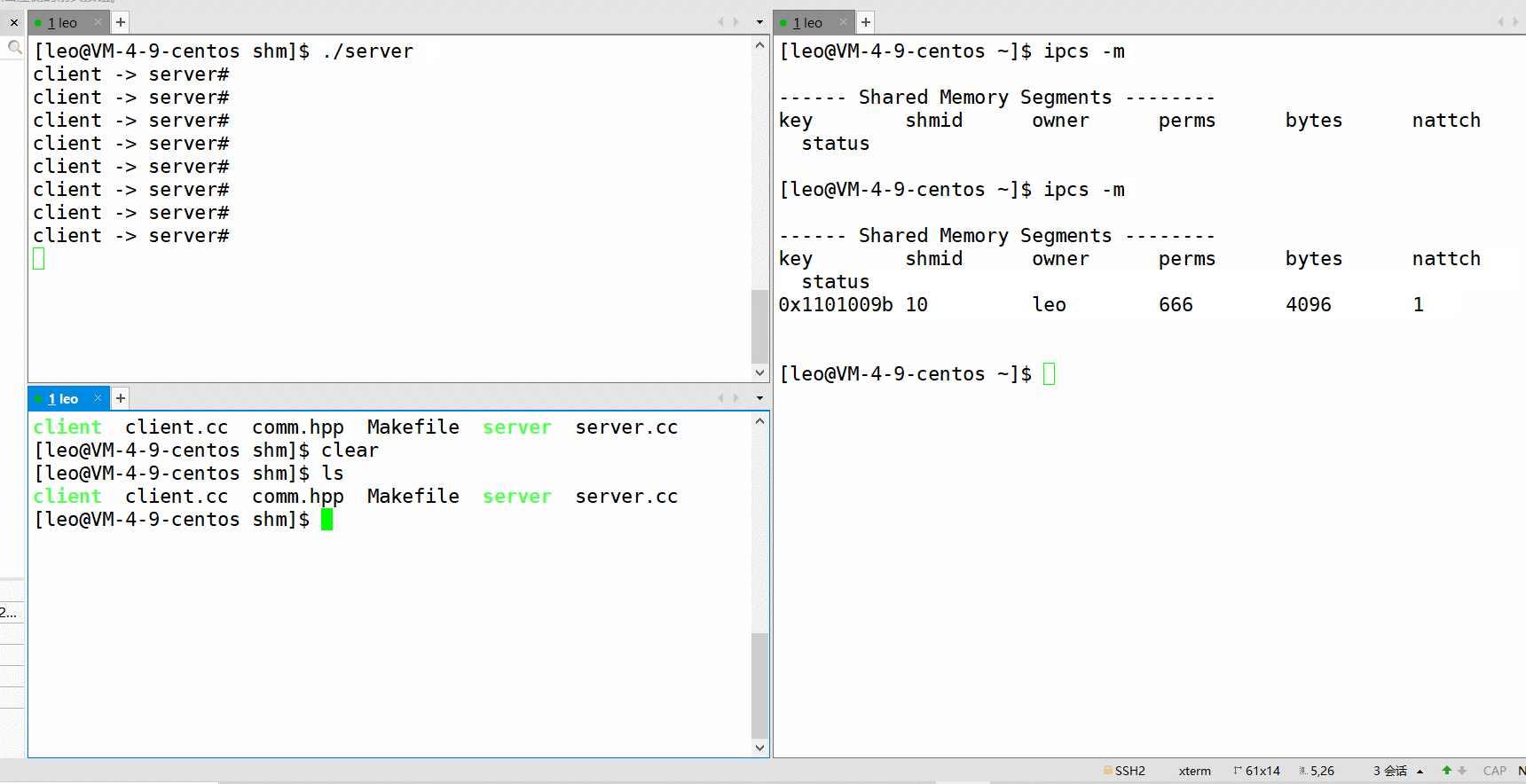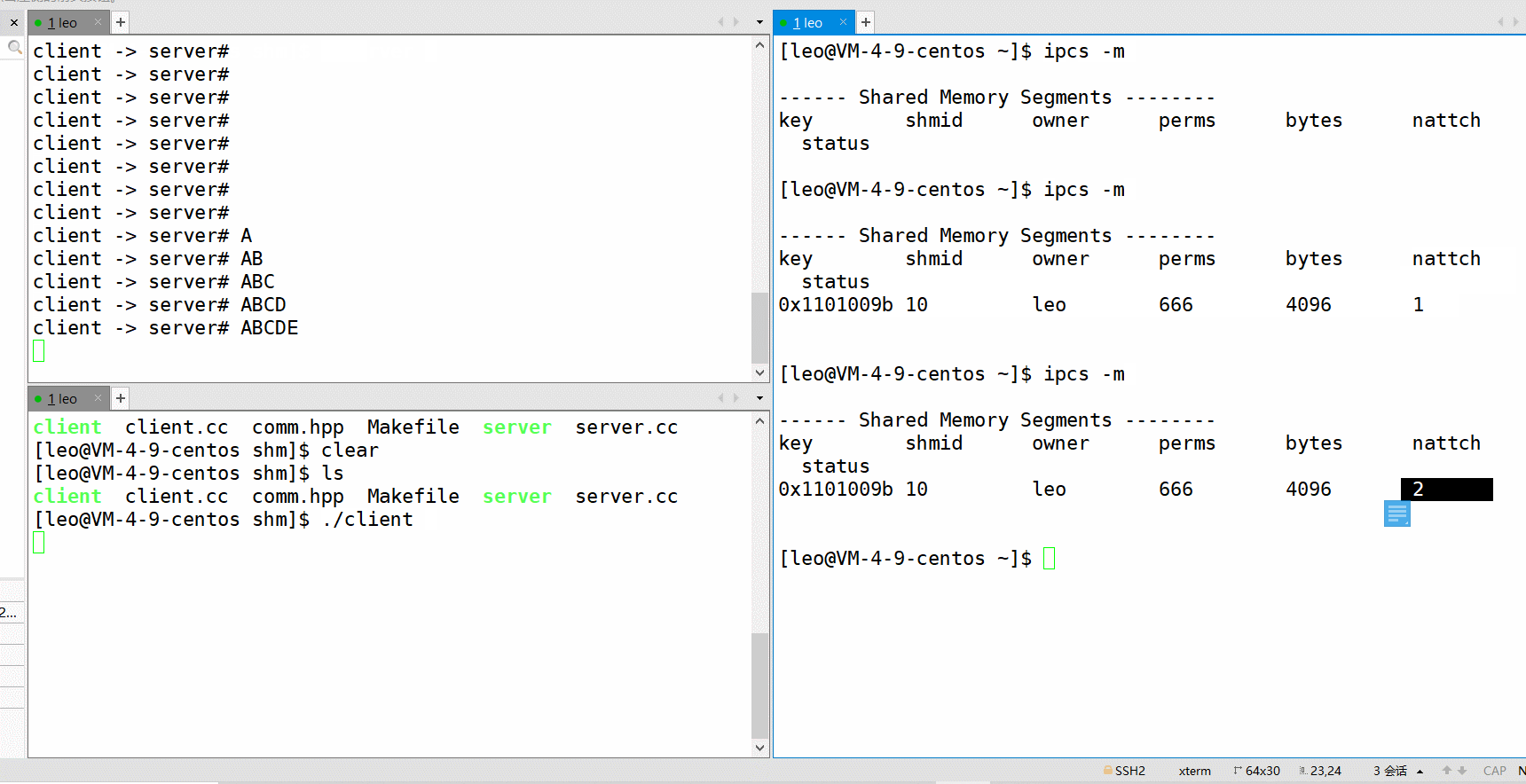
链接成功,就可以开始进程间通信啦!通信结束再取消链接。
当进程A、B通信结束,就可以将进程与共享内存去关联,要用到 shmdt() 。
shmdt()
功能:将共享内存段与当前进程脱离
原型
int shmdt(const void *shmaddr);
参数
shmaddr: 由shmat所返回的指针
返回值:成功返回0;失败返回-1
注意:将共享内存段与当前进程脱离不等于删除共享内存段
如下是代码。
char * AttachShm(int shmid)
{
char* start=(char*)shmat(shmid,nullptr,0);
return start;
}
void DetachShm(char* start)
{
int n=shmdt(start);
assert(n != -1);
(void)n;
}
shmctl()
功能:用于控制共享内存
原型
int shmctl(int shmid, int cmd, struct shmid_ds *buf);
参数
shmid:由shmget返回的共享内存标识码
cmd:将要采取的动作(有三个可取值)
buf:指向一个保存着共享内存的模式状态和访问权限的数据结构
返回值:成功返回0;失败返回-1
该函数可以用来删除共享内存块。如下是删除接口,只需要传入 shmid 即可,这是 shmget() 的返回值。
删除共享内存的原因是,如果两个进程都运行结束了,但是进程并没有删除共享内存块,共享内存块依然保存在那里,它不会自己删除。会造成资源浪费(共享内存的生命周期随操作系统)。
void DelShm(int shmid)
{
int n=shmctl(shmid,IPC_RMID,nullptr);
assert(n != -1);
(void)n;
}
特点
- 共享内存的内存分配是按照 PAGE 为单位的。
- 进程链接上共享内存之后,不需要额外的接口,就可以直接通信。(管道需要 write、read )
- 共享内存没有任何保护机制(同步互斥)
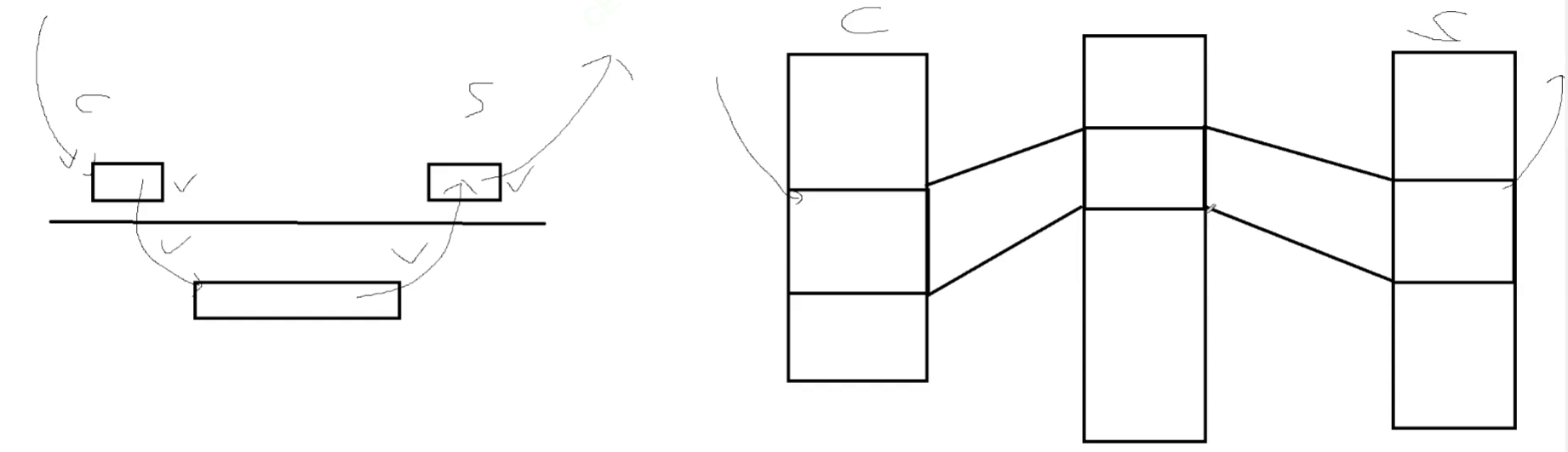
如下,画个图简单理解。
