1.下载
官网下载:Downloads | Apache Flink
阿里网盘下载(包含依赖包):阿里云盘分享
提取码:9bl2
2.解压
tar -zxvf flink-1.12.7-bin-scala_2.11.tgz -C ../opt/module3.修改配置文件
cd flink-1.12.7/conf/修改 flink-conf.yaml 文件
修改 masters 文件
创建 workers 文件
3.1修改 flink-conf.yaml 文件
具体配置按照自己的集群配置来
################################################################################
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
################################################################################
#==============================================================================
# Common
#==============================================================================
# The external address of the host on which the JobManager runs and can be
# reached by the TaskManagers and any clients which want to connect. This setting
# is only used in Standalone mode and may be overwritten on the JobManager side
# by specifying the --host <hostname> parameter of the bin/jobmanager.sh executable.
# In high availability mode, if you use the bin/start-cluster.sh script and setup
# the conf/masters file, this will be taken care of automatically. Yarn/Mesos
# automatically configure the host name based on the hostname of the node where the
# JobManager runs.
jobmanager.rpc.address: hadoop102
# The RPC port where the JobManager is reachable.
jobmanager.rpc.port: 6123
# The heap size for the JobManager JVM
jobmanager.heap.size: 800m
# The total process memory size for the TaskManager.
#
# Note this accounts for all memory usage within the TaskManager process, including JVM metaspace and other overhead.
taskmanager.memory.process.size: 1024m
# To exclude JVM metaspace and overhead, please, use total Flink memory size instead of 'taskmanager.memory.process.size'.
# It is not recommended to set both 'taskmanager.memory.process.size' and Flink memory.
#
#taskmanager.memory.flink.size: 1280m
# The number of task slots that each TaskManager offers. Each slot runs one parallel pipeline.
taskmanager.numberOfTaskSlots: 1
# The parallelism used for programs that did not specify and other parallelism.
parallelism.default: 1
# The default file system scheme and authority.
#
# By default file paths without scheme are interpreted relative to the local
# root file system 'file:///'. Use this to override the default and interpret
# relative paths relative to a different file system,
# for example 'hdfs://mynamenode:12345'
#
# fs.default-scheme
#==============================================================================
# High Availability
#==============================================================================
# The high-availability mode. Possible options are 'NONE' or 'zookeeper'.
#
high-availability: zookeeper
# The path where metadata for master recovery is persisted. While ZooKeeper stores
# the small ground truth for checkpoint and leader election, this location stores
# the larger objects, like persisted dataflow graphs.
#
# Must be a durable file system that is accessible from all nodes
# (like HDFS, S3, Ceph, nfs, ...)
#
high-availability.storageDir: hdfs://192.168.233.130:8020/flink/ha/
# The list of ZooKeeper quorum peers that coordinate the high-availability
# setup. This must be a list of the form:
# "host1:clientPort,host2:clientPort,..." (default clientPort: 2181)
#
high-availability.zookeeper.quorum: 192.168.233.130:2181,192.168.233.131:2181,192.168.233.132:2181
