数仓中的数据分层
文章目录
- 数仓中的数据分层
- 维度模型
- 维度建模下的主要概念
- 维度表
- 事实表
- 结合维度模型分析数据分层
- 贴源层 (Operation Data Store)
- 公共维度层 CDM(Common Data Model)
- 数据细节层 DWD(Data Warehouse Details)
- 数据中间层 DWM(Data Warehouse Middle)
- 数据服务层 DWS(Data Warehouse Service)
- 数据应用层 ADS(Application Data Service)
- Hive元数据仓库
- ODS_SOR层
- CDM_DWS层
- 表分区层级分区数量表
- 表设计
- ADS层
- 表一级分区的数量警示表
- 表设计
- 表二级分区的数量警示表
- 表设计
- 表分区级别警示表
- 表设计
- 序列化表中存在不指向存储信息表的记录表
- 表设计
为什么会出现数据分层?
- 对数据开发流程进行规范
- 明确数据结构,方便使用
- 进行有效的数据管理
- 保障数据质量
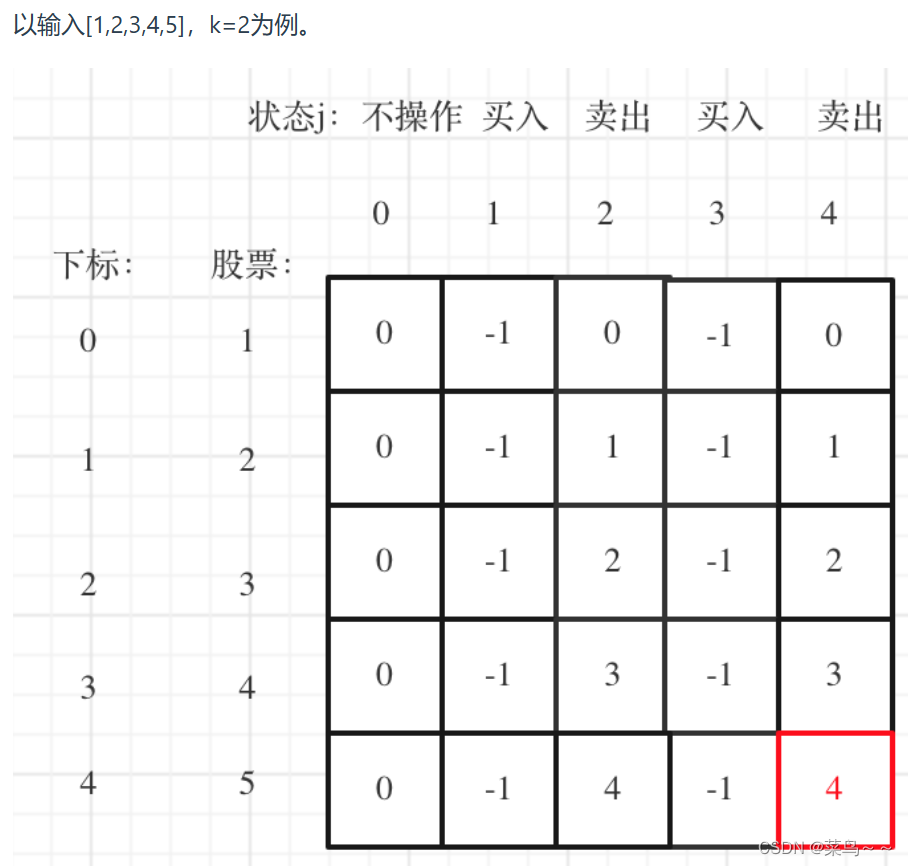
维度模型
维度建模是面向分析场景的,针对分析场景构建数仓模型;重点关注快速、灵活的解决分析需求,同时能够提供大规模数据的快速响应性能。主要应用于数据仓库构建和OLAP引擎低层数据模型。
优点:不需要完整的梳理企业业务流程和数据,实施周期根据主题边界而定,容易快速实现demo,而且相对来说便于理解、提高查询性能、对称并易扩展。
维度模型更侧重于完成具体的分析决策需求,是一种从下往上的构建思路。同时,它关注大规模复杂查询的响应性能,星型模型是其具体形式。
维度建模下的主要概念
维度表
维度表又称维表,维表存储的一般是对事实描述的信息。每一张维表对应现实世界中的一个对象或者概念。例如:用户、商品、日期、地区等。
高基数维度数据:数据量可能是千万级或者上亿级别,比如用户资料表、商品资料表类似的资料表。
低基数维度数据:数据量可能就是个位数或者几千几万,一般是配置表,比如枚举字段对应的中文含义,或者日期维表等。
事实表
事实表主要围绕业务过程设计,表中的每行数据代表一个业务事件(下单、支付、退款、评价等)。每一个事实表的行包括:具有可加性的数值型的度量值、与维表相连接的外键。通常具有两个和两个以上的外键,外键之间表示维表之间多对多的关系。
事实事务表
用于描述业务过程,按业务过程的单一性或多业务过程可进一步分为单事务事实表和多事务事实表。其中单事务事实表分别记录每个业务过程,如下单业务记入下单事实表,支付业务记入支付事实表。多事务事实表在同一个表中包含了不同业务过程,如下单、支付、签收等业务过程记录在一张表中,通过新增字段来判断属于哪一个业务过程。
结合维度模型分析数据分层
通用的分层(自上而下):应用层,加工汇总层,贴源层
维度模型常用的分层(自上而下):数据应用层,数据仓库层(数据细节层、数据中间层、数据服务层),贴源层(SSA层,SOR层)
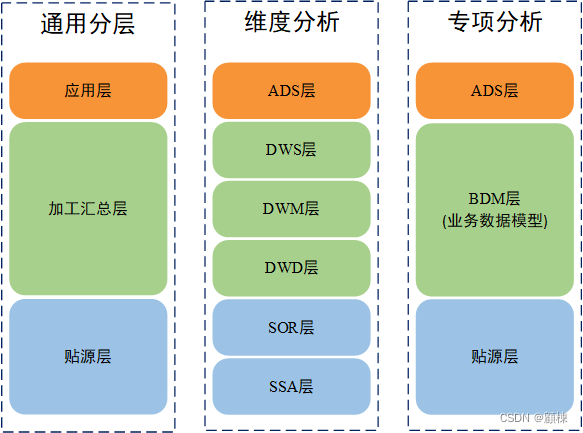
贴源层 (Operation Data Store)
贴源层可以细分为SSA层(system-of-records-staging-area)和SOR层(system-of-record)。
SSA层 是直接复制源数据的,除了需要版本化时增加数据采集的时间戳外,与源系统数据的原貌是一致的,包括错误值,空值等等。
SOR层 在学术上的一种解释是基于模型开发的符合数据库3NF范式规则的表结构,存储着数据库中最细最底层的数据。在实际操作中不一定满足第三范式,且如果源系统的数据本身就是结构化的数据(如Mysql数据库的数据),可以直接存入此层。
公共维度层 CDM(Common Data Model)
数据细节层 DWD(Data Warehouse Details)