左边代表管道, c 代表客户端,s 代表 服务器端,两个进程通信(假设 c 写、s读),c 要先把数据放到自己的缓冲区,然后拷贝到内核,再从内核拷贝到 s 自己的缓冲区。
右边代表共享内存, c 直接把数据放到共享内存,然后 s 就可以直接看到,不需要多次拷贝,所以速度要快很多!!
共享内存的这种特性,使得它是所有进程间通信方案里面,速度最快的。
📕 源代码
当然了,使用的时候可以封装成为一个类,这样用起来就更简单了!!
comm.hpp
#ifndef __COMM_HPP__
#define __COMM_HPP
#include<iostream>
#include<sys/ipc.h>
#include<sys/shm.h>
#include<sys/types.h>
#include<cerrno>
#include<cstring>
#include<sys/stat.h>
#include<cassert>
#include<unistd.h>
using namespace std;
#define PATH "."
#define PROJID 0x1111
#define SIZE 4096
#define CLIENT 0
#define SERVER 1
key_t getkey()
{
key_t k=ftok(PATH,PROJID);
if(k == -1)
{
cout<<"ftok error:"<<errno<<strerror(errno)<<endl;
exit(1);
}
return k;
}
static int tocreateshm(key_t k,int size,int flag)
{
int shmid=shmget(k,size,flag);
if(shmid == -1)
{
cout<<"shmget error:"<<errno<<strerror(errno)<<endl;
exit(2);
}
return shmid;
}
int CreateShm(key_t k,int size)
{
umask(0);
return tocreateshm(k,size,IPC_CREAT | IPC_EXCL | 0666);
}
int GetShm(key_t k,int size)
{
return tocreateshm(k,size,IPC_CREAT);
}
