冯老爷子的模型
首先,我们从一个问题开始( ̄∇ ̄)/
为什么需要程序员?
早期的计算机程序是硬件化的,即使用各种门电路组装出一个固定的电路板,这个电路板只能用于执行某个特定的程序,如果需要修改程序功能,就要新组装一个电路板。而一位叫做冯诺依曼的老爷子的出现,提出了一种指令数据化的思想,使得程序和数据一样,可以存储起来,组合调用,至此,程序脱离了电路板的桎梏,成为了可以人为组合的指令集,程序员应运而生。
当然,我们需要郑重地介绍下这位冯老爷子
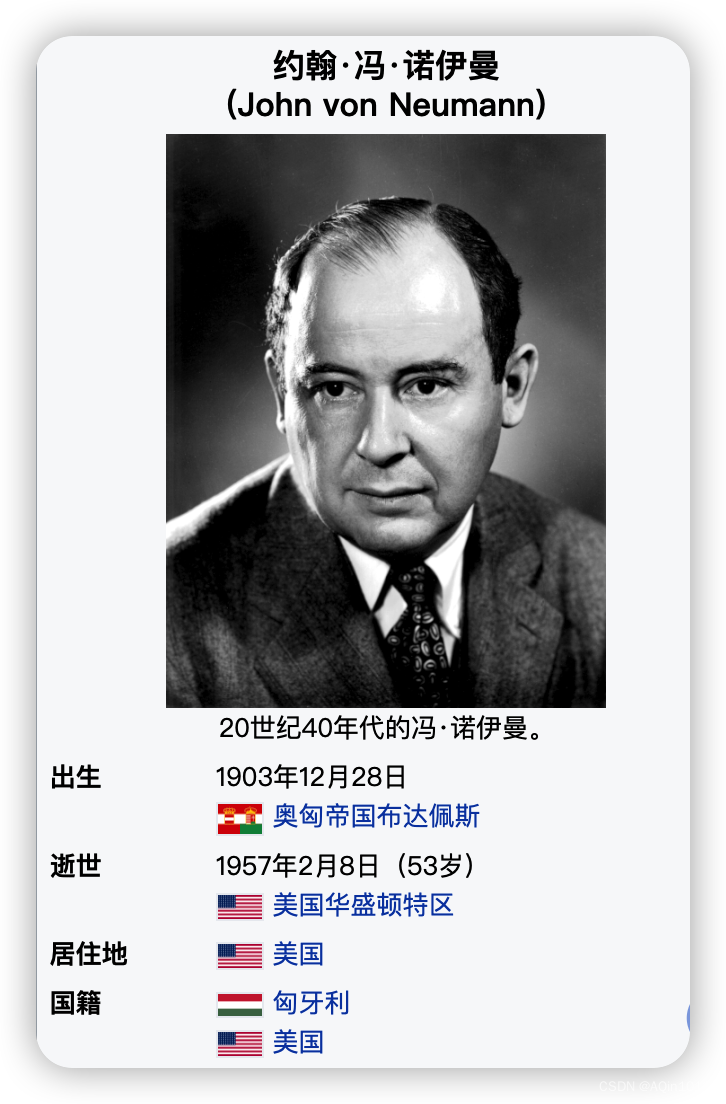
约翰·冯·诺伊曼(德语:John von Neumann,德语发音:[joːn.fɔn.ˈnɔɪ̯man],英语发音:/dʒɒn.vɒn.ˈnɔɪmən/,1903年12月28日—1957年2月8日),原名诺依曼·亚诺什·拉约什(匈牙利语:Neumann János Lajos,匈牙利语发音:[ˈnɒjmɒn ˈjaːnoʃ ˈlɒjoʃ]),出生于匈牙利的美国籍犹太人数学家,理论计算机科学与博弈论的奠基者,在泛函分析、遍历理论、几何学、拓扑学和数值分析等众多数学领域及电脑科学、量子力学和经济学中都有重大贡献。 —— 维基百科
冯诺伊曼计算机模型
冯·诺伊曼结构/计算机模型(英语:Von Neumann architecture),也称冯·纽曼模型(Von Neumann model)或普林斯顿结构(Princeton architecture),是一种将程序指令存储器和数据存储器合并在一起的电脑设计概念结构。本词描述的是一种实作通用图灵机的计算装置,以及一种相对于平行计算的序列式架构参考模型(referential model)。 —— 维基百科
冯诺依曼计算机模型(von Neumann architecture)是一种计算机硬件结构,在这种结构中,程序指令和数据共用同一块存储器,并通过控制单元来管理这些数据和程序指令的执行。这个模型是20世纪40年代由物理学家冯诺依曼(John von Neumann)提出的,至今仍然是计算机设计的主流模型。冯诺依曼结构的灵魂在于其思想减少了硬件的连接,导致硬件与软件的分离,即我们可以分别设计硬件与软件,