# ACL options are based on https://zookeeper.apache.org/doc/r3.1.2/zookeeperProgrammers.html#sc_BuiltinACLSchemes
# It can be either "creator" (ZOO_CREATE_ALL_ACL) or "open" (ZOO_OPEN_ACL_UNSAFE)
# The default value is "open" and it can be changed to "creator" if ZK security is enabled
#
high-availability.zookeeper.client.acl: open
#==============================================================================
# Fault tolerance and checkpointing
#==============================================================================
# The backend that will be used to store operator state checkpoints if
# checkpointing is enabled.
#
# Supported backends are 'jobmanager', 'filesystem', 'rocksdb', or the
# <class-name-of-factory>.
#
state.backend: filesystem
# Directory for checkpoints filesystem, when using any of the default bundled
# state backends.
#
state.checkpoints.dir: hdfs://192.168.233.130:8020/flink-checkpoints
# Default target directory for savepoints, optional.
#
state.savepoints.dir: hdfs://192.168.233.130:8020/flink-checkpoints
# Flag to enable/disable incremental checkpoints for backends that
# support incremental checkpoints (like the RocksDB state backend).
#
# state.backend.incremental: false
# The failover strategy, i.e., how the job computation recovers from task failures.
# Only restart tasks that may have been affected by the task failure, which typically includes
# downstream tasks and potentially upstream tasks if their produced data is no longer available for consumption.
jobmanager.execution.failover-strategy: region
#==============================================================================
# Rest & web frontend
#==============================================================================
# The port to which the REST client connects to. If rest.bind-port has
# not been specified, then the server will bind to this port as well.
#
rest.port: 8081
# The address to which the REST client will connect to
#
rest.address: 0.0.0.0
# Port range for the REST and web server to bind to.
#
rest.bind-port: 8080-8090
# The address that the REST & web server binds to
#
rest.bind-address: 0.0.0.0
# Flag to specify whether job submission is enabled from the web-based
# runtime monitor. Uncomment to disable.
web.submit.enable: true
#==============================================================================
# Advanced
#==============================================================================
# Override the directories for temporary files. If not specified, the
# system-specific Java temporary directory (java.io.tmpdir property) is taken.
#
# For framework setups on Yarn or Mesos, Flink will automatically pick up the
# containers' temp directories without any need for configuration.
#
# Add a delimited list for multiple directories, using the system directory
# delimiter (colon ':' on unix) or a comma, e.g.:
# /data1/tmp:/data2/tmp:/data3/tmp
#
# Note: Each directory entry is read from and written to by a different I/O
# thread. You can include the same directory multiple times in order to create
# multiple I/O threads against that directory. This is for example relevant for
# high-throughput RAIDs.
#
# io.tmp.dirs: /tmp
# The classloading resolve order. Possible values are 'child-first' (Flink's default)
# and 'parent-first' (Java's default).
#
# Child first classloading allows users to use different dependency/library
# versions in their application than those in the classpath. Switching back
# to 'parent-first' may help with debugging dependency issues.
#
# classloader.resolve-order: child-first
# The amount of memory going to the network stack. These numbers usually need
# no tuning. Adjusting them may be necessary in case of an "Insufficient number
# of network buffers" error. The default min is 64MB, the default max is 1GB.
#
# taskmanager.memory.network.fraction: 0.1
#taskmanager.memory.network.min: 128mb
#taskmanager.memory.network.max: 1gb
#==============================================================================
# Flink Cluster Security Configuration
#==============================================================================
