一、概述
1.Microsoft SQL Server系统的体系结构
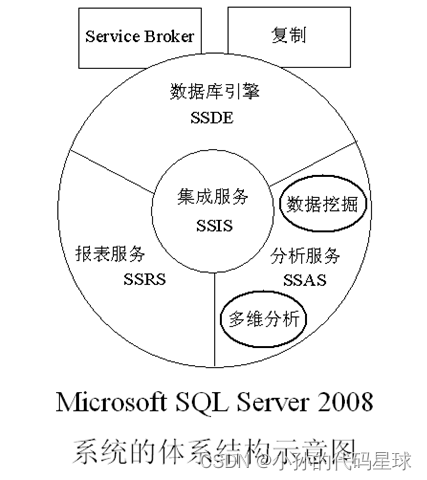
Microsoft SQL Server 2008系统由4个主要部分组成。这4个部分被称为4个服务,这些服务分别是数据库引擎、分析服务、报表服务和集成服务。这些服务之间相互存在和相互应用,它们的关系示意图如图所示:
2.数据库的类型和特点:
1.Microsoft SQL Server 2008系统提供了两种类型的数据库,即系统数据库和用户数据库。
2.系统数据库存放Microsoft SQL Server 2008系统的系统级信息,例如系统配置、数据库的属性、登录账户、数据库文件、数据库备份、警报、作业等信息。Microsoft SQL Server 2008使用这些系统级信息管理和控制整个数据库服务器系统。
3.用户数据库是由用户创建的、用来存放用户数据和对象的数据库。
二、安装和配置【不考】
三、管理安全性
角色
数据库角色是数据库级别的主体,也是数据库用户的集合。数据库用户可以作为数据库角色的成员,继承数据库角色的权限。
管理数据库角色
- 创建数据库角色
create role projectmanager/create role projectmanager authorization peter_user- 添加和删除数据库角色成员
sp_addrolemember 'role_name','security_account'- 查看数据库角色信息
sys.database_role_members- 修改和删除角色
alter role role_name with name new_role_namedrop role role_name
管理应用程序角色
架构
管理架构
- 创建架构
create schema companymanagercreate schema companymanager authorization peter_usercreate schema companymanager authorization create table elec(id int,name varchar(126))- 修改和删除架构
alter schema companymanager schoolmanagerdrop schema companymanger
权限
授予权限
GRANT <权限列表>
ON <关系名或视图名>
TO <用户或角色列表>;
修改权限
GRANT <权限列表>
ON <关系名或视图名>
TO <用户或角色列表>
WITH GRANT/ADMIN OPTION;
收回权限
REVOKE <权限列表>
ON <关系名或视图名>
FROM <用户或角色列表>;
数据库文件组成
-
数据文件:这些是包含实际存储在数据库中的数据的主文件。数据文件通常按表格组织,其中包含数据行和列。
-
索引文件:索引文件用于加速数据检索,提供了一种快速定位数据文件中特定记录的方法。可以在表格的一个或多个列上创建索引,以提高搜索数据的性能。
-
事务日志文件:这些文件用于记录对数据库进行的所有更改,包括插入、更新和删除操作。
数据库管理系统通常在执行写入操作时,首先将更改记录在事务日志文件中,然后再将更改写入数据文件中。这是因为在数据文件中写入更改之前,将其记录在日志文件中可以保证数据的一致性和完整性。
当系统意外崩溃或发生其他故障时,可以使用事务日志文件来还原数据库到崩溃之前的状态。恢复操作通常涉及使用日志文件中记录的操作来重建数据库,并确保任何未完成的事务得到正确处理。因此,事务日志文件在数据库管理中扮演着至关重要的角色。
快照作用和用途
快照是数据库中的一个重要概念,指的是在某个时间点上对数据库的一个镜像副本。快照记录了数据库在该时间点上的状态,包括其中的所有数据和元数据。与事务日志文件不同,快照不记录单个事务的更改历史,而是记录整个数据库在某个时间点上的状态。
快照的作用和用途如下:
-
数据备份:快照是创建数据库备份的一种方式。通过创建快照,可以在备份操作期间维护数据库的连续性和可用性,而不会对正在运行的生产环境产生负面影响。
-
数据恢复:如果在进行备份操作时发生了错误,可以使用快照来还原数据库到备份时的状态。
-
数据分析:快照可以用于进行数据分析和报告生成。在某个时间点上创建快照,可以在未来的时间点上进行分析和比较。
-
性能分析:快照可以用于数据库性能分析。通过比较不同时间点上的快照,可以分析数据库的性能趋势和瓶颈,并对数据库进行优化。
需要注意的是,快照并不是一个实时的数据库状态,而是某个时间点上的一个静态副本。如果在快照创建之后对数据库进行了更改,则这些更改不会反映在快照中。因此,在使用快照进行备份、恢复、分析和优化时,需要根据具体情况进行适当的管理和处理。
三、T-SQL
T-SQL(Transact-SQL)是一种扩展版的SQL(Structured Query Language),它是Microsoft SQL Server数据库管理系统所使用的SQL方言。下面是T-SQL的常见增删改查语句:
- 插入数据:
INSERT INTO table_name (column1, column2, column3, ...)