冯诺依曼计算机模型由五个部分组成:
-
运算器(Arithmetic and Logic Unit,ALU):负责执行各种算术和逻辑运算,例如加减乘除、与或非等运算。
-
控制器(Control Unit,CU):负责控制程序执行的流程和计算机硬件的操作,管理指令和数据的读写操作,指挥各种器件进行计算。
-
存储器(Memory):用于存储数据和程序指令。在冯诺依曼计算机模型中,存储器以线性地址方式编址,在同一块存储器内含有数据和指令两部分,程序指令和数据共享同样的物理存储器。
-
输入设备(Input Devices):用于向内部设备输入数据,例如键盘、鼠标等。
-
输出设备(Output Devices):用于向外部设备输出数据,例如显示器、打印机等。
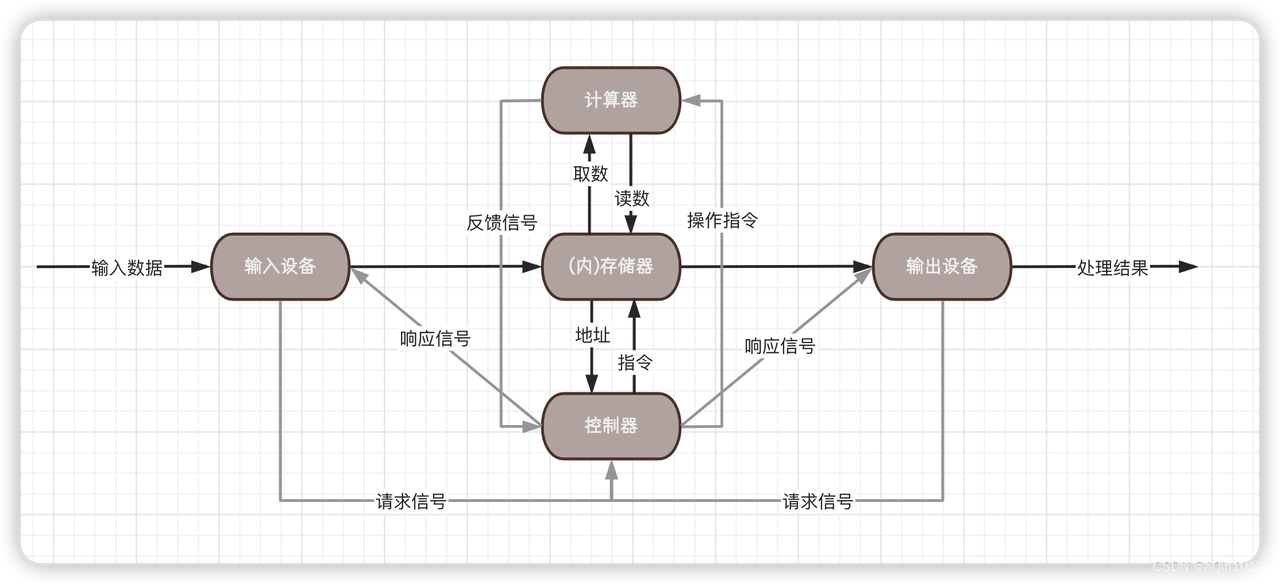
冯诺依曼计算机模型的优点在于它的简单性和灵活性,由于指令和数据共用同一块存储器,并且程序可以通过更改存储器中的指令来修改计算机的行为,使得程序可以随意修改,更加灵活。这个模型随着计算机技术的不断发展得到不断完善,并且被广泛应用在现代计算机的设计中。
在冯诺依曼计算机模型中, 运算器(Arithmetic and Logic Unit,ALU)和控制器(Control Unit,CU)组成了CPU,负责执行各种算术和逻辑运算,并管理指令和数据的读写操作,指挥各种器件进行计算;存储器即内存,则是计算机中用于存储指令和数据的设备,接下来我们就介绍下CPU和内存这两大核心
CPU
CPU指令结构
CPU的内部结构
-
控制单元
-
运算单元
-
数据单元
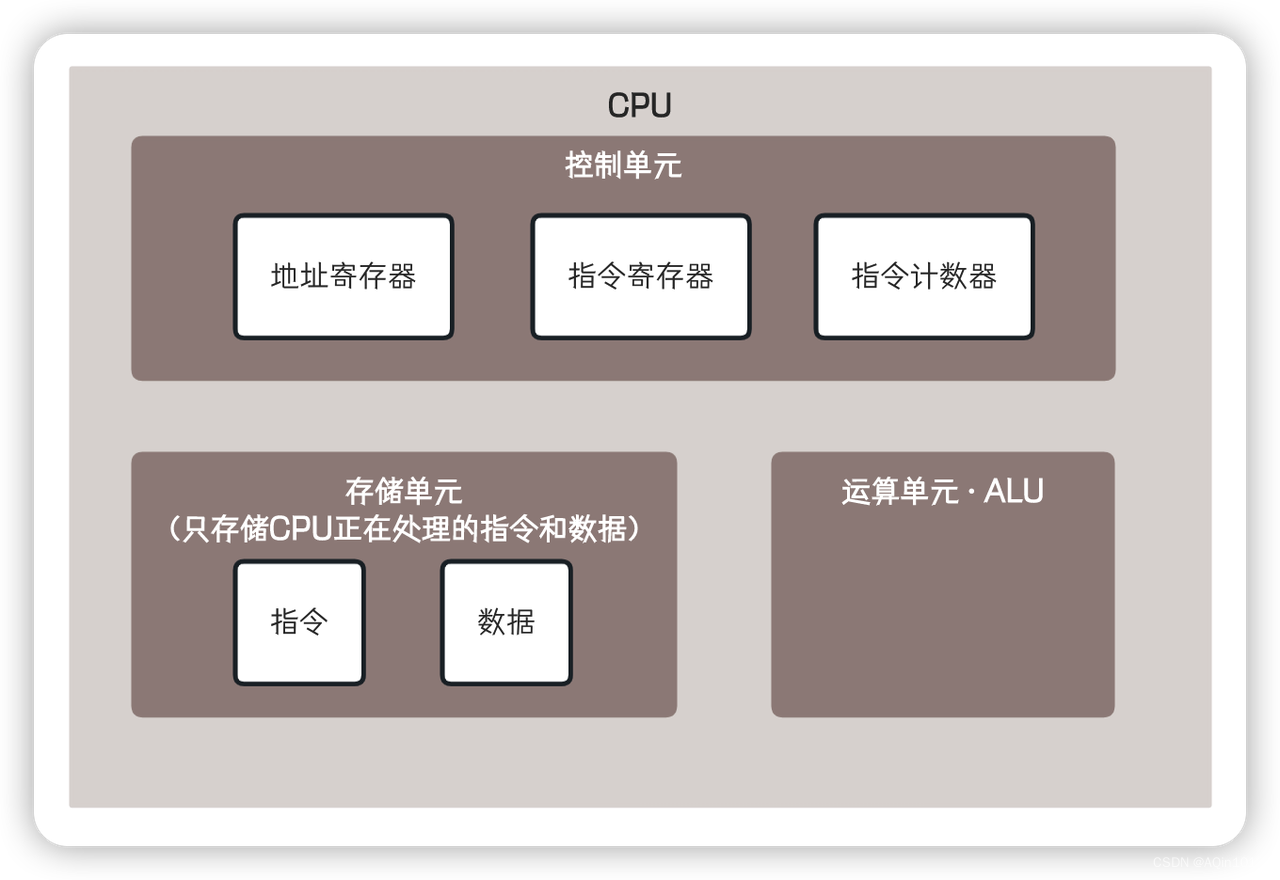
CPU缓存结构
说到CPU不得不提的就是著名的摩尔定律(Moore's Law)
摩尔定律是英特尔创始人之一戈登·摩尔的经验之谈,其核心内容为:集成电路上可以容纳的晶体管数目在大约每经过18个月到24个月便会增加一倍。换言之,处理器的性能大约每两年翻一倍,同时价格下降为之前的一半。