# Kerberos authentication for various components - Hadoop, ZooKeeper, and connectors -
# may be enabled in four steps:
# 1. configure the local krb5.conf file
# 2. provide Kerberos credentials (either a keytab or a ticket cache w/ kinit)
# 3. make the credentials available to various JAAS login contexts
# 4. configure the connector to use JAAS/SASL
# The below configure how Kerberos credentials are provided. A keytab will be used instead of
# a ticket cache if the keytab path and principal are set.
# security.kerberos.login.use-ticket-cache: true
# security.kerberos.login.keytab: /path/to/kerberos/keytab
# security.kerberos.login.principal: flink-user
# The configuration below defines which JAAS login contexts
# security.kerberos.login.contexts: Client,KafkaClient
#==============================================================================
# ZK Security Configuration
#==============================================================================
# Below configurations are applicable if ZK ensemble is configured for security
# Override below configuration to provide custom ZK service name if configured
# zookeeper.sasl.service-name: zookeeper
# The configuration below must match one of the values set in "security.kerberos.login.contexts"
# zookeeper.sasl.login-context-name: Client
#==============================================================================
# HistoryServer
#==============================================================================
# The HistoryServer is started and stopped via bin/historyserver.sh (start|stop)
# Directory to upload completed jobs to. Add this directory to the list of
# monitored directories of the HistoryServer as well (see below).
jobmanager.archive.fs.dir: hdfs://192.168.233.130:8020/completed-jobs/
# The address under which the web-based HistoryServer listens.
#historyserver.web.address: 0.0.0.0
# The port under which the web-based HistoryServer listens.
historyserver.web.port: 8082
# Comma separated list of directories to monitor for completed jobs.
historyserver.archive.fs.dir: hdfs://192.168.233.130:8020/completed-jobs/
# Interval in milliseconds for refreshing the monitored directories.
historyserver.archive.fs.refresh-interval: 10000
3.2修改masters
192.168.233.130:80813.3创建workers
里面配置 集群 各机器的 ip 或者 主机名
192.168.233.130
192.168.233.131
192.168.233.1324.分发集群
scp -r flink-1.12.7 hadoop103:/opt/module
scp -r flink-1.12.7 hadoop104:/opt/module5.配置环境变量
vim /etc/profile.d/my_env.sh
#FLINK_HOME
export FLINK_HOME=/opt/module/flink-1.12.7
export PATH=$FLINK_HOME/bin:$PATH
6.分发环境变量
scp /etc/profile.d/my_env.sh hadoop102:/etc/profile.d/
scp /etc/profile.d/my_env.sh hadoop103:/etc/profile.d/7.source 环境变量
集群节点1:source /etc/profile.d/my_env.sh
集群节点2:source /etc/profile.d/my_env.sh
集群节点3:source /etc/profile.d/my_env.sh8.添加依赖包
可以不添加试试,直接 bin/start-cluster.sh 启动 flink集群
不出意外的话 可能会出现一系列 的错误
https://mvnrepository.com/
搜索 commons-cli-1.4.jar 和 flink-shaded-hadoop-3-uber-3.1.1.7.2.1.0-327-9.0.jar 并下载
这个当然会有点慢
不过我在阿里云盘中已经放置了,可以去里面下载
9.启动flink集群
bin/start-cluster.shStarting standalonesession daemon on host hadoop102.
Starting taskexecutor daemon on host hadoop102.
Starting taskexecutor daemon on host hadoop103.
Starting taskexecutor daemon on host hadoop104.
实在不放心,在每个机器上 jps 查看下 是否又有对应的进程
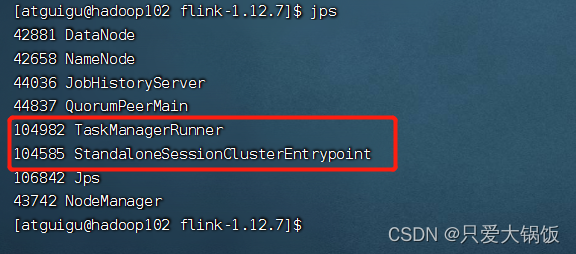

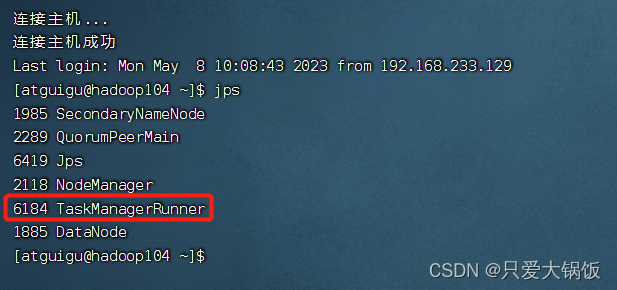
10.查看 flink web ui
http://192.168.233.130:8081/

11.测试
bin/flink run examples/streaming/WordCount.jar日志:
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/module/flink-1.12.7/lib/chunjun/chunjun-dist/connector/iceberg/chunjun-connector-iceberg.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/module/flink-1.12.7/lib/chunjun-dist/connector/iceberg/chunjun-connector-iceberg.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/module/flink-1.12.7/lib/chunjun/lib/log4j-slf4j-impl-2.16.0.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/module/flink-1.12.7/lib/log4j-slf4j-impl-2.16.0.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/module/flink-1.12.7/lib/slf4j-log4j12-1.7.15.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
Executing WordCount example with default input data set.
Use --input to specify file input.
Printing result to stdout. Use --output to specify output path.
Job has been submitted with JobID c537bf865e69549f725bb167bfa64c18
Program execution finished
Job with JobID c537bf865e69549f725bb167bfa64c18 has finished.
