介绍一篇较新的目标检测工作:
Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection

论文地址为:
https://arxiv.org/pdf/2303.05499.pdf
github 地址为:
https://github.com/IDEA-Research/GroundingDINO
文章目录
- 一、摘要
- 二、优点
- 三、Grounding DINO 模型
- 3.1 Feature Extraction and Enhancer
- 3.2 Language-Guided Query Selection
- 3.3 Cross-Modality Decoder
- 3.4 Sub-Sentence Level Text Feature
- 3.5 损失函数
- 四、一些可视化结果
一、摘要
作者展示一种开集目标检测方案:Grounding DINO,将将基于 Transformer 的检测器 DINO 与真值预训练相结合。
开集检测关键是引入 language 至闭集检测器,用于开集概念泛化。作者将闭集检测器分为三个阶段,提出一种紧密融合方案,包括 feature enhancer、language-guided query selection、cross-modality decoder。
作者除了对新颖类别进行检测还进行特定属性目标识别。在 COCO 数据集上零样本检测达到 52.5 AP,在 COCO 数据集 finetune 后达到 63 AP。
二、优点
Grounding DINO 相对于 GLIP 有以下优势:
- 基于 Transformer 结构与语言模型接近,易于处理跨模态特征;
- 基于 Transformer 的检测器有利用大规模数据集的能力;
- DINO 可以端到端优化,无需精细设计模块,比如:NMS。
目前开集检测器由闭集检测器引入语言信息实现,如下图所示:
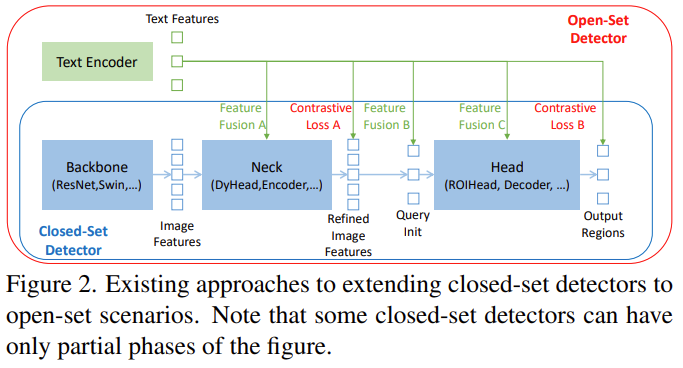
闭集检测器通过学习关注语言的区域编码,每个区域可分类为新类别,实现的关键是使用对比损失约束 neck 及 head 的区域输出及对应语言特征。
所以本文取得的成就为:
- 提出 Grounding DINO 通过多阶段跨模态融合改进开集目标检测器;