该层是业务层和数据仓库的隔离层,保持和ODS层一样的数据颗粒度;主要是对ODS数据层做一些数据的清洗和规范化的操作,比如去除空数据、脏数据、离群值等。
为了提高数据明细层的易用性,该层通常会才采用一些维度退化方法,将维度退化至事实表中,减少事实表和维表的关联。
数据中间层 DWM(Data Warehouse Middle)
该层是在DWD层的数据基础上,对数据做一些轻微的聚合操作,生成一些列的中间结果表,提升公共指标的复用性,减少重复加工的工作。
数据服务层 DWS(Data Warehouse Service)
该层是基于DWM上的基础数据,整合汇总成分析某一个主题域的数据服务层,一般是宽表,用于提供后续的业务查询,OLAP分析,数据分发等。
一般来说,该层的数据表会相对较少;一张表会涵盖比较多的业务内容,由于其字段较多,因此一般也会称该层的表为宽表。
DWM与DWS的边界不是很清晰,主要根据汇总聚合的条件粒度来判断。 这两个层数据都可以直接为ADS服务。
数据应用层 ADS(Application Data Service)
该层主要是提供给数据产品和数据分析使用的数据,一般会存放在ES、Redis、PostgreSql等系统中供线上系统使用;也可能存放在hive或者Druid中,供数据分析和数据挖掘使用,比如常用的数据报表就是存在这里。
Hive元数据仓库
将Hive元数据存储库(Mysql)中的数据采集存储至Hive中进行分析。
ODS_SOR层
采集的Mysql库中的表,按天全量采集,hive表采用分区表的形式,分区字段统一day(string)格式:“yyyyMMdd”。表的命名方式采用mysql表名加前缀hive_meta_的形式。
| Mysql表名 | Hive表名 ODS | 采集状态 | 备注 |
|---|---|---|---|
| DBS | hive_meta_dbs | 已采集 | |
| DB_PRIVS | hive_meta_db_privs | 已采集 | |
| TBLS | hive_meta_tbls | 已采集 | |
| COLUMNS_V2 | hive_meta_columns_v2 | 已采集 | |
| TABLE_PARAMS | hive_meta_table_params | 已采集 | |
| TBL_PRIVS | hive_meta_tbl_privs | 已采集 | |
| PARTITIONS | hive_meta_partitions | 已采集 | |
| PARTITION_KEYS | hive_meta_partition_keys | 已采集 | |
| PARTITION_PARAMS | hive_meta_partition_params | 已采集 | |
| SDS | hive_meta_sds | 已采集 | |
| SERDES | hive_meta_serdes | 已采集 | |
| SERDE_PARAMS | hive_meta_serde_params | 已采集 |
CDM_DWS层
新建统计表给数据应用层使用。
表分区层级分区数量表
表设计
表名T_DWS_BD_HIVE_META_PART_SAL_ED
| 字段名 | 字段类型 | 注释 | 备注 |
|---|---|---|---|
| tbl_id | bigint | 表的主键 | |
| tbl_name | string | 表的名称 | |
| db_id | bigint | 库的主键 | |
| tbl_owner | string | 表的拥有主体 | |
| part_sum | string | 表下的分区数量 | 若非分区表,则值为空 |
| part_level | string | 表下的分区级别 | 若非分区表,则值为空 |