CPU以每18个月翻一倍的速度在发展,然而内存和硬盘的发展远远赶不上CPU,缓存的出现就是为了填补CPU运算速度和I/O速度之间的鸿沟。
为了减少 CPU与内存的交互,提高执行效率,一般在CPU上集成了多层缓存架构,常见的为三级缓存结构,即CPU 中的缓存按照其距离 CPU 核心的远近、大小和速度等因素,通常分为 L1 缓存、L2 缓存、L3 缓存(有时也会有高速缓存(common cache))
-
L1 :是 CPU 中距离核心最近的缓存,大小通常在几 KB 到几百 KB 之间
-
逻辑核独占
-
访问速度非常快,可以在一个 CPU 时钟周期内完成
-
L1 缓存通常将指令和数据分别缓存,且一般来说,指令缓存比数据缓存更大
-
-
L2 :是 CPU 中的第二级缓存,通常比 L1 缓存要大,大小在几百 KB 到几 MB 之间
-
物理核独占,逻辑核共享
-
补充 L1 缓存,将更多的热数据缓存在内部,并且降低 L1 缓存未命中时的延迟
-
访问速度较 L1 缓存要慢一些,一般需要几个 CPU 时钟周期
-
-
L3 :是 CPU 中的第三级缓存,通常比 L2 缓存要大,大小在几 MB 到几十 MB 之间
-
物理核共享,CPU独占
-
补充 L2 缓存,一般用于高端 CPU,尤其是多核 CPU 的设计中
-
访问速度比 L2 要慢一些,但比主存要快得多
-
-
高速缓存(common cache):是一个统一的缓存,用于将 L2 和 L3 缓存中的数据共享
-
在一些多核 CPU 中,由于不同的核心时刻都在访问内存,因此 L2 和 L3 缓存中的数据可能会部分重叠,通过将这些缓存共享,可以缩小 CPU 在一个时钟周期内访问内存的延迟,并提高 CPU 的性能
-

寄存器(Register)是 CPU 内部的一种存储设备,CPU内核分为物理核和逻辑核,每个CPU都有自己独有的寄存器,用于暂时存储数据、地址和指令等相关的信息,是计算机体系结构中最快的存储器,它们与 CPU 相关的芯片集成在一起,位于 CPU 内部。寄存器的大小和数量通常是 CPU 架构的一个重要参数,寄存器的增加可以提高计算机系统的吞吐率和响应速度,但同时也增加了物理设备的复杂性和成本。