VALUES (value1, value2, value3, ...);
- 更新数据:
UPDATE table_name
SET column1 = value1, column2 = value2, ...
WHERE condition;
- 删除数据:
DELETE FROM table_name
WHERE condition;
- 查询数据:
SELECT column1, column2, ...
FROM table_name
WHERE condition;
需要注意的是,T-SQL和SQL是密切相关的,T-SQL是SQL的一种扩展版本,包含了更多的功能和特性。因此,T-SQL可以被认为是SQL的一种方言。大部分的SQL语句在T-SQL中同样适用,但是在T-SQL中也有一些SQL所没有的特殊语法和关键字,如存储过程、函数和变量等。同时,T-SQL还提供了许多SQL没有的高级特性,如事务处理、XML数据处理和窗口函数等。
重点T-SQL的使用
在T-SQL中,可以使用DECLARE语句定义变量。下面是一个使用T-SQL计算阶乘的例子:
DECLARE @number INT = 5;
DECLARE @factorial INT = 1;
DECLARE @counter INT = 1;
WHILE @counter <= @number
BEGIN
SET @factorial = @factorial * @counter;
SET @counter = @counter + 1;
END
PRINT 'Factorial of ' + CAST(@number AS VARCHAR(10)) + ' is ' + CAST(@factorial AS VARCHAR(20));
在上述例子中,使用DECLARE语句定义了三个变量,分别为@number、@factorial和@counter。然后使用WHILE循环计算阶乘,并将结果打印出来。
下面是一个使用T-SQL计算1到n的累加乘的例子:
DECLARE @n INT = 5;
DECLARE @result BIGINT = 1;
DECLARE @counter INT = 1;
WHILE @counter <= @n
BEGIN
SET @result = @result * @counter;
SET @counter = @counter + 1;
END
PRINT 'The product of 1 to ' + CAST(@n AS VARCHAR(10)) + ' is ' + CAST(@result AS VARCHAR(20));
在上述例子中,使用DECLARE语句定义了三个变量,分别为@n、@result和@counter。然后使用WHILE循环计算1到n的累加乘,并将结果打印出来。
需要注意的是,T-SQL中的变量必须使用DECLARE语句进行声明,并且必须指定变量的数据类型。在使用变量之前,必须先对其进行初始化。可以使用SET语句或SELECT INTO语句对变量进行赋值。
在T-SQL中,可以使用CREATE TABLE语句创建一个新的表。下面是一个创建表的示例:
CREATE TABLE MyTable (
ID INT PRIMARY KEY,
Name VARCHAR(50) NOT NULL,
Age INT,
Address VARCHAR(200)
);
在上述示例中,使用CREATE TABLE语句创建了一个名为MyTable的新表,该表包含ID、Name、Age和Address四个列。其中ID列被指定为主键,并且Name列被指定为NOT NULL,也就是说该列不能为空。
可以使用ALTER TABLE语句修改现有的表,例如添加或删除列,或者修改列的数据类型或约束等。下面是一个修改表的示例:
ALTER TABLE MyTable
ADD Email VARCHAR(100);
ALTER TABLE MyTable
ALTER COLUMN Age INT NOT NULL;
ALTER TABLE MyTable
DROP COLUMN Address;
在上述示例中,使用ALTER TABLE语句添加了一个名为Email的新列,修改了Age列的数据类型并将其指定为NOT NULL,最后删除了Address列。
需要注意的是,修改表时需要谨慎操作,因为这可能会影响到现有的数据和索引。在修改表结构之前,最好先备份数据以备不时之需。
四、特殊列全局统一标识符列
在SQL Server中,全局唯一标识符列(GUID列)是一种特殊的列类型,用于为每个记录分配全局唯一的标识符。GUID列通常用于分布式应用程序或需要在多个数据库之间同步数据的场景中。
要创建GUID列,可以使用uniqueidentifier数据类型,并在创建表时为该列指定一个默认值。例如,下面的T-SQL语句将创建一个包含GUID列的表:
CREATE TABLE MyTable (
ID UNIQUEIDENTIFIER DEFAULT NEWID() PRIMARY KEY,
Name VARCHAR(50) NOT NULL,
Age INT
);
在上述示例中,ID列被定义为UNIQUEIDENTIFIER类型,并使用DEFAULT关键字指定了一个默认值NEWID(),该函数会为每个新记录生成一个全局唯一的GUID。PRIMARY KEY约束用于将ID列定义为主键。
要向包含GUID列的表中插入新记录,可以使用NEWID()函数生成一个GUID值,例如:
INSERT INTO MyTable (ID, Name, Age) VALUES (NEWID(), 'John', 30);
需要注意的是,GUID值的唯一性是由GUID算法生成的,因此在极少数情况下,可能会发生GUID冲突。但在实际应用中,GUID值的重复几率非常小,因此GUID列通常可以作为全局唯一标识符使用。
五、什么是分区表及过程
在SQL Server中,分区表是一种特殊的表,它将数据分成多个区域(分区),每个分区可以单独进行管理和维护。分区表通常用于存储大量数据的表,可以提高查询和维护的效率。
创建分区表的过程如下:
-
创建分区函数:分区函数定义了如何将数据分配到不同的分区中。可以使用T-SQL中的CREATE PARTITION FUNCTION语句创建分区函数。例如:
CREATE PARTITION FUNCTION MyRangeFunc (INT) AS RANGE LEFT FOR VALUES (100, 200, 300);上述示例中创建了一个名为MyRangeFunc的分区函数,它将INT类型的数据分配到不同的分区中,分区边界为100、200、300。
-
创建分区方案:分区方案定义了如何将分区函数应用到表中。可以使用T-SQL中的CREATE PARTITION SCHEME语句创建分区方案。例如:
CREATE PARTITION SCHEME MyRangeScheme AS PARTITION MyRangeFunc TO ([PRIMARY], [PRIMARY], [PRIMARY], [PRIMARY]);上述示例中创建了一个名为MyRangeScheme的分区方案,它将MyRangeFunc分区函数应用到表中,并将数据分配到4个分区中,每个分区都使用[PRIMARY]文件组。
-
创建分区表:创建分区表时,需要指定分区方案和分区键。可以使用T-SQL中的CREATE TABLE语句创建分区表。例如:
CREATE TABLE MyPartitionedTable ( ID INT NOT NULL, Name VARCHAR(50) NOT NULL, Age INT, CONSTRAINT PK_MyPartitionedTable PRIMARY KEY (ID, Name) ) ON MyRangeScheme (ID);上述示例中创建了一个名为MyPartitionedTable的分区表,它使用了MyRangeScheme分区方案,并以ID列作为分区键。PRIMARY KEY约束包含了ID和Name两个列。
-
管理分区表:创建分区表后,可以使用ALTER PARTITION SCHEME、ALTER PARTITION FUNCTION和ALTER TABLE语句对分区表进行管理和维护。例如,可以使用ALTER PARTITION FUNCTION语句修改分区函数的分区边界,或者使用ALTER TABLE语句添加或删除分区。
六、分组
在SQL Server中,分组(GROUP BY)用于将数据集按照一个或多个列进行分组,并对每个组进行聚合计算。分组通常用于对查询结果进行分类汇总,以便更方便地进行数据分析。
要使用GROUP BY子句,需要在SELECT语句中指定要聚合计算的列,并在最后添加GROUP BY子句并指定用于分组的列。例如,以下是一个将订单按照客户和订单日期进行分组的示例:
SELECT CustomerID, OrderDate, SUM(TotalAmount) AS TotalSales
FROM Orders
GROUP BY CustomerID, OrderDate;
在上述示例中,CustomerID和OrderDate列被用于分组,SUM函数用于计算每个组的TotalAmount总和,并将结果命名为TotalSales列。
在GROUP BY子句中还可以使用聚合函数,如COUNT、MAX、MIN等,以便对每个组进行更复杂的聚合计算。例如,以下是一个按照客户分组并计算每个客户的订单数量和平均订单金额的示例:
SELECT CustomerID, COUNT(*) AS OrderCount, AVG(TotalAmount) AS AverageAmount
FROM Orders
GROUP BY CustomerID;