- 进一步在对 REC(Referring Expression Comprehension,目标指代物理解)数据集进行评估;
- 在COCO, LVIS, ODinW, and RefCOCO 数据集证明其有效性。
三、Grounding DINO 模型
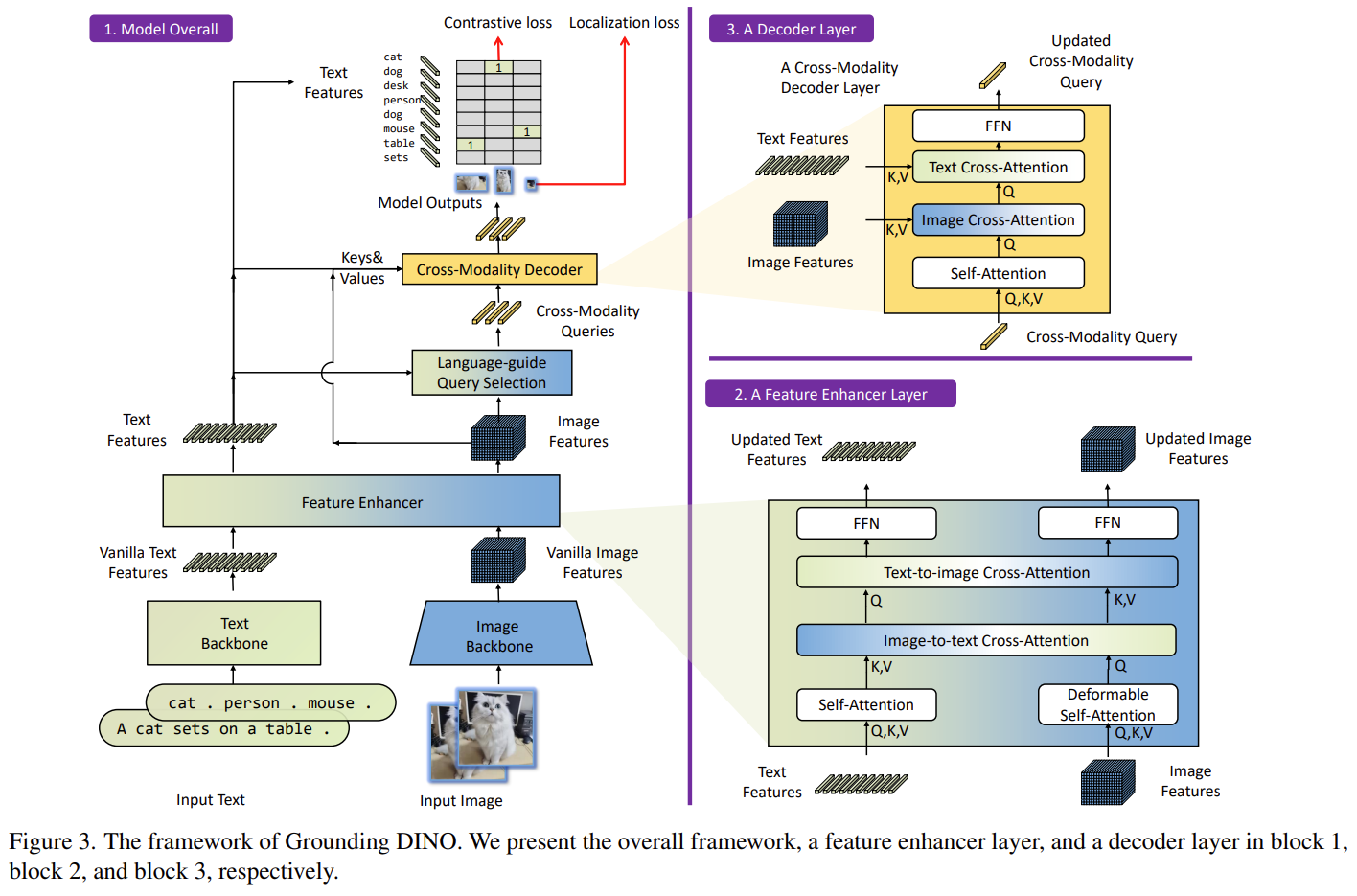
对于图片、文本对,Grounding DINO 可以输出多对目标框及对应名词短语。
Grounding DINO 采用双编码器,单解码器结构。
图像 backbone 用于提取图像特征,文本 backbone 用于提取文本特征,特征增强用于融合图像及文本特征,语言引导的 query 选择模块用于 query 初始化,跨模态解码器用于框精细化。
流程如下:
- 图像及文本 backbone 分别提取原始图像及文本特征;
- 特征强化模块用于跨模态特征融合;
- 通过语言引导查询选择模块从图像特征中选择与文本对应的跨模态 query;
- 跨模态解码器从跨模态 query 中提取需要特征,更新 query;
- 输出 query 用于预测目标框及提取对应短语。
3.1 Feature Extraction and Enhancer
Swin Transformer 用于提取图像特征,BERT 用于提取文本特征,特征强化层如上图中 block2,利用 Deformable self-attention 强化图像特征,原始的 self-attention 强化文本特征,受 GLIP 影响,增加图像到文本跨模态以及文本到图像跨模态,帮助对齐不同模态特征。
3.2 Language-Guided Query Selection
为引导文本进行目标检测,作者设计语言引导的 query 选择机制选择与文本更相关的特征作为解码器的 query。
算法下图所示。输出 num_query 索引,据此初始化 query。
每个 decoder query 包括两部分: content 及 position。
位置部分公式化为 dynamic anchor boxes,使用编码器输出进行初始化;内容部分训练中可学习。

"""
Input:
image_features: (bs, num_img_tokens, ndim)
text_features: (bs, num_text_tokens, ndim)
num_query: int.