Job Runtime: 2678 ms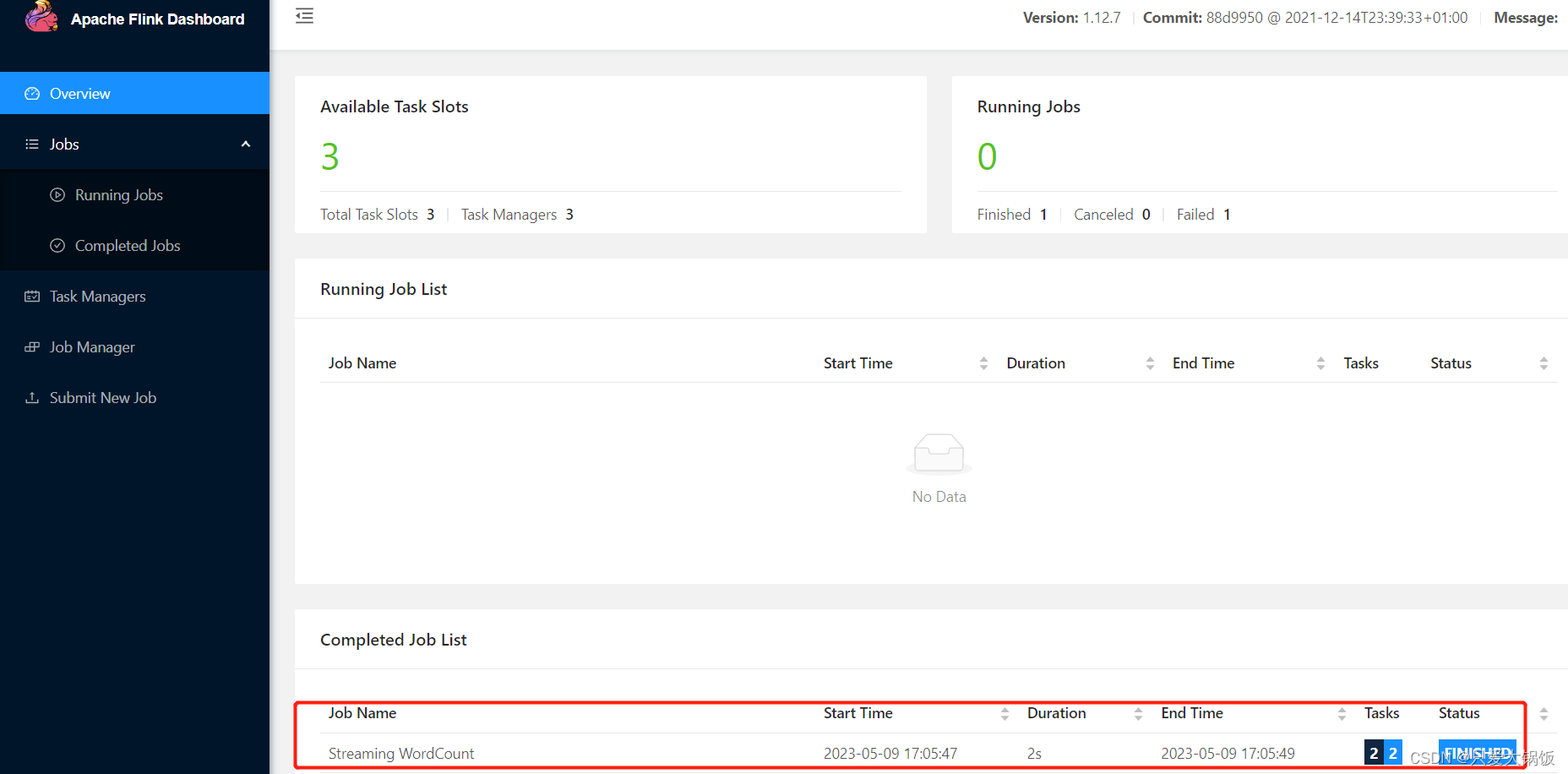
成功!
![[C++]string的使用](https://img-blog.csdnimg.cn/b71b46e263304e0798db79e48fbdea2d.png)
![[Dubbo] 重要接口与类 (三)](https://img-blog.csdnimg.cn/213f81e69c444b35923d9a61d6f68c9b.png)





![[Qt编程之Widgets模块] -001: QButtonGroup抽象容器](https://img-blog.csdnimg.cn/41bfc0cdf798465e81b8c7dc491d32bb.png)