在上述示例中,COUNT函数用于计算每个客户的订单数量,AVG函数用于计算每个客户的平均订单金额。由于只有一个分组列(CustomerID),因此没有在SELECT子句中指定OrderDate列,也没有在GROUP BY子句中包含该列。
七、连接
在SQL Server中,连接(Join)用于将多个表中的数据联合在一起,以便进行更复杂的查询和分析。常见的连接类型包括:
-
内连接(INNER JOIN):内连接根据两个表之间的匹配条件,将符合条件的记录联合在一起。只有在两个表中都存在匹配条件的记录才会被包括在结果集中。
-
左连接(LEFT JOIN):左连接会包括左边表中的所有记录,并将符合条件的右边表中的记录联合在一起。如果右边表中没有符合条件的记录,则用NULL值填充。
-
右连接(RIGHT JOIN):右连接与左连接类似,不同之处在于它会包括右边表中的所有记录,并将符合条件的左边表中的记录联合在一起。如果左边表中没有符合条件的记录,则用NULL值填充。
-
全连接(FULL JOIN):全连接会包括左边表和右边表中的所有记录,并将符合条件的记录联合在一起。如果左边表或右边表中没有符合条件的记录,则用NULL值填充。
-
交叉连接(CROSS JOIN):交叉连接是一种特殊的连接类型,它会将一个表的每一行与另一个表的每一行进行组合,生成一个新的表。交叉连接通常用于生成笛卡尔积(Cartesian product)。
在SQL Server中,连接通常使用JOIN关键字和ON子句进行指定。例如,以下是一个内连接的示例:
SELECT *
FROM Orders
INNER JOIN Customers
ON Orders.CustomerID = Customers.CustomerID;
在上述示例中,使用INNER JOIN将Orders表和Customers表联合在一起,并使用ON子句指定连接条件。根据该条件,只有当Orders表和Customers表中都存在相同的CustomerID列时,才会将记录联合在一起。
八、索引
在SQL Server中,索引是一种用于提高查询性能的数据结构。索引可以帮助数据库系统快速地定位到符合查询条件的数据,而不需要全表扫描。常见的索引类型包括:
-
聚集索引(Clustered Index):聚集索引定义了表中数据的物理顺序,并按照索引键的值进行排序。每个表只能有一个聚集索引,因为表中的数据只能按照一个顺序进行存储。
-
非聚集索引(Nonclustered Index):非聚集索引将索引键的值与对应数据的位置进行映射,并按照索引键的值进行排序。一个表可以有多个非聚集索引。
-
唯一索引(Unique Index):唯一索引与非唯一索引类似,不同之处在于它要求索引键的值是唯一的。唯一索引可以用于保证表中数据的唯一性。
-
全文索引(Full-Text Index):全文索引是一种用于全文搜索的索引类型,可以提供高效的文本搜索功能。
在SQL Server中,可以使用CREATE INDEX语句来创建索引。例如,以下是一个创建非聚集索引的示例:
CREATE INDEX idx_customer_lastname ON Customers (LastName);
在上述示例中,使用CREATE INDEX创建了一个名为idx_customer_lastname的非聚集索引,它基于Customers表的LastName列。这个索引将LastName列的值与对应的行号进行映射,并按照LastName列的值进行排序。在查询中,如果包含了LastName列的条件,SQL Server将使用该索引来快速定位符合条件的数据。
九、最小单位页8k
在 SQL Server 中,最小的存储单位是页面(Page),一个页面的大小为8KB,每个页面可以存储一个或多个行。SQL Server 将表和索引的数据存储在数据文件中,数据文件被划分为多个固定大小的页面。每个页面都有一个唯一的标识符,称为 Page ID。当数据库引擎需要从磁盘中读取数据时,它将以页面为单位进行读取,而不是以行为单位。这意味着如果要读取一行数据,即使这个行只有一个字节,也需要读取整个页面的8KB。因此,在设计表结构和索引时,需要考虑如何最小化数据的存储和读取成本,以提高查询性能。
十、数据库的完整性概念
数据库的完整性(Integrity)是指数据库中存储的数据满足特定的约束条件,这些约束条件可以保证数据的正确性、一致性和有效性。数据库的完整性包括以下几个方面:
-
实体完整性:指在一个表中,每一行数据都必须有一个唯一的标识符,即主键。主键必须唯一、非空,且不可更改。此外,主键还可以包含多个列,称为复合主键。
-
参照完整性:指在一个表中的外键引用另一个表的主键时,外键值必须存在于被引用表的主键中。如果被引用表中的主键被修改或删除,那么引用该主键的所有外键也必须被更新或删除,以保持数据的一致性。
-