Output:
topk_proposals_idx: (bs, num_query)
"""
logits = torch.einsum("bic,btc->bit",
image_features, text_features)
# bs, num_img_tokens, num_text_tokens
logits_per_img_feat = logits.max(-1)[0]
# bs, num_img_tokens
topk_proposals_idx = torch.topk(
logits_per_image_feature,
num_query, dim = 1)[1]
# bs, num_query
上面这段代码实现的功能是计算图像特征和文本特征之间的相似度得分。
具体来说,输入两个特征张量 image_features 和 text_features,其中 image_features 的维度为 (bs, num_img_tokens, ndim),text_features 的维度为 (bs, num_text_tokens, ndim),bs 表示 batch size,num_img_tokens 和 num_text_tokens 分别表示图像特征和文本特征的总数,ndim 则表示特征维度。
代码首先使用 torch.einsum 函数计算两个特征张量之间的得分矩阵 logits,其中 bic 表示 image_features 张量的维度(batch size x num_img_tokens x ndim),btc 表示 text_features 张量的维度(batch size x num_text_tokens x ndim),bit 表示输出得分矩阵的维度(batch size x num_img_tokens x num_text_tokens)。计算方法为将 image_features 张量的第二个维度和 text_features 张量的第二个维度进行矩阵乘法,得到 logits 张量。得分矩阵中的每个元素表示一个图像特征与一个文本特征之间的得分。
接下来,代码使用 logits.max(-1)[0] 得到 logits_per_img_feat 张量,该张量的维度为 (bs, num_img_tokens),其中每个元素表示一个图像特征与所有文本特征之间的最大得分。具体来说,logits.max(-1) 得到一个长度为 2 的元组,第一个元素是最大值张量,维度为 (bs, num_img_tokens),第二个元素是最大值索引张量,维度为 (bs, num_img_tokens)。因为我们只需要最大值张量,所以使用 [0] 表示取出最大值张量。
在下一行代码中,使用 torch.topk 函数得到每个图像特征对应的前 num_query 个文本特征的索引。具体来说,该函数用于在某个维度上寻找前k个最大值。在本例中,logits_per_image_feature 张量的每个元素表示一个图像特征与所有文本特征之间的最大得分,因此 torch.topk 函数在第二个维度上找到前 num_query 个最大值,结果保存到 topk_proposals_idx 张量中,维度为 (bs, num_query)。
3.3 Cross-Modality Decoder
跨模态解码器结合图像及文本模态信息,如上图 block3,跨模态 query 经过 self-attention 层,image cross-attention 层与图像特征结合,text cross-attention 层与文本特征结合,以及 FFN 层。与 DINO 相比,每个解码器都有一个额外的文本 cross-attention 层,引入文本信息,便于对齐模态。
3.4 Sub-Sentence Level Text Feature
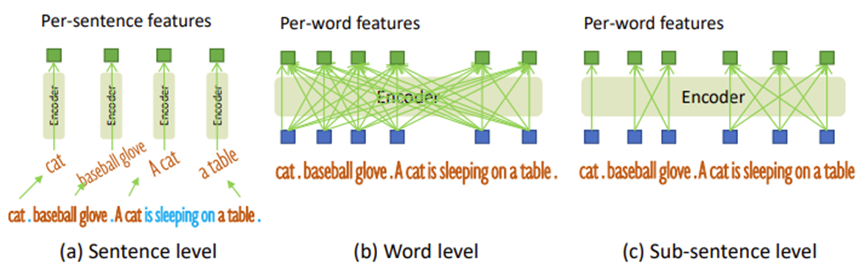
之前工作中探究了两种文本 prompt,如下图。
句子层级表征将整个句子编码为一个特征,移除了单词间影响;单词级表征能够编码多个类别,但引入不必要依赖关系;为避免不相关单词相互作用,作者引入 attention mask,此为 sub-sentence 级表征,既保留每个单词特征,又消除不相关单词间相互作用。
3.5 损失函数
类似 DETR,作者使用 L1 损失及 GIOU 损失用于框回归;沿用 GLIP,对预测目标是否匹配文本使用对比损失约束。
四、一些可视化结果