在实际计算机系统中,CPU 和内存之间的数据传输通常需要通过系统总线(Bus)进行。系统总线是计算机中各种硬件设备互联的物理通道,能够以高速率传输指令和数据。CPU 可以通过总线将指令和数据从内存读取到 CPU 中进行处理,也可以将处理结果存储回内存中。总线的带宽和传输速率对计算机的整体性能有很大的影响,因此在计算机硬件设计中,总线的带宽和性能通常是优化的重点。
总的来说,在速度上:寄存器 > L1 > L2 > L3 > 内存
缓存行(cacheline)
缓存行(cacheline)是缓存最小的存储块(通常大小为64byte)
-
如果L1 大小是512kb,那么L1里就会有 512 * 1025 /64 个cacheline
-
如果一个数据很大,一行装不下就两行,以此类推(特别大的数据还是比较少的)
两项原则
-
时间局部性原则(Temporal Locality):如果一个信息正在被访问,那么他近期很可能再被访问
-
比如循环、递归、方法的调用等
-
-
空间局部性原则(Spatial Locality):如果一个存储器的位置被引用,那么将来他附近的位置也会被引用(于是会进行预读)
-
比如顺序执行的代码、连续创建的两个对象、数组
-
我们可以做个小实验佐证下这项原则
-
初始化一个二维数组,分别按照先行后列、先列后行的顺序求和,输出执行时间
-
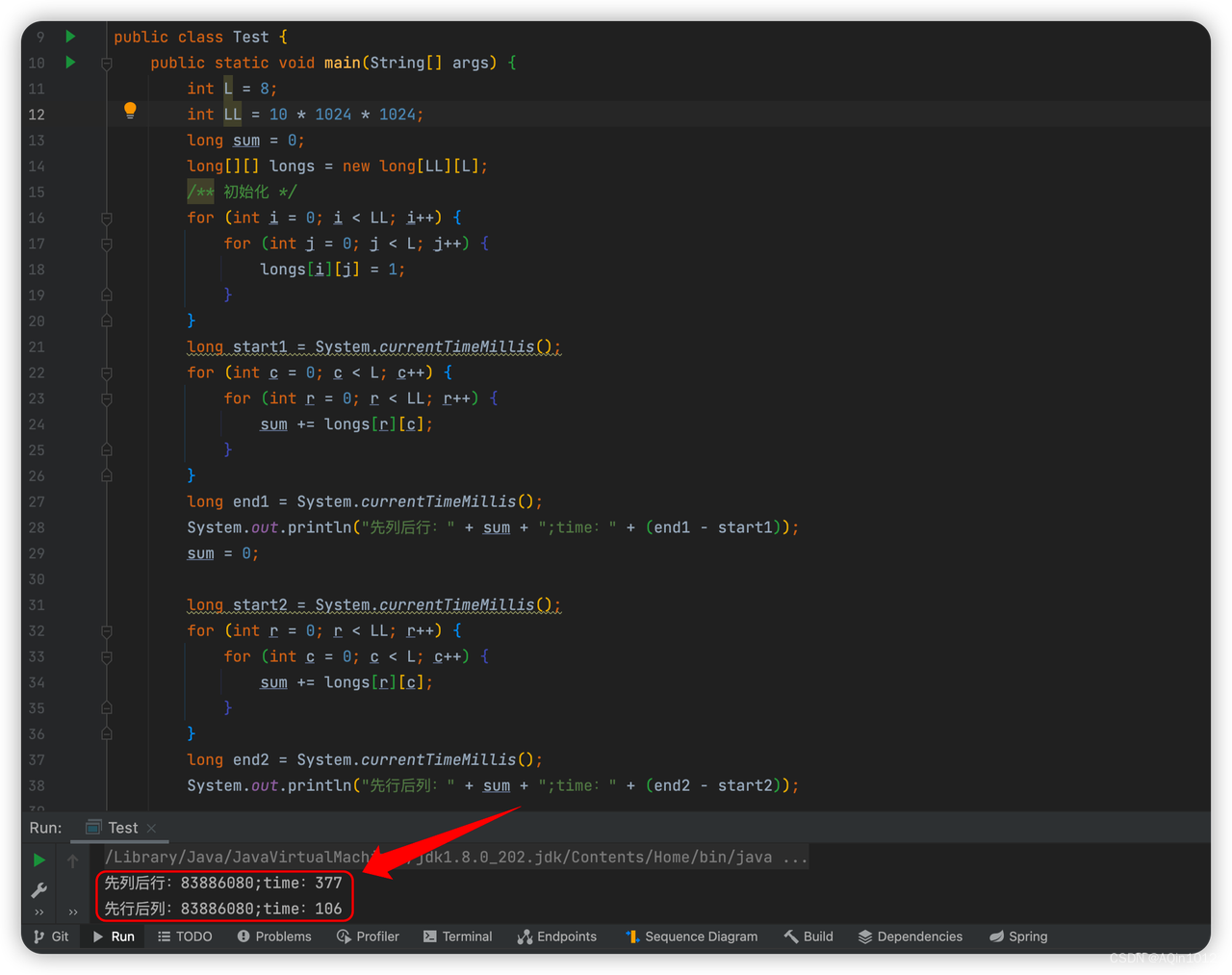
-
从上图的执行结果我们可以看出,先行后列比先列后行速度快很多,这就是空间局限性原则的体现,由于预读是以缓存行为单位的,我们分别分析下先行后列、先列后行这两种方式和主内存的交互次数
-
先行后列
-
由于 64/4=16 ,我们一行的数据有8个,因此可以通过一次与主内存的交互获得一行的数据,于是对行求和,然后再对列求,因此和主内存的交互次数为:10 * 1024 * 1024
-
-
先列后行
-
每次读取每行的第1个元素,相加求完一列的和再求下一列,因此和主内存的交互次数为:10 * 1024 * 1024 * 8