用户定义的完整性:指除了实体完整性和参照完整性之外,用户可以定义其他的约束条件,例如 CHECK 约束、DEFAULT 约束等,以保证数据的有效性和正确性。
-
域完整性:指在数据库中定义的域(Domain)必须满足一定的约束条件,例如数据类型、长度、格式等。
维护数据库完整性的方法包括:
-
使用约束条件:SQL Server 提供了多种约束条件,例如 PRIMARY KEY、FOREIGN KEY、CHECK、DEFAULT 等,可以用来定义数据的完整性。当违反约束条件时,SQL Server 会自动拒绝修改操作,并给出相应的错误信息。
-
使用触发器:触发器可以在特定的数据修改操作(INSERT、UPDATE、DELETE)发生时执行一些特定的业务逻辑,例如数据校验、数据转换等,从而保证数据的完整性。
-
使用存储过程:存储过程可以对数据进行复杂的业务逻辑处理,并在一定程度上保证数据的完整性。
维护数据库的完整性是数据库管理的重要任务之一,可以确保数据的准确性和可靠性。
十一、约束如何创建主键外键
在 SQL Server 中,可以使用 CREATE TABLE 或 ALTER TABLE 语句来创建主键和外键约束。
创建主键约束:
主键约束用于唯一标识一个表中的每一行数据。要创建主键约束,可以在 CREATE TABLE 语句中指定 PRIMARY KEY 关键字和主键列,或者使用 ALTER TABLE 语句来添加主键约束。
CREATE TABLE 语法示例:
CREATE TABLE TableName
(
Column1 INT PRIMARY KEY,
Column2 VARCHAR(50),
Column3 DECIMAL(10,2)
);
ALTER TABLE 语法示例:
ALTER TABLE TableName
ADD CONSTRAINT PK_TableName PRIMARY KEY (Column1);
创建外键约束:
外键约束用于在两个表之间建立关系,确保一个表中的数据可以与另一个表中的数据进行关联。要创建外键约束,需要在包含外键的表中定义外键列和引用表中的主键列,然后使用 FOREIGN KEY 关键字创建约束。
CREATE TABLE 语法示例:
CREATE TABLE Table1
(
Column1 INT PRIMARY KEY,
Column2 VARCHAR(50)
);
CREATE TABLE Table2
(
Column3 INT PRIMARY KEY,
Column4 VARCHAR(50),
Table1ID INT FOREIGN KEY REFERENCES Table1(Column1)
);
ALTER TABLE 语法示例:
ALTER TABLE Table2
ADD CONSTRAINT FK_Table2_Table1 FOREIGN KEY (Table1ID) REFERENCES Table1(Column1);
注意:创建外键约束时需要确保引用表中的主键列必须是唯一且非空的。如果引用表中的主键列包含多个列,则必须在外键列中包含相同的列,并按照相同的顺序进行引用。另外,如果要删除包含外键约束的表,需要先删除所有引用该表的其他表的外键约束,否则会导致删除失败。
十二、视图的概念及优缺点
视图是一个虚拟的表,它并不实际存储数据,而是由一个查询定义的结果集。在 SQL Server 中,视图可以简化复杂查询、保护敏感数据、重用常用查询逻辑等。
视图的优点包括:
-
简化复杂查询:当需要从多个表中检索数据时,可以使用视图来简化查询的语句。视图将多个表的数据组合成一个逻辑上的表,使得查询更容易编写和理解。
-
保护敏感数据:可以使用视图来限制用户对敏感数据的访问权限。通过创建视图来隐藏敏感数据的详细信息,只允许用户访问视图的特定列和行,可以更好地保护数据的安全性。
-
重用常用查询逻辑:当需要多次使用相同的查询逻辑时,可以使用视图来重用这些查询逻辑。可以将查询逻辑定义为视图,并将视图作为查询的基础,这样就可以减少代码量,并提高代码的可维护性。
-
简化数据访问:视图可以为用户提供简单易用的数据访问接口。通过将复杂的查询逻辑封装在视图中,用户可以使用简单的 SELECT 语句来访问数据,而不需要了解复杂的查询逻辑。
视图的缺点包括:
-
性能问题:由于视图需要在查询时动态生成结果集,所以查询视图的性能可能会比查询实际存储数据的表慢。
-
更新问题:视图通常不支持对其进行直接的更新操作,因为它们只是虚拟的表。如果需要更新视图中的数据,可能需要对其对应的基础表进行更新。
-
复杂性问题:当视图与多个表相关联时,可能会变得很复杂。在这种情况下,可能需要编写复杂的查询逻辑来获取需要的数据。
创建视图
在 SQL Server 中,可以使用 CREATE VIEW 语句来创建视图。CREATE VIEW 语句的语法如下:
CREATE VIEW view_name AS
SELECT column1, column2, ...