| day | string | 分区字段,日期 | 分区字段,日期格式:yyyyMMdd,每天存的是全量的数据 |
表依赖
hive_meta_tblshive_meta_partitionshive_meta_partition_keys
表数据来源
SELECT hmt.TBL_ID
,hmt.TBL_NAME
,hmt.DB_ID
,hmt.OWNER as tbl_owner
,ps.PART_SUM
,pl.PART_LEVEL
FROM hive_meta_tbls hmt
LEFT JOIN
(
SELECT COUNT(hmp.PART_ID) AS PART_SUM
,hmp.TBL_ID
FROM hive_meta_partitions hmp
WHERE hmp.day = '20230505'
GROUP BY hmp.TBL_ID
) AS ps
ON hmt.TBL_ID = ps.TBL_ID
LEFT JOIN
(
SELECT COUNT(hmpk.PKEY_NAME) AS PART_LEVEL
,hmpk.TBL_ID
FROM hive_meta_partition_keys hmpk
WHERE hmpk.day = '20230505'
GROUP BY hmpk.TBL_ID
) AS pl
ON hmt.TBL_ID = pl.TBL_ID
WHERE hmt.day = '20230505';
ADS层
新建一些可供应用层直接使用的表
表一级分区的数量警示表
表设计
T_ADS_BD_HIVE_META_PART_L1A_ED
| 字段名 | 字段类型 | 注释 | 备注 |
|---|---|---|---|
| tbl_id | bigint | 表的主键 | |
| tbl_name | string | 表的名称 | |
| db_id | bigint | 库的主键 | |
| tbl_owner | string | 表的拥有主体 | |
| db_owner | string | 库的拥有主体 | |
| part_sum | string | 表下的分区数量 | 若非分区表,则值为空 |
| part_level | string | 表下的分区级别 | 若非分区表,则值为空 |
| day | string | 分区字段,日期 | 分区字段,日期格式:yyyyMMdd,每天存的是全量的数据 |
表依赖
T_DWS_BD_HIVE_META_PART_SAL_EDhive_meta_dbs
表数据来源
SELECT t1.tbl_id
,t1.tbl_name
,t1.db_id
,t1.tbl_owner
,hmd.owner_name AS db_owner
,t1.part_sum
,t1.part_level
FROM
T_DWS_BD_HIVE_META_PART_SAL_ED AS t1
JOIN hive_meta_dbs hmd
ON hmd.db_id = t1.db_id
WHERE hmd.day = '20230505'
AND t1.day = '20230505'
AND t1.part_sum > 1800
AND t1.part_level = 1;
表二级分区的数量警示表
表设计
T_ADS_BD_HIVE_META_PART_L2A_ED
| 字段名 | 字段类型 | 注释 | 备注 |
|---|---|---|---|
| tbl_id | bigint | 表的主键 | |
| tbl_name | string | 表的名称 | |
| db_id | bigint | 库的主键 | |
| tbl_owner | string | 表的拥有主体 | |
| db_owner | string | 库的拥有主体 | |
| part_sum | string | 表下的分区数量 | 若非分区表,则值为空 |