-
-
-
-
内存
操作系统内存管理
执行空间的保护
操作系统拥有用户空间和内核空间两个概念,目的是为了做到程序运行安全隔离与稳定
有四个(按照Intel的标准)
-
ring0(最高,内核态)
-
ring1
-
ring2
-
ring3(用户态,比如JVM)
Linux和WIndows只用到了ring0和ring3这连哥哥安全🔐级别,操作系统内部的指令通常运行在ring0级别上,操作系统以外的运行在ring3级别,当第三方程序需要调用系统内部的函数功能,由于安全级别不够,就需要切换CPU的运行状态(即从ring3切换到ring0),因此Java中创建线程、线程阻塞唤醒是重型操作(Java中的线程和操作系统的线程是一一对应的),因为CPU要切换运行状态
举个🌰,JVM创建线程时,CPU的大致工作流程
-
CPU从ring3切换到ring0,创建线程
-
CPU从ring0切换到ring3,线程执行JVM程序
-
执行完毕,ring3切换到ring0销毁线程
线程的分类
CPU调度的基本单位是线程
-
内核线程模型(KLT)
-
用户线程模型(ULT)
Java的线程是映射到操作系统的原生线程之上的,在 Linux 和 windows 使用的是内核级线程模型KLT
JVM 没有限定Java线程需要使用哪种线程模型来实现,JVM 只是封装了底层操作系统的差异,而不同的操作系统可能使用不同的线程模型,例如 Linux 和 windows 使用了一对一模型,solaris 和unix 某些版本可能使用多对多模型。所以一谈到 Java 语言的多线程模型,需要针对具体 JVM 实现。
比如 Sun JDK 1.2 开始,线程模型都是基于操作系统原生线程模型来实现,它的 Window 版和 Linux 版都是使用系统的1:1的线程模型实现的。