FROM table_name
WHERE condition;
其中,view_name 是视图的名称,column1, column2, … 是要包含在视图中的列的名称,table_name 是要从中选择数据的表的名称,condition 是一个可选的条件,用于限制从表中选择的数据。注意,SELECT 语句可以是任何有效的 SELECT 语句,包括使用 JOIN、GROUP BY、HAVING 等语句的复杂查询。
下面是一个创建视图的示例:
CREATE VIEW dbo.ProductView AS
SELECT ProductID, ProductName, CategoryName, UnitPrice
FROM Products p
INNER JOIN Categories c ON p.CategoryID = c.CategoryID;
该视图名为 ProductView,从 Products 表和 Categories 表中选择数据,并连接它们,以便获取产品 ID、产品名称、类别名称和单位价格。
在创建视图后,可以像查询表一样使用它。例如,可以使用以下查询检索 ProductView 视图中的数据:
SELECT * FROM dbo.ProductView;
视图是只读的,不能对其进行直接的更新操作。如果需要更新视图中的数据,可能需要对其对应的基础表进行更新。
十三、触发器
触发器是一种特殊的存储过程,它是与表相关联的一组 T-SQL 语句,当满足特定条件时自动触发执行。
触发器可以用来对数据库进行自动化控制和约束,例如在插入、更新、删除表中的数据时,触发器可以自动执行一些额外的逻辑操作,如检查数据的完整性、记录审计信息等。
SQL Server 支持两种类型的触发器:行级触发器和语句级触发器。行级触发器是与每一行数据相关联的触发器,当每一行数据发生改变时都会自动触发执行;而语句级触发器是与整个语句相关联的触发器,只有在整个语句执行完成后才会触发执行。
触发器的优点包括:
-
数据的约束和保护。通过触发器可以对表中的数据进行约束和保护,防止非法操作和错误数据的插入、更新和删除。
-
数据库的自动化控制和维护。通过触发器可以对数据库进行自动化控制和维护,例如在某些情况下可以自动化地记录审计信息、更新数据等。
-
提高了数据的完整性和安全性。通过触发器可以提高数据的完整性和安全性,保证数据的正确性和完整性。
创建触发器可以使用 SQL Server Management Studio (SSMS) 或 Transact-SQL (T-SQL) 语句来创建。下面是一个简单的创建触发器的 T-SQL 示例:
CREATE TRIGGER trCustomerOrders
ON Customers
AFTER INSERT
AS
BEGIN
INSERT INTO Orders (CustomerID, OrderDate)
SELECT CustomerID, GETDATE()
FROM inserted
END;
该触发器名为 trCustomerOrders,与 Customers 表相关联,当在该表中插入数据时触发执行。该触发器将插入一个新的订单记录到 Orders 表中,包括 CustomerID 和当前日期。在此示例中,使用了一个名为 inserted 的特殊表,它包含了刚刚插入的所有行的数据。
十四、备份和还原
数据库备份和还原是数据库管理中非常重要的一环。备份是指将数据库中的数据和日志文件复制到另一个位置,以便在数据丢失或损坏时能够恢复数据。还原是指将备份文件中的数据和日志文件还原到数据库中,以恢复数据库到备份时的状态。
在 SQL Server 中,可以使用 SQL Server Management Studio (SSMS) 或 Transact-SQL (T-SQL) 语句来进行数据库备份和还原。以下是备份和还原的一些基本步骤:
备份数据库:
-
打开 SQL Server Management Studio,连接到 SQL Server 数据库引擎。
-
在 Object Explorer 中,展开服务器节点和数据库节点,右键单击要备份的数据库,选择“Tasks”->“Back Up”。
-
在“Back Up Database”对话框中,选择备份类型和备份文件的位置和名称。
-
点击“OK”按钮开始备份。
还原数据库:
-
打开 SQL Server Management Studio,连接到 SQL Server 数据库引擎。
-
在 Object Explorer 中,展开服务器节点和数据库节点,右键单击要还原的数据库,选择“Tasks”->“Restore”->“Database”。