| part_level | string | 表下的分区级别 | 若非分区表,则值为空 |
| day | string | 分区字段,日期 | 分区字段,日期格式:yyyyMMdd,每天存的是全量的数据 |
表依赖
T_DWS_BD_HIVE_META_PART_SAL_EDhive_meta_dbs
表数据来源
SELECT t1.tbl_id
,t1.tbl_name
,t1.db_id
,t1.tbl_owner
,hmd.owner_name AS db_owner
,t1.part_sum
,t1.part_level
FROM
T_DWS_BD_HIVE_META_PART_SAL_ED AS t1
JOIN hive_meta_dbs hmd
ON hmd.db_id = t1.db_id
WHERE hmd.day = '20230505'
AND t1.part_sum > 20000
AND t1.day = '20230505'
AND t1.part_level = 2;
表分区级别警示表
表设计
T_ADS_BD_HIVE_META_PART_LA_ED
| 字段名 | 字段类型 | 注释 | 备注 |
|---|---|---|---|
| tbl_id | bigint | 表的主键 | |
| tbl_name | string | 表的名称 | |
| db_id | bigint | 库的主键 | |
| tbl_owner | string | 表的拥有主体 | |
| db_owner | string | 库的拥有主体 | |
| part_level | string | 表下的分区级别 | 数值大于2 |
| day | string | 分区字段,日期 | 分区字段,日期格式:yyyyMMdd,每天存的是全量的数据 |
表依赖
T_DWS_BD_HIVE_META_PART_SAL_EDhive_meta_dbs
表数据来源
SELECT t1.tbl_id
,t1.tbl_name
,t1.db_id
,t1.tbl_owner
,hmd.owner_name AS db_owner
,t1.part_level
FROM T_DWS_BD_HIVE_META_PART_SAL_ED AS t1
JOIN hive_meta_dbs hmd
ON hmd.db_id = t1.db_id
WHERE hmd.day = '20230505'
AND t1.day = '20230505'
AND t1.part_level > 2;
序列化表中存在不指向存储信息表的记录表
根据表关系serdes表的数据会与sds关联,serdes会通过sds标明表或者表分区的序列化与反序列信息,若不与sds关联,数据就会形成空岛。如何使用呢?
表设计
表名T_ADS_BD_HIVE_META_SERDES_UNDIRECTED_ED
| 字段名 | 字段类型 | 注释 | 备注 |
|---|---|---|---|
| SERDE_ID | bigint | 序列化的编号 | |
| NAME | string | 序列化和反序列化名称 | |
| SLIB | string | 使用的是哪种序列化方式 | |
| day | string | 分区字段,日期 | 分区字段,日期格式:yyyyMMdd,每天存的是全量的数据 |
表依赖
hive_meta_serdeshive_meta_sds
表数据来源
SELECT *
FROM hive_meta_serdes a
WHERE serde_id not IN ( SELECT serde_id FROM hive_meta_sds b WHERE b.day = '20230505')
AND a.day = '20230505';