void DelShm(int shmid)
{
int n=shmctl(shmid,IPC_RMID,nullptr);
assert(n != -1);
(void)n;
}
char * AttachShm(int shmid)
{
char* start=(char*)shmat(shmid,nullptr,0);
return start;
}
void DetachShm(char* start)
{
int n=shmdt(start);
assert(n != -1);
(void)n;
}
class Init
{
public:
Init(int t)
:type(t)
{
key_t key=getkey(); // 创建 key 值
if(type == SERVER)
shmid=CreateShm(key,SIZE); // 服务器端创建共享内存
else shmid=GetShm(key,SIZE); // 用户端使用共享内存
start=AttachShm(shmid); // 关联
}
char* getstart()
{
return start;
}
~Init()
{
DetachShm(start); // 去关联
if(type == SERVER) DelShm(shmid); // 服务器端删除共享内存
}
private:
int type;
char* start;
int shmid;
};
#endif // !
server.cc
#include"comm.hpp"
int main()
{
Init init(SERVER);
char* start=init.getstart();
int n = 0;
while (n <= 30)
{
cout << "client -> server# " << start << endl;
sleep(1);
n++;
}
return 0;
}
client.cc
#include"comm.hpp"
int main()
{
Init init(CLIENT);
char *start = init.getstart();
char c = 'A';
while (c <= 'Z')
{
start[c - 'A'] = c;
c++;
start[c] = '\0';
sleep(1);
}
return 0;
}