-
在“Restore Database”对话框中,选择备份文件的位置和名称,并选择要还原的备份集。
-
在“Options”选项卡中,选择恢复选项和数据库文件的位置和名称。
-
点击“OK”按钮开始还原。
备份和还原数据库的频率应该根据数据库的重要性和更新频率来决定。对于重要的生产数据库,建议定期进行完整备份,并根据情况进行差异备份和事务日志备份,以便在数据丢失或损坏时能够快速恢复数据。
数据库备份和恢复是数据库管理中非常重要的一部分,了解数据库恢复模式和备份类型很重要。
- 数据库恢复模式
在 SQL Server 中,有三种数据库恢复模式:
-
完整恢复模式(Full Recovery Model):这种模式可以实现完整的恢复操作,包括事务日志备份、差异备份和完整备份等。可以进行精确的事务级别恢复,并能恢复到某个时间点之前的状态。
-
简单恢复模式(Simple Recovery Model):这种模式只支持完整备份和差异备份。每次事务提交后,事务日志都会被截断,无法进行事务级别的恢复。如果数据丢失或损坏,只能还原最近的一次完整备份和差异备份。
-
大容量日志恢复模式(Bulk-Logged Recovery Model):这种模式可以对大量数据的批量操作进行优化,同时支持完整备份、差异备份和事务日志备份。在进行大量数据操作时,可以切换到简单恢复模式来避免事务日志过大,然后再切换回来进行日志备份。
- 数据库备份类型
在 SQL Server 中,有四种数据库备份类型:
-
完整备份(Full Backup):备份整个数据库,包括数据文件和事务日志。
-
差异备份(Differential Backup):备份上次完整备份以来修改的数据。
-
事务日志备份(Transaction Log Backup):备份数据库事务日志,包括从上次备份后提交的所有事务。
-
文件或文件组备份(File or Filegroup Backup):备份数据库中的文件或文件组。
备份类型和备份策略应根据业务需求和数据库特点来确定。例如,对于关键业务数据,应该定期进行完整备份和事务日志备份,以便快速恢复数据。对于较大的数据库,可以选择差异备份来减少备份时间和空间。
执行备份操作和还原操作需要使用 SQL Server Management Studio 或 Transact-SQL 语句。以下是备份和还原的基本语法:
- 备份语句
完整备份:
BACKUP DATABASE database_name TO disk = 'backup_file_path' WITH INIT
差异备份:
BACKUP DATABASE database_name TO disk = 'backup_file_path' WITH DIFFERENTIAL
事务日志备份:
BACKUP LOG database_name TO disk = 'backup_file_path'
文件或文件组备份:
BACKUP DATABASE database_name FILE = 'file_or_filegroup_name' TO disk = 'backup_file_path'
- 还原语句
完整备份还原:
RESTORE DATABASE database_name FROM disk = 'backup_file_path' WITH REPLACE
差异备份还原:
RESTORE DATABASE database_name FROM disk = 'backup_file_path' WITH NORECOVERY
RESTORE DATABASE database_name FROM disk = 'differential_backup_file_path' WITH RECOVERY
事务日志备份还原:
RESTORE LOG database_name FROM disk = 'backup_file_path' WITH NORECOVERY
RESTORE LOG database_name FROM disk = 'transaction_log_backup_file_path' WITH RECOVERY
文件或文件组备份还原:
RESTORE DATABASE database_name FILE = 'file_or_filegroup_name' FROM disk = 'backup_file_path' WITH RECOVERY
以上仅是备份和还原的基本语法,具体使用还需要根据情况来确定备份类型、备份路径等参数,并且需要进行更多的备份和还原细节设置。