Java线程在JDK1.2之前,是基于称为“绿色线程”(Green Threads)的用户线程实现的,而在JDK1.2中,线程模型替换为基于操作系统原生线程模型来实现。因此,在目前的JDK版本中,操作系统支持怎样的线程模型,在很大程度上决定了Java虚拟机的线程是怎样映射的,这点在不同的平台上没有办法达成一致,虚拟机规范中也并未限定Java线程需要使用哪种线程模型来实现。线程模型只对线程的并发规模和操作成本产生影响,对Java程序的编码和运行过程来说,这些差异都是透明的。
对于Sun JDK来说,它的Windows版与Linux版都是使用一对一的线程模型实现的,一条Java线程就映射到一条轻量级进程之中,因为Windows和Linux系统提供的线程模型就是一对一的。而在Solari平台中,由于操作系统的线程特性可以同时支持一对一(通过Bound Threads或Alternate Libthread实现)及一对多(通过LWP/Thread Based Synchronization实现)的线程模型,因此在Solaris版的JDK中也对应提供了两个平台专有的虚拟机参数:-XX:+UseLWPSynchronization(默认值)和-XX:+UseBoundThreads来明确指定虚拟机使用哪种线程模型。
—— 《深入理解Java虚拟机》
感谢博文:https://www.cnblogs.com/itxdm/p/What_kind_of_implementation_is_the_thread_created_Why_is_process_switching.html
虚拟机指令集架构
分类
-
栈指令集架构
-
寄存器指令集架构
栈指令集架构
HotSpot 虚拟机使用的就是栈指令集架构
优点:
-
设计与实现更简单,适用于资源受限的系统
-
避开了寄存器的分配难题,使用零地址指令方式分配
-
指令流中的指令大部分是零地址指令,其执行过程依赖于操作栈,指令集更小,编译器更容易实现
-
不需要硬件支持,可移植性好,更好实现跨平台
缺点:
-
在内存中执行,效率较低
-
实现同一项操作花费的指令数量更多
寄存器指令集架构
典型的应用是X86的二进制指令集:比如传统的PC以及Androud的Davlik虚拟机
优点:
-
在CPU中执行,效率更高
-
实现同一项操作花费的指令数量更少
缺点:
-
完全依赖于硬件,可移植性差